Attention Is All You Need paper review (4)
작성일
부족하겠지만 처음으로 내 스스로 논문을 읽고 정리해보려 함
영어실력의 부족으로 번역에 문제가 좀 있을 수 있으니 오역의 부분이 있다면 댓글을 달아주시면 좋을듯 함
- 1편 Attention Is All You Need Review (1)
- 2편 Attention Is All You Need Review (2)
- 3편 Attention Is All You Need Review (3)
- 4편 Attention Is All You Need Review (4)
Attention Is All You Need paper review (4)
5 Training

이 섹션은 우리의 모델에 대한 학습 방법을 설명함
5.1 Training Data and Batching

우리는 약 450만개의 문장 쌍으로 구성된 표준 WMT 2014 English-German 데이터셋 으로 학습함
문장들은 약 37,000 개의 토큰의 source-target 사전을 공유하는 byte-pair encoding 을 사용하여 인코딩 되었음
English-French 에 대해서 우리는 3600만개의 문장으로 구성된 훨씬 더 큰 WMT 2014 English-French 데이터셋을 사용했음
그리고 32000개의 word-piece 단어사전안에 들어있는 토큰으로 나눔
문장쌍은 대략적인 시퀀스길이에 의해 함께 배치화 되었음
각각의 학습 배치는 대략적으로 25000 개의 source 토큰 과 25000 개의 target 토큰을 포함하는 문장 쌍들의 집합이 들어있음
5.2 Hardware and Schedule

우리는 우리의 모델을 8개의 NVIDIA P100 GPU 들을 가진 하나의 컴퓨터로 학습함
논문을 통해 설명된 하이퍼파라미터들을 사용한 우리의 base 모델에 대해 각각의 학습 단계는 약 0.4초 걸림
우리는 base 모델을 12시간동안 총 100,000 스텝을 학습함
table 3 의 마지막 줄에서 소개된 우리의 big 모델에 대해서 학습 단계는 1.0초 걸림
big 모델은 3.5 일동안 300,000 스텝이 학습됨
5.3 Optimizer

우리는 Adam optimizer($\beta_1 = 0.9, \beta_2 = 0.98 and \eta = 10^{-9}$)를 사용했음
우리는 학습 과정 중에 learning rate 를 바꿨음
아래 공식을 따라서
\[lrate = d_{model}^{-0.5} \cdot min(step_num^{-0.4}, step_num \cdot warmup_steps^{-0.4})\]이것은 첫번째 $warmup_steps$ 훈련 단계에 대해 선형적으로 learning rate 를 증가시키고 그 후에 $\sqrt{step_num}$ 의 역수로 비율적으로 감소시키는 것에 해당함
우리는 $warmup_steps$ = 4000 으로 사용함
5.4 Regularization

우리는 학습중에 3가지 타입의 정규화를 사용함
Residual Dropout
우리는 각각의 sub-layer 의 output 이 sub-layer 의 input 과 더해지고 정규화 되기 전에 dropout 을 적용함
우리는 encoder 와 decoder stack 둘다에서 embedding 과 positional encoding 들의 합에 dropout 을 적용함
base model 에서 우리는 dropout 비율을 $P_{drop}$ = 0.1 로 사용함

Label Smoothing
학습 중에 우리는 $\eta_{ls}$ = 0.1 의 label smoothing 을 사용함
이것은 모델이 좀 더 확실하지 않은 것을 배우기 때문에 당황? 당혹감을 더 크게 만들지만 정확도와 BLEU score 를 향상시킴
6 Results
6.1 Machine Translation

WMT 2014 English-to-German 번역 task 에서 big transformer 모델은 새로운 SOTA 인 BLEU score 28.4 를 기록하면서 앙상블을 포함한 이전의 발표됐던 모델들의 BLEU 점수를 2.0 보다 많이 넘었음
이 모델의 구성은 Table 3 의 마지막 줄에 있음
학습은 8대의 P100 GPU 로 3.5일 걸렸음
심지어 우리 base model 은 경쟁하는 모델들에 학습 비용이 적게들었는데 이전에 발표된 모델들과 앙상블 전부보다 성능이 좋음
WMT 2014 English-to-French 번역 task 에서 우리의 big 모델은 학습비용이 이전의 SOTA 모델의 1/4 보다 적은데 이전에 발표된 단일 모델들 전부를 뛰어넘는 BLEU score 41.0 을 달성함
English-to-French 를 위해 학습된 Transformer(big) 모델은 dropout 비율을 0.3 대신에 $P_{drop}$ = 0.1 을 사용함
base 모델에서 우리는 10분 간격으로 만들어진 마지막 5개의 checkpoint 를 평균함으로써 얻어진 단일모델을 사용함
우리는 beam size 가 4이고 길이 패널티(length penalty)가 $\alpha$ = 0.6 인 beam search 를 사용했음
이러한 하이퍼파라미터들은 development set 로 실험후에 선택되었음
우리는 추론 중에 최대 output 길이를 input 길이 + 50 만큼 세팅했지만 가능하다면 빨리 끊었음
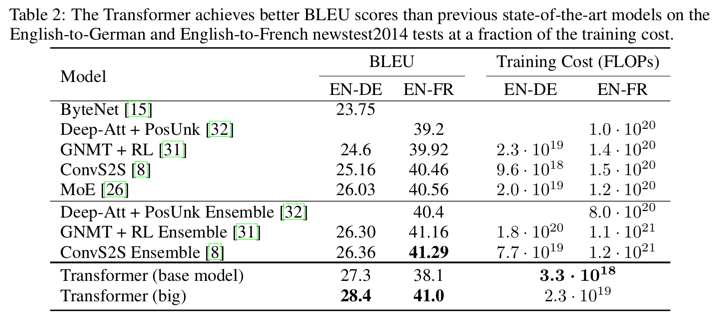
Table 2 는 우리의 결과를 요약하고 우리의 번역 퀄리티와 학습 비용을 다른 논문들로 부터의 모델 아키텍처와 비교함
우리는 학습시간과 GPU 의 수와 각각의 GPU 의 수용량을 단일 정밀도(single-precision) 으로 표현한 부동소수점 추정치를 곱함으로써 모델을 학습하는데 사용된 계산량을 부동소수점으로 추정함
6.2 Model Variations

Transforemr 의 다른 구성요소의 중요성을 평가하기 위해 우리는 newstest2013 을 development set 으로 English-to-German 번역에서의 성능의 변화를 측정하는 다른 방법으로 우리의 base 모델을 변화시켰음
우리는 이전 섹션에서 설명한것과 같은 beam search 를 사용했지만 checkpoint 의 평균은 사용하지 않았음
우리는 이 결과들을 Table 3 에서 보여줬음
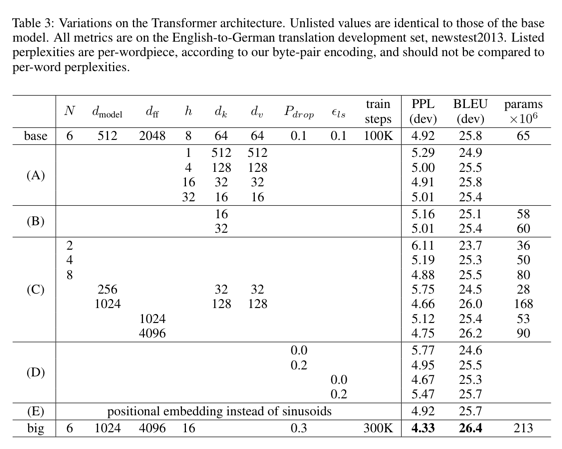
Table 3 (A) 행에서 우리는 3.2.2 섹션에서 설명된것처럼 상수의 계산량을 유지하면서 attention head 의 수와 attention key 와 value 의 차원들을 바꿨음
단일 head attention 은 최적의 세팅보다 0.9 BLEU score 만큼 나빠졌지만 너무 많은 head 는 품질또한 떨어졌음

Table 3 (B) 행에서 우리는 attention key 의 사이즈인 $d_k$가 줄어드는 것은 모델의 퀄리티를 떨어뜨리는 것을 관찰함
이것은 호환성을 결정하는 것은 쉽지않음과 내적보다 좀 더 정교한 호환성 함수가 이득이 될 것이라는 것을 제안함
우리는 더나아가 예상했듯이 (C) 와 (D) 행에서 더 큰 모델이 더 나은 성능을내고 dropout 이 over-fitting 을 피하는데 효과적이라는 것을 관측함
(E) 행에서 우리는 정현파(sinusoidal) positional encoding 을 학습가능한 positional embedding 으로 대체함
그리고 base 모델과 거의 동일한 결과를 관측함
7 Conclusion

이 연구에서 우리는 encoder-decoder 아키텍처에서 가장 일반적으로 사용되는 recurrent 층을 multi-headed self-attention 으로 대체한 처음으로 완전히 attention 으로 구성된 시퀀스 변환모델인 Transformer 를 소개했음
번역 task 에 대해 Transforemr 는 reccurrent 또는 convolutional 층으로 이루어진 아키텍처보다 상당히 빠르게 학습될 수 있음
WMB 2014 English-to-German 과 WMT 2014 English-to-French 번역 task 둘다에서 우리는 새로운 SOTA 를 달성함
앞의 task 에서 우리의 best 모델은 심지어 앙상블로 발표된 이전의 모든 모델들을 능가함
우리는 attention 으로 이루어진 모델들의 미래에 대해 흥분했고 다른 task 에도 적용하려고 계획함
우리는 Transformer 를 text 와 다른 양식의 input 과 output 을 포함하는 문제들로 확장하려고 계획함
그리고 이미지, 오디오 그리고 비디오와 같은 큰 input 과 output 들을 효과적으로 다룰수 있는 제한된 attention mechanism 을 조사할 계획임
비연속적인 생성을 만드는 것은 우리의 또 다른 연구 목표임
우리의 모델을 학습하고 평가하기 위해 사용된 코드는 https://gitgub.com/tensorflow/tensor2tensor 에서 이용 가능함
댓글남기기