Day_38 01. BERT 언어모델 소개
작성일
BERT 언어모델 소개
1. BERT 언어모델 소개
1.1 BERT 모델 소개
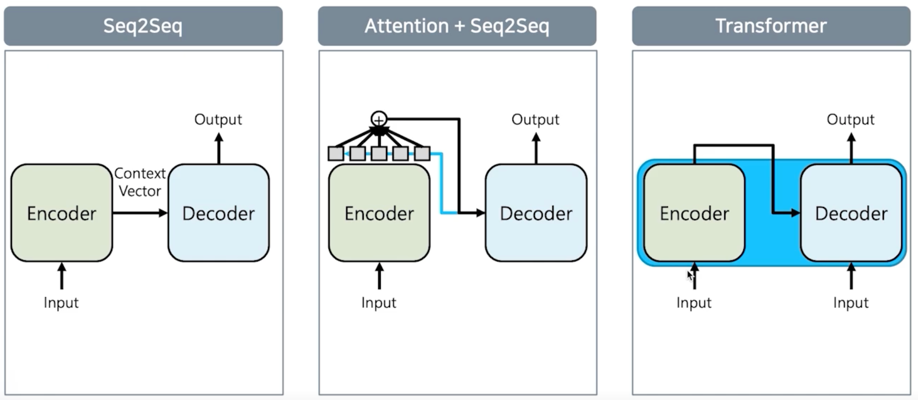
seq2seq 모델을 거쳐서 seq2seq with attention 그리고 Transformer 까지 진행되었고
간단하게 이미지로 예제를 설명해보자
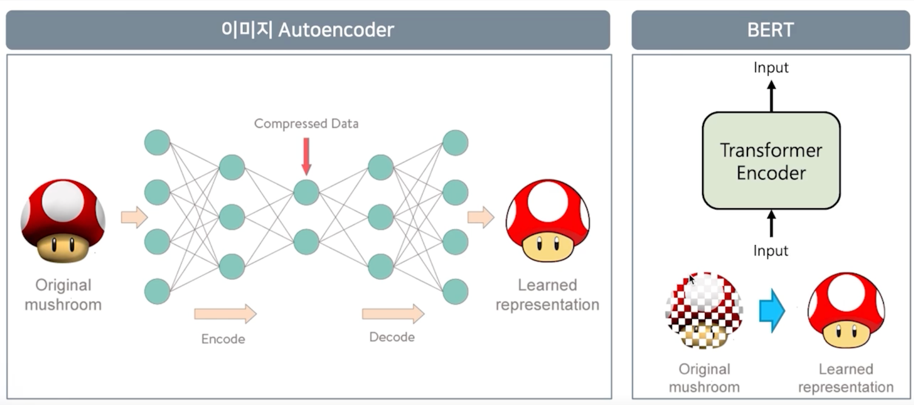
이미지분야 쪽에는 Autoencoder 라고 하는 모델이 있음
이 모델은 역시 encoder 와 decoder 로 구성이 되어 있는데 encoder 의 역할은 입력된 이미지를 압축된 형태로 표현하는게 목적임
RNN 으로 얘기하자면 일종의 context vector 를 만들어내는 게 됨
근데 decoder 의 목적은 원본을 그대로 다시 복원하는게 목적임
seq2seq 의 입장인데 입력이 나 자신이고 네트워크는 random initialize 가 되었기 때문에 어떤 vector 값이 나올 것임
근데 그 vector 값을 decoding 해서 본인 스스로가 나오도록 학습을 하게 됨
이게 왜 중요하냐면?
Autoencoder network 에서 Compressed 되어있는 Neural network 의 vector 정보를 가져오면 그 말은 입력된 이미지에
대한 vector 값이 될 수 있음
왜냐면 본인 스스로를 가장 잘 표현할 수 있게 학습된 모델이기 때문임
이걸 그대로 BERT 에 대입해보자.
BERT 는 self-attention 즉, Transformer 를 사용한 모델임
그래서 입력된 정보를 다시 입력된 정보로 representation 하는걸 목적으로 학습이 되게 됨
근데 한가지 다른점은 MASKED 라는 기술을 사용함
무슨말이냐면 입력된 이미지 자체에 중간중간에 MASKING 을 하게 됨
MASKING 을 하게되면 원본 이미지를 복원하기가 더 어려워지게 됨
이렇게 그냥 자연어를 학습을 할 때 입력된걸 그대로 다시 뱉어내도록 학습하는게 아니라 MASK 를 함으로써 더 어렵게 만든 문제를
해결하는 과정으로서 언어를 좀 더 확실하게 학습하는 방법으로 만들어진게 BERT 임
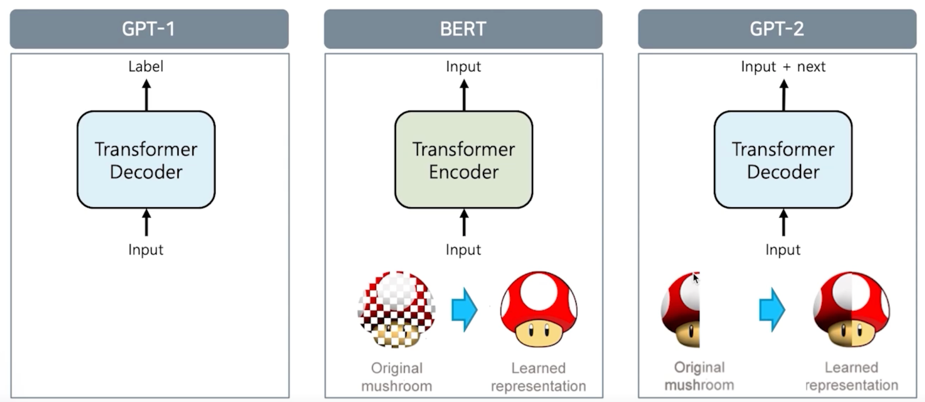
GPT-1 은 decoder 부분만으로 이루어져있고 이미지를 sequence 로 잘라서 다음부분을 예측하는 방식으로 이루어져 있다고 생각하면 됨
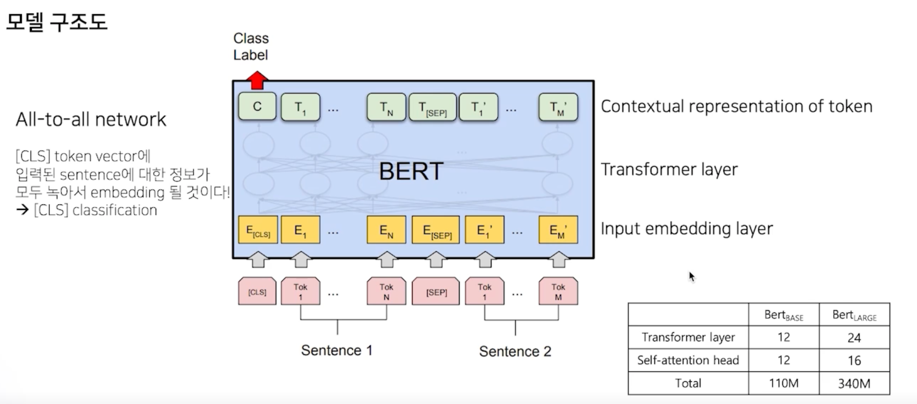
input layer 는 sentence 2개를 입력으로 받음
sentence1 에 [SEP] 토큰을 부착하고 sentence2 가 들어가게 됨
BERT 는 Transformer 12개의 layer 로 구성되어 있음
[CLS] 토큰은 sentence1 과 sentence2 가 Next sentence 관계인지 혹은 전혀 상관없는 sentence 로 만들어져있는지 그
클래스를 분류하기 위해 학습됨
BERT 구조가 왜 의미를 가지냐면?
BERT 내부의 Tansformer 가 All-to-ALL network 로 연결이 되어있고 그렇기 때문에 [CLS] 토큰의 출력벡터가 sentence1 과
sentence2 를 포괄하고 있는 어떤 벡터로 녹아든다고 가정을 두고 있음
실제로 [CLS] 토큰이 sentence1 과 sentence2 를 잘 표현하기 위해 그 [CLS] 토큰 위에 Classification layer 를 부착해서
pre-training 을 진행을 하게 되는 것임
학습 코퍼스 데이터
- BooksCorpus (800M words)
- English Wikipedia (2,500M words without lists, tables and headers)
- 30,000 token vocabulary
데이터의 tokenizing
- WordPiece tokenizing
- 빈도수 기반으로 tokenizing
- He likes playing $\rightarrow$ He likes play ##ing
- 입력 문장을 tokenizing 하고, 그 token 들로
token sequence를 만들어 학습에 사용 - 2개의 token sequence 가 학습에 사용

** Masked Language Model**
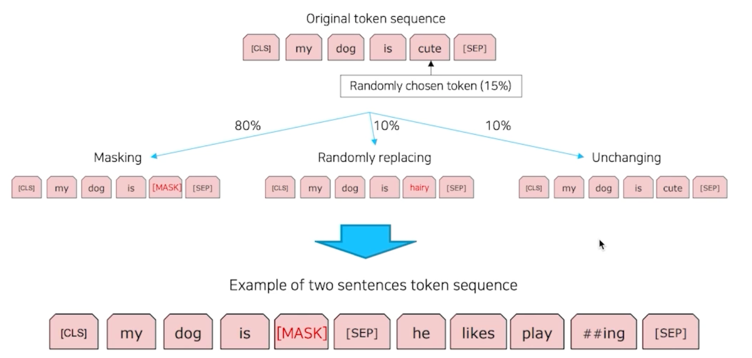
입력된 토큰이 완성이 되었으면 [CLS] 토큰과 [SEP] 토큰을 제외하고 나머지 단어들에 대해서 15% 랜덤으로 masking 해줌
NLP 실험
GLUE datasets
- MNLI: Multi-Genre Natural Language Inference
- 두 문장의 관계 분류를 위한 데이터셋
- QQP: Quora Question Pairs
- 두 질문이 의미상 같은지 다른지 분류를 위한 데이터셋
- QNLI: Question Natural Language Inference
- 질의응답 데이터셋
- SST-2: The Stanford Sentiment Treebank
- 영화 리뷰 문장에 관한 감성 분석을 위한 데이터셋
- CoLA: The Corpus of Linguistic Acceptability
- 문법적으로 맞는 문장인지 틀린 문장인지 분류를 위한 데이터셋
- STS-B: The Semantic Textual Similarity Benchmark
- 뉴스 헤드라인과 사람이 만든 paraphrasing 문장이 의미상 같은 문장인지 비교를 위한 데이터셋
- MRPC: Microsoft Research Paraphrase Corpus
- 뉴스의 내용과 사람이 만든 문장이 의미상 같은 문장인지 비교를 위한 데이터셋
- RTE: Recognizing Textual Entailment
- MNLI 와 유사하나, 상대적으로 훨씬 적은 학습 데이터셋
- WNLI: Winograd NLI
- 문장 분류 데이터셋
SQuAD v1.1 - 질의응답 데이터셋 CoNLL 2003 Named Entity Recognition datasets - 개체명 분류 데이터셋 SWAG: Situations With Adversarial Generations
- 현재 문장 다음에 이어질 자연스러운 문장을 선택하기 위한 데이터셋
이런 데이터셋이 중요한 이유는 언어모델의 성능평가의 지표가 될 수 있음
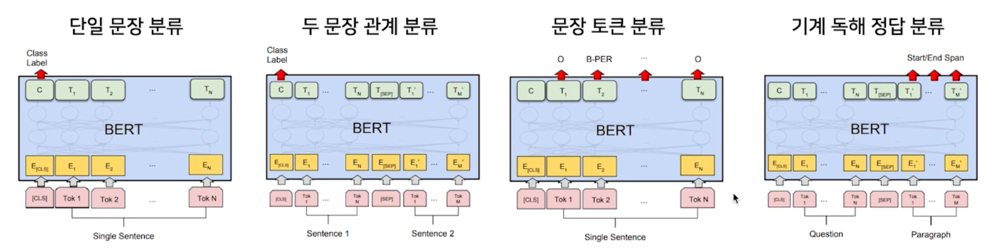
다양한 task 를 이 4가지 모델로 다 실험할 수 있음
- 단일 문장 분류
- BERT 모델에 하나의 입력문장이 주어졌을 때 이 문장이 어떤 class 에 속하는가를 분류하는 task
- 두 문장의 관계 분류
- 문장 2개가 입력으로 들어가고 이 두개의 문장이 Nest Sentence 인지를 예측하는 것도 하나의 task 가 되고 혹은 sentence1 이 sentence2 의 가설이 된다거나 이런 것도 있고 두 문장의 유사도도 비교할 수 있음
- 문장 토큰 분류
- 보통은 [CLS] 토큰이 입력된 sentence 의 정보가 녹아들어있다고 가정을 두게되는데 문장 토큰 분류는 각 토큰들의 output 에 분류기를 부착하는 것
- 토큰들 위에 분류기를 부착해서 이 토큰이 어떤 label 을 가지게 되는지 분류하게 됨
- 대표적으로 개체명인식기가 있음
- 기계 독해 정답 분류
- 두 가지 정보가 주어지게되는데 하나는 질문(예. 이순신의 고향은 어디인가?) 이런 질문이 주어지고 그 다음에는 정답이 포함된 문서가 주어짐
- 그러면 이 모델의 역할은 문서 내에 굉장히 많은 토큰이 존재할텐데 이 토큰내에서 정답이 start point 가 어디고 end point 가 어디다 이걸 잡아내는게 기계 독해 정답 분류 task 임
1.2 BERT 모델의 응
감성 분석
네이버 영화 리뷰 코퍼스 (https://github.com/e95/nsmc) 로 감성 분석
학습: 150,000 문장 / 평가: 50,000 문장 (긍정: 1, 부정: 0)
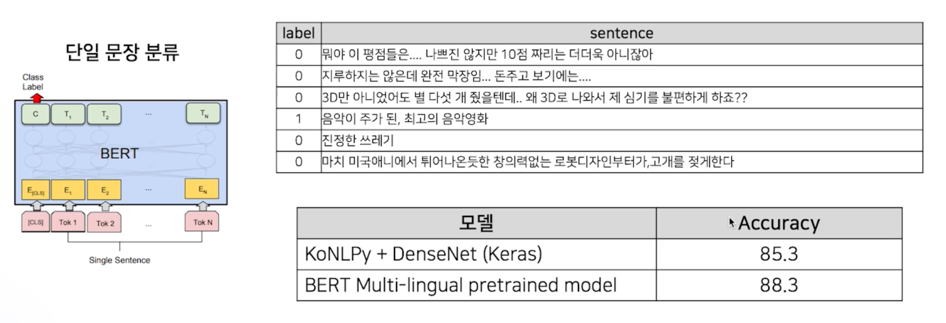
요즘은 91점은 나와야 SOTA 모델이 되는 듯
관계 추출
KAIST 가 구축한 Silver data 사용 (1명의 전문가가 annotation)
학습: 985,806 문장 / 평가: 100,001 문장
총 81개 label (관계 없음 포함)
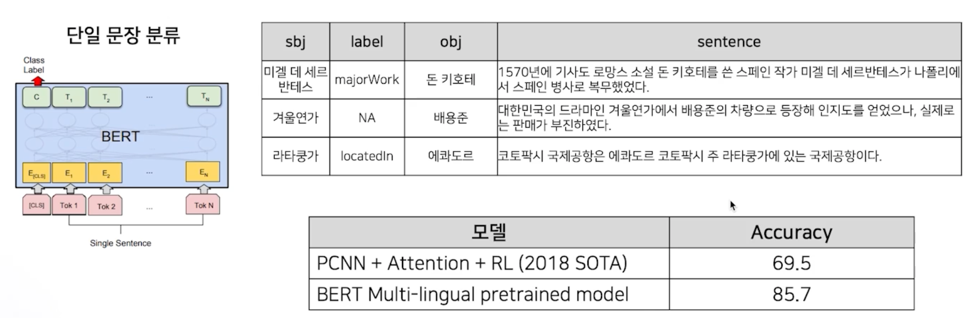
의미 비교
디지털 동반자 패러프레이징 질의 문장 데이터를 이용하여 질문-질문 데이터 생성 및 학습
학습: 3,401 문장 쌍 (유사 X: 1,700개, 유사 O: 1,701개)
평가: 1,001 문장 쌍 (유사 X: 500개, 유사 O: 501개)

sentence1 과 sentence2 를 보면 너무 상관없는 주제로 데이터가 만들어짐
이것도 전처리의 문제라고 볼 수 있는데 이런 식으로 학습한 모델은 다른 곳에서 쓸수가 없음
왜냐면?
실제로 우리가 분류해야 하는 문장은 굉장히 의미가 유사함
예를 들어 sentence1 이 판타지소설 추천해주세요, sentence2 는 무협소설 추천해주세요 이게 모델 입장에서 봤을때는
둘 다 장르소설 추천이라는 요소를 가지고 embedding 이 될 것임
그러면 모델입장에서는 이 두 개의 문장벡터를 보면 굉장히 유사할 것임
사실 분류모델은 이런 비슷한 문장을 분류하는 것을 목적으로 두는게 맞음
점수가 98.3 으로 높지만 데이터 설계부터 잘 못 되었음
개체명 분석
ETRI 개체명 인식 데이터를 활용하여 학습 및 평가 진행 (정보통신단체표준 TTAKO-10.0852)
학습: 95,787 문장 / 평가: 10,503 문장
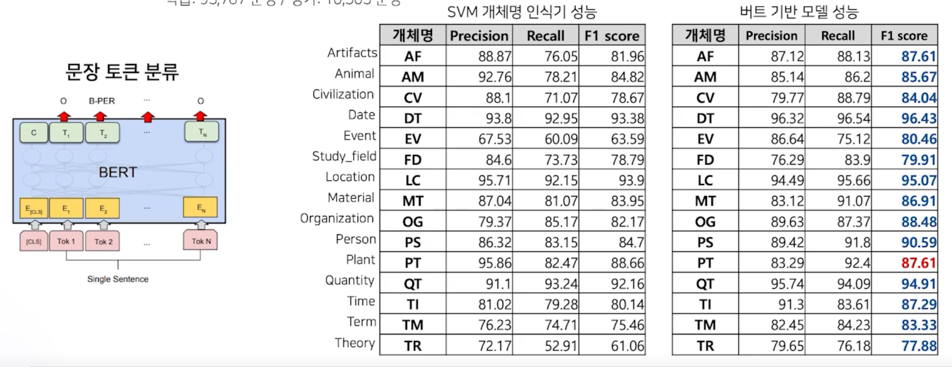
기계 독해
LG CNS 가 공개한 한국어 QA 데이터 셋, KorQuAD (https://korquad.github.io/)
Wikipedia article 에 대해 10,645 건의 문단과 66,181 개의 질의응답 (Training set 60,407개, Dev set 5,774개)
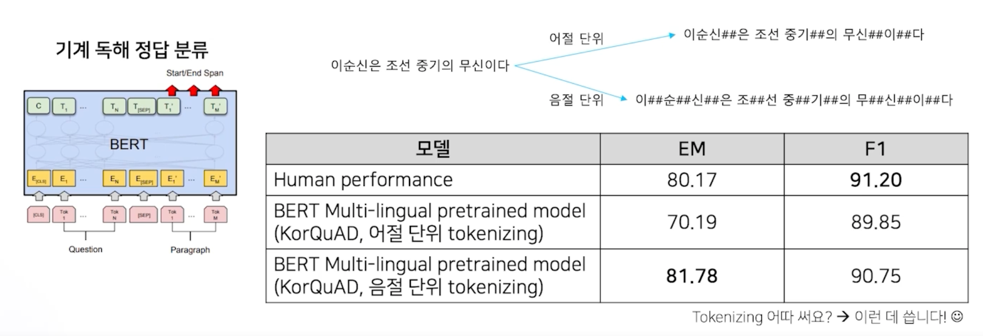
task 에 맞춰서 나의 tokenizer 를 정의하고 쓰는게 중요
1.3 한국어 BERT 모델
ETRI KoBERT 의 tokenizing
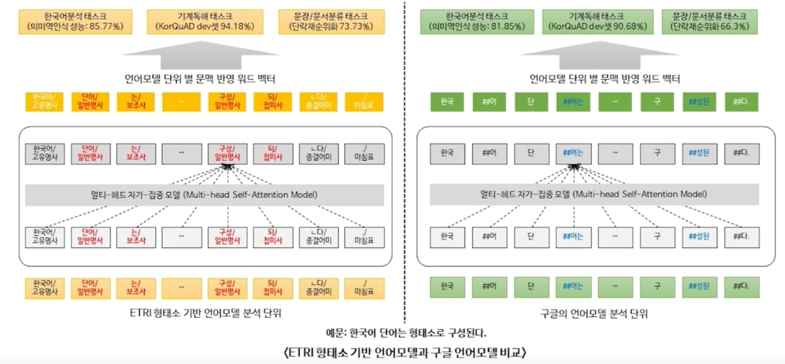
WordPiece Tokenizer 를 사용을 하되 먼저 형태소 단위로 분리를하고 형태소 단위로 분리된 것을 바탕으로 WordPiece Tokenizer 를 사용함
이렇게 하면 형태소의 최소역할은 의미를 가지는 최소의 단위로 분리하겠다는 건데 이순신 과 은 은 형태소 tokenizer 를
통해서 반드시 분리를 하겠다가 된거고 이거 다음에 WordPiece tokenizer 를 태우게되면 이 와 순신 이 분리될 수 있을거고
왜냐면 이 는 성씨로 많이 들어가니까 그래서 이런식으로 분리를 한국어에 특화되게 만들었고 그랬더니 Google 모델보다 성능이 거의
10점이상 오르는 엄청나게 성능이 좋아지게 됨
두번째는 SKT 에서 공개한 KoBERT 인데 얘는 형태소 tokenizer 를 사용하지 않고 WordPiece tokenizer 만 사용했고
KorQuAD 에서는 ETRI KoBERT 보다 성능이 떨어지게 됨
그런데 장단점이 있음
ETRI KoBERT 를 사용하려면 ETRI 형태소 분석기를 사용해야 함
그래서 다 본인의 목적과 상황에 맞게 취사선택이 필요함
한국어 tokenizing 에 따른 성능 비교 (https://arxiv.org/abs/2010.02534)
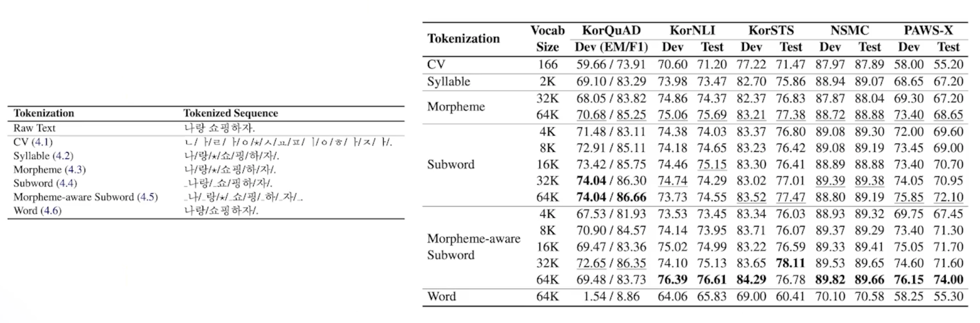
카카오브레인과 이루다로 유명한 스캐터랩 PingPong 팀에서 함께 협업해서 논문으로 제출함
형태소 분석기를 태우고 sub-word tokenizer 를 사용한게 성능이 가장 좋았음을 보여줌
Advanced BERT model
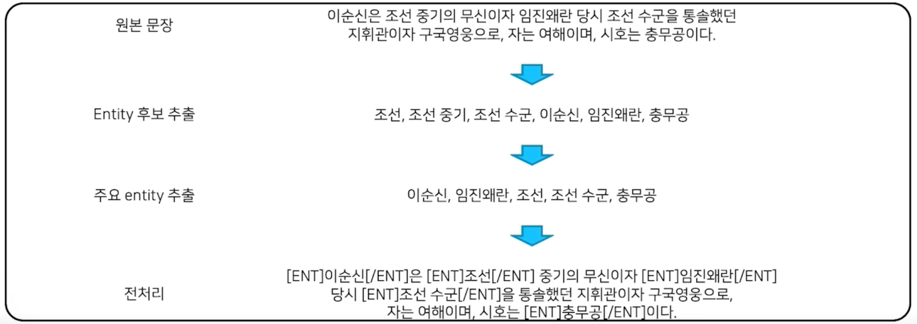
KBQA 에서 가장 중요한 entity 정보가 기존 BERT 에서는 무시
Entity linking 을 통한 주요 entity 추출 및 entity tag 부착
Entity embedding layer 의 추가
형태소 분석을 통한 NNP 와 entity 우선 chunking masking
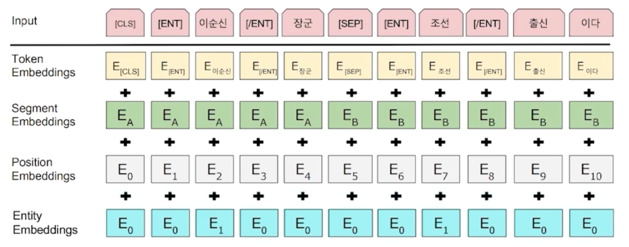
기존의 token embedding, setment embedding, position embedding 에다가 entity embedding 을 추가했더니
학습 데이터: 2019년 06월 20일 Wiki dump (약 4,700만 어절)
Batch: 128
Sequence length: 512
Training steps: 300,000 (대략 10 epochs)
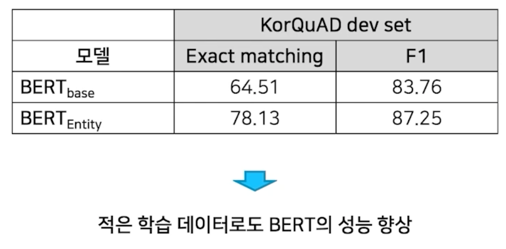
동일한 데이터를 사용했고 앞서서 BERT 모델처럼 수십개를 사용한게 아니고 600M 정도되는 Wiki 데이터를 사용했고
학습도 되게 조금 돌렸음
이렇게 돌려봤을 때 기존 Base BERT 모델 대비 Entity embedding 을 추가한 BERT 모델의 성능이 더 좋아졌음을 보여줌
실제로 entity 를 명시하는 모델이 ERNIE 모델이 SOTA 를 찍고 있음
실습
Tokenizer 의 응용
from transformers import AutoModel, AutoTokenizer, BertTokenizer
# Store the model we want to use
MODEL_NAME = "bert-base-multilingual-cased"
# We need to create the model and tokenizer
model = AutoModel.from_pretrained(MODEL_NAME)
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
이 코드를 실행하면 다운로드 페이지가 뜨면서 모델이 필요한 파라미터를 담고있는 파일이라던가 혹은 configuration 그리고 vocab 파일 이런 요소들을 전부다 다운받게 됨
이 모델 같은 경우는 multilingual 모델이고 WordPiece vocab 이 12만개 가까이 됨
굉장히 큰 vocab 을 가지고 있지만 이 중에 한국어는 8,000개 정도 밖에 없다고 생각하면 됨
한국어 corpus 를 이용해서 vocab 을 만들 때 대충 30,000개 정도 정의를 하게되면 한자나 특수기호 이런 것들도 왠만하면
다 들어감
그래서 나중에 혹시 자신의 BERT 모델을 만들거나 tokenizer 를 만들 때 WordPiece 단위로 하게되면 30,000개 정도로 정의하면
vocab 이 적절하게 될 것 같음
tokenizer 를 test 해보자
text = "이순신은 조선 중기의 무신이다."
tokenized_input_text = tokenizer(text, return_tensors="pt")
for key, value in tokenized_input_text.items():
print("{}:\n\t{}".format(key, value))
return_tensors="pt": pytorch 로 반환을 하겠다라는 의미

- token_type_ids : 문장이 하나만 들어가면 0 으로 전부 되고 두 문장이 들어간 경우 sentence2 에는 1로 들어감
- attention_mask : tokenizer 에서 가장 중요한 기능이 padding 이라고 했는데 padding 같은 경우는 0으로 초기화 됨
print(tokenized_input_text['input_ids']) # input text를 tokenizing한 후 vocab의 id
print(tokenized_input_text.input_ids)
print(tokenized_input_text['token_type_ids']) # segment id (sentA or sentB)
print(tokenized_input_text.token_type_ids)
print(tokenized_input_text['attention_mask']) # special token (pad, cls, sep) or not
print(tokenized_input_text.attention_mask)
dictionary 형태로 되어 있기 때문에 tokenized_input_text['input_ids'] 이렇게나 tokenized_input_text.input_ids
이렇게 가져올 수 있음
이번엔 decoding 된 문장을 봐보자.
tokenized_text = tokenizer.tokenize(text)
print(tokenized_text)
input_ids = tokenizer.encode(text)
print(input_ids)
decoded_ids = tokenizer.decode(input_ids)
print(decoded_ids)

tokenizer() 에 바로 text 를 tokenizer(text) 처럼 넣었을 경우에는 input_ids, token_type_ids,
attention_mask 를 바탕으로 나오게 됨
tokenizer.tokenize(): 함수는 입력된 문장을 tokenizing 하는 것임tokenizer.encode(): 토큰화된 문장의 인코딩된 결과tokenizer.decode(): [CLS], [SEP] 토큰이 들어감- 왜 붙냐면?
tokenize()함수에 자동으로 special 토큰을 부착하게 되어 있음 - 원치 않는 경우에는
add_special_tokens=False를 사용하면 됨
- 왜 붙냐면?
tokenized_text = tokenizer.tokenize(text, add_special_tokens=False)
print(tokenized_text)
input_ids = tokenizer.encode(text, add_special_tokens=False)
print(input_ids)
decoded_ids = tokenizer.decode(input_ids)
print(decoded_ids)

일반적으로는 BERT 의 tokenizer 를 다른데 쓸 때는 special token 을 없앤다거나 이런데 썼던거 같음
하지만 왠만하면 이 옵션을 끄지 않고 사용
이전 실습에서 padding 과 truncation 이 중요하다고 말했음
tokenized_text = tokenizer.tokenize(
text,
add_special_tokens=False,
max_length=5,
truncation=True
)
print(tokenized_text)
input_ids = tokenizer.encode(
text,
add_special_tokens=False,
max_length=5,
truncation=True
)
print(input_ids)
decoded_ids = tokenizer.decode(input_ids)
print(decoded_ids)

tokenizer.tokenize() 함수에 truncation 옵션이 있음
위의 코드에서는 text 를 tokenizing 하는데 special 토큰을 부착하지말고 max_length 는 5로 하되 truncation = True 로 해버리면 5개의 토큰으로두고 뒤에가 잘려져버리게 됨
tokenizer 는 토큰단위로 자르는 것이기 때문에 원래 입력문장과 length 와 관련성이 없음
무슨말이냐면 “이순신은 조선의 무신이다” 라는 문장이 긴데 이걸 max_length=5 로 했을 때 음절 단위로 5개가 짤린다거나
어절단위로 몇개가 짤린다거나 이런 규칙이 있는게 아니고 입력된 문장을 tokenizing 했을 때 나오는 토큰의 5개를 자르게 됨
그래서 이 경우에 decoding 을 하게되면 “이순신은 조선” 이거밖에 안나오게 됨
마찬가지로 padding 도 할 수 있음
print(tokenizer.pad_token)
print(tokenizer.pad_token_id)
tokenized_text = tokenizer.tokenize(
text,
add_special_tokens=False,
max_length=20,
padding="max_length"
)
print(tokenized_text)
input_ids = tokenizer.encode(
text,
add_special_tokens=False,
max_length=20,
padding="max_length"
)
print(input_ids)
decoded_ids = tokenizer.decode(input_ids)
print(decoded_ids)

tokenize 함수에 padding 을 넣어주기만 하면 됨
padding 의 옵션이 굉장히 다양함
문장이 들어갔을 때 앞부분에 padding 을 부착해서 최대 length 를 채울수도 있고 아니면 뒤에 최대 length 를 채울수도 있고
반면에 segment A, B 가 들어간 경우 segment A 를 padding 해서 max_length 를 채울수도 있고 segment B 를 padding 해서
max_length 를 채울수도 있음
이런 옵션들을 자유롭게 사용가능
이번엔 새로운 token 을 추가해보자 즉, 내가 원하는 단어를 vocab 에 추가하자
다만 뒤부터 정상적으로 tokenize 되지 않는 문장이 있음
text = "깟뻬뜨랑 리뿔이 뜨럽거 므리커럭이 케쇽 냐왜쇼 우뤼갸 쳥쇼섀료다혀뚜여"
tokenized_text = tokenizer.tokenize(text, add_special_tokens=False)
print(tokenized_text)
input_ids = tokenizer.encode(text, add_special_tokens=False)
print(input_ids)
decoded_ids = tokenizer.decode(input_ids)
print(decoded_ids)

이 경우 [UNK] 로 바꿔버림
[UNK] 가 많으면 많을수록 원본 데이터의 의미가 사라져버림
왜냐면 정보표현 할 있는 토큰이 없으니까
그러면 이것을 원치않기 때문에 만약에 에어비앤비의 리뷰 텍스트들을 분류하는 task 를 하고싶다 그러면 에어비앤비에 맞는
에어비앤비의 corpus 에 맞도록 vocab 을 추가해줘야함
임의로 vocab 을 추가해줌
added_token_num = tokenizer.add_tokens(["깟뻬뜨랑", "케쇽", "우뤼갸", "쳥쇼", "섀료"])
print(added_token_num)
tokenized_text = tokenizer.tokenize(text, add_special_tokens=False)
print(tokenized_text)
input_ids = tokenizer.encode(text, add_special_tokens=False)
print(input_ids)
decoded_ids = tokenizer.decode(input_ids)
print(decoded_ids)

add_tokens() : 함수를 통해서 list 를 받으면 vocab 에 추가됨
그래서 나중에 tokenizing 을 할 때 vocab 이 반영되서 tokenizing 이 되게 됨
decoding 했을 때 완벽하게 문장이 복원 됨
예를 들어서 현재 만들어진 vocab 이 Wiki 만을 토대로 만들어진 상태에서 전문 분야성을 가지고 있는 화학논문을 분석하고 싶을 수 있음
근데 화학논문에 경우에는 화학식도 vocab 에 없을것이고 용어자체도 엄청 생소할 것임
그러면 기존에 만들어진 BERT 를 가지고 분류모델을 학습하게 되면 아마 대부분이 [UNK] 가 나올 것임
그러면 분류모델을 제대로 학습할 수 없을 것임
그래서 이렇게 vocab 추가라는 방법을 사용해서 내가 원하는 task 내가 작업할 corpus 에 맞춰서 tokenizer 수정이 필요함
특정 역할을 위한 special token 도 추가할 수 있음
text = "[SHKIM]이순신은 조선 중기의 무신이다.[/SHKIM]"
# [ENTITY]이순신[/ENTITY]
tokenized_text = tokenizer.tokenize(text, add_special_tokens=False)
print(tokenized_text)
input_ids = tokenizer.encode(text, add_special_tokens=False)
print(input_ids)
decoded_ids = tokenizer.decode(input_ids)
print(decoded_ids)

예제로 들었던게 ENTITY TAG 를 [ENTITY] 이순신 [/ENTITY] 처럼 넣어서 BERT 모델에게 명시적으로 이순신은 ENTITY 입니다를
알려주고 싶다면 special token 을 추가해줘야 함
그런데 기존의 special token 을 [SHKIM] 이렇게 해버린다 그러면 토큰이 토큰처럼 안여겨지게 됨
전부 분리가 되게 됨
text = "[SHKIM]이순신은 조선 중기의 무신이다.[/SHKIM]"
added_token_num += tokenizer.add_special_tokens({"additional_special_tokens":["[SHKIM]", "[/SHKIM]"]})
tokenized_text = tokenizer.tokenize(text, add_special_tokens=False)
print(tokenized_text)
input_ids = tokenizer.encode(text, add_special_tokens=False)
print(input_ids)
decoded_ids = tokenizer.decode(input_ids)
print(decoded_ids)
decoded_ids = tokenizer.decode(input_ids,skip_special_tokens=True)
print(decoded_ids)

add_special_token() 를 사용해서 넣어줘야 함
코드를 보면 입력이 dictionary 형태로 되어있고 왜그러냐면 special token 은 정말로 special 하기 때문에 문장의 시작을
표현하는 것도 있을거고 padding token, CLS token 이 있을건데 이런 경우 dictionary 로 넣을 때 “cls_token” 이라고
넣게되면 그게 CLS 토큰으로 등록이 되게 됨
내가 원하는 건 그런 토큰을 건드리고 싶지 않음
“additional_special_token” 이라고 해서 넣어줌
추가해주고 나서는 [SHKIM] [/SHKIM] 으로 분리가 되는 것을 확인할 수 있음
special 토큰을 만들고 나면 나중에 학습데이터를 special token 을 부착해서 input 에 넣고 싶을 때 원래는 tokenizing 된 거에서 id 값에 special token 위치 찾아서 list 에 id 값으로 append 를 해줘야하는데 tokenizer 라이브러리를 사용하게 되면 원본 문서 자체에 special token 을 부착을 해주면 그냥 잘 자르게 됨
이렇게 토큰을 추가해주고 나면
added_token_num 이 7개가 됨
이게 왜 중요하냐면?
이미 pre-fix 된 모델 자체는 embedding layer 에 있는 vocab size 가 약 12만개로 고정이 되어 있음
그렇기 때문에 이걸 벗어나는 id 가 input 으로 들어오게 되면 에러가 남
그럼 나중에 모델 resize 를 해줘야 함 그 때 resize 의 기준이 added_token_num 이 됨
다양한 task 가 있는데 단일문장일때, 다중 문장일 때 tokenizer 도 이쁘게 해줌
# Single segment input
single_seg_input = tokenizer("이순신은 조선 중기의 무신이다.")
# Multiple segment input
multi_seg_input = tokenizer("이순신은 조선 중기의 무신이다.", "그는 임진왜란을 승리로 이끌었다.")
print("Single segment token (str): {}".format(tokenizer.convert_ids_to_tokens(single_seg_input['input_ids'])))
print("Single segment token (int): {}".format(single_seg_input['input_ids']))
print("Single segment type : {}".format(single_seg_input['token_type_ids']))
# Segments are concatened in the input to the model, with
print()
print("Multi segment token (str): {}".format(tokenizer.convert_ids_to_tokens(multi_seg_input['input_ids'])))
print("Multi segment token (int): {}".format(multi_seg_input['input_ids']))
print("Multi segment type : {}".format(multi_seg_input['token_type_ids']))

단일 문장은 tokenizer 에 그냥 넣어주고 두 문장인 경우 ‘,’ 로 구분해서 넣어주면 끝
tokenizer 에 배열형태로 넣게 되면 똑같이 배열형태로 출력이 됨
# Padding highlight
tokens = tokenizer(
["이순신은 조선 중기의 무신이다.", "그는 임진왜란을 승리로 이끌었다."],
padding=True # First sentence will have some PADDED tokens to match second sequence length
)
for i in range(2):
print("Tokens (int) : {}".format(tokens['input_ids'][i]))
print("Tokens (str) : {}".format([tokenizer.convert_ids_to_tokens(s) for s in tokens['input_ids'][i]]))
print("Tokens (attn_mask): {}".format(tokens['attention_mask'][i]))
print()

BERT 모델 테스트
tokenizer 에 대한 실습이 됐으니 BERT 에 input 으로 넣어보자
text = "이순신은 [MASK] 중기의 무신이다."
tokenized_text = tokenizer.tokenize(text)
print(tokenized_text)

transformers 라이브러리의 pipeline 함수를 사용해서 fill-mask task 를 진행하면
from transformers import pipeline
nlp_fill = pipeline('fill-mask', model=MODEL_NAME)
nlp_fill("이순신은 [MASK] 중기의 무신이다.")
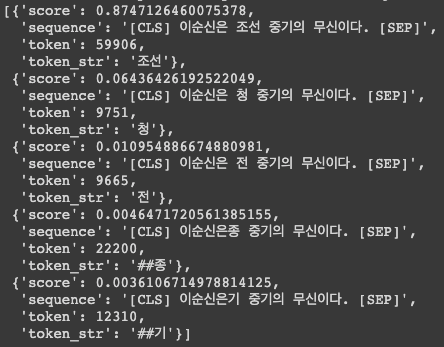
[MASK] 를 채워서 반환해줌
모델의 출력결과도 얻을 수 있음
tokens_pt = tokenizer("이순신은 조선 중기의 무신이다.", return_tensors="pt")
for key, value in tokens_pt.items():
print("{}:\n\t{}".format(key, value))
outputs = model(**tokens_pt)
last_hidden_state = outputs.last_hidden_state
pooler_output = outputs.pooler_output
print("\nToken wise output: {}, Pooled output: {}".format(last_hidden_state.shape, pooler_output.shape))
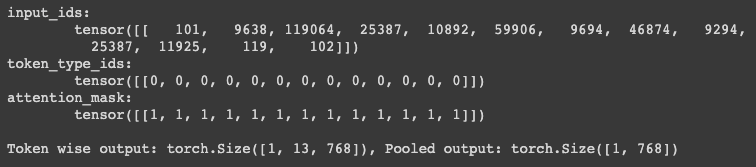
tokenizer 의 출력결과를 model 에 넣게되면 출력결과를 얻을 수 있음
‘last_hidden_state’ 을 사용하면 문장 token 들의 벡터를 얻어낼 수 있음
pooler_output 을 사용하면 [CLS] 토큰의 벡터만을 얻어낼 수 있음
만약 vocab 을 새롭게 추가했다면 model 의 embedding layer 사이즈를 늘려주는게 필요!!
print(model.get_input_embeddings())
model.resize_token_embeddings(tokenizer.vocab_size + added_token_num)
print(model.get_input_embeddings())

우리는 added_token_num 7 만큼 늘어남
[CLS] 토큰을 이용해서 유사도를 측정할 수 있음
무슨말이냐면 [CLS] 토큰 (pooler_output) 을 사용하면 문장 벡터의 output 이라고 말했는데 그 말은 두 문장간의 벡터 유사도도
계산이 가능하다는 의미
sent1 = tokenizer("오늘 하루 어떻게 보냈나요?", return_tensors="pt")
sent2 = tokenizer("오늘은 어떤 하루를 보내셨나요?", return_tensors="pt")
sent3 = tokenizer("이순신은 조선 중기의 무신이다.", return_tensors="pt")
sent4 = tokenizer("깟뻬뜨랑 리뿔이 뜨럽거 므리커럭이 케쇽 냐왜쇼 우뤼갸 쳥쇼섀료다혀뚜여", return_tensors="pt")
outputs = model(**sent1)
sent_1_pooler_output = outputs.pooler_output
outputs = model(**sent2)
sent_2_pooler_output = outputs.pooler_output
outputs = model(**sent3)
sent_3_pooler_output = outputs.pooler_output
outputs = model(**sent4)
sent_4_pooler_output = outputs.pooler_output
예를들어 이렇게 4개의 문장의 pooler_output 벡터를 저장했음
그리고 문장간의 유사도 비교를 해봤음
from torch import nn
cos = nn.CosineSimilarity(dim=1, eps=1e-6)
print(cos(sent_1_pooler_output, sent_2_pooler_output))
print(cos(sent_2_pooler_output, sent_3_pooler_output))
print(cos(sent_3_pooler_output, sent_4_pooler_output))
print(cos(sent_1_pooler_output, sent_4_pooler_output))
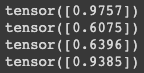
문장1(오늘 하루 어떻게 보냈나요?)과 문장2(오늘은 어떤 하루를 보내셨나요?) 의 유사도는 97점이 나오고
2번째, 3번째는 굉장히 낮은 유사도를 가지고 있고 1번과 4번은 은근히 높은 유사도를 가지고 있음
cosing similarity 가 높다고 하더라도 의미론적으론 유사하지 않을수도 있음
0.5 아래로는 유사하지 않은걸로 봐도 되는거 아니냐라는 threshold 자체가 의미가 없음
실습
BERT 를 이용한 Chatbot 만들기
질의응답 Dataset 예시
chatbot_Question = ['기차 타고 여행 가고 싶어','꿈이 이루어질까?','내년에는 더 행복해질려고 이렇게 힘든가봅니다', '간만에 휴식 중', '오늘도 힘차게!'] # 질문
chatbot_Answer = ['꿈꾸던 여행이네요.','현실을 꿈처럼 만들어봐요.','더 행복해질 거예요.', '휴식도 필요하죠', '아자아자 화이팅!!'] # 답변
print(chatbot_Question[:])
print(chatbot_Answer[:])

그 다음에는 [CLS] 토큰을 얻어야 함
def get_cls_token(sent_A):
model.eval()
tokenized_sent = tokenizer(
sent_A,
return_tensors="pt",
truncation=True,
add_special_tokens=True,
max_length=128
)
with torch.no_grad():# 그라디엔트 계산 비활성화
outputs = model( # **tokenized_sent
input_ids=tokenized_sent['input_ids'],
attention_mask=tokenized_sent['attention_mask'],
token_type_ids=tokenized_sent['token_type_ids']
)
logits = outputs.last_hidden_state[:,0,:].detach().cpu().numpy()
return logits
문장을 tokenizing 하는데 긴 문장은 truncation 해주고 앞에 [CLS] 토큰과 뒤에 [SEP] 토큰 부착을 명시해줌 그리고 padding 이 없는데 padding 되지는 않게 설정해놓음
그리고 모델에 tokenizing 했던 결과값들을 input 으로 넣게 됨
이렇게 안하고 model(**tokenized_sent) 이러게 해줘도 동일하게 동작함
- input_ids : 토큰화된 문장의 vocab id 가 들어가게 됨
- attnetion_mask : padding 된 건 0, 아니면 1 인데 padding 안된곳만 봐라를 명시적으로 알려주는 역할
- token_type_ids : sentence 하나인 경우는 0으로 다 초기화 되어있음
outputs.last_hidden_state 의 첫번째를 가져오니까 [CLS] 토큰임
query = '아 여행가고 싶다~'
query_cls_hidden = get_cls_token(query)
print(query_cls_hidden)
print(query_cls_hidden.shape)
“아 여행가고 싶다~” 가 사전에 주어지 문장이 아닌데 입력으로 넣게되면 [CLS] 토큰에 대한 768차원의 벡터를 얻게 됨
이렇게 얻어낸 걸 가지고 있고 query vector 는 [CLS] 토큰이 됨
그 다음은 사전에 준비했던 데이터셋(Question, Answer 가 존재하는) 거기서 Question 정보만 가져다가 [CLS] 토큰으로 바꿔버림
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
dataset_cls_hidden = []
for q in chatbot_Question:
q_cls = get_cls_token(q)
dataset_cls_hidden.append(q_cls)
dataset_cls_hidden = np.array(dataset_cls_hidden).squeeze(axis=1)
print(dataset_cls_hidden) # 데이터셋의 질문에 대한 [CLS] 토큰 벡터
print(dataset_cls_hidden.shape)
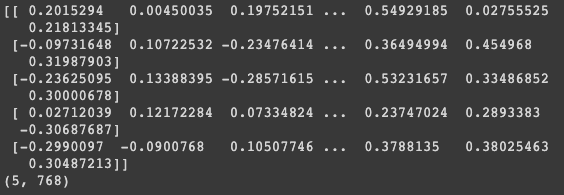
이 코드를 실행하면 5개의 question 들이 768차원의 벡터로 나온걸 확인할 수 있음
사용자 쿼리 벡터 획득했고 데이터셋의 Question 에 대한 벡터 획득했음
남은거는 각각을 비교하는 것만 남음
그래서 코사인 유사도를 파악할 수 있음
cos_sim = cosine_similarity(query_cls_hidden, dataset_cls_hidden) # 데이터셋의 0번째 질문과 가장 유사하군요!
print(cos_sim)

cosine_similarity 는 sklearn 에서 제공하는 함수
Question 0 번과 가장 유사함을 확인할 수 있음
그러면 Qeustion 0 번에 해당하는 답변을 내어주면 이게 chatbot 이 됨
top_question = np.argmax(cos_sim)
print('나의 질문: ', query)
print('저장된 답변: ', chatbot_Answer[top_question])

작성자
* 김성현 (bananaband657@gmail.com) 1기 멘토 김바다 (qkek983@gmail.com) 박상희 (parksanghee0103@gmail.com) 이정우 (jungwoo.l2.rs@gmail.com) 2기 멘토 박상희 (parksanghee0103@gmail.com) 이정우 (jungwoo.l2.rs@gmail.com) 이녕우 (leenw2@gmail.com) 박채훈 (qkrcogns2222@gmail.com)
댓글남기기