Day_40 [오피스아워] Relation Extraction
작성일
[오피스아워] Relation Extraction - 박채훈
Relation Extraction Competition
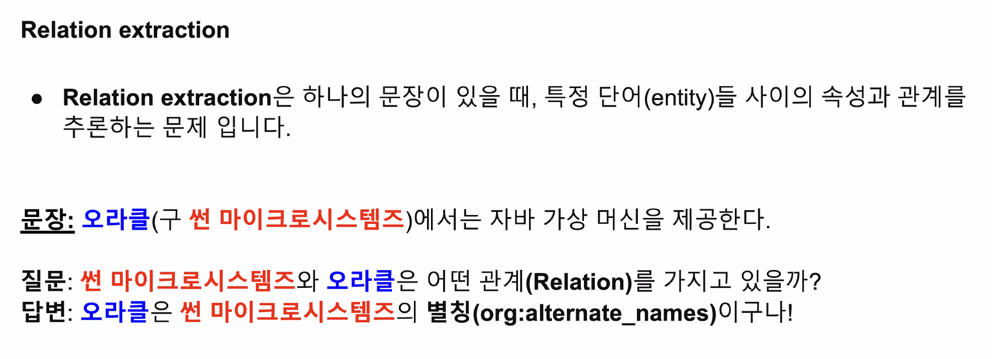
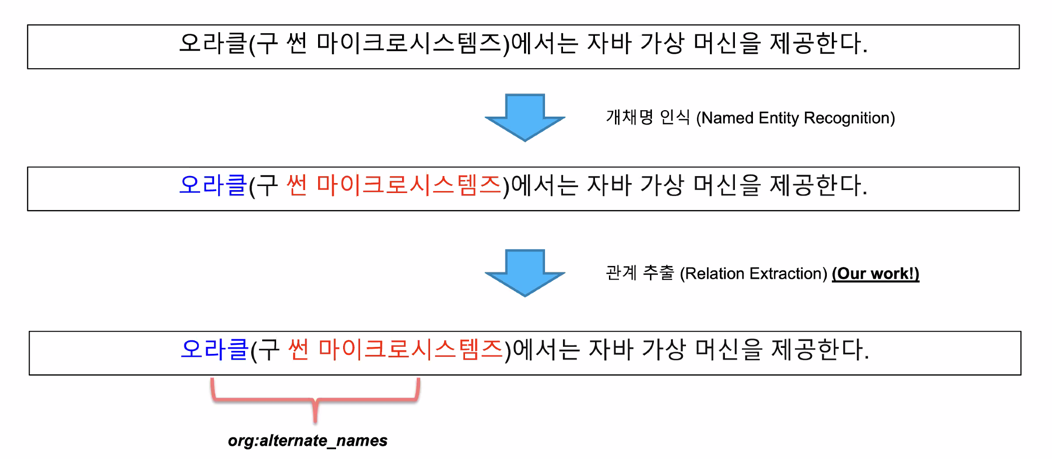
Relation extraction 이란?
Competition Idea & Tips
Language Models for Korean!

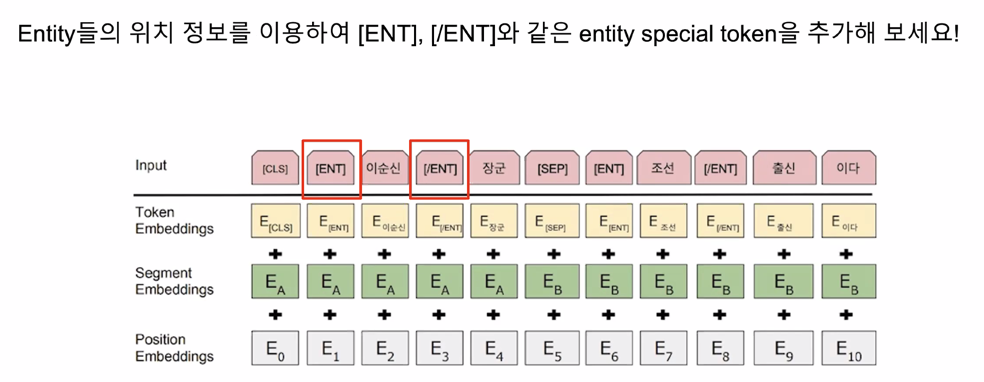
Using Special Token

Additional Embedding Layer
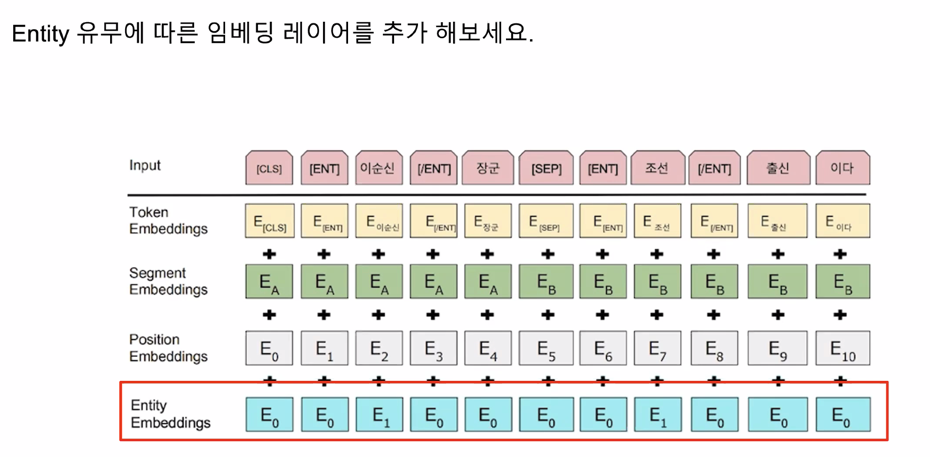
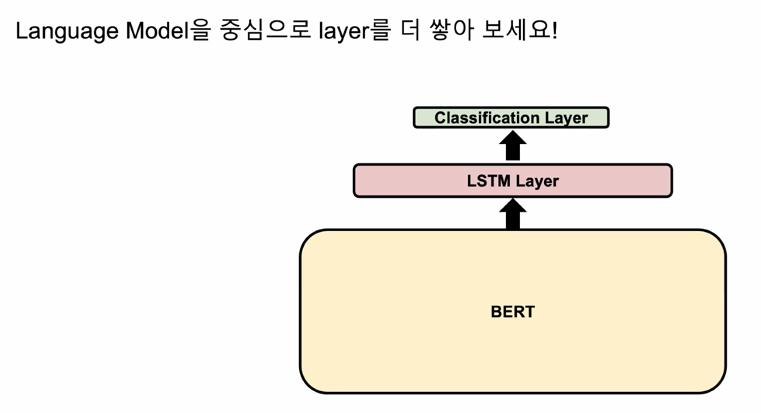
Additional Output Layer
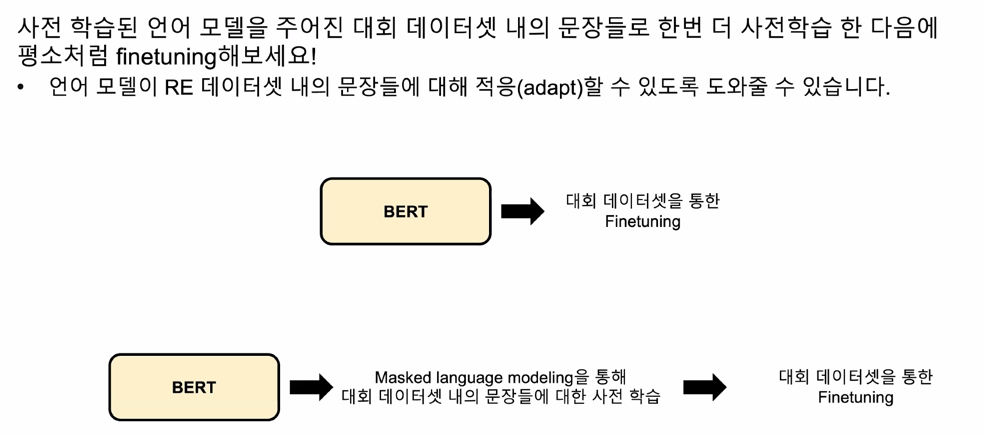
Language Model Domain Adaptation
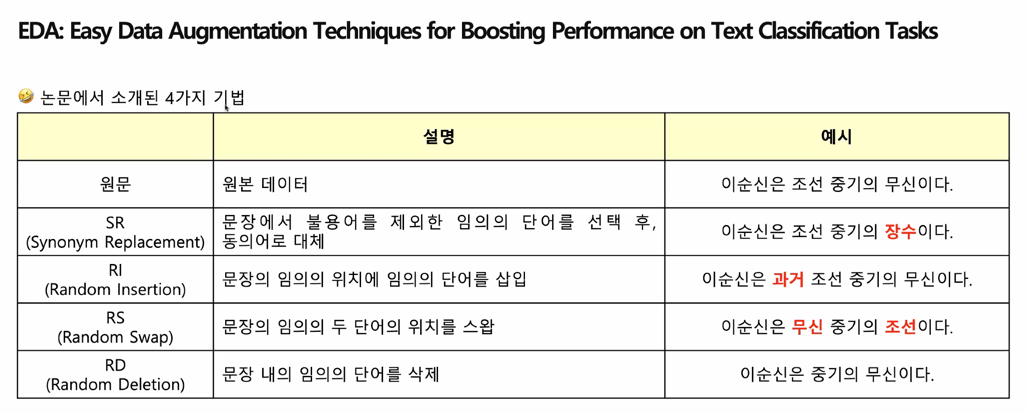
Data Augmentation


EDA


EDA 구현해보기

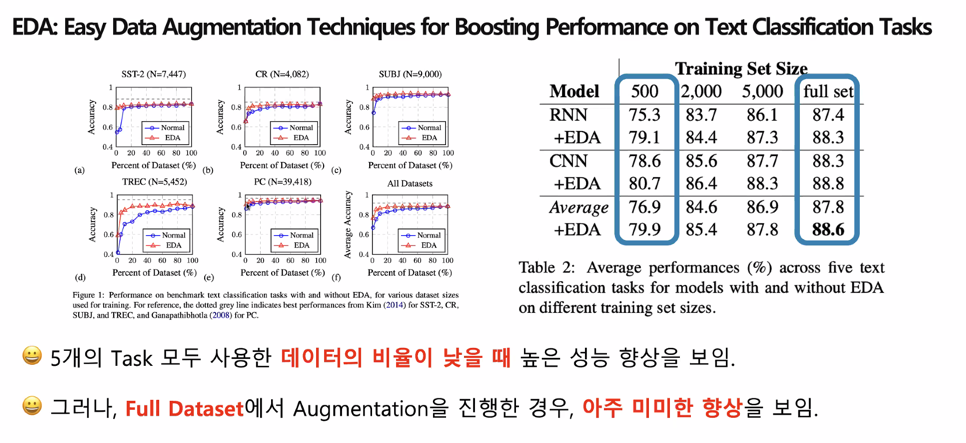
EDA 실험 결과

혹시 EDA 를 시도해 볼 시간이 없다면?

Round-trip translation (a.k.a. Back-translation)
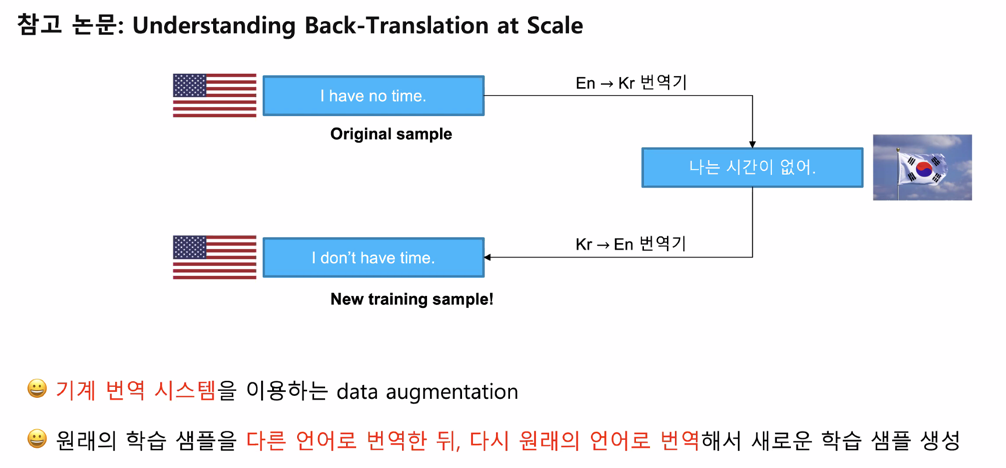

예시를 보면 좀 의미가 달라지는 경우가 있음
Single or Multi ?
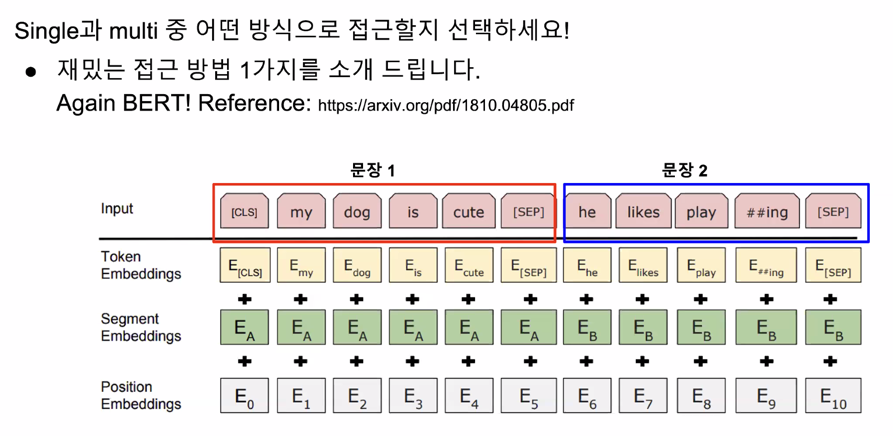


Recent Studies for Relation Extraction
Relation Extraction on Special Domain
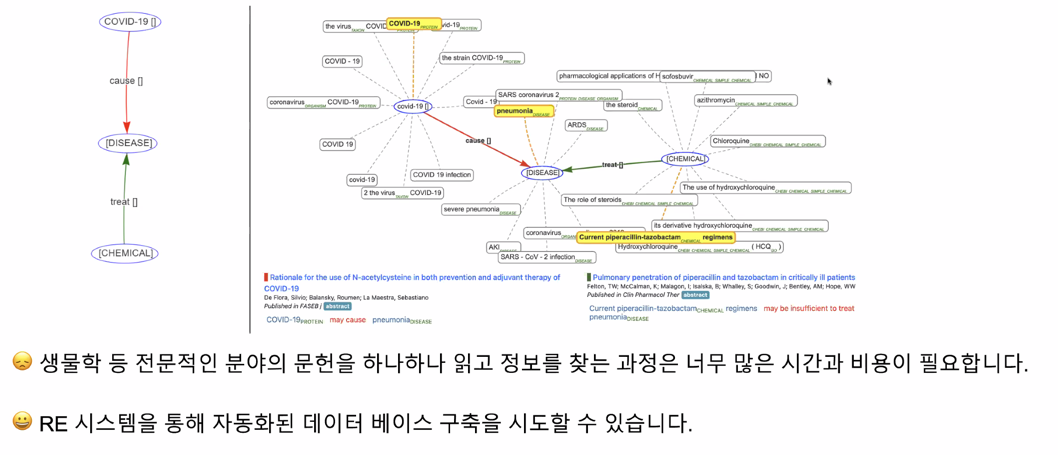
Document-level Relation Extraction

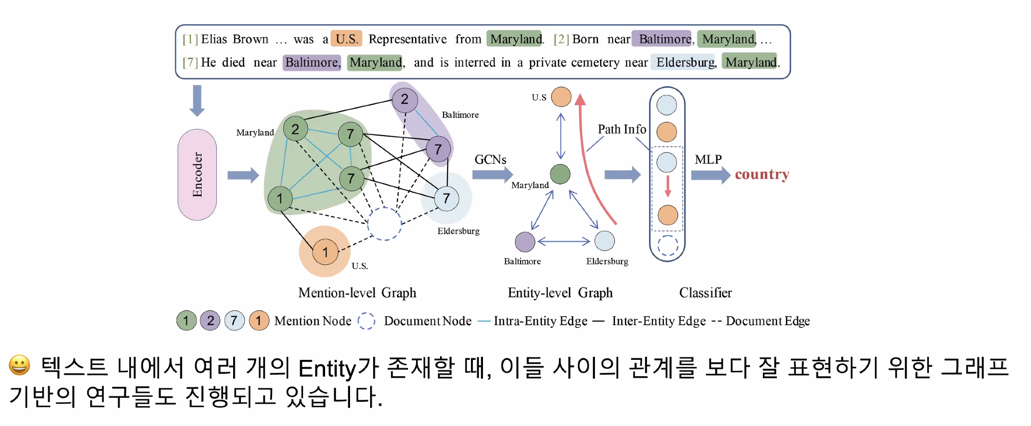
Graph-based Relation Extraction
Q & A


전처리 할 때 tokenization 이 전처리 처음 단계에서 무조건 사용되는데 tokenizer 를 뭘쓸지 생각을 많이 안해보는 듯
그래서 tokenization 도 다양한 방법으로 할 수 있고 각각의 차이가 어떻게 나오는지를 알려주고 싶었음
Back Translation을 하게 되면 entity 위치가 변경되거나 없어질 수도 있는데 이것은 어떻게 해결할 수 있을까요?
- Entity 에 괄호를 넣으면 잘 보정이 되지 않을까? 그 단위가 통채로 번역되지 않을까? 하는 생각이 있음
- 두개의 Entity 가 보존 될 때까지
- 굳이 augmentation 을 한 후에 정상이 아닌 데이터를 사용하지 않아도 됨
ENTITY 대신 고유명사를 넣어서 번역하고 다시 entity로 대체하는 방법은 어떤가요?
Entity 를 보존한다는 관점에서는 좋긴한데 번역기가 혹시나 다른 단어로 대체해버릴 수 있음
혹시 finetuning 하는 레이어를 깊게쌓는것도 도움이 되나요?
시도해 볼 만한 좋은 방법인 것 같음
그 사이사이에 dimention fuction 을 어떤걸 쌓느냐가 성능에 영향을 줄 수 있으므로
해보는 것도 좋음
RE task 에서 혹시 start_index 와 end_index 가 어디에 도움이 될 수 있을까요?
한 문장에서 단어가 2번 나왔으면 그 단어가 어떤 단어인지 파악하기 어려워서 주워진다고 봄
데이터가 많은지 적은지 판단하는 기준은 무엇인가요?
똑같은 task 를 하더라도 데이터셋이 많으면 많을수록 좋다라고 상대적인 비교로 말을 많이
하는 것 같음
RE task 같은 경우에는 class 별로 분류를 하는 건데 한 데이터의 sample 이 10개 밖에 안된다
하면 이런 경우에 불균형이 있으므로 상대적으로 데이터가 적다고 할 수 있지 않나 싶음
두번의 단어가 등장할 때 어떤 단어를 고르냐에 따라 성능에 적지않은 영향을 미친다고 생각하시는걸까요??
데이터셋을 구축할 때 기준이 무엇인지를 명시함
현재 Entity Type이 human sense 관점으로 잘못 매겨진 것으로 판단되는 데이터들이 몇개 있었습니다. 이것을 바꾸는 것이 좋을지 아니면 그냥 두는 것이 좋을지 모르겠습니다. 몇개나 잘못됬는지도 눈으로 보지 않으면 판단할 수가 없어 결정을 못하고 잇습니다 ㅠㅠ
만약 trainset 안에 humansense 와 같이 잘못된 데이터가 있다면 test 에서도 잘 못 되어 있을 거라고 생각함
같은 클래스내에 엔티티끼리 바꾼 방식의 augmentation이 가능할까요?
label 에 따라서 적용 가능한 label 이 있고 아닌 것도 있을 것 같음
서동건 캠퍼님 질문 이어서 한 번 더 질문하겠습니다! data가 적은 label class의 mislabel data는 그 영향이 클 것 같은데 이 때는 바꾸는 것이 좋지 않을까요?
이 경우는 바꾸는게 좋을 것 같긴 함
특정 labeling 방식에 대해서 문의드리고 싶은 것이 있습니다. 데이터 중 “어떤 남녀가 이혼에 합의했다” 라는 문장에서 남녀를 entity로 묶은 것이 있는데, 본 데이터셋에서는 no_relation이라고 되어있습니다. 이렇듯 현재 시점을 기준으로만 labeling이 진행된건가요?
re 팀에 문의 후 klue 채널에 남겨 주겠다고 하심
홍길동은 한국에서 태어났다 -> 홍길동은 볼리비아에서 태어났다 이렇게 추가하면 문제가 될까요? 뭔가 둘의 관계가 태어난곳의 위치인것만 맞추면 될 것 같은데 정답단어 자체의 의미가 중요 할까요?
되게 좋은 방법인 것 같다.
한국이나 볼리비아라는 값은 국가라는 느낌이 같고 문장에서 relation 을 추출할 수 있다고 생각해서
좋은것 같음
type 은 같은데 다른 단어로 바꿔주는 방식이기 때문에 정교하게 잘 되기만 하면 좋은 방법인 것 같음
추가로 말씀드리자면, 데이터셋의 각 entity마다 개체명 테그가 부착되어 있을거에요 :-) 개체명 테그가 같은 entity로는 교체해도 의미적으로 큰 문제가 생기진 않을겁니다. 저라면 모든 데이터를 대상으로 각 개체별 사전을 만들어놓고 random replace를 한 후에 관찰해볼거같아요
train시 unknown 토큰이 있는 게 regularization 기능을 할 수 있을지 궁금합니다! 또 entity에 unknown 토큰이 있을 때는 어떤 영향이 있을지 궁금합니다.
train 할 때 unknown 이 있는 것이 중요한 것이 학습과정에서 대체할 수 있는 능력을 기를 수 있음
entity 에 unknown 이 있으면 좋은 경우는 아니지만 test 에서도 그런 경우가 있을 수 있음
최근에 개체명인식기로 논문을 썼는데, bert류 모델들이 (놀랍게도) [unk] 랑 무관하게 잘 잡더라구요 -> [unk]는 2012년에 태어났다 -> [unk]:PS 로 잡더라구요 :-)
sentence 의 길이를 파악할 때는 tokenization 하기 전의 길이를 보는게 맞나요?
개인적으론 tokenization 하나의 결과를 본 뒤에 보는게 맞지 않나 싶음
한국어 전처리 관련된 많은 패키지들이 있는데, 다른 국가 언어도 섞여 있어서 그런지 적용했을 때 의도한 대로 출력되지 않는경우도 있었던 것 같은데, 사용하는게 좋을까요..?
case by case
TAPT(PPT 본문의 Domain Apaptation) 돌릴 때는 아무래도 모니터링할 매트릭이 없는데, 보통 loss가 어느 수준으로 떨어질 때까지 돌리는지 궁금합니다!
가장 좋은 metric 은 실제 downstream 에서 loss 를 보는게 제일 좋을 것 같긴 한데 그게 힘든 일이기도 하니까 validation 을 만들어서 사전학습 loss 가 안정화 될 때까지 해보는게 좋을 것 같음
validation 으로 downstream task 를 해서 loss 를 계산
fine-tuning에서 warm-up 쓰는게 맞나요?
안쓰는 걸 추천하고 크게 의미가 없
불용어를 따로 처리하는 것도 모델 학습에 도움이 될까요? 학습에 방해가 될 수도 있을 것 같아서 질문드립니다!
제거한 상태로 학습하면 모델이 학습할 때는 불용어가 없는 상태로 학습을 했는데 테스트를 할 때는 불용어가 들어있는 상태로 테스트를 진행하니까 좀
source에 따라 모델을 다르게 학습하는 것도 도움이 될까요?
source(wikitree, wikipedia, policy_briefing) 에 따라 하는건 새로운 방법인 것 같음
이어지는 질문인데요 보통 불용어를 제거한다면 train 과 test 전부 다 적용하지 않나요??
보통은 전처리하면 일관적으로 다 할 수도 있는데 대회의 경우에는 test set 이 가려져 있기 때문에
불용어를 제거 못함
잘 못 알고 계신듯
네 테스트셋을 전처리해서 모델이 인퍼 넣는건 매우 자연스러운거같구요
예를들어서 악성댓글 분류할때도 ‘ㅋㅋㅋㅋㅋㅋㅋ’ 이나 ‘ㅠㅠㅠㅠㅠㅠ’ 같은것도 전부 normalization한 후에 모델에 태우거든요
이루다나 심심이의 대답의 결과가 얼마나 좋은지를 평가하는 것은 어려운 일
정답과 비교하는 것이 의미가 별로 없고 대화모델을 어떻게 평가하는지 어려운 부분이 있는데
이런 부분에 대해서 연구하고 있음
댓글남기기