Day_39 01. BERT 기반 두 문장 관계 분류 모델 학습
작성일
BERT 기반 두 문장 관계 분류 모델 학습
1. 두 문장 관계 분류 task 소개
1.1 두 문장 관계 분류 task
주어진 2개의 문장에 대해, 두 문장의 자연어 추론과 의미론적인 유사성을 측정하는 task
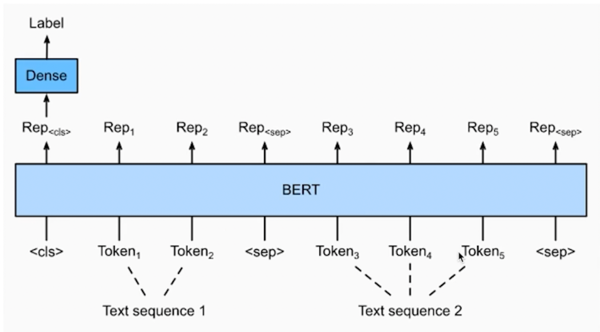
Natural Language Inference (NLI)
- 언어모델이 자연어의 맥락을 이해할 수 있는지 검증하는 task
- 전체문장(Premise)과 가설문장(Hypothesis)을 Entailment(함의), Contradiction(모순), Neutral(중립) 으로 분류
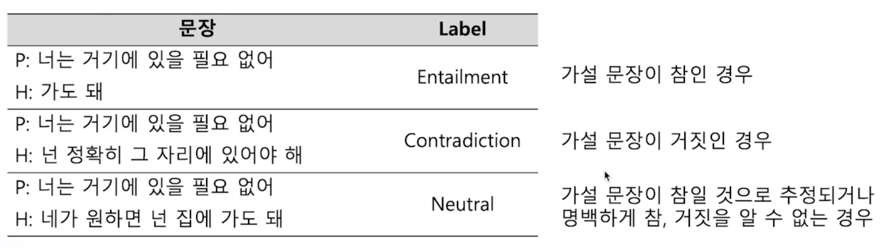
label 3개를 classification 하는 문제
Semantic text pair
- 두 문장의 의미가 서로 같은 문장인지 검증하는 task

2가지 class 를 분류하는 문제
2. 두 문장 관계 분류 모델 학습
2.1 Information Retrieval Question and Answering (IRQA)
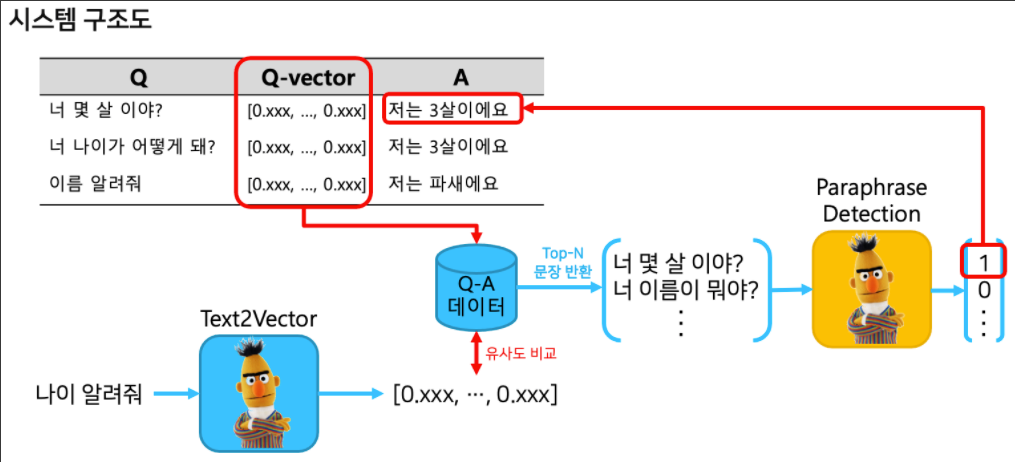
시스템 구조도
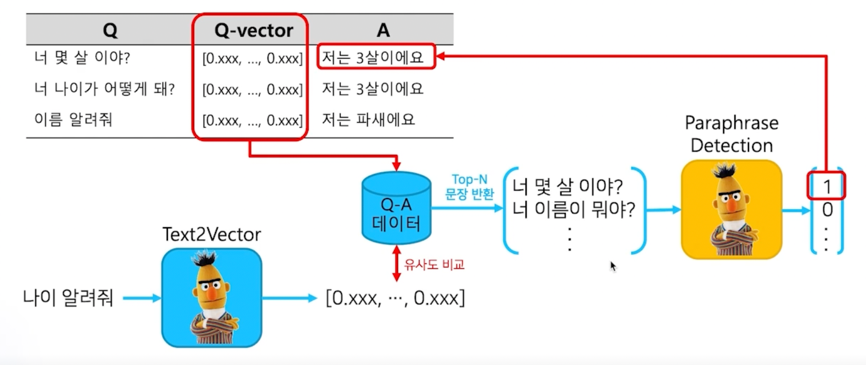
이 task 는 챗봇을 위한 task 인데 그 중에 IRQA 라는 task 임
사전에 정의해놓은 QA set 에서 가장 적절한 답변을 찾아내는 과정을 IRQA 라고 함
저번 실습에서 [CLS] 토큰을 이용해 cosine similarity 를 이용해 챗봇을 개발한것과 유사한 task 임
이번 실습에서는 나이 알려줘 라는 질문을 하게되면 BERT 를 통해서 sentence embedding 을 하게 됨
여기까지는 이전 챗봇과 동일함
그리고 사전에 정의한 table 에서 Question 과 Answer 가 pair 로 되어있는 table 도 역시 sentence embedding 을 하고
기존에 존재하던 Question 과 나의 Query 의 유사도를 비교를해서 가장 적절한 문장을 반환할 수 있음
여기 task 까지는 기존의 했던 task 와 동일한 task 인데 이 task 뒷단에 paraphrase detection 이라는 두 문장간의 관계
분류 task 를 학습한 모델을 부착시킬 예정임
이 모델을 부착하는 이유는 top-n 개로 문장을 반환할 수 있는데 그 중에 무조건 top-1 이 정답이 되지 않는 경우도 있음
그래서 paraphrase detection 모델이 진짜로 내가 질의한 query 와 사전에 정의된 question 이 실제로 유사한 의미를 가지고
있는지를 검증하고 그 검증 필터링을 통과해야지만 답변이 나오게 되는 task 임
실슴
두 문장 관계 분류를 위한 학습 데이터 구축
이번 task 의 목적은 paraphrase 된 두 문장이 서로 같은 의미를 가지고 있는지 분류하는 것임
paraKQC 라는 데이터를 가져오자
이 데이터는 두 문장이 pair 된 쌍이 있는게 아니라 하나의 문장에대해 10개의 유사한 paraphrase 된 문장 데이터를 가지고 있음
이 데이터는 조원익 님이라는 분께서 만들어 주셨음
!git clone https://github.com/warnikchow/paraKQC.git
데이터를 받았으면 실제로 데이터가 어떻게 생겼는지 확인해보자
data = open('/content/paraKQC/data/paraKQC_v1.txt')
lines = data.readlines()
for i in range(0,15):
print(lines[i]) # 10개씩 paraphasing

우리가 필요한 건 paraphrase 된 데이터와 paraphrase 되지 않은 데이터 2가지가 필요함
그래야지만 classification 이 가능해짐
이 실습의 목적은 그 데이터를 구축하는데 목적이 있음
그러면 지금은 10개씩 쌍으로 데이터가 묶여져 있지만 줄로만 나열이 되어있음
그래서 10개씩 데이터의 형태로 묶도록 하겠음
similar_sents = {}
similar_sent = []
total_sent = []
for line in lines:
line = line.strip()
sent = line.split('\t')[2]
total_sent.append(sent)
similar_sent.append(sent)
if len(similar_sent) == 10:
similar_sents[similar_sent[0]] = similar_sent[1:]
similar_sent = []
print(len(total_sent)) # 가장 유사한 문장을 찾기 위한 전체 문장 pool

데이터 형태로 문장을 하나씩 읽어나가면서 문장 10개를 읽게되는 순간 데이터 배열로 데이터 말뭉치를 빼도록 되어있음
전체문장은 total_sent 라는 배열에 저장해뒀음
for i in range(0,15):
print(total_sent[i])

total_sent 를 읽어보면 데이터셋에 있던 전체 문장이 순서대로 저장되어있음을 확인할 수 있음
print(len(similar_sents))
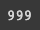
그 다음엔 10개의 묶음이 몇개 있는지 확인해보면 999개 의 paraphrase 된 묶음이 저장된 것을 확인할 수 있음
for i, key in enumerate(similar_sents.keys()): # 10개의 문장 중, 첫 번째 문장을 key
print('\n', key) # 나머지 9개의 문장을 value
for sent in similar_sents[key]: # 헷갈리니까 이걸 similar_sents dict라고 정의할게요 :-)
print("-", sent)
if i > 3:
break


이 저장된 데이터를 어떻게 쓰느냐?
데이터는 유사한 데이터와 유사하지 않은 데이터 이렇게 0 과 1 로 구분할 수 있는 데이터가 필요함
근데 우리가 가진 데이터는 전부다 유사한 데이터만 가지고 있음
그래서 유사하지 않은 데이터를 구축할 때 어떻게 하냐면?
아까 total_sent 라는 배열에 전체 문장을 저장해뒀음
그 중에서 random 으로 선택하게 되면 서로 다른 문장 의미가 다른 문장이 선택될 수 있음
하지만 이렇게 random 인 상태에서 선택을 하게 되면 문제가 발생할 수 있음
이렇게 되면 두 의미가 정말로 상반된 결과를 가지고 학습을 하게됨
그러면 문제가 정말로 쉬운 문제를 푸는 task 로 바뀌게 됨
그래서 어떻게 할거냐면?

이 key 값 value 를 가지고 있는 문장을 두고 이 문장을 BERT 를 통해서 sentence embedding 을 할 것임
그러면 key 문장의 sentence embedding 결과가 나올거고 그리고 total_sent 에 들어있는 문장중에 이 문장을
모두 sentence embedding 을 하고 가장 embedding 결과가 유사한 애를 선택하도록 할 것임
그러니까 모델이 봤을때는 sentence embedding 즉, embedding 결과가 유사한 두 문장이 있지만 실제로 이 두문장은
의미론적으론 다름
이러면 문제가 굉장히 어려워지게 됨
모델 입장에서는 어려운 문제를 학습하게 되는 것이기 때문에 나중에 우리가 test 를 할때도 어려운 문제에 대해서도 올바르게
평가를 할 수 있을것임
sentence embedding 을 얻기 위해 BERT 를 가져와야 함
import torch
from transformers import AutoModel, AutoTokenizer
MODEL_NAME = "bert-base-multilingual-cased"
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
model = AutoModel.from_pretrained(MODEL_NAME)
model.to('cuda:0')
계속 사용했던 bert-base-multilingual-cased 모델을 사용하겠음
그러면 [CLS] 토큰을 가져올 수 있어야함
def get_cls_token(sent_A):
model.eval()
tokenized_sent = tokenizer(
sent_A,
return_tensors="pt",
truncation=True,
add_special_tokens=True,
max_length=32
).to('cuda:0')
with torch.no_grad():# 그라디엔트 계산 비활성화
outputs = model(
input_ids=tokenized_sent['input_ids'],
attention_mask=tokenized_sent['attention_mask'],
token_type_ids=tokenized_sent['token_type_ids']
)
logits = outputs.last_hidden_state[:,0,:].detach().cpu().numpy()
return logits
print(get_cls_token("이순신은 조선 중기의 무신이다."))
- 너무 길어서 일부만 캠쳐함
[CLS] 토큰을 가져오고 그 토큰의 embedding 결과를 출력하는 코드를 작성했음
물론 이전 실습에서 해왔던 것처럼 모델의 inference 를 날리고 pooled_output 을 가져오게 되면 똑같이 [CLS] 토큰을 가져올 수 있음
“이순신은 조선 중기의 무신이다.” 문장에 대해 [CLS] 토큰 768 차원의 벡터틀 올바르게 가져온 것을 확인할 수 있음
total_sent_vector = {}
for i, sent in enumerate(total_sent): # 전체 문장 pool을 전부 embedding!
total_sent_vector[sent] = get_cls_token(sent) # {key, value} = {문장, vector}
if i % 500==0:
print(i)

paraphrase 된 key sentence 의 가장 유사한 문장을 찾기 위해 전체 total_sent 위에서 저장했던 전체 문장을 전부 embedding 을 하자
key, value 로 저장할건데 전체 total 문장에 대해 key=문장, value=vector 로 저장하도록 함
total_sent 를 반복문을 돌면서 vector 를 가져오게 됨
이 코드를 실행하면 전체 문장에 대해 각각의 vector 가 저장이 됨
그러면 다음의 목적은 similar_sent dictionary 라고 정의했던 부분이 있었는데 거기에 있는 key 값과 total_sent 를 전부 비교를하며 가장 유사도가 높은 문장 벡터를 가져오도록 하자
import numpy as np
def custom_cosine_similarity(a,b):
numerator = np.dot(a,b.T)
a_norm = np.sqrt(np.sum(a * a))
b_norm = np.sqrt(np.sum(b * b, axis=-1))
denominator = a_norm * b_norm
return numerator/denominator
non_similar_sents = {}
for key in similar_sents.keys(): # similar_sents dict의 sentence를 가져옵니다.
key_sent_vector = total_sent_vector[key] # 전체 문장 pool에서 해당 sent의 vector을 가져옵니다.
sentence_similarity = {} # 다음으로는 전체 문장 pool의 모든 vector와 비교하며
for sent in total_sent: # 가장 유사한 문장을 가져옵니다.
if sent not in similar_sents[key] and sent != key:
sent_vector = total_sent_vector[sent]
similarity = custom_cosine_similarity(key_sent_vector, sent_vector)
sentence_similarity[sent] = similarity
sorted_sim = sorted(sentence_similarity.items(), key=lambda x: x[1], reverse=True)
non_similar_sents[key] = sorted_sim[0:10] # similar_sents dict의 문장과 가장 유사한 10개의 문장을 반환합니다.
for i, key in enumerate(non_similar_sents.keys()):
print('\n', key)
for sent in non_similar_sents[key]:
print("-", sent)
if i > 3:
break
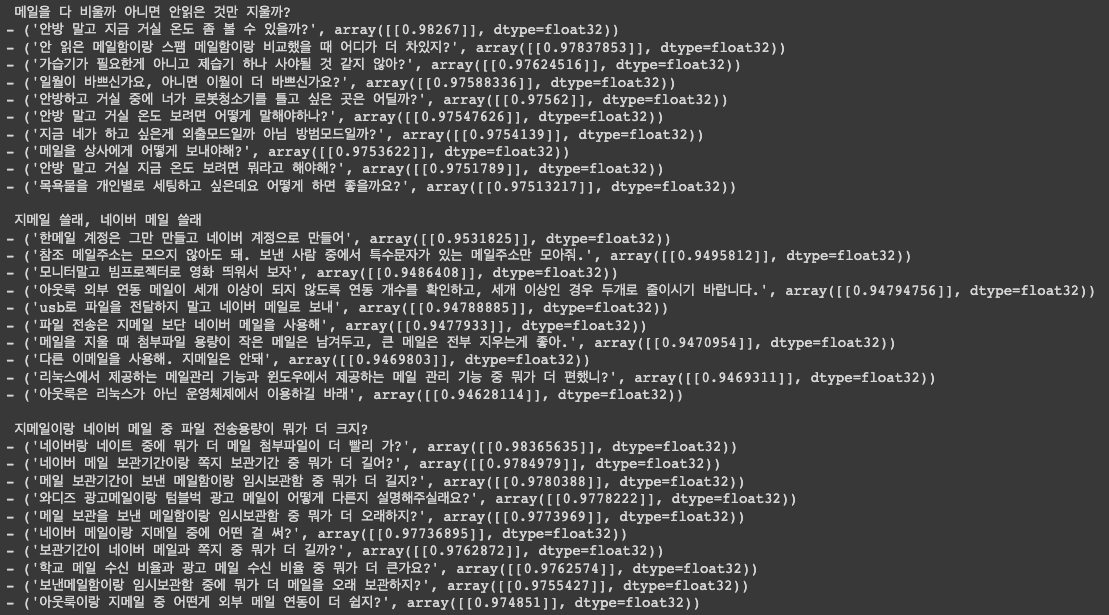

전체 문장 pool 을 대상으로 모든 벡터를 저장해뒀고 그러면 해당 딕셔너리에 similar_sents dict 에 있는 sentence 를
key 값으로 넣게되면 똑같이 벡터값을 반환을 함
이게 우리가 구하고자 하는 sentence embedding 결과가 됨
다음은 전체 문장 pool 에서 모든 벡터를 다 비교를하며 가장 유사한 벡터를 가져옴
total_sent 를 대상으로 반복문을 돌고 그리고 지금 similar_sents dict 같은 경우에는 key 값이 sentence 이고
value 가 유사한 문장 9개가 있었음
그래서 이 9개 문장에 해당하지 않는지를 검사를 하게 됨
그래서 total_sent 를 대상으로 봤을 때 9개 문장에 해당되지 않으면 embedding 의 cosine similarity 를 구하게 됨
전체 total_sent 에 대한 cosine similarity 결과를 저장할 수 있음
그리고 그 저장된 딕셔너리를 정렬을 해주게 되고 그 상위 10개만 non_similar_sents 딕셔너리에 저장하게 됨
이런 방법으로 코드는 진행되고 유사하지 않은 문장 데이터가 완성됨
이렇게 학습데이터를 만들었고 기존에 있었던 key sentence 와 유사한 9개의 문장은 1로 tagging 이 될 거고 얘는 유사하다
그리고 방금 만든 데이터셋은 유사하지 않다라고 tagging 이 될 것임
그래서 0 과 1 로 classification 을 진행할 수 있게됨
이렇게 만들어진 데이터를 para_kqc_sim_data.txt 로 저장하자
output = open('para_kqc_sim_data.txt', 'w', encoding='utf-8') # 이걸 데이터로 만들어줍니다 :-)
for i, key in enumerate(similar_sents.keys()):
for sent in similar_sents[key]:
output.write(key + '\t' + sent + '\t1\n')
for i, key in enumerate(non_similar_sents.keys()):
for sent in non_similar_sents[key]:
output.write(key + '\t' + sent[0] + '\t0\n')
output.close()
이렇게 학습데이터를 구축했고 다음 단계로 진짜로 두 문장의 관계를 분류할 수 있는 BERT 모델을 학습하도록 하자
실습
BERT 모델을 활용한 두 문장 관계 분류 학습
학습데이터를 확인해보자
import torch
import sys
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
data = open('/content/para_kqc_sim_data.txt', 'r', encoding='utf-8')
lines = data.readlines()
# 데이터셋 구조 확인
print(lines[0:10])

보면 두 문장은 \t 으로 구분되어있고 \t 뒤에는 label 이 되어있는 text 파일로 구성되어 있음
이 text 파일을 다루기 쉽게 pandas 로 불러오자
import random
random.shuffle(lines)
train = {'sent_a':[], 'sent_b':[], 'label':[]}
test = {'sent_a':[], 'sent_b':[], 'label':[]}
for i, line in enumerate(lines):
if i < len(lines) * 0.8:
line = line.strip()
train['sent_a'].append(line.split('\t')[0])
train['sent_b'].append(line.split('\t')[1])
train['label'].append(int(line.split('\t')[2]))
else:
line = line.strip()
test['sent_a'].append(line.split('\t')[0])
test['sent_b'].append(line.split('\t')[1])
test['label'].append(int(line.split('\t')[2]))
train data 와 test data 는 다음과 같이 구성됨
sent_a 항목이 있고 문장1번, 그리고 sent_b 문장2번 그리고 그 두문장의 관계가 유사하냐 유사하지 않느냐라고
label 을 tagging 하도록 하겠음
이 때 나눌때, 현재 구축된 데이터의 80% 는 학습데이터로 쓰고 20% 는 평가 데이터로 사용하도록 하겠음
import pandas as pd
train_data = pd.DataFrame({"sent_a":train['sent_a'], "sent_b":train['sent_b'], "label":train['label']})
test_data = pd.DataFrame({"sent_a":test['sent_a'], "sent_b":test['sent_b'], "label":test['label']})
# 데이터 중복을 제외한 갯수 확인
print("학습데이터 : ",train_data.groupby(['sent_a', 'sent_b']).ngroups," 라밸 : ",train_data['label'].nunique())
print("데스트 데이터 : ",test_data.groupby(['sent_a', 'sent_b']).ngroups," 라벨 : ",test_data['label'].nunique())
# 중복 데이터 제거
train_data.drop_duplicates(subset=['sent_a', 'sent_b'], inplace= True)
test_data.drop_duplicates(subset=['sent_a', 'sent_b'], inplace= True)
# 데이터셋 갯수 확인
print('중복 제거 후 학습 데이터셋 : {}'.format(len(train_data)))
print('중복 제거 후 테스트 데이터셋 : {}'.format(len(test_data)))

중복데이터를 제거하고 outlier 데이터들도 확인을 해봐야 함
import numpy as np
import matplotlib.pyplot as plt
# null 데이터 제거
train_data.replace('', np.nan, inplace=True)
test_data.replace('', np.nan, inplace=True)
train_data = train_data.dropna(how = 'any')
test_data = test_data.dropna(how = 'any')
print('null 제거 후 학습 데이터셋 : {}'.format(len(train_data)))
print('null 제거 후 테스트 데이터셋 : {}'.format(len(test_data)))

null 데이터도 제거해보자.
그렇지만 변화는 없었음
최종적으로 총 학습데이터는 15183개의 문장 pair sentence 를 이용할거고 약 4000 문장을 이용해서 모델이 올바르게 학습이
됐는지 평가를 진행하도록 하겠음
샘플 데이터는 이렇게 생겼음
print(train_data['sent_a'][0])
print(train_data['sent_b'][0])
print(train_data['label'][0])

# 학습 전제 문장 길이조사
print('학습 전제 문장의 최대 길이 :',max(len(l) for l in train_data['sent_a']))
print('전제 문장의 평균 길이 :',sum(map(len, train_data['sent_a']))/len(train_data['sent_a']))
plt.hist([len(s) for s in train_data['sent_a']], bins=50)
plt.xlabel('length of data')
plt.ylabel('number of data')
plt.show()
# 학습 가정 문장 길이조사
print('학습 가정 문장의 최대 길이 :',max(len(l) for l in train_data['sent_b']))
print('가정 문장의 평균 길이 :',sum(map(len, train_data['sent_b']))/len(train_data['sent_b']))
plt.hist([len(s) for s in train_data['sent_b']], bins=50)
plt.xlabel('length of data')
plt.ylabel('number of data')
plt.show()
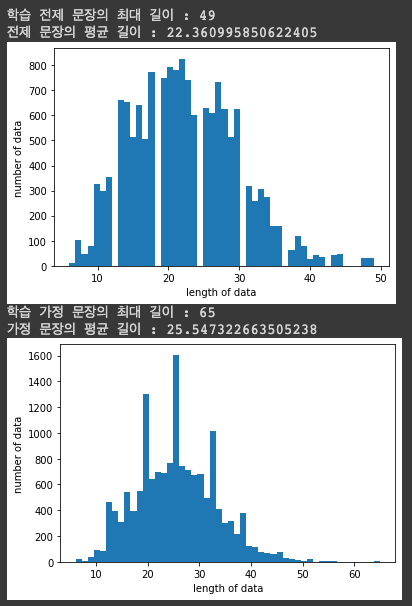
전체 문장의 길이와 평균 길이를 확인할 수 있음
본격적으로 BERT 를 활용해서 학습을 진행해보자
# Store the model we want to use
from transformers import AutoModel, AutoTokenizer, BertTokenizer
MODEL_NAME = "bert-base-multilingual-cased"
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
여기서부터는 이전 실습과 거의 동일하지만 tokenzier 를 불러올때가 다름
앞서서 단일 문장 분류 task 에서는 tokenizer 에 단일문장 하나만 입력으로 들어갔음
이렇게 두 문장의 관계 분류 task 에서는 문장 2개를 입력으로 넣게되면 자동으로 tokenizer 가 [CLS] 문장 A [SEP] 문장 b [SEP]
이렇게 다 토큰을 부착해서 tokenizing 을 해주고 그리고 그 안에서도 token_type_ids 를 segmentA 는 [0, 0, 0, …] 그리고
segmentB 는 [1, 1, 1, …] 이렇게 이쁘게 tagging 을 해주게 됨
tokenized_train_sentences = tokenizer(
list(train_data['sent_a'][0:]),
list(train_data['sent_b'][0:]),
return_tensors="pt",
padding=True,
truncation=True,
add_special_tokens=True,
max_length=64
)
print(tokenized_train_sentences[0])
print(tokenized_train_sentences[0].tokens)
print(tokenized_train_sentences[0].ids)
print(tokenized_train_sentences[0].attention_mask)

여기까지하면 tokenizer 를 통해서 학습데이터가 완성이 됨
마찬가지로 평가를 위한 test data 도 tokenizing 을 진행하자
tokenized_test_sentences = tokenizer(
list(test_data['sent_a'][0:]),
list(test_data['sent_b'][0:]),
return_tensors="pt",
padding=True,
truncation=True,
add_special_tokens=True,
max_length=64
)
label 도 만들자
train_label = train_data['label'].values[0:]
test_label = test_data['label'].values[0:]
print(train_label[0])

잘 저장된 걸 확인할 수 있음
여기서부터는 이전의 실습 내용과 다 똑같음
Dataset class 를 선언해줌
class MultiSentDataset(torch.utils.data.Dataset):
def __init__(self, encodings, labels):
self.encodings = encodings
self.labels = labels
def __getitem__(self, idx):
item = {key: torch.tensor(val[idx]) for key, val in self.encodings.items()}
item['labels'] = torch.tensor(self.labels[idx])
return item
def __len__(self):
return len(self.labels)
__getitem__ 이 step 이 진행됨에 따라서 모델에 계속해서 입력으로 들어가게 되는 데이터임
input 같은 경우에는 tokenizer 를 통해서 나온 결과의 key, value 값을 입력으로 넣게되고 label 은 사전에 정의했던 label 을 모델에 입력으로 같이 넣게 됨
train_dataset = MultiSentDataset(tokenized_train_sentences, train_label)
test_dataset = MultiSentDataset(tokenized_test_sentences, test_label)
train data 와 test data 를 dataset 으로 만들어줌
마찬가지로 BERT 를 활용해서 training 을 진행을 할건데 모델 입장에서보면 두 문장이든 한 문장이든 어차피 입력자체가
tokenized 된 sentence 가 들어가게 되고 마지막에 [CLS] 토큰 하나만 분류하게됨
그렇기 때문에 우리가 사용할 모델은 단일문장에서 사용했던것과 동일한 BertForSequenceClassification 임
이거를 불러다가 사용하면 입력된 sequence 에 대한 분류가 가능해지게 됨
from transformers import BertForSequenceClassification, Trainer, TrainingArguments, BertConfig
training_args = TrainingArguments(
output_dir='./results', # output directory
num_train_epochs=3, # total number of training epochs
per_device_train_batch_size=8, # batch size per device during training
per_device_eval_batch_size=64, # batch size for evaluation
logging_dir='./logs', # directory for storing logs
logging_steps=500,
save_total_limit=2,
)
아래 arguments 옵션들은 단일 문장 분류에서 했던것과 동일하게 되어있음
그 다음은 model 을 initialize 해주고 GPU 로 업로드 해주자
model = BertForSequenceClassification.from_pretrained(MODEL_NAME, num_labels=2)
model.parameters
model.to(device)
그 다음에는 평가 함수를 만들어주자
from sklearn.metrics import precision_recall_fscore_support, accuracy_score
def compute_metrics(pred):
labels = pred.label_ids
preds = pred.predictions.argmax(-1)
precision, recall, f1, _ = precision_recall_fscore_support(labels, preds, average='binary')
acc = accuracy_score(labels, preds)
return {
'accuracy': acc,
'f1': f1,
'precision': precision,
'recall': recall
}
trainer = Trainer(
model=model, # the instantiated 🤗 Transformers model to be trained
args=training_args, # training arguments, defined above
train_dataset=train_dataset, # training dataset
eval_dataset=test_dataset, # evaluation dataset
compute_metrics=compute_metrics
)
Trainer() 에 training_args 를 입력으로 넣고 그 다음에 train 을 하게되면 학습이 되게 됨
trainer.train()
학습이 끝나면 evaluate() 함수를 호출해서 evaluation 을 해보자
trainer.evaluate(eval_dataset=test_dataset)
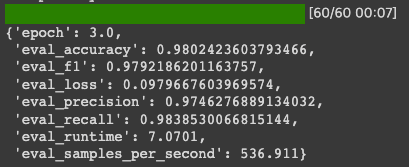
accuracy 는 98점 가까이나왔고 f1 도 97점까지 나오는 것을 봐서 모델이 굉장히 학습이 잘 된 것을 확인할 수 있음
trainer.save_model('./results')
모델도 ./results 라는 폴더에 저장해둠
그럼 실제로 이제 현실세계에서 쓰는 데이터를 이용해서 test 를 해봐야 함
prediction 할 수 있는 함수를 만들어보자
# predict함수
# 0: "non_similar", 1: "similar"
def sentences_predict(sent_A, sent_B):
model.eval()
tokenized_sent = tokenizer(
sent_A,
sent_B,
return_tensors="pt",
truncation=True,
add_special_tokens=True,
max_length=64
)
tokenized_sent.to('cuda:0')
with torch.no_grad():# 그라디엔트 계산 비활성화
outputs = model(
input_ids=tokenized_sent['input_ids'],
attention_mask=tokenized_sent['attention_mask'],
token_type_ids=tokenized_sent['token_type_ids']
)
logits = outputs[0]
logits = logits.detach().cpu().numpy()
result = np.argmax(logits)
if result == 0:
result = 'non_similar'
elif result == 1:
result = 'similar'
return result
단일 문장 inference 하는 부분과 굉장히 유사하게 되어있고 tokenizer 에 sentence 가 2개 들어가는것만 다름
print(sentences_predict('오늘 날씨가 어때요?','오늘의 날씨를 알려줘')) # similar
print(sentences_predict('오늘 날씨가 어때요?','기분 진짜 안좋다.')) # non_similar
print(sentences_predict('오늘 날씨가 어때요?','오늘 기분 어떠세요?')) # non_similar
print(sentences_predict('오늘 날씨가 어때요?','오늘 기분이 어때요?')) # non_similar
print(sentences_predict('오늘 날씨가 어때요?','지금 날씨가 어때요?')) # non_similar
print(sentences_predict('무협 소설 추천해주세요.','무협 장르의 소설 추천 부탁드립니다.')) # similar
print(sentences_predict('무협 소설 추천해주세요.','판타지 소설 추천해주세요.')) # non_similar
print(sentences_predict('무협 소설 추천해주세요.','무협 느낌나는 소설 하나 추천해주실 수 있으실까요?')) # similar
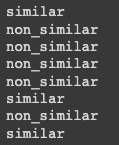
결과를 한번 보면 잘 예측하는 것을 볼 수 있음
실습
BERT IRQA 기반의 챗봇 실습
앞서서 실습했던게 [CLS] 토큰을 이용해서 만든 챗봇이 있었고 두 문장의 유사도를 비교하는 모델을 만들었음
이 두가지 모델을 하나로 합쳐서 챗봇을 만들어보도록 하자
먼저 데이터를 다운로드 받자 이 데이터는 심리상담과 관련된 챗봇 데이터임
!git clone https://github.com/songys/Chatbot_data.git
git clone 을 이용해 다운로드 받게 되면
import pandas as pd
data = pd.read_csv('/content/Chatbot_data/ChatbotData.csv')
data.head()

데이터가 이렇게 구성되어 있음
입력과 출력이 하나로 된 singleton 데이터셋을 확인할 수 있음
우리가 하고자 하는게 강의자료에서 설명한것과 마찬가지로 1차적으로는 [CLS] 토큰의 유사도를 이용해서 top-n 개를 뽑도록 하자
top-n 개를 뽑고나면 그 n 개를 하나씩 확인을 하며 paraphrase detection 을 하게 되는 것임
그래서 paraphrase detection 했을 때 정말로 question 과 나의 query 가 유사한게 확인이 됐다면 A 답변을 반환하게되는 그런 구조로 구성되어 있음
import torch
from transformers import AutoModel, AutoTokenizer
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
MODEL_NAME = "bert-base-multilingual-cased"
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
model = AutoModel.from_pretrained(MODEL_NAME)
model.to(device)
“bert-base-multilingual-cased” 모델을 활용해서 [CLS] 토큰의 sentence embedding 결과를 가져오도록 하겠음
데이터를 확인해보자
chatbot_Question = data['Q'].values
chatbot_Answer = data['A'].values
print(chatbot_Question[0:3])
print(chatbot_Answer[0:3])
이전에 [CLS] 토큰을 이용한 챗봇을 개발할 때 question 과 answer 를 전부 배열형태로 저장했었음
마찬가지로 챗봇 question 에 대해서 value 들을 리스트형태로 다 저장해두자
def get_cls_token(sent_A):
model.eval()
tokenized_sent = tokenizer(
sent_A,
return_tensors="pt",
truncation=True,
add_special_tokens=True,
max_length=32
).to(device)
with torch.no_grad():# 그라디엔트 계산 비활성화
outputs = model(
input_ids=tokenized_sent['input_ids'],
attention_mask=tokenized_sent['attention_mask'],
token_type_ids=tokenized_sent['token_type_ids']
)
logits = outputs.last_hidden_state[:,0,:].detach().cpu().numpy()
return logits
[CLS] 토큰을 얻는 것은 get_cls_token() 함수를 통해서 토큰을 얻도록 하자
그러면 첫번째로 해야할것은 사전에 정의되었던 데이터셋 그 데이터셋에 저장된 모든 sentence 에 대한 vector 를 또다시 얻어야 함
그래야지 새로운 question 이 들어왔을 때 그 벡터 리스트와 비교를하며 가장 유사한 벡터를 획득할 수 있음
그래서 챗봇 question 에 있는 sentence 를 반복문을 돌면서 [CLS] 토큰의 embedding 결과 768 차원짜리 벡터를 전부 저장 하도록하자
chatbot_Question_vectors = {}
for i, question in enumerate(chatbot_Question):
chatbot_Question_vectors[i] = get_cls_token(question)
이렇게 하면 chatbot_Question_vectors 안에 챗봇 question 에 대한 모든 sentence embedding 벡터가 들어가 있게 됨
이제 필요한 것은 우리의 query 가 들어갔을 때 기존 데이터셋에 있던 sentence embedding 결과와 가장 유사한 top-n 개를 출력해내는 그런 함수가 필요함
import numpy as np
def custom_cosine_similarity(a,b):
numerator = np.dot(a,b.T)
a_norm = np.sqrt(np.sum(a * a))
b_norm = np.sqrt(np.sum(b * b, axis=-1))
denominator = a_norm * b_norm
return numerator/denominator
그래서 cosine_similarity 를 계산할 수 있는 함수를 만들고 (물론 sklearn 에 있는 함수를 가져와서 사용해도 괜찮음)
def return_top_n_idx(question, n):
question_vector = get_cls_token(question)
sentence_similarity = {}
for i in chatbot_Question_vectors.keys():
ir_vector = chatbot_Question_vectors[i]
similarity = custom_cosine_similarity(question_vector, ir_vector)
sentence_similarity[i] = similarity
sorted_sim = sorted(sentence_similarity.items(), key=lambda x: x[1], reverse=True)
return sorted_sim[0:n]
top-n 개를 반환하는 함수를 만듦
이것도 이전에 학습데이터를 구축할 때 만들었던 코드와 동일함
question 이 들어오고 n 개를 지정해주면 question 에 대한 vector 를 구하게 되고 기존에 저장되어 있던 chatbot_Question_vectors
에서 가장 유사한 벡터를 가져오게 됨
역시 정렬을하고 정렬된 거에서 top-n 개를 반환하게 되면 유사한 인덱스가 나오게 됨
예를 들어서 text 해보자
print(return_top_n_idx("오늘 너무 힘들어", 5)) # top 5개 question id를 반환합니다.

“오늘 너무 힘들어” 라고 입력을 넣고 n 에 5를 넣었을 때 가장 유사한 question 이 유사도와 함께 반환이 되게 됨
직접적으로 어떤게 반환되는지 확인해보자
print('most similar questions')
for result in return_top_n_idx("오늘 너무 힘들어", 5):
print(chatbot_Question[result[0]])
print('\nmost similar answers')
for result in return_top_n_idx("오늘 너무 힘들어", 5):
print(chatbot_Answer[result[0]])

보통은 top-1 의 결과가 답변으로 나가게 됨
하지만 top-1 의 결과가 정답이 아닌 경우도 있음
print('most similar questions')
for result in return_top_n_idx("너 이름이 뭐야?", 5):
print(chatbot_Question[result[0]])
print('\nmost similar answers')
for result in return_top_n_idx("너 이름이 뭐야?", 5):
print(chatbot_Answer[result[0]])

“너 이름이 뭐야?” 라고 넣고 top-n 개의 결과를 가져와봤음
이 때 top-1 이 “우정이 뭐야?” 나왔는데 형태적으로 굉장히 유사한 문장이기에 BERT 에게는 sentence embedding 이 유사하게 나와서
두 문장이 비슷한 것 같다고 판단할 수 있음
실제로 의미론적으론 다르게 됨
이런 예제들 때문에 가장 유사한 집단의 paraphrase detection 하는 모델을 부착하게 되는 것임
이 경우엔 “우정이 뭐야?” 라는 답변보다는 “너 뭐니?” 또는 “너 누구?” 라는 문장이 더 적절해보임
그러면 이렇게 만들어진 top-n 개를 이진 분류 모델에 태워서 실제로 유사한지 아닌지를 검사하는 task 를 진행하도록 하자
이전 학습에서 사용한 모델을 불러와서 사용하겠음
from transformers import BertForSequenceClassification
MODEL_NAME = "본인의 paraphrase detection 모델 파일 저장 위치"
classifier_model = BertForSequenceClassification.from_pretrained(MODEL_NAME)
classifier_model.to(device)
앞서서 모델의 결과를 확인했던 것과 마찬가지로 inference 코드를 그대로 가져와서 사용하자
# predict함수
# 0: "non_similar", 1: "similar"
def sentences_predict(sent_A, sent_B):
classifier_model.eval()
tokenized_sent = tokenizer(
sent_A,
sent_B,
return_tensors="pt",
truncation=True,
add_special_tokens=True,
max_length=64
)
tokenized_sent.to('cuda:0')
with torch.no_grad():# 그라디엔트 계산 비활성화
outputs = classifier_model(
input_ids=tokenized_sent['input_ids'],
attention_mask=tokenized_sent['attention_mask'],
token_type_ids=tokenized_sent['token_type_ids']
)
logits = outputs[0]
logits = logits.detach().cpu().numpy()
result = np.argmax(logits)
# if result == 0:
# result = 'non_similar'
# elif result == 1:
# result = 'similar'
return result
이 때 sent_A 와 sent_B 가 입력으로 들어오게 되고 역시 tokenizer 에 두 문장이 입력으로 들어가게 됨
그 다음에 softmax 결과가 0번 레이블이 높냐 1번 레이블이 높냐를 result 를 통해서 반환하게 됨
print(sentences_predict('오늘 날씨가 어때요?','오늘의 날씨를 알려줘')) # similar
print(sentences_predict('오늘 날씨가 어때요?','기분 진짜 안좋다.')) # non_similar
print(sentences_predict('오늘 날씨가 어때요?','오늘 기분 어떠세요?')) # non_similar
print(sentences_predict('오늘 날씨가 어때요?','오늘 기분이 어때요?')) # non_similar
print(sentences_predict('오늘 날씨가 어때요?','지금 날씨가 어때요?')) # non_similar
print(sentences_predict('무협 소설 추천해주세요.','무협 장르의 소설 추천 부탁드립니다.')) # similar
print(sentences_predict('무협 소설 추천해주세요.','판타지 소설 추천해주세요.')) # non_similar
print(sentences_predict('무협 소설 추천해주세요.','무협 느낌나는 소설 하나 추천해주실 수 있으실까요?')) # similar
print(sentences_predict('메난민이 뭐야','너 메난민이지?')) # similar

그러면 두 모듈을 하나로 합쳐보자
pipeline 을 합친다고 보면 됨
get_answer() 라는 함수를 만들자
def get_answer(question, n):
results = return_top_n_idx(question, n) # top n개를 list로 받고
for result in results: # n개를 반복문을 돌면서
ir_answer = chatbot_Answer[result[0]]
ir_question = chatbot_Question[result[0]]
if sentences_predict(question, ir_question) == 1: # 이진분류 모델이 query<->question의 의미가 서로 같다고 판단되면?
return ir_answer # 정답을 반환합니다.
return chatbot_Answer[results[0][0]] # "잘 모르겠어요."
사용자의 question 과 top-n 개를 몇개까지 볼 것인가 인 n 을 입력으로 받게 됨
첫번째, 나의 question 과 가장 유사한 question list 를 반환을 받음 이때, 아까 만들었던 return_top_n_idx() 함수를 사용
그러면 results 안에 top-n 개의 결과값이 저장됨
이때 results 를 반복문을 돌면서 result 의 question 을 가져오고 그 question 을 내가 만든 question 이 2개의 유사도가
1인지 0인지를 판단하게 됨
만약 2개가 유사하다면 question 과 맵핑되어있던 답변을 반환하게 됨
만약 반복문을 다 돌고나서도 답변이 올바르게 나오지 않았다면 그 다음 정책을 세울 수 있음
이 때 세운 정책은 top-1 을 반환하게 되는 것임
이렇게 만들면 “잘 모르겠어요” 라기 보다는 무언가 답변이 나오게 됨
그러니가 “잘 모르겠어요” 보다는 어떤 답변이라도 뭔가 만들어내는 것임
만약에 이런 말도 안되는 답변은 원치않는다라고 하면 “잘 모르겠어요” 라고 답변이 나오는게 더 맘에든다면
마지막 줄 return 을 “잘 모르겠어요” 라고 반환해주면 top-n 개 내에서 정답이 존재하지 않는다면 “잘 모르겠어요” 라는
답변이 출력이 될 것임
한번 테스트를 해보자
print(get_answer("너 이름이 뭐야?", 5))

print(get_answer("나 지금 너무 우울해", 5))
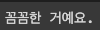
print(get_answer("오늘 기분 어때?", 5))
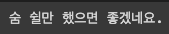
print(get_answer("바쁜가보네?", 5))

print(get_answer("어떻게 확인하는데?", 5))
보통 자유대화가 가능한 챗봇이라고 하면 전부 생성모델로 상상할 수 있을텐데 반드시 어떤 질문에 대해 반드시 나와야하는 답변을 일반적으로 사전 정의를 해놓고 이런 IRQA 모듈을 태워서 1차적으로는 IRQA 답변을 태우고 만약에 IRQA 에서 답변할 수 없는 질문이 들어왔다면 그 다음에 생성모델을 통해 답변을 만들어내는 그런 과정으로 챗봇을 구현함
작성자
* 김성현 (bananaband657@gmail.com) 1기 멘토 김바다 (qkek983@gmail.com) 박상희 (parksanghee0103@gmail.com) 이정우 (jungwoo.l2.rs@gmail.com) 2기 멘토 박상희 (parksanghee0103@gmail.com) 이정우 (jungwoo.l2.rs@gmail.com) 이녕우 (leenw2@gmail.com) 박채훈 (qkrcogns2222@gmail.com)
@inproceedings{cho2020discourse, title={Discourse Component to Sentence (DC2S): An Efficient Human-Aided Construction of Paraphrase and Sentence Similarity Dataset}, author={Cho, Won Ik and Kim, Jong In and Moon, Young Ki and Kim, Nam Soo}, booktitle={Proceedings of The 12th Language Resources and Evaluation Conference}, pages={6819–6826}, year={2020} }
댓글남기기