Day_37 [오피스아워] AI 신약 개발
작성일
[오피스아워] AI 신약개발 - 김준태
AI Drug Discovery
1.1 신약개발이란?

한국에서는 신약개발 하는 회사가 별로 없음
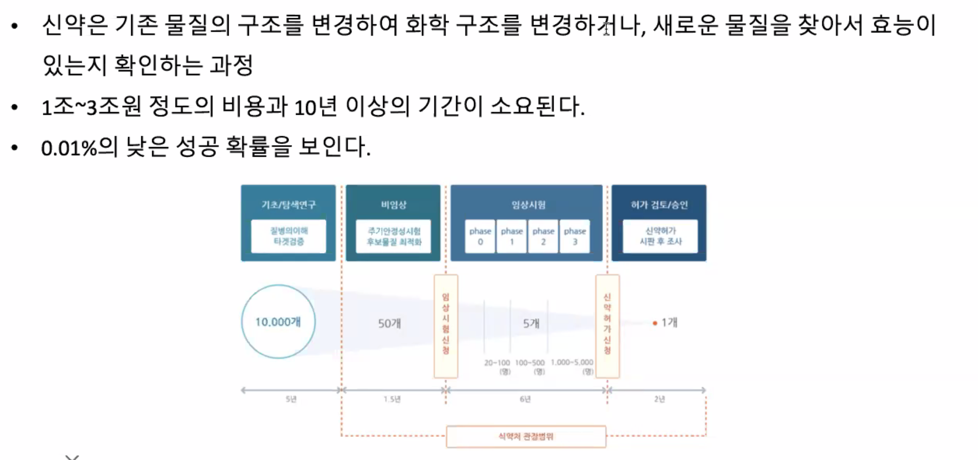
후보물질을 발견했으면 가볍게 무시하면 됨
시간도 많이 들고 비용도 많이 듦
임상에 갔다고 하면 어느정도 배팅할만하다고 생각하면 됨
1상까지는 대부분 통과하고 2, 3상에서 실패가 많이 나옴

효능이 있는 물질(Hit)이 다른 단백질에도 영향을 미치면 안되므로 최적화 과정에서 돈이 많이들고 시간도 많이 듦
인공지능과 신약개발
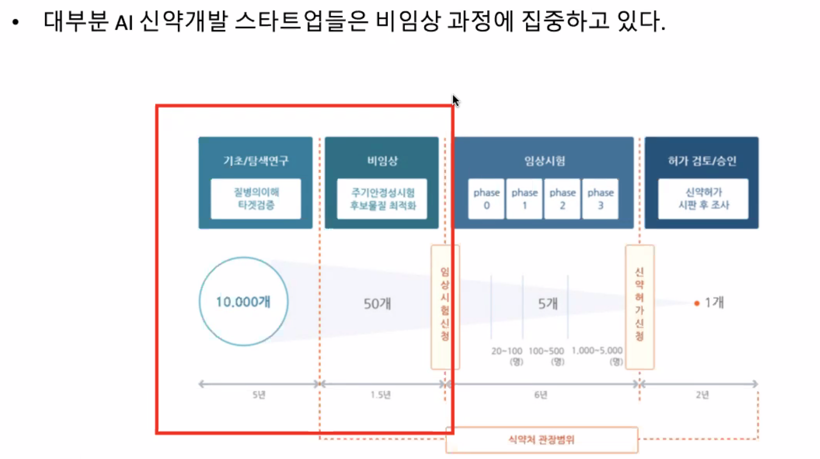
2 화학 데이터

이 데이터를 표현하는 방법도 다 다름
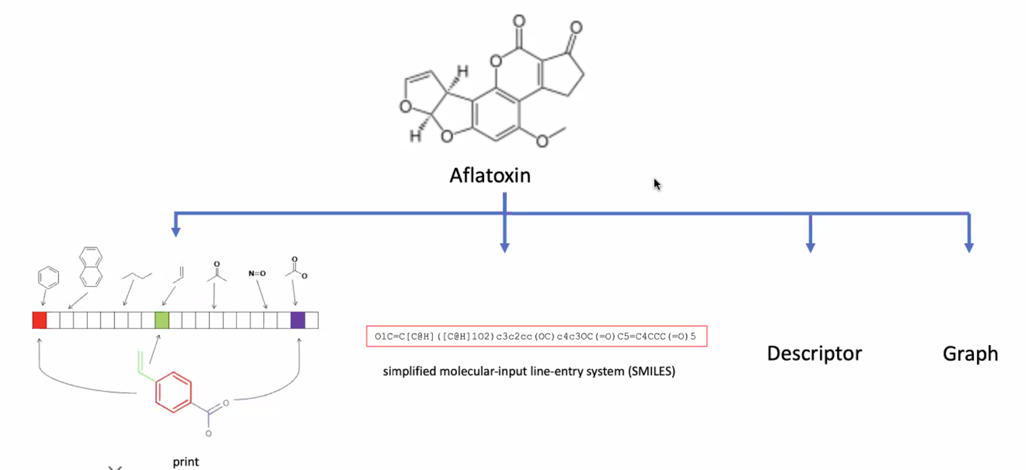
print 가 아니라 fingerprint
딥러닝이 뜨면서 분자구조를 Graph 로 처리하는 방법을 많이 사용함
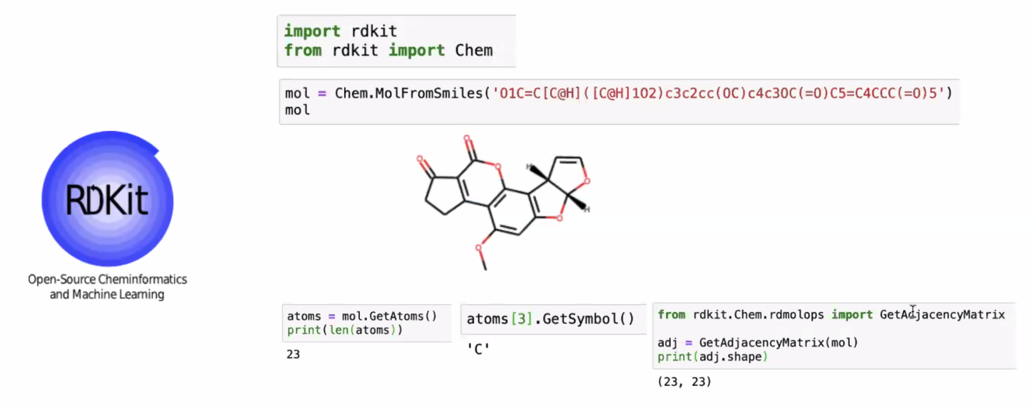
rdkit 이라는 라이브러리를 쓰면 SMILES 로 주어주면 분자구조를 쉽게 얻을 수 있음
신약개발하는 사람들은 대부분 rdkit 을 사용함
3 적용분야

Properties : 물성 (물질의 특성)
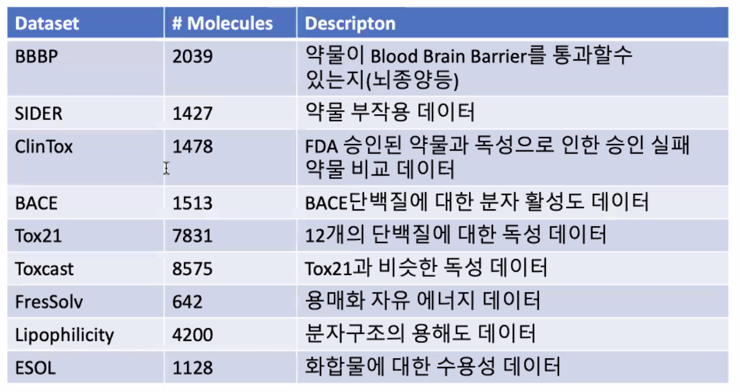
데이터셋들이 많지만 개수가 굉장히 적음
딥러닝이나 RandomForest 나 차이가 안나는 경우가 많음
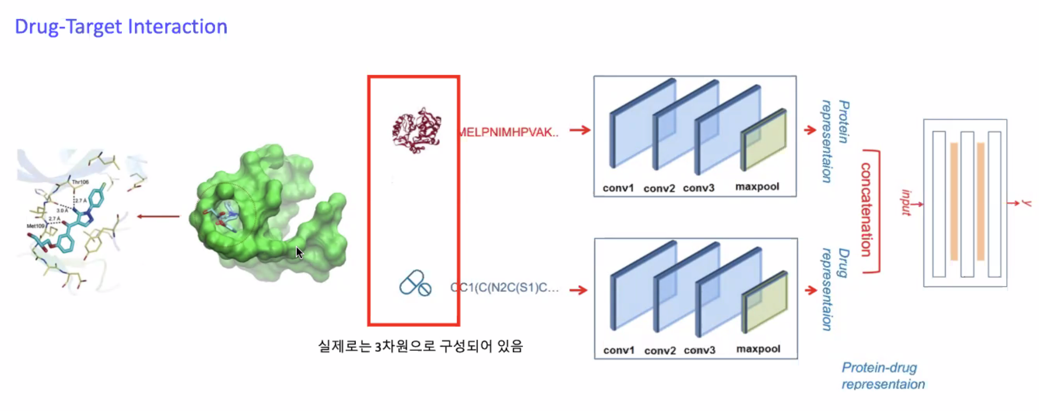
단백질이 어떠한 질병이 있다라는 것을 알고 이 단백질에 어떠한 구조가 활성도가 높은지를 알아야함
Task 가 Multimodal task 와 비슷함
분자구조와 단백질의 대한 서열정보(sequence) 이 2개의 데이터를 넣어서 representatoin 을 잘 조합해서 활성도를 예측하는 방법으로 처리
어떤 모델을 사용할 것인지, 2개의 정보를 어떻게 조합할것인지에 대한 연구가 많이 진행되고 있음
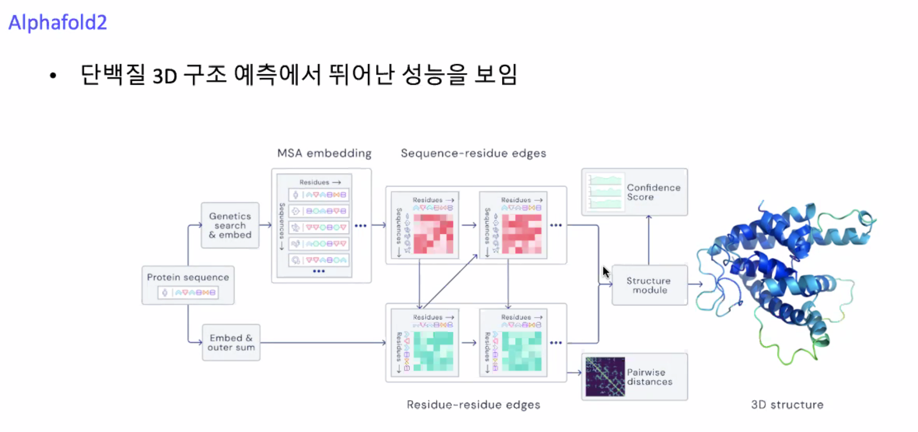
올해 Alphafold2 가 굉장히 떴는데 단백질 3D 구조 예측에서 뛰어난 성능을 보임
DeepMind 가 다 차이나게 SOTA 찍어버림
가장 돈이 되는 영역이 신약개발쪽이라서 DeepMind 가 이런일을 하지 않을까 싶음
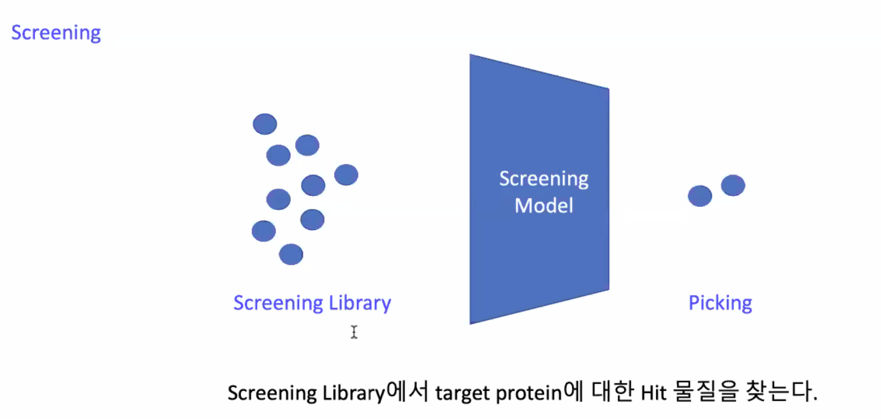
Screening Library : 이미 만들어진 1억개 이상의 분자구조가 있는데 어느 단백질에서 활성이 일어나는지 알 수 없음 그래서 1억개 중에 단어를 뽑아내서 예측을 해봄
보통 이 과정이 1~2년 걸리는데 딥러닝으로 된다면 1시간으로 가능할 듯
이건 꿈의 얘기고 실제로는 이렇게 되지 않음
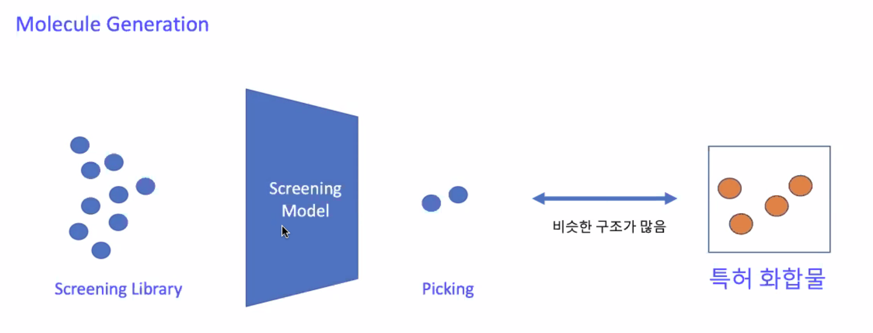
예측만 했을때 문제점이 뭐냐면 비슷한것만 예측을 잘 함
이미 나와있는 약과 비슷한 물질을 찾아내면 문제점은 특허에 걸려서 약이 될 수 없음
효능이 좋은 상태로 구조가 다른 물질을 생성하자라고 해서 Molecule Generation 을 하고 있음
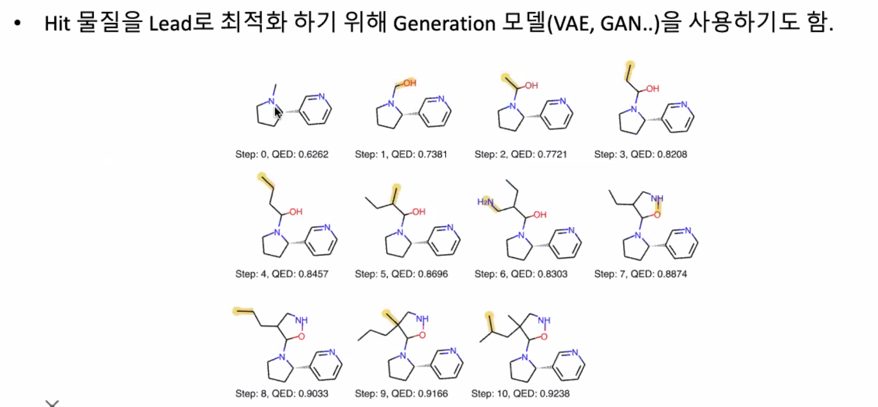
Hit 물질이 부작용을 일으킬 수 있으므로 최적화를 통해서 찾아낸 것이 Lead 물질임
Generation 모델을 통해 만들면 비슷한걸 만들 수 밖에 없어서 차이점을 만들어내는게 비즈니스 모델이 될 듯
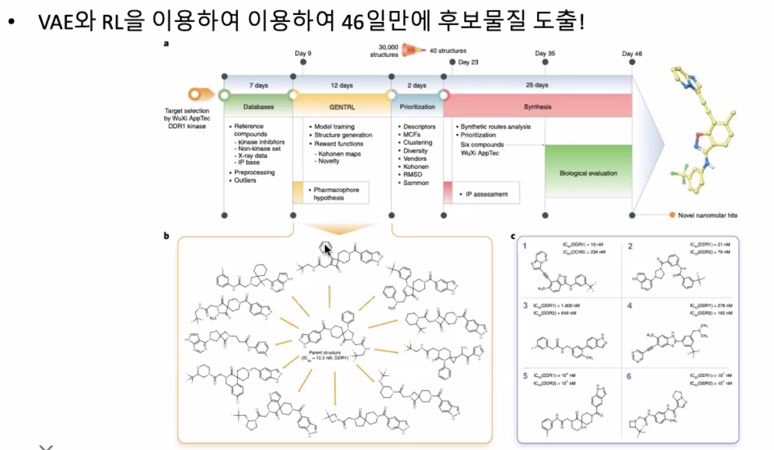
딥러닝이 무언가를 할 때마다 신약개발하는 사람들은 끝났다라고 얘기하지만 실제로는 임상에서 탈락
그렇지만 후보물질 찾는게 3년정도 걸리는데 후보물질 뽑아내는데 46일 밖에 안걸려서 어마어마한 결과를 낸 것임은 분명
몇백억을 아낄 수 있는 가능성
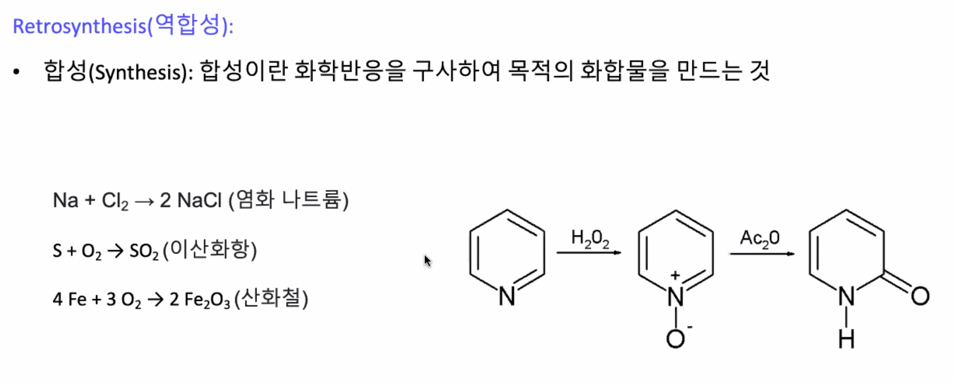
코로나의 분자구조를 만들려면 엄청 작은거부터 시작해서 합성을 하면서 만들어야 함
합성도 돈이 굉장히 많이 드는 영역임
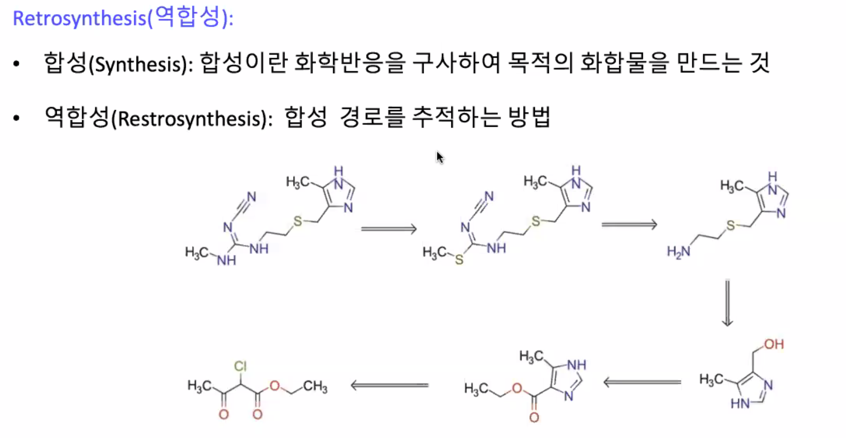
역합성의 대한 연구도 많이 진행되고 있음
합성이 어려우면 약이 되기가 어려움
합성 난이도 + 평소에 사용하지 않는 시약 사용 $\rightarrow$ 비용이 증가 (시장성 감소)
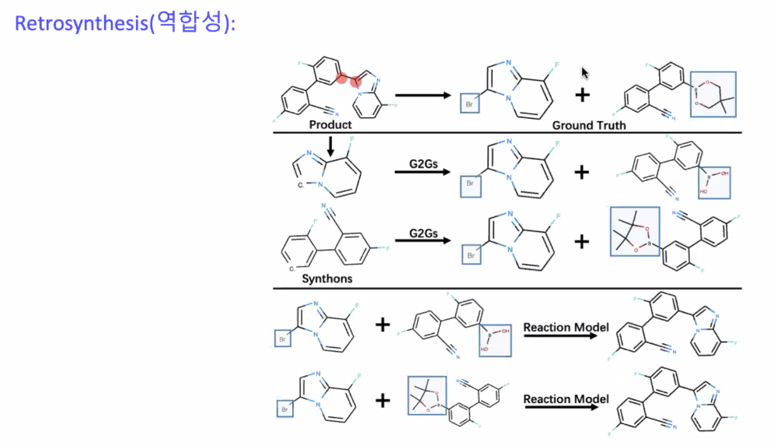
G2G 모델을 이용해서 연구 진행 중
이 연구가 갑자기 뜬 이유가 딥러닝 모델이 생성모델을 많이 사용하는데 딥러닝은 너무 희안한 구조를 많이 내놓음
그래서 합성이 안되는 경우도 굉장히 많음
4 왜 신약개발로?

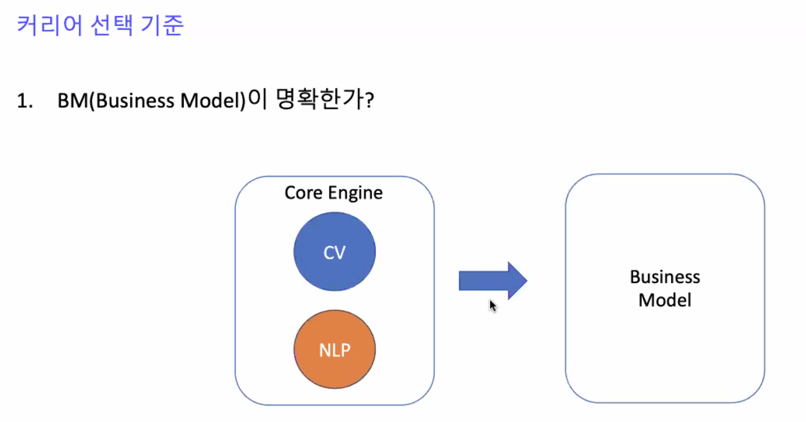
CV 과 NLP 너무 재밌지만 이 2가지로 할 수 있는게 굉장히 많은데 이 2가지를 가지고 비즈니스 모델을 만들기 굉장히 어려웠음
명확한 비즈니스를 찾기가 힘듦
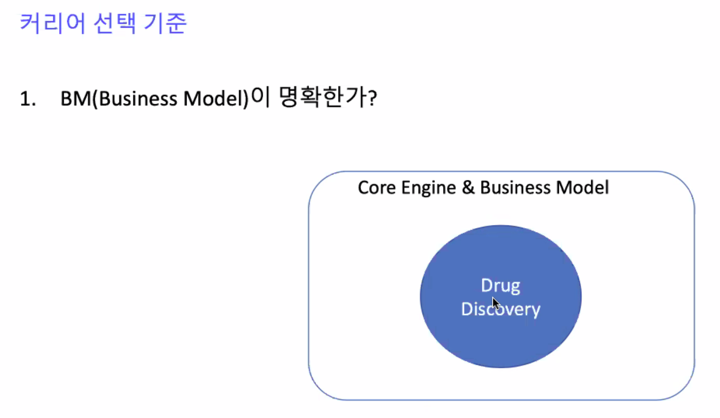
신약개발은 겹침 연구자체가 비즈니스임
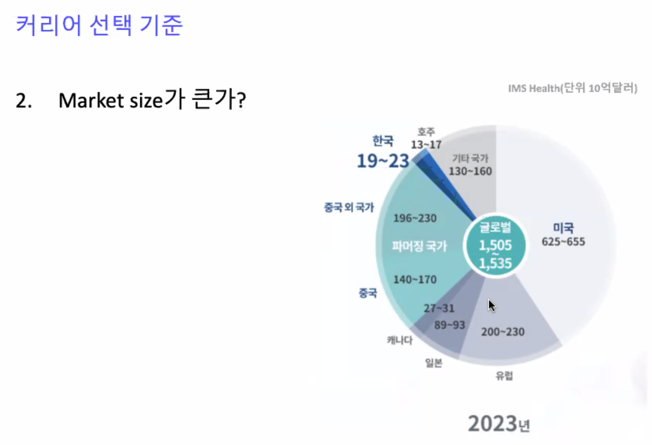
굉장히 큰 사이즈의 market size 에서 조금만 먹어도 많이 먹을 수 있음
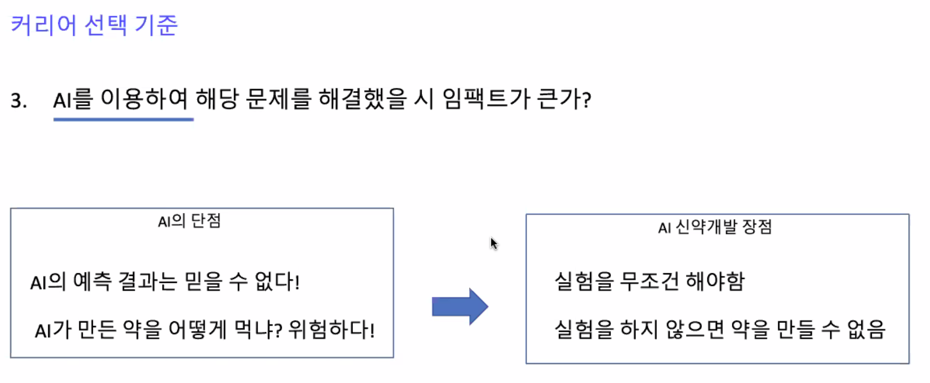
신약개발이 AI 를 도입하기 굉장히 좋은 영역임
신약개발의 장점이 AI 가 예측을 하더라도 실험을 무조건 해야함
결국엔 보는게 실험결과이기 때문에 실험결과가 AI 가 만든게 좋으면 AI 를 쓰면되고 아니면 안쓰면 됨
AI 를 이용하여 라는점이 중요

돈의 영역은 10년 이상의 과정 프로세스와 1조~3조가 들어가는 비용을 몇%라도 줄일 수 있으면 굉장히 효율적인 도구가 됨

사회적 문제를 해결할 수 있음
희귀병약은 비싼데 이런 약의 비용을 줄일 수 있으면 사회적 문제를 조금이라도 해결할 수 있지 않을까
신약개발을 하기 위해 AI 를 사용한다고 생각함
CV 영역의 AlexNet 단계랑 비슷한 듯
아직 VGG 나 ResNet 정도는 안된다고 생각함
CNN, GNN, Transformer, NLP 도 써보고 엄청 이것저것 도입하는 시점
Q&A
너무 마이너한 질문 아닐까 걱정이지만, 후보물질의 약효는 분자구조와 단백질의 상호작용을 예측하는 일이라고 이해했습니다. 단백질 구조는 3D 구조를 처리해야하는 작업이 있을 것 같습니다. 아직은 CV/NLP만 맛본 정도라 앞선 내용이 어떻게 처리되는지 잘 이해가 되지 않는데, 간단하게 설명해주실 수 있을까요?
외부 소프트웨어를 쓰면 3D 구조를 예측하는데 굉장히 오래걸려서 오픈되어있는 3D 구조를 많이 사용함
그게 아니라면 실제 실험을 해야함
다 돈을 쓰는 영역임
신약 개발??에 강화학습을 사용한다고 하신것 같은데요.. 그게 맞다면 보상 같은것은 어떻게 설정하고 실제 테스트는 어떤식으로 진행되는지 궁금합니다..!!
reward 로 예측모델을 많이 사용함
그래서 문제가 많이 있을 수 있음
단백질 예측은 그래프를 사용하는 gnn으로 하는 것으로 알고 있는데, 맞다면 마지막에 기술에 대한 평가가 gnn에 대한 평가인가요 아니면 단백질에 국한된 내용인가요
Isomer들은 구분을 어떻게 하나요
이걸 해결하는 뉴럴넷을 많이 사용함
약에 대해서는 딱히 구별은 안하는 것 같음
Isomer 구분은 쉽지가 않습니다. Isomer를 같이 학습하게 되면 난이도가 있어서 chirality 는 제거하고 학습을 하는 추세입니다.
현재 단계에서 내가 캠퍼라면 이것에 가장 집중할 것 같다?
이것저것 해야할게 많다고 생각될텐데 UpStage 과정이 잘 되어 있다고 생각하고 잘 이수하면서
가장 포인트를 맞춰야하는 거는 metric 보다는 어떻게 이 문제를 해결할 것인지에 집중하는게 중요함
데이터를 이것저것 바꿔보면서 가설을 세우고 이런 데이터를 봤을 때 이런 feature engineering 을 하면 잘 나올 것 같아 이런 가설들이나
가설을 사용한 이유에대해서 정리를 하면 실력향상이나 면접에서 도움이 될 거라고 생각
AI를통한 신약개발은 임상시험 전까지로 국한된다고 이해했는데요,, 사람이 아닌 AI가 후보물질을 발견했기 때문에 임상단계로 넘어가면서 윤리문제나 리스크가 생길 수 있을까요??
전혀 생기지 않음
무조건 실험을 해야함
실험을 한다는게 동물실험을해서 무조건 데이터를 만들어야 함
현재 computer 로 신약개발을 하는 분야는 예전부터 있던 분야라서 이 프로그램이 AI 로 바뀐것 뿐이라고 생각하면 됨
반려견 시장도 크다보니, 동물을 대상으로도 신약개발 분야가 있을 것 같은데, 시장이 별로 안큰가요?
한번도 생각하지 못한 영역인데 비즈니스 모델 감사합니다. ㅋㅋㅋㅋ
앞으로 캠퍼들이 어떤 공부나 준비를 하면 좋을지?
딥러닝은 결국에는 도메인과의 협업이므로 커뮤니케이션 스킬이나 시장분석
AI 하는 사람들이 연구에 집중을 하고 있어서 금액적인 부분을 좀 덜생각하는 것 같음
회사는 기본적으로 돈을 벌어야하는 집단이기에 금액적인 부분을 생각하는게 좋을 듯
사업분석, 시장분석, 이 분야에 AI 를 도입했을 때 비용 효율성을 얼마나 올릴 수 있을지? 이런 쪽의 공부를 하면 굉장히 많은 도움이 될 것 같음
시니어급의 분들을 만나면 이런 얘기를 많이 하심
혹시 커리어 선택 기준으로 골랐던것중에 다른후보들은 뭐가있었나요?
CV 와 NLP 를 절대 하지 않겠다
그래서 대학원때는 시계열 데이터를 다뤘음
주식이나 코인을 해서 부자가 되자라는 생각이 있었음
댓글남기기