Day_39 02. BERT 언어모델 기반의 문장 토큰 분류
작성일
BERT 언어모델 기반의 문장 토큰 분류
1. 문장 토큰 분류 task 소개
1.1 문장 토큰 관계 분류 task
주어진 문장의 각 token 이 어떤 범주에 속하는지 분류하는 task
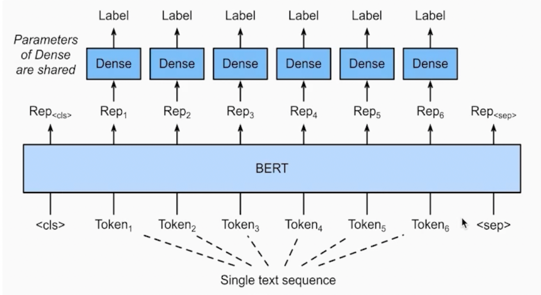
토큰 분류 task 는 문장이 입력으로 들어가게 되면 각각 token 에 대해 classification layer 가 부착이 되서 각 token 이 어떤 token 인지 입력된 문장의 각 token 들을 분류하는 task 임
Named Entity Recognition (NER)
- 개체명 인식은 문맥을 파악해서 인명, 기관명, 지명 등과 같은 문장 또는 문서에서 특정한 의미를 가지고 있는 단어 또는 어구(개체) 등을 인식하는 과정을 의미한다.

재밌는 예시가 있음
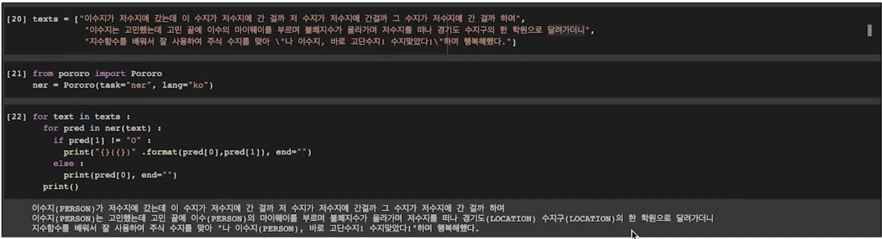
같은 단어라도 문맥에서 다양한 개체(Entity)로 사용됨
개체명인식기에서 가장 중요한 것은 이 모델이 문맥을 올바르게 파악하고 있는가 아닌가 이기 때문에 문맥을 고려하는 것이 굉장히 중요!
지금 나온 예제는 카카오브레인에서 개발한 PORORO 라는 라이브러리임
이 라이브러리를 활용하면 개체명인식 혹은 관계추출, 두문장 관계분석 심지어 summary 까지 뭐 거의 한국어로 할 수 있는
모든 자연어처리가 하나의 라이브러리로 다 들어가있음
그래서 PORORO 를 활용하면 빠르게 proto typing 을 해야한다던가 혹은 구상한 아이디어를 빠르게 구현해보는 그런 test 를
하는데 굉장히 용이함
Part-of-speech tagging (POS TAGGING)
- 품사란 단어를 문법적 성질의 공통성에 따라 언어학자들이 몇 갈래로 묶어 놓은 것이다.
- 품사 태깅은 주어진 문장의 각 성분에 대하여 가장 알맞는 품사를 태깅하는 것을 의미한다.
품사태깅, 형태소태깅 같은 예시가 있음
형태소태깅은 언어가 가지는 가장 최소의 단위로 분류하는 것을 얘기함
그래서 개체명 인식과 마찬가지로 주어진 문장에 대해 문맥을 파악하면 형태소 분석을 할 수 가 있을 것임

PORORO 에도 POS tagging 을 지원하고 있음
1.2 문장 token 분류를 위한 데이터
kor_ner
- 한국해양대학교 자연어 처리 연구실에서 공개한 한국어 NER 데이터셋
- 일반적으로, NER 데이터셋은 pos tagging 도 함께 존재

개체명 인식이 가능한 코드를 활용해서 POS taggin 이 가능한 모델들도 학습할 수 있음
이 데이터셋의 가장 큰 특징중의 하나는 개체명인식에 대해서 개체명 tagging 을 BIO 라는 tag 로 구성했음
kor_ner 에서 다루는 개체명은 다음과 같음
- Entity tag 에서 B 의 의미는 개체명의 시작(Begin)을 의미하고, I 의 의미는 내부(Inside)를 의미하며, O 는
다루지 않는 개체명(Outside)를 의미한다.
- B : Begin 이라는 의미
- I : Inner 의 의미
- O : Out 의 의미
- 즉, B-PER 은 인물명 개체명의 시작을 의미하며, I-PER 는 인물명 개체명의 내부 부분을 뜻한다.
- kor_ner 데이터셋에서 다루는 개체명은 다음과 같다.

2. 문장 토큰 분류 모델 학습 실습
2.1 문장 토큰 분류 모델 학습
NER fine-tuning with BERT
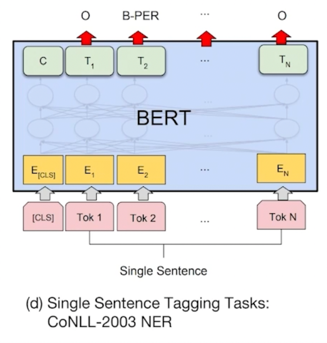
각각의 token 에 대해서 classification layer 를 부착해서 분류하는 과정으로 task 를 진행함
주의점
정답은 아니지만 개체명인식을 할 때 항상 음절단위로 분석을 하게 만듦
왜냐면 tokenizer 의 문제가 될 수 있는데 BERT 같은 경우엔 WordPiece tokenizer 를 사용하게 됨
그러면 WordPiece tokenizer 가 올바르게 자르지 못한 존재에 대해서는 개체명도 error 가 날 수 밖에 없음
예를 들어서 “이순신은 조선 중기의 무신이다” 라는 문장이 있을 때 WordPiece tokenizer 가 “이순”, “신은” 이렇게
분리를 했다고 가정해보자
“이순” 은 PER 로 분류가 될 수 있음
그러면 “신” 도 PER 로 분류가 되어야 함
그런데 애초에 tokenizer 가 “이순신” 을 “이”, “순”, “신” 처럼 따로따로 분류한게 아니고 “이순” 과 “신은” 이라고 분리를
한 경우에 “신은” 은 아무리 잘라도 PER 이 나올 수 없음
그래서 tokenizer 자체가 token 을 잘 못 잘랐기에 발생하는 문제임
그래서 음절단위로 자르는걸 많이 추천드림
개체명 인식기를 음절단위로 학습을 하게되면 아래와 같이 데이터를 구성할 수 있음
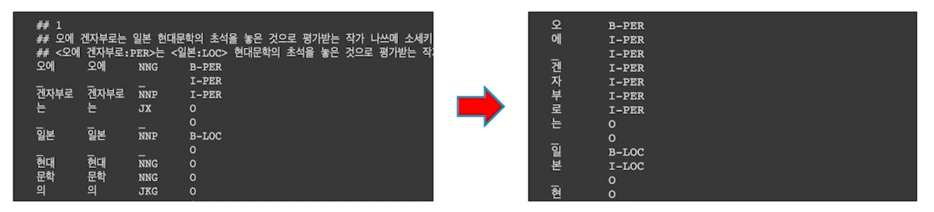
형태소 단위의 토큰을 음절 단위의 토큰으로 분해하고, Entity tag 역시 음절 단위로 매핑시켜 주어야 함
학습 과정
실습
문장 토큰 단위 분류 모델 학습
데이터셋을 다운로드 받자
!git clone https://github.com/kmounlp/NER.git
모든 파일을 가져와서 출력을 해보자
import os
import glob
file_list = []
for x in os.walk('/content/NER/'):
for y in glob.glob(os.path.join(x[0], '*_NER.txt')): # ner.*, *_NER.txt
file_list.append(y)
file_list = sorted(file_list)
for file_path in file_list:
print(file_path)

데이터 샘플을 확인해보자
from pathlib import Path
file_path = file_list[0]
file_path = Path(file_path)
raw_text = file_path.read_text().strip()
print(raw_text[0:1000])
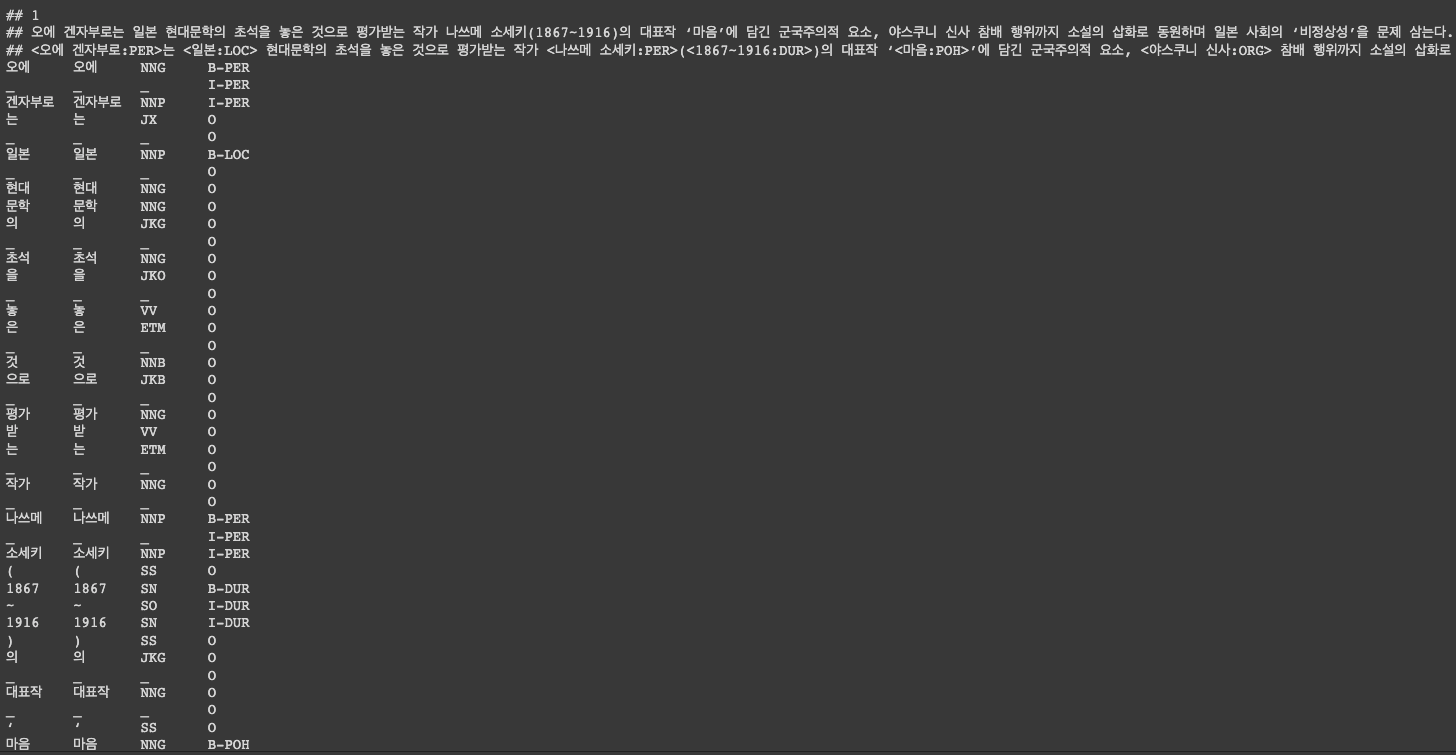
형태소 단위로 tokenizing 되어있고 BIO tag 로 개체명 tag 가 부착된 것을 확인할 수 있음
이걸 음절단위로 변환하는 과정을 먼저 거칠 것임
데이터를 전처리하는 과정을 먼저 진행하자
이 데이터셋은 기존의 우리가 봤던 데이터셋과 형태가 다름
어떻게 다르냐면?
기존에는 모든 데이터셋이 line-by-line 으로 구성되어 있었음
첫번째 line 에 첫번째 행을 보면 sentence 가 있고 두번째에는 label 이 부착되어있고 그렇기 때문에
line-by-line 으로만 읽으면 문제없이 데이터셋을 구축할 수 있었음
그런데 이 데이터셋은 형태소 단위로 enter 로 구분되어 있는걸 볼 수 있음
BERT 로 입력이 들어갈 때는 이것을 하나의 문장으로 합쳐서 입력이 되어야 함
그러니까 이렇게 세로로 되어있는 데이터를 하나의 문장으로 만들고 세로로 나누어져있는 BIO tag 들을 각각의
token 에 맞는 label 로서 입력을 넣어줘야 학습이 이루어지게 됨
이러한 과정을 할 수 있는 전처리 과정을 진행해보자
import re
def read_file(file_list):
token_docs = []
tag_docs = []
for file_path in file_list:
# print("read file from ", file_path)
file_path = Path(file_path)
raw_text = file_path.read_text().strip()
raw_docs = re.split(r'\n\t?\n', raw_text)
for doc in raw_docs:
tokens = []
tags = []
for line in doc.split('\n'):
if line[0:1] == "$" or line[0:1] == ";" or line[0:2] == "##":
continue
try:
token = line.split('\t')[0]
tag = line.split('\t')[3] # 2: pos, 3: ner
for i, syllable in enumerate(token): # 음절 단위로 잘라서
tokens.append(syllable)
modi_tag = tag
if i > 0:
if tag[0] == 'B':
modi_tag = 'I' + tag[1:] # BIO tag를 부착할게요 :-)
tags.append(modi_tag)
except:
print(line)
token_docs.append(tokens)
tag_docs.append(tags)
return token_docs, tag_docs
데이터 전체를 다 읽고 이중 enter 를 기준으로 document 로서 구분하게 됨
각각의 line 을 읽어나가면서 그 token 들을 문장으로 부착하는 과정을 거치게 됨
우리의 데이터셋은 tokenizing 단위가 형태소 단위로 되어있었음
그래서 이것을 음절단위로 바꾸는 과정을 위해 반복문을 돌면서 음절 단위로 token 을 자르는 과정을 거치도록 함
각각의 syllable(음절) 음절 단위 정보를 가져와서 token 뒤에 계속해서 append 를 하면서 문장을 만들어 나감
이 때 잘라진 음절에 대해서 마찬가지로 BIO tag 를 부착하는 과정을 거침
이렇게 만들어진 tag 에 데이터셋을 확인해보면 다음과 같음
texts, tags = read_file(file_list[:])
print(len(texts))
print(len(tags))
print(texts[0], end='\n\n') # 음절 단위로 잘 잘렸네요!
print(tags[0])
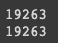

기존의 데이터셋이 전부 음절단위로 잘라졌고 tag 도 잘 부착되었음
데이터가 다 준비되었으니 학습을 위한 과정을 진행하자
학습을 하려면 먼저 이 tag 들을 숫자로 바꿔줘야 함
vocab id 처럼 tag label id 로 바꿔줘야 함
unique_tags = set(tag for doc in tags for tag in doc)
tag2id = {tag: id for id, tag in enumerate(unique_tags)}
id2tag = {id: tag for tag, id in tag2id.items()}
for i, tag in enumerate(unique_tags):
print(tag) # 학습을 위한 label list를 확인합니다.

데이터가 보유하고 있는 개체명 tag 들의 종류임
데이터셋을 확인해보자
import numpy as np
import matplotlib.pyplot as plt
texts_len = [len(x) for x in texts]
plt.figure(figsize=(16,10))
plt.hist(texts_len, bins=50, range=[0,800], facecolor='b', density=True, label='Text Length')
plt.title('Text Length Histogram')
plt.legend()
plt.xlabel('Number of Words')
plt.ylabel('Probability')
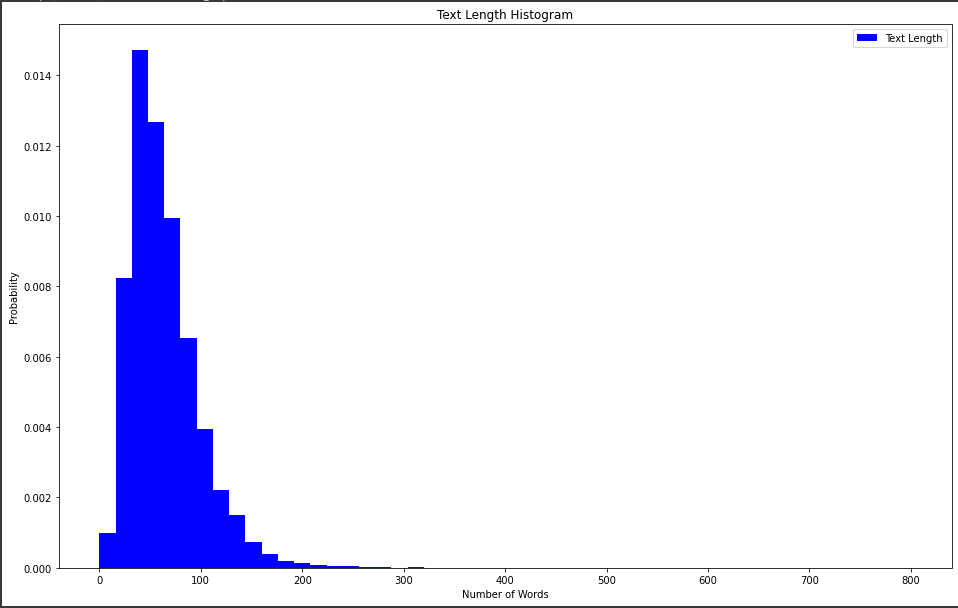
문장의 길이나 평균길이를 확인하면 나중에 모델을 학습할 때 데이터를 전처리 과정을 통해 제거를 해주거나 필터링 할 수 있음
각 NER 태그에 포함되어 있는 데이터의 개수를 확인해보자
for tag in list(tag2id.keys()) :
globals()[tag] = 0
for tag in tags :
for ner in tag :
globals()[ner] += 1
for tag in list(tag2id.keys()) :
print('{:>6} : {:>7,}'. format(tag, globals()[tag]))
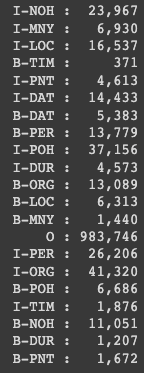
각각의 tag 에 대해서 데이터가 어느정도 포함되어 있는지 개수를 파악
각각의 tag 마다 가지고 있는 데이터의 개수가 다 다름
일반적으로 개수가 부족한 tag 에 대해서는 학습 성능이 떨어질 수 밖에 없음
그럴때는 해당 tag 에 관련된 데이터셋을 더 추가하는 방법으로 보완을 할 수 있음
train 과 test set 을 분리해주자
from sklearn.model_selection import train_test_split
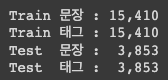
train_texts, test_texts, train_tags, test_tags = train_test_split(texts, tags, test_size=.2)
print('Train 문장 : {:>6,}' .format(len(train_texts)))
print('Train 태그 : {:>6,}' .format(len(train_tags)))
print('Test 문장 : {:>6,}' .format(len(test_texts)))
print('Test 태그 : {:>6,}' .format(len(test_tags)))
BERT tokenizer 와 model 을 가져와서 실질적으로 학습을 진행해보자
from transformers import AutoModel, AutoTokenizer, BertTokenizer
MODEL_NAME = "bert-base-multilingual-cased"
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
pad_token_id = tokenizer.pad_token_id # 0
cls_token_id = tokenizer.cls_token_id # 101
sep_token_id = tokenizer.sep_token_id # 102
pad_token_label_id = tag2id['O'] # tag2id['O']
cls_token_label_id = tag2id['O']
sep_token_label_id = tag2id['O']
현재 모델의 각각의 token 에 대해서 token 에 해당하는 label 이 부착이 되어 있는데 하지만 [CLS] 토큰이나 혹은 [SEP] 토큰
그리고 [PAD] 토큰에 대해서는 label 이 데이터셋에 존재하지 않음
그래서 임의로 그런 데이터셋을 만들어주게 됨
어쨋든 모델의 입력으로 들어갈 때는 문장의 형태로 들어가게 될텐데 그 문장에 있는 [CLS] 토큰은 O tag 로 나오고 [SEP] 토큰도
O tag 로 나올 수 있게 [PAD] 토큰도 O tag 로 나오게 label 을 지정해줌
기존의 tokenizer 는 WordPiece tokenizer 를 사용했기 때문에 입력된 결과 대해 tokenizer 를 태우면 tokenizer 결과가
다르게 나올 것임
왜냐하면 우리의 데이터는 음절단위로 만들어져있기 때문임
음절 단위로 tokenizing 할 수 있는 그런 tokenizer 를 만들어줘야 함
# 기존 토크나이저는 wordPiece tokenizer로 tokenizing 결과를 반환합니다.
# 데이터 단위를 음절 단위로 변경했기 때문에, tokenizer도 음절 tokenizer로 바꿀게요! :-)
def ner_tokenizer(sent, max_seq_length):
pre_syllable = "_"
input_ids = [pad_token_id] * (max_seq_length - 1)
attention_mask = [0] * (max_seq_length - 1)
token_type_ids = [0] * max_seq_length
sent = sent[:max_seq_length-2]
for i, syllable in enumerate(sent):
if syllable == '_':
pre_syllable = syllable
if pre_syllable != "_":
syllable = '##' + syllable # 중간 음절에는 모두 prefix를 붙입니다.
# 이순신은 조선 -> [이, ##순, ##신, ##은, 조, ##선]
pre_syllable = syllable
input_ids[i] = (tokenizer.convert_tokens_to_ids(syllable))
attention_mask[i] = 1
input_ids = [cls_token_id] + input_ids
input_ids[len(sent)+1] = sep_token_id
attention_mask = [1] + attention_mask
attention_mask[len(sent)+1] = 1
return {"input_ids":input_ids,
"attention_mask":attention_mask,
"token_type_ids":token_type_ids}
그래서 ner_tokenizer() 라는 함수를 새로 만들었음
이 tokenizer 는 마찬가지로 max_seq_length 를 받아서 max_seq_length 만큼 truncation 도 하고 padding 도 제공함
이 tokenizer 의 핵심은 어절의 중간에 들어가는 음절들은 모두 ‘##’ 으로 이루어진 prefix 를 붙이는 것임
이 tokenizer 가 반환하는 것은 기존의 tokenizer 가 반환하는 것과 동일하게 만들어져 있음
input_ids, attention_mask, token_type_ids 를 반환함
질문이 하나 생겼을 수도 있는데요!
기존의 BERT 는 WordPiece 단위로 되어있고 제가 임의로 맏는거는 음절단위로 만들어지게 됨
어쨌든 음절단위로 만들어진것도 전부 vocab id 가 부착이 되어야 할텐데 WordPiece 로 만들어진 tokenizer 를 사용할 때
음절 단위로 잘라진것에 대해서 전부 다 out-of-vocabulary 그니까 [UNK] 토큰으로 변환되지 않을까 라는 걱정을 할 수 있을것
같은데 multi-lingual model 같은 경우에는 한국어의 대한 vocab 이 8,000개 밖에 존재하지 않고 그 안의 있는 한국어들이
거의다 음절로만 되어있음 그래서 음절단위 tokenizer 를 적용해도 vocab id 가 어느 정도 다 획득할 수 있게 됨
하나의 샘플을 보자
print(ner_tokenizer(train_texts[0], 5))

[CLS] 토큰과 [SEP] 토큰 잘 부착되어 있고 안에 문장들 잘 들어가 있는 것을 확인할 수 있음
train data 를 tokenizing 하고 tokenize 된 데이터를 모델에 넣는 그런 과정을 반복하면 됨
tokenized_train_sentences = []
tokenized_test_sentences = []
for text in train_texts: # 전체 데이터를 tokenizing 합니다.
tokenized_train_sentences.append(ner_tokenizer(text, 128))
for text in test_texts:
tokenized_test_sentences.append(ner_tokenizer(text, 128))
train data 를 tokenize 해서 tokenized_train_sentence 에 저장하게 됨
tokenizer 같은 경우는 truncation 과 padding 이 들어가게 된다고 했는데 우리의 label 데이터도 마찬가지로 truncation 과 padding 이 필요함
기존 label 데이터에 [PAD] 토큰 혹은 truncation 된 사이즈만큼 길이를 맞춰주는 과정을 encode_tags() 라는 함수를
통해서 진행하겠음
def encode_tags(tags, max_seq_length):
# label 역시 입력 token과 개수를 맞춰줍니다 :-)
tags = tags[:max_seq_length-2]
labels = [tag2id[tag] for tag in tags]
labels = [tag2id['O']] + labels
padding_length = max_seq_length - len(labels)
labels = labels + ([pad_token_label_id] * padding_length)
return labels
encode_tags(train_tags[0], 5)
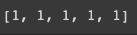
이렇게 하면 train data 에서 5개로 truncation 이 올바르게 된 것을 확인할 수 있음
train labels 역시 encode_tags() 함수를 통해서 전부 만들어 줌
train_labels = []
test_labels = []
for tag in train_tags:
train_labels.append(encode_tags(tag, 128))
for tag in test_tags:
test_labels.append(encode_tags(tag, 128))
len(train_labels), len(test_labels)
이렇게 하면 train data 만들어졌고 train lable 만들어 졌음
다음으로는
import torch
# 여기 부터는 이제 지겨워지죠? :-)
class TokenDataset(torch.utils.data.Dataset):
def __init__(self, encodings, labels):
self.encodings = encodings
self.labels = labels
def __getitem__(self, idx):
item = {key: torch.tensor(val) for key, val in self.encodings[idx].items()}
item['labels'] = torch.tensor(self.labels[idx])
return item
def __len__(self):
return len(self.labels)
train_dataset = TokenDataset(tokenized_train_sentences, train_labels)
test_dataset = TokenDataset(tokenized_test_sentences, test_labels)
dataset 을 만들어주고 입력은 __getitem__ 에 들어가게 되고 label 은 사전에 정의를 해둔 label 이 순차적으로
들어가게 됨
기존의 single sentence classification 그리고 두 문장간 관계분류 이런 애들은 BertForSentenceClassification 모델을
사용했는데 이번에 해야하는 것은 각각의 token 위에 token 마다 classification layer 가 부착이 되서 해당 token 이 어떤
label 값인지 분류하는 과정을 진행하게 될 것임
transformers 에서 역시 BertForTokenClassification 이라고 하는 class 를 제공해주고 있음
from transformers import BertForTokenClassification, Trainer, TrainingArguments
import sys
training_args = TrainingArguments(
output_dir='./results', # output directory
num_train_epochs=5, # total number of training epochs
per_device_train_batch_size=8, # batch size per device during training
per_device_eval_batch_size=64, # batch size for evaluation
logging_dir='./logs', # directory for storing logs
logging_steps=100,
learning_rate=3e-5,
save_total_limit=5
)
train arguments 동일하게 채워주고
마찬가지로 모델의 initialize 를 BertForTokenClassification 으로 해주게 되고 중요한게 하나가 더 있음
model = BertForTokenClassification.from_pretrained(MODEL_NAME, num_labels=len(unique_tags))
model.to(device)
trainer = Trainer(
model=model, # the instantiated 🤗 Transformers model to be trained
args=training_args, # training arguments, defined above
train_dataset=train_dataset, # training dataset
eval_dataset=test_dataset # evaluation dataset
)
기존에는 MODEL_NAME 파라미터 하나만 넣고 분류로 넘어갔었는데 얘는 num_labels 에서 unique_tags(우리가 구분해야하는 label)이 몇개인지를 명확하게 지정해줘야 함
trainer.train() # 1 epoch에 대략 5분 정도 걸립니다.
학습이 완료되면 실제 NER inference 를 해보도록 하자
역시 중요한 것은 기존에 우리가 사용하던 것은 WordPiece tokenizer 를 사용했지만 이번에 우리는 음절 tokenizer 를 사용했음
그래서 입력된 문장에 대해서도 반드시 음절 tokenizer 를 거친후에 모델의 입력으로 들어가야 함
def ner_inference(text) :
model.eval()
text = text.replace(' ', '_')
predictions , true_labels = [], []
tokenized_sent = ner_tokenizer(text, len(text)+2)
input_ids = torch.tensor(tokenized_sent['input_ids']).unsqueeze(0).to(device)
attention_mask = torch.tensor(tokenized_sent['attention_mask']).unsqueeze(0).to(device)
token_type_ids = torch.tensor(tokenized_sent['token_type_ids']).unsqueeze(0).to(device)
with torch.no_grad():
outputs = model(
input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids)
logits = outputs['logits']
logits = logits.detach().cpu().numpy()
label_ids = token_type_ids.cpu().numpy()
predictions.extend([list(p) for p in np.argmax(logits, axis=2)])
true_labels.append(label_ids)
pred_tags = [list(tag2id.keys())[p_i] for p in predictions for p_i in p]
print('{}\t{}'.format("TOKEN", "TAG"))
print("===========")
# for token, tag in zip(tokenizer.decode(tokenized_sent['input_ids']), pred_tags):
# print("{:^5}\t{:^5}".format(token, tag))
for i, tag in enumerate(pred_tags):
print("{:^5}\t{:^5}".format(tokenizer.convert_ids_to_tokens(tokenized_sent['input_ids'][i]), tag))
그래서 text 가 입력이 되었을 때 사전에 만들어 뒀던 ner_tokenizer 를 거쳐서 tokenized_sent 를 만들게 되고
이것을 input_ids, attention_mask, token_type_ids value 로 가져오게 되고 이것을 모델에 그대로 입력으로 넣게 됨
각각의 token 에 대해서 softmax 가 최대로 되는 값이 무엇인지 그 값을 가져와서 token 결과를 반환할 수 있음
실제 예제를 확인해 보자
text = '이순신은 조선 중기의 무신이다.'
ner_inference(text)

text = '로스트아크는 스마일게이트 RPG가 개발한 쿼터뷰 액션 MMORPG 게임이다.'
ner_inference(text)

text = '2014년 11월 12일 최초 공개했으며 2018년 11월 7일부터 오픈 베타 테스트를 진행하다 2019년 12월 4일 정식 오픈했다.'
ner_inference(text)


개체명 인식 과정을 통해서 문장에 대한 token 분류 task 를 학습을 실습해봤음
다음엔 본문 내에서 정답 token 이 어디에 존재하는지를 분류할 수 있는 기계독해 task 를 실습해보자
실습
기계독해 모델 학습
import torch
import sys
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
이번에 사용할 dataset 은 KorQUaD 라는 데이터 임
!mkdir dataset
!wget https://korquad.github.io/dataset/KorQuAD_v1.0_train.json
!wget https://korquad.github.io/dataset/KorQuAD_v1.0_dev.json
한국어 기계독해 데이터셋임
!mv /content/KorQuAD_v1.0_train.json dataset
!mv /content/KorQuAD_v1.0_dev.json dataset
이 데이터셋은 json 형태로 되어있음
학습하기에 편한 형태로 가져오도록 하자
# 데이터셋을 파싱해오겠습니다 :-)
import json
from pathlib import Path
def read_squad(path):
path = Path(path)
with open(path, 'rb') as f:
squad_dict = json.load(f)
contexts = []
questions = []
answers = []
for group in squad_dict['data']:
for passage in group['paragraphs']:
context = passage['context']
for qa in passage['qas']:
question = qa['question']
for answer in qa['answers']:
contexts.append(context)
questions.append(question)
answers.append(answer)
return contexts, questions, answers
train_contexts, train_questions, train_answers = read_squad('dataset/KorQuAD_v1.0_train.json')
val_contexts, val_questions, val_answers = read_squad('dataset/KorQuAD_v1.0_dev.json')
이 과정을 데이터 파싱한다고 얘기함 파싱을 통해서 데이터 안에 존재하는 paragraph 와 question 그리고 정답 관련된 answer 데이터 이런 요소들을 가져오는 과정을 거침
print(train_contexts[52471])
print(len(train_contexts[52471]))

이렇게 하면 train_contexts 에 본문에 대한 내용을 확인할 수 있음
print(train_questions[52471])

print(train_answers[52471]) # 본문 내에서 정답이 시작되는 음절 순서가 'answer start'에 저장되어 있습니다.

질문과 답변까지 확인 할 수 있음
answer_start 라는게 보이는데 본문 내에서 정답이 시작하는 음절 순서를 의미함
이 경우엔 본문 내에서 568 번째 음절에 answer 가 시작한다 라는 것을 의미
정답의 text 의 길이를 사용하면 end 의 위치를 자동적으로 알 수 있음
모델을 위해 학습 데이터를 만들어 줘야 함
def add_end_idx(answers, contexts):
for answer, context in zip(answers, contexts):
# 모델 학습을 위해 정답 데이터를 만들겠습니다.
# 정답 데이터는 start음절과 end 음절로 구성되어 있습니다.
# 모델은 전체 토큰 중에서 start token과 end token을 찾아내는 것을 목표로 학습하게 됩니다.
gold_text = answer['text']
start_idx = answer['answer_start']
end_idx = start_idx + len(gold_text)
# sometimes squad answers are off by a character or two – fix this
# 실제 본문에서 해당 음절 번호로 잘라냈을 때, 정답과 같은지 검사해서 start, end를 보정합니다 :-)
# '이순신은 조선 중기의 무신이다' -> '이순신' -> start: 0, end: 4
if context[start_idx:end_idx] == gold_text:
answer['answer_end'] = end_idx
elif context[start_idx-1:end_idx-1] == gold_text:
answer['answer_start'] = start_idx - 1
answer['answer_end'] = end_idx - 1 # When the gold label is off by one character
elif context[start_idx-2:end_idx-2] == gold_text:
answer['answer_start'] = start_idx - 2
answer['answer_end'] = end_idx - 2 # When the gold label is off by two characters
return answers
train_answers = add_end_idx(train_answers, train_contexts)
val_answers = add_end_idx(val_answers, val_contexts)
모델은 answer start position 그리고 answer end position 이 2개를 입력으로 받게 됨
from transformers import AutoModel, AutoTokenizer, BertTokenizer
MODEL_NAME = "bert-base-multilingual-cased"
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
train_encodings = tokenizer(train_contexts, train_questions, truncation=True, padding=True)
val_encodings = tokenizer(val_contexts, val_questions, truncation=True, padding=True)
모델은 앞의 실습과 동일하게 사용함
def add_token_positions(encodings, answers):
start_positions = []
end_positions = []
# 이제 음절 index를 token index와 mapping하는 작업을 해보도록 하겠습니다 :-)
for i in range(len(answers)):
# tokenizer의 char_to_token 함수를 호출하면 음절 숫자를 token index로 바꿔줄 수 있습니다.
start_positions.append(encodings.char_to_token(i, answers[i]['answer_start']))
end_positions.append(encodings.char_to_token(i, answers[i]['answer_end']))
# 아래 부분은 truncation을 위한 과정입니다.
# if start position is None, the answer passage has been truncated
if start_positions[-1] is None:
start_positions[-1] = tokenizer.model_max_length
# if end position is None, the 'char_to_token' function points to the space before the correct token - > add + 1
if end_positions[-1] is None:
end_positions[-1] = encodings.char_to_token(i, answers[i]['answer_end'] + 1)
# 추가된 예외 처리, 예를들어서 tokenizer와 model input의 max_length가 512인데, start와 end position이 600과 610 이면 둘다 max_length로 변경해야함.
# 어차피 max_length가 512인 모델은 정답을 볼 수 없음.
if start_positions[-1] is None or start_positions[-1] > tokenizer.model_max_length:
start_positions[-1] = tokenizer.model_max_length
if end_positions[-1] is None or end_positions[-1] > tokenizer.model_max_length:
end_positions[-1] = tokenizer.model_max_length
encodings.update({'start_positions': start_positions, 'end_positions': end_positions})
return encodings
train_encodings = add_token_positions(train_encodings, train_answers)
val_encodings = add_token_positions(val_encodings, val_answers)
이 부분이 기계독해에서 핵심인 부분이 될 수 있음
우리가 구축한 데이터는 음절 인덱스를 가져오게 됨
하지만 BERT 모델은 WordPiece 단위로 되어있음
그렇기 때문에 음절단위에 있는 숫자를 token index 로 바꿔줘야 함
그래야지 해당 token index 가 정답에서 정답의 시작이다 라는 label 을 학습할 수 있음
이 때 사용하는 함수가 char_to_token() 임 이 함수를 호출하면 음절 숫자를 token index 로 바꿔줄 수 있음
예외처리 부분도 있음
BERT 모델은 512 토큰이 maximum 인데 만약 정답이 512 토큰을 넘어서는 위치에 존재한다면 그거는 학습을 하나마나가 됨
그래서 그 부분에 대한 예외처리를 추가했음
학습데이 자체는 start_position 에 대한 정보와 end_position 에 대하 정보를 토큰 단위로 가지게 됨
이렇게 데이터를 만들고나면 dataset 을 만들고
import torch
class SquadDataset(torch.utils.data.Dataset):
def __init__(self, encodings):
self.encodings = encodings
def __getitem__(self, idx):
return {key: torch.tensor(val[idx]) for key, val in self.encodings.items()}
def __len__(self):
return len(self.encodings.input_ids)
train_dataset = SquadDataset(train_encodings)
val_dataset = SquadDataset(val_encodings)
이 때 반환하는 값이 모델에 입력으로 들어가던 tokenized 된 결과임 그리고 여기에 정답에 대한 token index 정보를 함께 반환해서 label 로 사용하게 됨
from transformers import BertForQuestionAnswering
model = BertForQuestionAnswering.from_pretrained(MODEL_NAME)
역시 huggingface 에서 기계독해를 위한 BertForQuestionAnswering 를 제공하고 있음
from transformers import BertForQuestionAnswering, Trainer, TrainingArguments
import sys
training_args = TrainingArguments(
output_dir='./results', # output directory
num_train_epochs=1, # total number of training epochs
per_device_train_batch_size=8, # batch size per device during training
per_device_eval_batch_size=64, # batch size for evaluation
logging_dir='./logs', # directory for storing logs
logging_steps=100,
learning_rate=3e-5,
save_total_limit=5
)
model = BertForQuestionAnswering.from_pretrained(MODEL_NAME)
model.to(device)
trainer = Trainer(
model=model, # the instantiated 🤗 Transformers model to be trained
args=training_args, # training arguments, defined above
train_dataset=train_dataset, # training dataset
eval_dataset=val_dataset # evaluation dataset
)
기계독해를 위한 모델 완성!
trainer.train() # 1 epoch에 대략 1시간 정도 걸립니다.
모델이 학습되고 나면 모델을 저장해줌
trainer.save_model(".")
pipeline 을 활용해서 inference 를 해보자
from transformers import pipeline
nlp = pipeline("question-answering", model=model, tokenizer=tokenizer, device=0)
context = r"""
이순신(李舜臣, 1545년 4월 28일 ~ 1598년 12월 16일 (음력 11월 19일))은 조선 중기의 무신이었다.
본관은 덕수(德水), 자는 여해(汝諧), 시호는 충무(忠武)였으며, 한성 출신이었다.
문반 가문 출신으로 1576년(선조 9년) 무과(武科)에 급제하여 그 관직이 동구비보 권관, 훈련원 봉사, 발포진 수군만호, 조산보 만호, 전라좌도 수군절도사를 거쳐 정헌대부 삼도수군통제사에 이르렀다.
"""
print(nlp(question="이순신이 태어난 날짜는?", context=context))
print(nlp(question="이순신의 본관은?", context=context))
print(nlp(question="이순신의 시호는?", context=context))
print(nlp(question="이순신의 고향은?", context=context))
print(nlp(question="이순신의 마지막 직책은?", context=context))

pipeline 에 “question-answering” 을 넣어서 사용
작성자
* 김성현 (bananaband657@gmail.com) 1기 멘토 김바다 (qkek983@gmail.com) 박상희 (parksanghee0103@gmail.com) 이정우 (jungwoo.l2.rs@gmail.com) 2기 멘토 박상희 (parksanghee0103@gmail.com) 이정우 (jungwoo.l2.rs@gmail.com) 이녕우 (leenw2@gmail.com) 박채훈 (qkrcogns2222@gmail.com)
댓글남기기