Day_37 02. 자연어의 전처리
작성일
자연어의 전처리
1. 자연어 전처리
전처리
- 원시 데이터(raw data)를 기계 학습 모델이 학습하는데 적합하게 만드는 프로세스
- 학습에 사용될 데이터를 수집&가공 하는 모든 프로세스
전처리가 왜 필요한가요?
Task 의 성능을 가장 확실하게 올릴 수 있는 방법입니다!
모델을 아무리 바꾸고, 튜닝하더라도, 데이터 자체가 문제가 있다면 성능이 나올 수 없습니다.
가장 중요한 것은 데이터입니다.
단! 저작권에 유의하세요
$\rightarrow$ (특강 6강) 문지형 - 내가 만든 AI 모델은 합법일까, 불법일까)

1.1 자연어처리의 단계
-
Task 설계

-
필요 데이터 수집
- 통계학적 분석
- Token 개수 $\rightarrow$ 아웃라이어 제거
- 빈도 확인 $\rightarrow$ 사전(dictionary) 정의
- 전처리
- 개행문자 제거
- 특수문자 제거
- 공백 제거
- 중복 표현 제어 (ㅋㅋㅋㅋㅋ, ㅠㅠㅠㅠ, …)
- 이메일, 링크 제거
- 제목 제거
- 불용어 (의미가 없는 용어) 제거
- 조사 제거
- 띄어쓰기, 문장분리 보정
-
Tagging

- Tokenizing
- 자연어를 어떤 단위로 살펴볼 것인가
- 어절 tokenizing
- 형태소 tokenizing
- WordPiece tokenizing
- 자연어를 어떤 단위로 살펴볼 것인가
- 모델 설계
- 모델 구현
- 성능 평가
- 완료
그러나 Task 를 수행할 때 한번에 완벽하게 되는 경우는 없음

1.2 Python string 관련 함수
대소문자의 변환
| 함수 | 설명 |
|---|---|
| upper() | 모두 대문자로 변환 |
| lower() | 모두 소문자로 변환 |
| capitalize() | 문자열의 첫 문자를 대문자로 변환 |
| title() | 문자열에서 각 단어의 첫 문자를 대문자로 변환 |
| swapcase() | 대문자와 소문자를 서로 변환 |
편집, 치환
| 편집 | 치환 |
|---|---|
| strip() | 좌우 공백을 제거 |
| rstrip() | 오른쪽 공백을 제거 |
| lstrip() | 왼쪽 공백을 제거 |
| replace(a, b) | a를 b로 치환 |
분리, 결합
| 함수 | 설명 |
|---|---|
| split() | 공백으로 분리 |
| split(‘\t’) | 탭을 기준으로 분리 |
| ’‘.join(s) | 리스트 s에 대하여 각 요소 사이에 공백을 두고 결합 |
| lines.splitlines() | 라인 단위로 분리 |
구성 문자열 판별
| 함수 | 설명 |
|---|---|
| isdigit() | 숫자 여부 판별 |
| isalpha() | 영어 알파벳 여부 판별 |
| isalnum() | 숫자 혹은 영어 알파벳 여부 판별 |
| islower() | 소문자 여부 판별 |
| isupper() | 대문자 여부 판별 |
| isspace() | 공백 문자 여부 판별 |
| startswith(‘hi’) | 문자열이 hi로 시작하는지 여부 파악 |
| endswith(‘hi’) | 문자열이 hi로 끝나는지 여부 파악 |
검색
| 함수 | 설명 |
|---|---|
| count(‘hi’) | 문자열에서 hi가 출현한 빈도 리턴 |
| find(‘hi’) | 문자열에서 hi가 처음으로 출현한 위치 리턴, 존재하지 않는 경우 -1 |
| find(‘hi’, 3) | 문자열의 index 에서 3번부터 hi 가 출현한 위치 검색 |
| rfind(‘hi’) | 문자열에서 오른쪽부터 검사하여 hi 가 처음으로 출현한 위치 리턴, 존재하지 않는 경우 -1 |
| index(‘hi’) | find 와 비슷한 기능을 하지만 존재하지 않는 경우 예외발생 |
| rindex(‘hi’) | rfind 와 비슷한 기능을 하지만 존재하지 않는 경우 예외발생 |
2. 한국어 토큰화
2.1 한국어 토큰화
토큰화(Tokenizing)
- 주어진 데이터를 토큰(Token)이라 불리는 단위로 나누는 작업
- 토큰이 되는 기준은 다를 수 있음(어절, 단어, 형태소, 음절, 자소 등)
문장 토큰화(Sentence Tokenizing)
- 문장 분리
단어 토큰화(Word Tokenizing)
- 구두점 분리, 단어 분리
“Hello, World!” $\rightarrow$ “Hello”, “,”, “World”, “!”
한국어 토큰화
- 영어는 New York 과 같은 합성어 처리와 it’s 와 같은 줄임말 예외처리만 하면, 띄어쓰기를 기준으로도 잘 동작하는 편
- 한국어는 조사나 어미를 붙여서 말을 만드는 교착어로, 띄어쓰기만으로는 부족
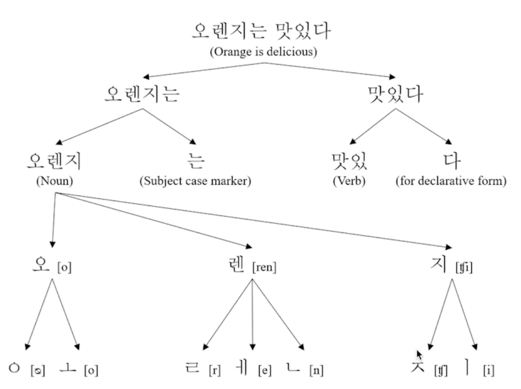
예시) he/gim $\rightarrow$ 그, 그가, 그는, 그를, 그에게 - 한국어에서는 어절이 의미를 가지는 최소 단위인 형태로소 분리
예시) 안녕하세요 $\rightarrow$ 안녕/NNG, 하/XSA, 세/EP, 요/EC
실습 - 한국어 전처리
1. 데이터 수집
newspaper 라이브러리는 url 만 입력하게되면 제목과 content 를 자동으로 분리를 해서 news 기사를 크롤링해줌
!pip install newspaper3k
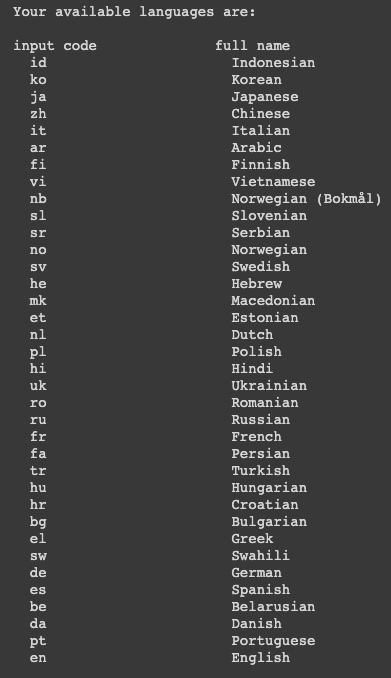
newspaper 라이브러리에서 제공하는 언어 list 를 볼 수 있음
ko korean 한국어도 제공
import newspaper
newspaper.languages()
일반적으로 뉴 기사의 경우, 재배포 수집 자체가 저작권에 굉장히 민감함
이번 실습에서는 저작권에서 비교적 자유로운 위키트리 뉴스 데이터를 사용하도록 함
news_url = "https://www.wikitree.co.kr/articles/692045"
from newspaper import Article
article = Article(news_url, language='ko')
article.download()
article.parse()
print('title:', article.title)
print('context:', article.text)

context 가 좀 더러우므로 이런 요소들을 깨끗하게 제거하는 것을 실습하려함
일반적으로 뉴스기사를 긁어오게되면 많이 존재하는 그런 데이터들도 추가함
context = article.text.split('\n')
context.append("<h1>여기에 태그가 있네요!</h1> <h3>이곳에도 태그가 있구요</h3> html은 <b>태그</b>로 이루어진 문서입니다. 텍스트를 <b>진하게</b> 만들 수도 있고, <u>밑줄</u>을 칠 수도 있습니다. ‘<br>이 줄은 실제 뉴스(news,)에 포함되지 않은 임시 데이터임을 알립니다…<br>‘")
context.append("(서울=위키트리) 손희락 기자 (jfhdzzang@gmail.com) <저작권자(c) 무단전재-재배포 금지> ‘<br>이 줄은 실제 뉴스(news,)에 포함되지 않은 임시 데이터임을 알립니다…<br>‘")
context.append("(사진=위키트리, 무단 전재-재배포 금지) ‘<br>이 줄은 실제 뉴스(news,)에 포함되지 않은 임시 데이터임을 알립니다…<br>‘")
context.append("#노제 #스우파 #댄서 #노마스크 #논란")
for i, sent in enumerate(context):
print(i, sent)

2. 데이터 전처리
2.1 HTML 제거
HTML 을 제거하는 방법중에 하나는 정규표현식 사용
impor tre
def remove_html(texts):
"""
HTML 태그를 제거합니다.
``<p>안녕하세요 ㅎㅎ </p>`` -> ``안녕하세요 ㅎㅎ ``
"""
preprocessed_text = []
for text in texts:
text = re.sub(r"<[^>]+>\s+(?=<)|<[^>]+>", "", text).strip()
if text:
preprocessed_text.append(text)
return preprocessed_text

2.2 문장 분리
한국어 문장분리기 중, 가장 성능이 우수한 것으로 알려진 [kss 라이브러리] 를(https://github.com/hyunwoongko/kss) 사용하도록 하겠음
!pip install kss
import kss
sents = []
for sent in context:
sent = sent.strip()
if sent:
splited_sent = kss.split_sentence(sent)
sents.extend(splited_sent)
for i, sent in enumerate(sents):
print(i, sent)

2.3 Normalizing
이메일은 개인정보이므로 반드시 제거해줘야 함
def remove_email(texts):
"""
이메일을 제거합니다.
``홍길동 abc@gmail.com 연락주세요!`` -> ``홍길동 연락주세요!``
"""
preprocessed_text = []
for text in texts:
text = re.sub(r"[a-zA-Z0-9+-_.]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+", "", text).strip()
if text:
preprocessed_text.append(text)
return preprocessed_text

제가 작성했던 email 이 사라졌음
해시태그(#~)들도 제거해줌
def remove_hashtag(texts):
"""
해쉬태그(#)를 제거합니다.
``대박! #맛집 #JMT`` -> ``대박! ``
"""
preprocessed_text = []
for text in texts:
text = re.sub(r"#\S+", "", text).strip()
if text:
preprocessed_text.append(text)
return preprocessed_text
sents = remove_hashtag(sents)
for i, sent in enumerate(sents):
print(i, sent)

여기선 나오지 않았지만 @~ 로 이루어진 멘션에 쓰이는 태깅정보들도 개인정보가 될 수 있으므로 제거해야 함
def remove_user_mention(texts):
"""
유저에 대한 멘션(@) 태그를 제거합니다.
``@홍길동 감사합니다!`` -> `` 감사합니다!``
"""
preprocessed_text = []
for text in texts:
text = re.sub(r"@\w+", "", text).strip()
if text:
preprocessed_text.append(text)
return preprocessed_text
sents = remove_user_mention(sents)
for i, sent in enumerate(sents):
print(i, sent)

자연어 입장에서 url 정보 역시 개인정보 혹은 우리가 가져오면 안되는 중요한 주소를 포함한다거나 할 수 있음
그래서 주소도 제거해줌
def remove_url(texts):
"""
URL을 제거합니다.
``주소: www.naver.com`` -> ``주소: ``
"""
preprocessed_text = []
for text in texts:
text = re.sub(r"(http|https)?:\/\/\S+\b|www\.(\w+\.)+\S*", "", text).strip()
text = re.sub(r"pic\.(\w+\.)+\S*", "", text).strip()
if text:
preprocessed_text.append(text)
return preprocessed_text
sents = remove_url(sents)
for i, sent in enumerate(sents):
print(i, sent)

가끔 한국어 데이터를 크롤링 하게되면 알 수 없는 기호들이 같이 들어올 때가 있음
이런 애들은 나중에 모델에 입력하게 되거나 vocab 을 생성하거나 할 때 항상 error 를 만들어 낼 수 있음
왜냐면 UTF-8 로 읽히지 않는다거나 하는 문제점이 생길때가 있음
그래서 이런 값들은 크롤링을 하고나면 일차적으로 반드시 제거해줌
def remove_bad_char(texts):
"""
문제를 일으킬 수 있는 문자들을 제거합니다.
"""
bad_chars = {"\u200b": "", "…": " ... ", "\ufeff": ""}
preprcessed_text = []
for text in texts:
for bad_char in bad_chars:
text = text.replace(bad_char, bad_chars[bad_char])
text = re.sub(r"[\+á?\xc3\xa1]", "", text)
if text:
preprcessed_text.append(text)
return preprcessed_text
sents = remove_bad_char(sents)
for i, sent in enumerate(sents):
print(i, sent)

그 다음엔 기자 정보 or 언론사 정보를 제거해줌
def remove_press(texts):
"""
언론 정보를 제거합니다.
``홍길동 기자 (연합뉴스)`` -> ````
``(이스탄불=연합뉴스) 하채림 특파원 -> ````
"""
re_patterns = [
r"\([^(]*?(뉴스|경제|일보|미디어|데일리|한겨례|타임즈|위키트리)\)",
r"[가-힣]{0,4} (기자|선임기자|수습기자|특파원|객원기자|논설고문|통신원|연구소장) ", # 이름 + 기자
r"[가-힣]{1,}(뉴스|경제|일보|미디어|데일리|한겨례|타임|위키트리)", # (https://raki-1203.github.io. 연합뉴스) ..
r"\(\s+\)", # ( )
r"\(=\s+\)", # (= )
r"\(\s+=\)", # ( =)
]
preprocessed_text = []
for text in texts:
for re_pattern in re_patterns:
text = re.sub(re_pattern, "", text).strip()
if text:
preprocessed_text.append(text)
return preprocessed_text
sents = remove_press(sents)
for i, sent in enumerate(sents):
print(i, sent)

copyright 관련 정보도 삭제해줌
def remove_copyright(texts):
"""
뉴스 내 포함된 저작권 관련 텍스트를 제거합니다.
``(사진=저작권자(c) 연합뉴스, 무단 전재-재배포 금지)`` -> ``(사진= 연합뉴스, 무단 전재-재배포 금지)`` TODO 수정할 것
"""
re_patterns = [
r"\<저작권자(\(c\)|ⓒ|©|\(Copyright\)|(\(c\))|(\(C\))).+?\>",
r"저작권자\(c\)|ⓒ|©|(Copyright)|(\(c\))|(\(C\))"
]
preprocessed_text = []
for text in texts:
for re_pattern in re_patterns:
text = re.sub(re_pattern, "", text).strip()
if text:
preprocessed_text.append(text)
return preprocessed_text
sents = remove_copyright(sents)
for i, sent in enumerate(sents):
print(i, sent)

사진, 출처 표시 제거해줌
def remove_photo_info(texts):
"""
뉴스 내 포함된 이미지에 대한 label을 제거합니다.
``(사진= 연합뉴스, 무단 전재-재배포 금지)`` -> ````
``(출처=청주시)`` -> ````
"""
preprocessed_text = []
for text in texts:
text = re.sub(r"\(출처 ?= ?.+\) |\(사진 ?= ?.+\) |\(자료 ?= ?.+\)| \(자료사진\) |사진=.+기자 ", "", text).strip()
if text:
preprocessed_text.append(text)
return preprocessed_text
sents = remove_photo_info(sents)
for i, sent in enumerate(sents):
print(i, sent)

의미없는 정보를 포함하고 있는 괄호는 통채로 지우고 정보가 포함되어 있다면 strict 하게 만들어 줌
def remove_useless_breacket(texts):
"""
위키피디아 전처리를 위한 함수입니다.
괄호 내부에 의미가 없는 정보를 제거합니다.
아무런 정보를 포함하고 있지 않다면, 괄호를 통채로 제거합니다.
``수학(,)`` -> ``수학``
``수학(數學,) -> ``수학(數學)``
"""
bracket_pattern = re.compile(r"\((.*?)\)")
preprocessed_text = []
for text in texts:
modi_text = ""
text = text.replace("()", "") # 수학() -> 수학
brackets = bracket_pattern.search(text)
if not brackets:
if text:
preprocessed_text.append(text)
continue
replace_brackets = {}
# key: 원본 문장에서 고쳐야하는 index, value: 고쳐져야 하는 값
# e.g. {'2,8': '(數學)','34,37': ''}
while brackets:
index_key = str(brackets.start()) + "," + str(brackets.end())
bracket = text[brackets.start() + 1 : brackets.end() - 1]
infos = bracket.split(",")
modi_infos = []
for info in infos:
info = info.strip()
if len(info) > 0:
modi_infos.append(info)
if len(modi_infos) > 0:
replace_brackets[index_key] = "(" + ", ".join(modi_infos) + ")"
else:
replace_brackets[index_key] = ""
brackets = bracket_pattern.search(text, brackets.start() + 1)
end_index = 0
for index_key in replace_brackets.keys():
start_index = int(index_key.split(",")[0])
modi_text += text[end_index:start_index]
modi_text += replace_brackets[index_key]
end_index = int(index_key.split(",")[1])
modi_text += text[end_index:]
modi_text = modi_text.strip()
if modi_text:
preprocessed_text.append(modi_text)
return preprocessed_text
sents = remove_useless_breacket(sents)
for i, sent in enumerate(sents):
print(i, sent)

이 기사 내용엔 없지만 ㅋㅋㅋㅋㅋㅋㅋ 이라는 표현이 있는 경우 모델입장에서 학습을 할 때 ㅋ 하나 짜리와 ㅋ 두개짜리 또
세개짜리 이런 것들 전부다 다르게 학습을 할 수 있음 그래서 이걸 전부 Normalization(일반화) 과정을 거침
한국에서 일반화를 할 때 가장 쉽게 쓸 수 있는 라이브러리가 soynlp 라는 라이브러리임
!pip install soynlp
함수 중에 repeat_normalize() 함수가 있음 num_repeats 파라미터로 반복되는 것을 몇개까지 허용할지를 정할 수 있음
from soynlp.normalizer import *
print(repeat_normalize('와하하하하하하하하하핫', num_repeats=4))
만약 num_repeats=4 로 설정하면

하 가 4번 반복하는 것을 알 수 있음
만약 num_repeats=1 로 설정하면
from soynlp.normalizer import *
print(repeat_normalize('와하하하하하하하하하핫', num_repeats=1))

하 가 한번만 나옴
그런데 num_repeats=1 로 설정하면 실제로 동일한 음절이 반복되는 단어라면 문제가 생길 수 있음
그래서 2개로 설정했음
def remove_repeat_char(texts):
preprocessed_text = []
for text in texts:
text = repeat_normalize(text, num_repeats=2).strip()
if text:
preprocessed_text.append(text)
return preprocessed_text
sents = remove_repeat_char(sents)
for i, sent in enumerate(sents):
print(i, sent)

다른 문서를 크롤링 할 때 혹은 리뷰를 크롤링할 때 매우 유용할 듯
다음은 기호들을 일반화하는 과정이 필요함
뉴스를 수집하면 기자들이 인용된 말을 표현할 때 기자들이 자신만의 기준으로 기호를 사용할 수 있음
이런 기호들도 중구난방으로 될 수 있으니 하나로 통일을 해줘야 함
왜냐하면 모델 입장에선 이것들 전부다를 다른 단어로 받아들일 수 있으므로
기호들을 punctuation 이라고 부르는데 이런 기호들을 통일
def clean_punc(texts):
punct_mapping = {"‘": "'", "₹": "e", "´": "'", "°": "", "€": "e", "™": "tm", "√": " sqrt ", "×": "x", "²": "2", "—": "-", "–": "-", "’": "'", "_": "-", "`": "'", '“': '"', '”': '"', '“': '"', "£": "e", '∞': 'infinity', 'θ': 'theta', '÷': '/', 'α': 'alpha', '•': '.', 'à': 'a', '−': '-', 'β': 'beta', '∅': '', '³': '3', 'π': 'pi', }
preprocessed_text = []
for text in texts:
for p in punct_mapping:
text = text.replace(p, punct_mapping[p])
text = text.strip()
if text:
preprocessed_text.append(text)
return preprocessed_text
sents = clean_punc(sents)
for i, sent in enumerate(sents):
print(i, sent)

이렇게 처리를 많이 하다보면 이중 space 가 나올 수 있음
반복된 space 도 하나로 치환하는 과정을 거쳐야 함
def remove_repeated_spacing(texts):
"""
두 개 이상의 연속된 공백을 하나로 치환합니다.
``오늘은 날씨가 좋다.`` -> ``오늘은 날씨가 좋다.``
"""
preprocessed_text = []
for text in texts:
text = re.sub(r"\s+", " ", text).strip()
if text:
preprocessed_text.append(text)
return preprocessed_text
sents = remove_repeated_spacing(sents)
for i, sent in enumerate(sents):
print(i, sent)

중복되는 문장을 학습하는 것도 원치 않으니 중복되는 데이터도 제거해줌
OrderedDict 의 fromkeys 로 만들어주면은 입력된 순서대로 중복을 제거해서 list 로 다시 만들어줌
from collections import OrderedDict
def remove_dup_sent(texts):
"""
중복된 문장을 제거합니다.
"""
texts = list(OrderedDict.fromkeys(texts))
return texts
sents = remove_dup_sent(sents)
for i, sent in enumerate(sents):
print(i, sent)

다음은 필수과정은 아니지만 띄어쓰기 보정을 해줘야 할 때가 있음
예를 들면 크롤링을 했는데 모든 데이터가 띄어쓰기가 하나도 없이 붙어있는 경우가 있을 수 있음
이런경우에는 문장을 띄어쓰기 단위로 split 을 하고 그 split 된 수가 너무 적으면 그 문장을 날리던가 띄어쓰기 보정을 해줘야 함
띄어쓰기 보정을 하는 방법은 실제로 규칙이 굉장히 다양해서 어려움
제안하는 방법은 KoSpacing 이라는 라이브러리를 사용
!pip install git+https://github.com/haven-jeon/PyKoSpacing.git
예제를 보면
from pykospacing import Spacing
spacing = Spacing()
spacing("김형호영화시장분석가는'1987'의네이버영화정보네티즌10점평에서언급된단어들을지난해12월27일부터올해1월10일까지통계프로그램R과KoNLP패키지로텍스트마이닝하여분석했다.")

띄어쓰기가 되지 않은 text 가 자동으로 띄어쓰기가 됨
생각보다 잘 되는 것을 볼 수 있음
이 부분을 필수요소라고 하지 않은 것이 결과를 보면 확인할 수 있음
def spacing_sent(texts):
"""
띄어쓰기를 보정합니다.
"""
preprocessed_text = []
for text in texts:
text = spacing(text)
if text:
preprocessed_text.append(text)
return preprocessed_text
sents_ = spacing_sent(sents)
for i, sent in enumerate(sents_):
print(i, sent)

마지막 줄에 알립니다 $\rightarrow$ 알립니 다 처럼 옳지 않게 분리되는 경우가 있음
띄어쓰기 모듈을 사용할 때는 정말로 다 붙어있어서 띄어쓰기가 존재하지 않거나 혹은 띄어쓰기가 너무 적을 때 모듈에 태워서 보정을
해줄 수가 있는데 일반적으로 뉴스 기사 같은 경우에는 기자가 문법적으로 오탈자 없이 많이 쓰려고 노력한 문서이기 때문에 이렇게
굳이 Spacing 모듈을 안써도 괜찮음
맞춤법 검사기도 테스트 해보자
추천하는 라이브러리는 hanspell 라이브러리 임
!pip install git+https://github.com/ssut/py-hanspell.git
예제를 보자
from hanspell import spell_checker
sent = "대체 왜 않돼는지 설명을 해바"
spelled_sent = spell_checker.check(sent)
print(spelled_sent)
checked_sent = spelled_sent.checked
print(checked_sent)

spell_checker.check() 를 통해 맞춤법 검사 가능
블로그나 트위터를 크롤링 할때는 반드시 이런것을 거쳐야 하지만 뉴스 기사 같은 경우에는 거치지 않아도 괜찮음
모델이 기계학습 기반 모델이기 때문에 성능이 100%라고 보장할 수 없음
그러면 오히려 올바르게 만들어진 것을 틀리게 고쳐낼 수 도 있음
이런 것들을 방지하기 위해 뉴스 기사에서는 안써도 상관 없음
def spell_check_sent(texts):
"""
맞춤법을 보정합니다.
"""
preprocessed_text = []
for text in texts:
try:
spelled_sent = spell_checker.check(text)
checked_sent = spelled_sent.checked
if checked_sent:
preprocessed_text.append(checked_sent)
except:
preprocessed_text.append(text)
return preprocessed_text
sents_ = spell_check_sent(sents)
for i, sent in enumerate(sents_):
print(i, sent)

필터링의 끝판왕!
형태소 분석 기반 필터링을 테스트하기 위해 한국어 형태소 분석기를 설치
이것을 사용하면 쓸모없는 문장은 왠만하면 다 날라감
어떤 원리로 동작하는지 알아보자
목적은 이런 애들을 날리고 싶음

그런데 이런 애들은 영어를 날린다면 말이 안됨 왜냐하면 Mnet 이런 애들도 남아 있을 수 있으니까
음… 그러면 한국어가 포함안된거? 이것도 잘 못됐을 것 같음 왜냐하면 문장내에 영어만 있는 경우도 있을 테니까
그래서 이런 요소들은 필터링을 하기에 규칙을 정하는게 굉장히 어려움
그래서 만든게 형태소 기반의 필터링임
빠르고 성능 좋은 mecab 을 설치하자
!pip install konlpy
!bash <(curl -s https://raw.githubusercontent.com/konlpy/konlpy/master/scripts/mecab.sh)
예제를 보자
from konlpy.tag import Mecab
mecab = Mecab()
morphs = mecab.pos("아버지가방에들어가신다.", join=False)
print(morphs)

mecab 이라는 라이브러리를 사용하려면 konlpy.tag 에서 Mecab 을 불러와서 Mecab() 클래스를 정의해주고
형태소 pos(part of speech) 를 부착해주면 형태소 분석이 잘 되는 것을 확인할 수 있음
- NN : 명사 관련
- J : 조사 관련
- V : 동사 관련
2.4 Filtering
필터링하고 싶은 규칙은 문장 내에 반드시 명사, 동사, 형용사 이 3가지 형태소가 들어가 있어야 함
이게 없으면 한국어에서는 완성된 문장이 아닐 수 있음
def morph_filter(texts):
"""
명사(NN), 동사(V), 형용사(J)의 포함 여부에 따라 문장 필터링
"""
NN_TAGS = ["NNG", "NNP", "NNB", "NP"]
V_TAGS = ["VV", "VA", "VX", "VCP", "VCN", "XSN", "XSA", "XSV"]
J_TAGS = ["JKS", "J", "JO", "JK", "JKC", "JKG", "JKB", "JKV", "JKQ", "JX", "JC", "JKI", "JKO", "JKM", "ETM"]
preprocessed_text = []
for text in texts:
morphs = mecab.pos(text, join=False)
nn_flag = False
v_flag = False
j_flag = False
for morph in morphs:
pos_tags = morph[1].split("+")
for pos_tag in pos_tags:
if not nn_flag and pos_tag in NN_TAGS:
nn_flag = True
if not v_flag and pos_tag in V_TAGS:
v_flag = True
if not j_flag and pos_tag in J_TAGS:
j_flag = True
if nn_flag and v_flag and j_flag:
preprocessed_text.append(text)
break
return preprocessed_text
sents = morph_filter(sents)
for i, sent in enumerate(sents):
print(i, sent)

한국어의 문법적 특징을 포함하는 문장만 남게 됨
다음으로는 특정 단어를 포함하는 문장을 필터링하는 필터링 기술임
이하 뉴스1 or 임의로 추가 했던 이 줄은 실제 뉴스~~ 이런 데이터들, 즉, 특정 단어들을 포함하고 있는 문장을 날려주겠음
def excluded_word_filter(excluded_words, texts):
"""
특정 단어를 포함하는 문장 필터링
"""
preprocessed_text = []
for text in texts:
include_flag = False
for word in excluded_words:
if word in text:
include_flag = True
break
if not include_flag:
preprocessed_text.append(text)
return preprocessed_text
excluded_words = ["이하 뉴스1", "이 줄은 실제 뉴스"]
sents = excluded_word_filter(excluded_words, sents)
for i, sent in enumerate(sents):
print(i, sent)

다음으로는 의미가 없는 불용어들을 삭제해줌
보통 데이터를 보고 직접 의미가 없는 단어들을 선택해서 stopwords 리스트에 넣어줌
def remove_stopwords(sents):
# 큰 의미가 없는 불용어 정의
stopwords = ['소취요', '-', '조드윅', '포스터', '앓는', '서린']
preprocessed_text = []
for sent in sents:
sent = [w for w in sent.split(' ') if w not in stopwords]# 불용어 제거
preprocessed_text.append(' '.join(sent))
return preprocessed_text
sents_ = remove_stopwords(sents)
for i, sent in enumerate(sents_):
print(i, sent)

다음으로는 outlier 에 대한 제거를 해줌
문장을 최대, 최소 길이로 필터링해줌
def min_max_filter(min_len, max_len, texts):
"""
문장을 최대, 최소 길이로 필터링합니다.
"""
preprocessed_text = []
for text in texts:
if min_len < len(text) and len(text) < max_len:
preprocessed_text.append(text)
return preprocessed_text
sents_ = min_max_filter(min_len=5, max_len=70, texts=sents)
for i, sent in enumerate(sents_):
print(i, sent)

추가로 넣었던 문장을 제외하고는 정상적인 문장만 남은 것을 확인할 수 있음
2.5 유니코드 기반으로 filtering
예로 보여주고 싶은 것은 데이터내에서 특정한 언어를 삭제하는 것
예를 들어 학습을 할 때, 러시아어, 아랍어 이런 애들이 데이터에 포함되어 있다고 한들 한국어 모델을 학습하는데 굳이 사용하고
싶지 않음
이럴때 특정한 언어를 삭제하는 것을 유니코드 기반으로 만들 수 있음
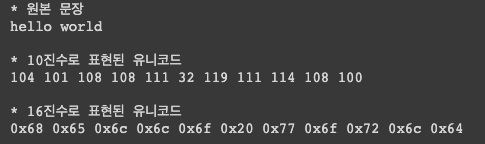
sentence = 'hello world'
print('* 원본 문장')
print(sentence)
print('\n* 10진수로 표현된 유니코드')
for w in sentence:
print(ord(w), end=' ') # 문자 -> 10진수 변환
print('\n\n* 16진수로 표현된 유니코드')
for w in sentence:
print(hex(ord(w)), end=' ') # 문자 -> 16진수 변환
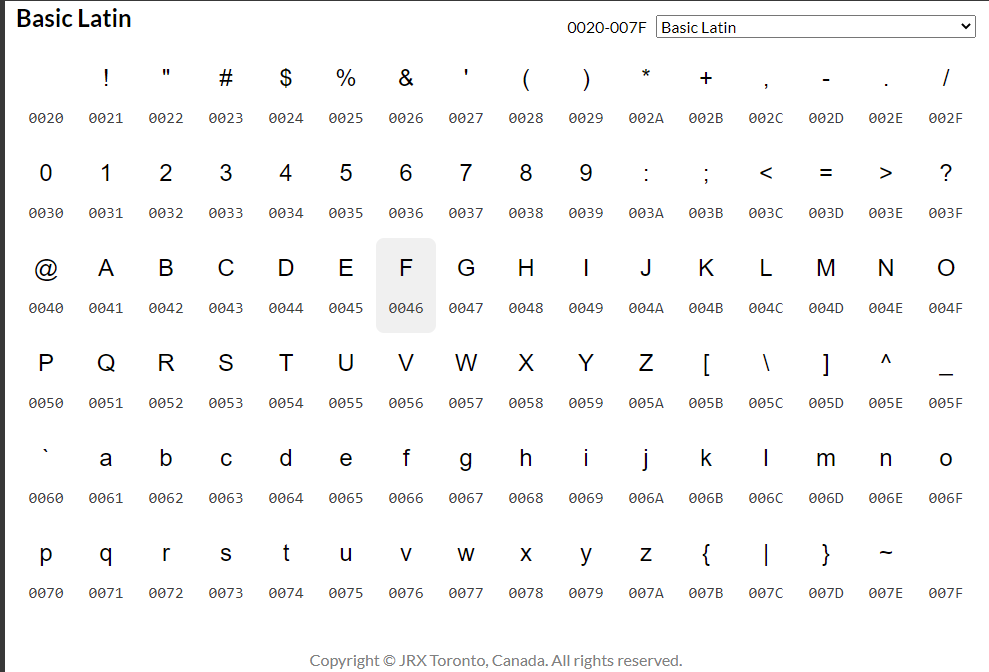
유니코드 표에 따르면 문자별로 범위가 존재함
range_s = int('0370',16) # 그리스 문자 유니코드 범위
range_e = int('03FF',16) # 16진수 -> 10진수 변환
for i in range(range_s, range_e + 1): #
print(chr(i), end=' ')

유니코드는 순서를 가지기 때문에 범위를 가지게 됨
def remove_language(range_s, range_e, sentence):
a = int(range_s, 16) # 16진수 -> 10진수 변환
b = int(range_e, 16)
return_sentence = ''
for i, w in enumerate(sentence):
if a<= ord(w) and ord(w) <= b: # 음절 단위로 사전에 정의한 유니코드 범위 내에 존재하는가
continue
return_sentence+=w
return return_sentence
sentence = 'hello world 안녕하세요 세계 مرحبا بالعالم Hallo Welt Chào thế giới Привет, мир'
# 영어 한국어 아랍어 독일어 베트남어 러시아어
# 구글번역기 이용
print(sentence)
print(remove_language('0600','06FF',sentence)) # 아랍어 제거, 아랍어의 유니코드 범위 0600 ~ 06FF
print(remove_language('0400','04FF',sentence)) # 러시아어 제거, 러시아 키릴 문자의 유니코드 범위 0400 ~ 04FF



영어를 제거하려면?
print(remove_language('0020','007F',sentence)) # 알파벳 제거, 알파벳의 유니코드 범위 0020 ~ 007F

문제가 생겼음
원하는 건 영어만 지우는건데 Hallo Welt 이 부분도 삭제됨
왜냐면 언어마다 같은 유니코드 체계를 사용할 수 있음
영어이지만 영어 유니코드 내에는 알파벳이 포함되어 있는데 다른 나라언어에서 그 알파벳을 가져다가 본인의 언어로 사용하게되면 원치 않게 삭제가 될 수 있음
그래서 유니코드만으로 모든 언어를 detection 하는 건 안됨
유니코드의 범위를 잘 고려를 하면서 설계를 해야지 올바르게 사용할 수 있음
실습 - 한국어 토크나이징
실습을 위해 한국어 wikipedia 파일을 가져오도록 하겠음
본 wikipedia 파일은 앞선 전처리 실습을 통해 전처리가 완료된 파일임
!mkdir my_data
!curl -c ./cookie -s -L "https://drive.google.com/uc?export=download&id=1zib1GI8Q5wV08TgYBa2GagqNh4jyfXZz" > /dev/null
!curl -Lb ./cookie "https://drive.google.com/uc?export=download&confirm=`awk '/download/ {print $NF}' ./cookie`&id=1zib1GI8Q5wV08TgYBa2GagqNh4jyfXZz" -o my_data/wiki_20190620_small.txt
데이터 확인해보자
data = open('my_data/wiki_20190620_small.txt', 'r', encoding='utf-8')
# 'r' 은 read를 의미합니다.
# 본 파일은 encoding format을 UTF-8로 저장했기 때문에, UTF-8로 읽겠습니다.
# 한국어는 특히 encoding format이 맞지 않으면, 글자가 깨지는 현상이 나타납니다.
lines = data.readlines() # 전체 문장을 list에 저장하는 함수입니다.
for line in lines[0:10]:
print(line)

1. 어절 단위 tokenizing
어절 단위 tokenizing 은 모든 문장을 띄어쓰기 단위로 분리하는 것을 의미
text = "이순신은 조선 중기의 무신이다."
tokenized_text = text.split(" ") # split 함수는 입력 string에 대해서 특정 string을 기반으로 분리해줍니다.
print(tokenized_text)

Tokenizing 의 목적은 크게 두 가지
- 의미를 지닌 단위로 자연어를 분절
- Model 의 학습 시, 동일한 size 로 입력
따라서, tokenizer 는 특정 사이즈로 token 의 개수를 조절하는 함수가 필수로 포함되어야 함
이를 위해, token 의 개수가 부족할 때는 padding 처리를 해주고, 개수가 많을 때는 token 을 잘라줘야 함
max_seq_length = 10
# padding
tokenized_text += ["padding"] * (max_seq_length - len(tokenized_text))
print(tokenized_text)

max_seq_length = 2
# filtering
tokenized_text = tokenized_text[0:max_seq_length]
print(tokenized_text)

이것을 pythonic 하게 클래스화 하겠음
class Tokenizer:
def __init__(self):
self.tokenizer_type_list = ["word"]
self.pad_token = "<pad>"
self.max_seq_length = 10
self.padding = False
def tokenize(self, text, tokenizer_type):
assert tokenizer_type in self.tokenizer_type_list, "정의되지 않은 tokenizer_type입니다."
if tokenizer_type == "word":
tokenized_text = text.split(" ")
if self.padding:
tokenized_text += [self.pad_token] * (self.max_seq_length - len(tokenized_text))
return tokenized_text[:self.max_seq_length]
else:
return tokenized_text[:self.max_seq_length]
def batch_tokenize(self, texts, tokenizer_type):
for i, text in enumerate(texts):
texts[i] = self.tokenize(text, tokenizer_type)
return texts
처음은 tokenizer_type 을 word 로 설정
나중에 코드의 변경 없이 tokenizer_type 만 추가하면서 진행할 예정
my_tokenizer = Tokenizer()
my_tokenizer.pad_token = "[PAD]"
my_tokenizer.max_seq_length = 10
my_tokenizer.padding = True
print(my_tokenizer.tokenize("이순신은 조선 중기의 무신이다.", "word"))
print(my_tokenizer.batch_tokenize(["이순신은 조선 중기의 무신이다.", "그는 임진왜란을 승리로 이끌었다."], "word"))

2. 형태소 단위 tokenizing
형태소 분석기로는 mecab 을 사용
from konlpy.tag import Mecab
mecab = Mecab()
print(mecab.pos("아버지가방에들어가신다."))

text = "이순신은 조선 중기의 무신이다."
# 이순신 -> PS
# 조선 -> DT TI
# 중기 -> TI
# 무신 -> OC
# 이순신 - 직업 - 무신
# 이순신 - 출생지 - 조선
tokenized_text = [lemma[0] for lemma in mecab.pos(text)]
print(tokenized_text)

형태소 tokenizer 도 class 에 추가하자
class Tokenizer:
def __init__(self):
self.tokenizer_type_list = ["word", "morph"]
self.pad_token = "<pad>"
self.max_seq_length = 10
self.padding = False
def tokenize(self, text, tokenizer_type):
assert tokenizer_type in self.tokenizer_type_list, "정의되지 않은 tokenizer_type입니다."
if tokenizer_type == "word":
tokenized_text = text.split(" ")
elif tokenizer_type == "morph":
tokenized_text = [lemma[0] for lemma in mecab.pos(text)]
if self.padding:
tokenized_text += [self.pad_token] * (self.max_seq_length - len(tokenized_text))
return tokenized_text[:self.max_seq_length]
else:
return tokenized_text[:self.max_seq_length]
def batch_tokenize(self, texts, tokenizer_type):
for i, text in enumerate(texts):
texts[i] = self.tokenize(text, tokenizer_type)
return texts
my_tokenizer = Tokenizer()
my_tokenizer.pad_token = "[PAD]"
my_tokenizer.max_seq_length = 10
my_tokenizer.padding = True
print(my_tokenizer.tokenize("이순신은 조선 중기의 무신이다.", "morph"))
print(my_tokenizer.batch_tokenize(["이순신은 조선 중기의 무신이다.", "그는 임진왜란을 승리로 이끌었다."], "morph"))

3. 음절 단위 tokenizing
음절 단위 tokenizing 은 한 자연어를 한 글자씩 분리함
text = "이순신은 조선 중기의 무신이다."
tokenized_text = list(text) # split 함수는 입력 string에 대해서 특정 string을 기반으로 분리해줍니다.
print(tokenized_text)

음절 단위 tokenizer 도 class 에 추가
class Tokenizer:
def __init__(self):
self.tokenizer_type_list = ["word", "morph", "syllable"]
self.pad_token = "<pad>"
self.max_seq_length = 10
self.padding = False
def tokenize(self, text, tokenizer_type):
assert tokenizer_type in self.tokenizer_type_list, "정의되지 않은 tokenizer_type입니다."
if tokenizer_type == "word":
tokenized_text = text.split(" ")
elif tokenizer_type == "morph":
tokenized_text = [lemma[0] for lemma in mecab.pos(text)]
elif tokenizer_type == "syllable":
tokenized_text = list(text)
if self.padding:
tokenized_text += [self.pad_token] * (self.max_seq_length - len(tokenized_text))
return tokenized_text[:self.max_seq_length]
else:
return tokenized_text[:self.max_seq_length]
def batch_tokenize(self, texts, tokenizer_type):
for i, text in enumerate(texts):
texts[i] = self.tokenize(text, tokenizer_type)
return texts
my_tokenizer = Tokenizer()
my_tokenizer.pad_token = "[PAD]"
my_tokenizer.max_seq_length = 20
my_tokenizer.padding = True
print(my_tokenizer.tokenize("이순신은 조선 중기의 무신이다.", "syllable"))
print(my_tokenizer.batch_tokenize(["이순신은 조선 중기의 무신이다.", "그는 임진왜란을 승리로 이끌었다."], "syllable"))

4. 자소 단위 tokenizing
한글은 하나의 문자도 최대 초성, 중성, 종성, 총 3개의 자소로 분리가 가능
실습에서는 자소 분리를 위해 hgtk 라이브러리를 사용함
!pip install hgtk
import hgtk
text = "이순신은 조선 중기의 무신이다."
tokenized_text = list(hgtk.text.decompose(text))
print(tokenized_text)
# ㅇ ㅣ ㅅ ㅜ ㄴ ㅅ ㅣ ...

‘ᴥ’ 이 이상한 기호가 들어있음
이 기호는 음절과 음절 단위를 구분해주는 구분자임
이게 왜필요할까라고 생각할 수 있는데 FastText 같은 경우 앞뒤로 <> 를 넣어준다 했는데 이 꺾쇠의 의미가 시작음절이냐
끝음절이냐를 명시적으로 알려주는 역할을 할 수 있음
이 경우도 마찬가지임
음절 구분이 없으면 ㅇ ㅣ ㅅ ㅜ ㄴ ㅅ ㅣ ... 이렇게 분리될 수 있음 이러면 혼란스러워짐
수많은 크롤링을 해봤지만 ‘ᴥ’ 이 문자가 들어있는 경우는 본적이 없어서 아마 문제없이 사용할 수 있을것임
자도 단위 tokenizer 도 class 에 추가함
class Tokenizer:
def __init__(self):
self.tokenizer_type_list = ["word", "morph", "syllable", "jaso"]
self.pad_token = "<pad>"
self.max_seq_length = 10
self.padding = False
def tokenize(self, text, tokenizer_type):
assert tokenizer_type in self.tokenizer_type_list, "정의되지 않은 tokenizer_type입니다."
if tokenizer_type == "word":
tokenized_text = text.split(" ")
elif tokenizer_type == "morph":
tokenized_text = [lemma[0] for lemma in mecab.pos(text)]
elif tokenizer_type == "syllable":
tokenized_text = list(text)
elif tokenizer_type == "jaso":
tokenized_text = list(hgtk.text.decompose(text))
if self.padding:
tokenized_text += [self.pad_token] * (self.max_seq_length - len(tokenized_text))
return tokenized_text[:self.max_seq_length]
else:
return tokenized_text[:self.max_seq_length]
def batch_tokenize(self, texts, tokenizer_type):
for i, text in enumerate(texts):
texts[i] = self.tokenize(text, tokenizer_type)
return texts
my_tokenizer = Tokenizer()
my_tokenizer.pad_token = "[PAD]"
my_tokenizer.max_seq_length = 20
my_tokenizer.padding = True
print(my_tokenizer.tokenize("이순신은 조선 중기의 무신이다.", "jaso"))
print(my_tokenizer.batch_tokenize(["이순신은 조선 중기의 무신이다.", "그는 임진왜란을 승리로 이끌었다."], "jaso"))

5. WordPiece tokenizing
Transformer 라이브러리를 사용해 구현할 예정
!pip install transformers
WordPiece Tokenizer 를 위한 폴더 생성
!mkdir wordPieceTokenizer
from tokenizers import BertWordPieceTokenizer
# Initialize an empty tokenizer
wp_tokenizer = BertWordPieceTokenizer(
clean_text=True, # [이순신, ##은, ' ', 조선]
handle_chinese_chars=True,
strip_accents=False, # True: [YepHamza] -> [Yep, Hamza]
lowercase=False,
)
# And then train
wp_tokenizer.train(
files="my_data/wiki_20190620_small.txt",
vocab_size=10000,
min_frequency=2,
show_progress=True,
special_tokens=["[PAD]", "[UNK]", "[CLS]", "[SEP]", "[MASK]"],
limit_alphabet=1000,
wordpieces_prefix="##"
)
# Save the files
wp_tokenizer.save_model("wordPieceTokenizer", "my_tokenizer")
clean_text: 기대하는 tokenzier 의 형태- [이순신, ##은, ‘ ‘, 조선] 여기서 ‘ ‘ 를 지우고 싶으면 True 로 주면 됨
- 우리가 실습할 Bert 모델 같은 경우 clean_text = True 로 학습되어 있음
handle_chinese_charts: 한자는 띄어쓰기가 존재하지 않음, 중국어나 일본어는 띄어쓰기가 존재하지 않음 그래서 얘네들은 모든 분석을 할 때 반드시 한음절 단위로 분석을 해야함- handle_chinese_charts=True 이면 본문내의 존재하는 한자들이 전부 음절 단위로 분리됨
- vocab 자체도 분리됨
- ’##’ 이 안붙게 됨
strip_accents: True 일 때, [YepHamza] -> [Yep, Hamza] 이렇게 분리 됨lowercase: True 일 때, 모든 알파벳을 소문자로 바꿔줌- True 보다 False 가 성능이 더 좋음
tokenizer 에 대한 옵션을 만들어줬으면 train() 만 해주면 WordPiece Tokenizer 의 학습이 바로 됨
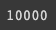
files: 만들어내기 위한 corpus 를 입력으로 넣게 됨vocab_size: 만들고 싶은 vocab 의 사이즈를 많게 만들면 거의 음절단위로 잘라지게 됨- vocab_size 를 채울만큼 WordPiece 를 돌게됨
min_frequency: 빈도수, 2개이하로 등장하는 애들은 vocab 으로 만들지 않겠다!special_tokens: Bert 모델이나 다른 모델들도 정의가 되어있는 형태를 가져와 사용wordpieces_prefix: “##” 사용
save_model(directory) 하면 저장됨

print(wp_tokenizer.get_vocab_size())
text = "이순신은 조선 중기의 무신이다."
tokenized_text = wp_tokenizer.encode(text)
print(tokenized_text)
print(tokenized_text.tokens)
print(tokenized_text.ids)

WordPiece tokenizer 도 class 에 추가함
class Tokenizer:
def __init__(self):
self.tokenizer_type_list = ["word", "morph", "syllable", "jaso", "wordPiece"]
self.pad_token = "<pad>"
self.max_seq_length = 10
self.padding = False
def tokenize(self, text, tokenizer_type):
assert tokenizer_type in self.tokenizer_type_list, "정의되지 않은 tokenizer_type입니다."
if tokenizer_type == "word":
tokenized_text = text.split(" ")
elif tokenizer_type == "morph":
tokenized_text = [lemma[0] for lemma in mecab.pos(text)]
elif tokenizer_type == "syllable":
tokenized_text = list(text)
elif tokenizer_type == "jaso":
tokenized_text = list(hgtk.text.decompose(text))
elif tokenizer_type == "wordPiece":
tokenized_text = wp_tokenizer.encode(text).tokens
if self.padding:
tokenized_text += [self.pad_token] * (self.max_seq_length - len(tokenized_text))
return tokenized_text[:self.max_seq_length]
else:
return tokenized_text[:self.max_seq_length]
def batch_tokenize(self, texts, tokenizer_type):
for i, text in enumerate(texts):
texts[i] = self.tokenize(text, tokenizer_type)
return texts
my_tokenizer = Tokenizer()
my_tokenizer.pad_token = "[PAD]"
my_tokenizer.max_seq_length = 10
my_tokenizer.padding = True
print(my_tokenizer.tokenize("이순신은 조선 중기의 무신이다.", "wordPiece"))
print(my_tokenizer.batch_tokenize(["이순신은 조선 중기의 무신이다.", "그는 임진왜란을 승리로 이끌었다."], "wordPiece"))

구현된 tokenizing 함수를 모두 확인해보자
print(my_tokenizer.tokenize("이순신은 조선 중기의 무신이다.", "word"))
print(my_tokenizer.tokenize("이순신은 조선 중기의 무신이다.", "morph"))
print(my_tokenizer.tokenize("이순신은 조선 중기의 무신이다.", "syllable"))
print(my_tokenizer.tokenize("이순신은 조선 중기의 무신이다.", "jaso"))
print(my_tokenizer.tokenize("이순신은 조선 중기의 무신이다.", "wordPiece"))

tokenizer 에 대해 익숙해지지 않으면 다양한 모델을 사용할 때 어려움을 겪을 수 있음
작성자
* 김성현 (bananaband657@gmail.com) 1기 멘토 김바다 (qkek983@gmail.com) 박상희 (parksanghee0103@gmail.com) 이정우 (jungwoo.l2.rs@gmail.com) 2기 멘토 박상희 (parksanghee0103@gmail.com) 이정우 (jungwoo.l2.rs@gmail.com) 이녕우 (leenw2@gmail.com) 박채훈 (qkrcogns2222@gmail.com)
댓글남기기