Day_37 01. 인공지능과 자연어 처리
작성일
인공지능과 자연어 처리
1. 인공지능의 탄생과 자연어처리
1.1 자연어처리 소개
피그말리온과 갈리테리아 (B.C. 43 - A.D. 17)

- 피그말리온이 여성의 결점을 제거해서 만든 조각상
- 인간을 대체하는 인공물에 대한 최초의 기록
오래전부터 인간이 상상해온 인공물에 대한 상상 $\rightarrow$ 인공지능
인간의 지능이 가지는 학습, 추리, 적응, 논증 따위의 기능을 갖춘 컴퓨터 시스템
콜러서스 컴퓨터 (1943)

- 프로그래밍이 가능한 세계 최초의 전자식 컴퓨터
- 1500개의 진공관을 이용해 Boolean 논리 연산을 수행
인공지능은 컴퓨터의 개발에 맞춰서 황금기를 이룸
이미테이션 게임 (튜링 테스트, 1950)
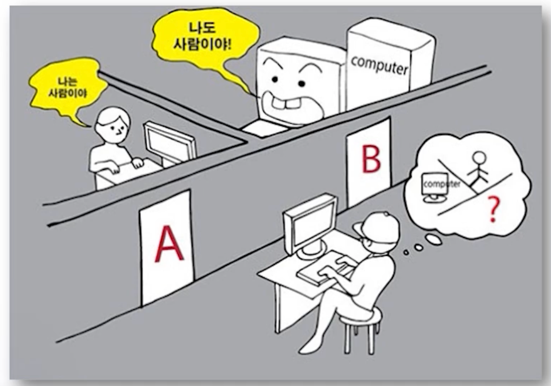
- 앨런 튜링
- 기계에 지능이 있는지를 판별하고자 하는 실험
- 인간의 정의나 인간의 지능을 정의하긴 어렵다!
- 하지만, 인간이 보기에 인간 같은 것을 인간에 준하는 지능이 있다고 간주
- 컴퓨터가 인간처럼 대화를 할 수 있다면 그 컴퓨터는 인간처럼 사고할 수 있다.
최초의 인공지능은 자연어처치를 근간으로 시작한 것을 알 수 있음
AI 의 황금기 (1956 - 1974)
- General purpose AI 를 만들기 위해 자연어 연구가 폭발적으로 관심을 받게 됨
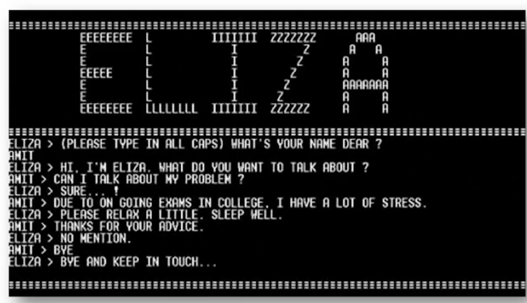
- 대표적인 ELIZA (1966) 챗봇
- 심리 상담사의 역할을 하도록 설계
- 단순 Rule Base
- 나 지금 너무 우울히 $\rightarrow$ 왜 우울하세요?
- 가족 문제로 고민이야 $\rightarrow$ 가족에 대해서 말해주세요.
- 최초의 대화형 (chitchat) 챗봇
- 튜링 테스트를 적용할 수 있는 최초의 Human-Like AI
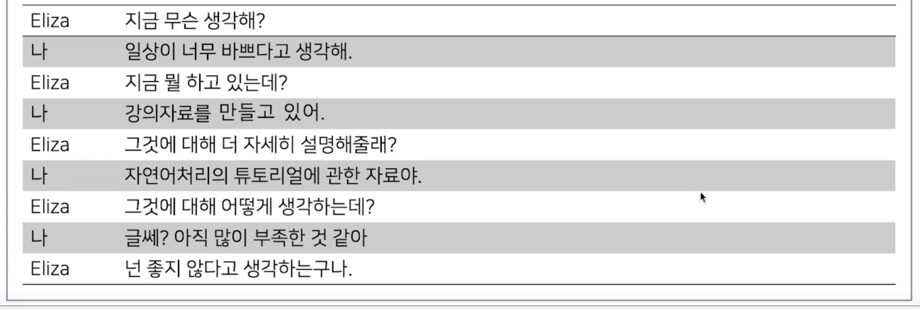
ELIZA 와의 대화
1.2 자연어처리의 응용분야
다양한 자연어처리 application
| - 문서 분류 | - 기계 독해 | - 텍스트 압축 |
| - 문법, 오타 교정 | - 챗봇 | - 패러프레이징 |
| - 정보 추출 | - 형태소 분석 | - 주요 키워드 추출 |
| - 음성 인식 결과 보정 | - 개체명 분석 | - 빈칸 맞추기 |
| - 음성 합성 텍스트 보정 | - 구문 분석 | - 발음기호 변환 |
| - 정보 검색 | - 감성 분석 | - 소설 생성 |
| - 요약문 생성 | - 관계 추출 | - 텍스트 기반 게임 |
| - 기계 번역 | - 의도 파악 | - 오픈 도메인 QA |
| - 질의 응답 | - 이미지 캡셔닝 | - 가설 검증 |
1.2.1 예시
한국 언론 재단에서 제공하는 서비스
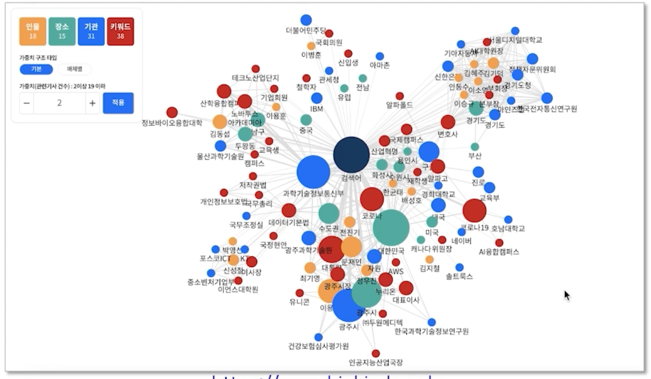
https://www.bigkinds.or.kr
뉴스에서 개체명을 인식하고 개체명간의 상관관계와 뉴스관의 관계를 파악해서 관련 키워드를 추천해주는 서비스
인간의 자연어처리
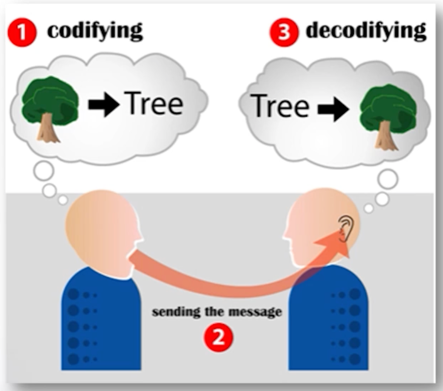
- 대화의 단계
- 화자는 자연어 형태로 객체를 인코딩
- 메세지의 전송
- 청자는 자연어를 객체로 디코딩
$\rightarrow$
화자는 청자가 이해할 수 있는 방법으로 이쁘게 인코딩
청자는 본인 지식을 바탕으로 디코딩
컴퓨터의 자연어처리
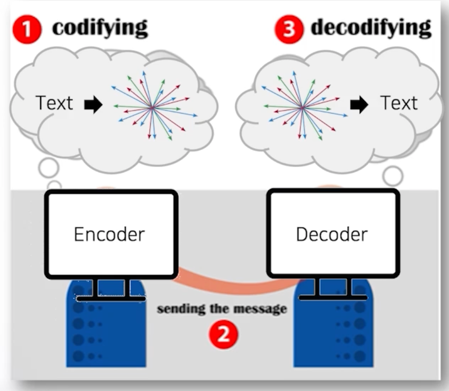
컴퓨터는 자연어처리를 바로 할 수 없어서 숫자형태로 변형되어야 함
- 대화의 단계
- Encoder 는 벡터 형태로 자연어를 인코딩
- 메세지의 전송
- Decoder 는 벡터를 자연어로 디코딩
$\rightarrow$
Encoder 는 Decoder 가 이해할 수 있는 방법으로 이쁘게 인코딩
Decoder 는 본인 지식을 바탕으로 디코딩
자연어를 컴퓨터가 이해할 수 있게 수학적으로 어떻게 이쁘게 인코딩할 수 있는지를 살펴봅시다!
인코딩이 이쁘게 되면? 디코딩을 통해 무엇이든 할 수 있다!
다양한 자연어처리 application
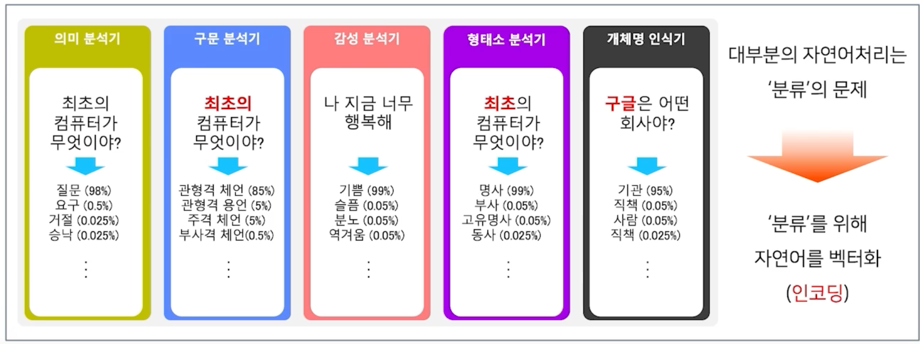
1.3 자연어 단어 임베딩
특징 추출과 분류
분류를 위해선 데이터를 수학적으로 표현- 먼저, 분류 대상의 특징 (Feature) 을 파악 (Feature extraction)

- 분류 대상의 특징 (Feature) 를 기준으로, 분류 대상을 그래프 위에 표현 가능
- 분류 대상들의 경계를 수학적으로 나눌 수 있음 (Classification)
- 새로운 데이터 역시 특징을 기준으로 그래프에 표현하면, 어떤 그룹과 유사한지 파악 가능
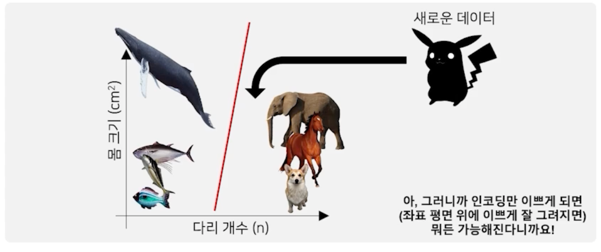
인코딩만 이쁘게되면 즉 좌표평면 위에 데이터들이 이쁘게 나열만 되면 뭐든지 다 가능해짐
- 과거에는 사람이 직접 특징 (Feature) 를 파악해서 분류
- 실제 복잡한 문제들에선 분류 대상의 특징을 사람이 파악하기 어려울 수 있음
- 이러한 특징을 컴퓨터가 스스로 찾고 (Feature extraction), 스스로 분류 (Classification) 하는 것이
기계학습의 핵심

Word2Vec
- 자연어를 어떻게 좌표평면 위에 표현할 수 있을까?
- 가장 단순한 표현 방법은 one-hot encoding 방식 $\rightarrow$ Sparse representation
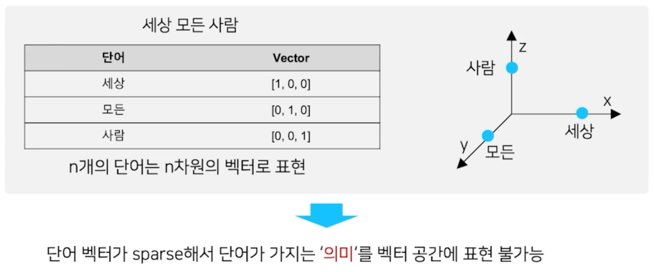
one-hot encoding 방식을 보완하기 위한 방법이 Word2Vec
- Word2vec (word to vector) 알고리즘: 자연어 (특히, 단어) 의 의미를 벡터 공간에 임베딩
- 한 단어의 주변 단어들을 통해, 그 단어의 의미를 파악

주변에 힌트를 넣어봄

- Word2vec 알고리즘은 주변부의 단어를 예측하는 방식으로 학습 (Skip-gram 방식)
- 단어에 ㄷ해ㅏㄴ dense vector 를 얻을 수 있음
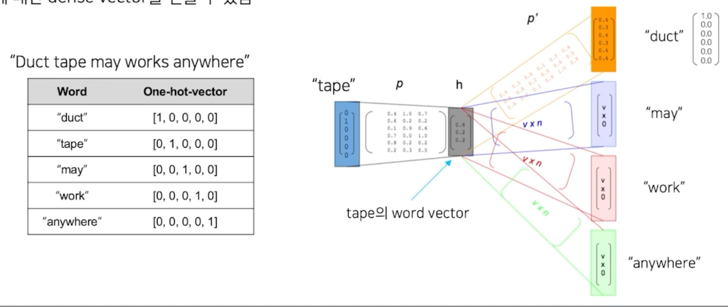
1.3.1 예제

1.3.2 정리
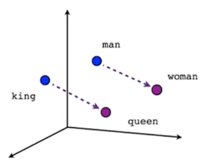
- 단어가 가지는 의미 자체를 다차원 공간에
벡터화하는 것 -
중심 단어의 주변 단어들을 이용해 중심단어를 추론하는 방식으로 학습
- 장점
- 단어간의 유사도 측정에 용이
- 단어간의 관계 파악에 용이
- 벡터 연산을 통한 추론이 가능 (e.g. 한국 - 서울 + 도쿄 = ?)
- 단점
- 단어의 subword information 무시 (e.g. 서울 vs 서울시 vs 고양시)
- Out of vocabulary (OOV) 에서 적용 불가능
OOV 문제를 보완하기 위해 나온 알고리즘이 FastText 임
FastText
- 한국어는 다양한 용언 형태를 가짐
- Word2Vec 의 경우, 다양한 용언 표현들이 서로 독립된 vocab 으로 관리
FastText 는 sub-word information 을 이용함

- Fasttext
- Facebook research 에서 공개한 open source library (https://research.fb.com/fasttext/, fasttext.cc)
- C++ 11
- Training
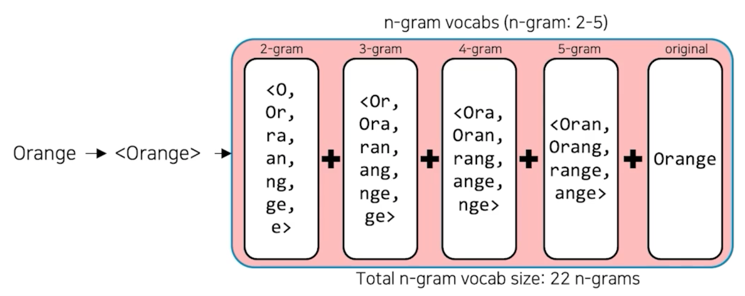
- 기존의 word2vec 과 유사하나, 단어를 n-gram 으로 나누어 학습을 수행
- n-gram 의 범위가 2-5 일 때, 단어를 다음과 같이 분리하여 학습함
“assumption” = {as, ss, su, …, ass, ssu, sum, ump, mpt, …, ption, assumption} - 이 때, n-gram 으로 나눠진 단어는 사전에 들어가지 않으며, 별도의 n-gram vector 를 형성함
- Testing
- 입력 단어가 vocabulary 에 있을 경우, word2vec 과 마찬가지로 해당 단어의 word vector 를 return 함
- 만약 OOV 일 경우, 입력 단어의 n-gram vector 들의 합산을 return 함
- FastText 는 단어를 n-gram 으로 분리를 한 후, 모든 n-gram vector 를 합산한 후 평균을 통해 단어 벡터를 획득
- 오탈자, OOV, 등장 회수가 적은 학습 단어에 대해서 강세 (https://link.apringer.com/chapter/10,1007/978-3-030-12385-7_3, https://github.com/MrBananaHuman/JamoFastText)
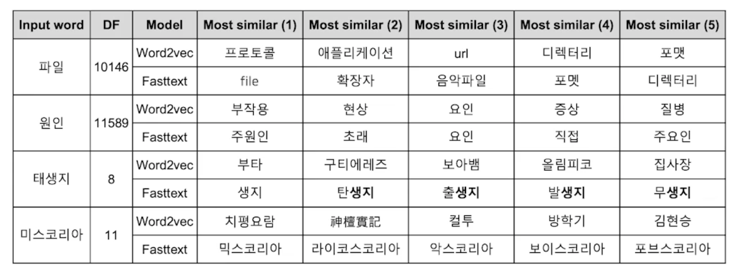
단어 임베딩 방식의 한계점
- Word2Vec 이나 FastText 와 같은 word embedding 방식은 동형어, 다의어 등에 대해선 embedding 성능이 좋지 못하다는 단점이 있음
- 주변 단어를 통해 학습이 이루어지기 때문에,
문맥을 고려할 수 없음

2. 딥러닝 기반의 자연어처리와 언어모델
2.1 언어모델
모델이란?

- 모델의 종류
- 일기예보 모델, 데이터 모델, 비즈니스 모델, 물리 모델, 분자 모델 등
- 모델의 특징
- 자연 법칙을 컴퓨터로 모사함으로써 시뮬레이션이 가능
- 이전 state 를 기반으로 미래의 state 를 예측할 수 있음 (e.g. 습도와 바람 세기 등으로 내일 날씨 예측)
- 즉, 미래의 state 를 올바르게 예측하는 방식으로 모델 학습이 가능함
언어모델
자연어의 법칙을 컴퓨터로 모사한 모델 $\rightarrow$ 언어모델- 주어진 단어들로부터 그 다음에 등장한 단어의 확률을 예측하는 방식으로 학습 (이전 state 로 미래 state 를 예측)
- 다음의 등장할 단어를 잘 예측하는 모델은 그 언어의 특성이 잘 반영된 모델이자, 문맥을 잘 계산하는 좋은 언어 모델
Markov 기반의 언어모델
- 마코프 체인 모델 (Markov Chain Model)
- 초기의 언어 모델은 다음의 단어나 문장이 나올 확률을 통계와 단어의 n-gram 을 기반으로 계산
- 딥러닝 기반의 언어모델은 해당 확률을 최대로 하도록 네트워크를 학습
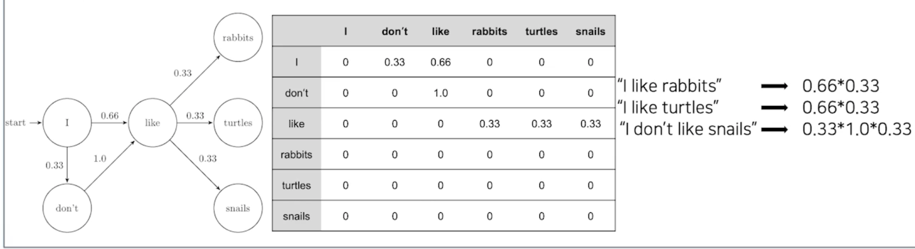
이 Markov 기반의 언어모델을 그대로 딥러닝 네트워크로 옮긴 예제가 바로 RNN 기반의 언어모델 임
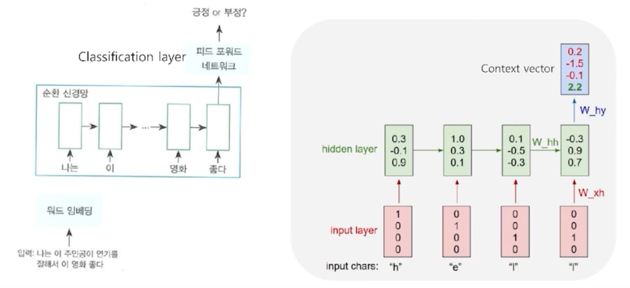
Recurrent Neural Network (RNN) 기반의 언어모델
- RNN 은 히든 노드가 방향을 가진 엣지로 연결돼 순환구조를 이룸 (directed cycle)
- 이전 state 정보가 다음 state 를 예측하는데 사용됨으로써, 시계열 데이터 처리에 특화
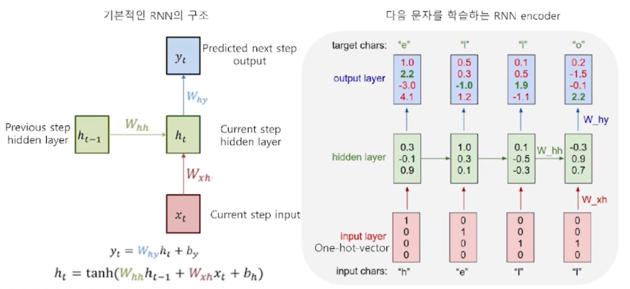
- 마지막 출력은 앞선 단어들의
문맥을 고려해서 만들어진 최종 출력 vector $\rightarrow$ Context vector - 출력된 context vector 값에 대해 classification layer 를 붙이면 문장 분류를 위한 신경망 모델
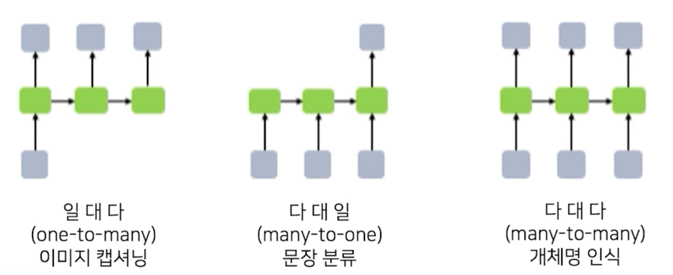
아래와같이 RNN 구조를 다양한 네트워크 구조로 표현할 수 있음
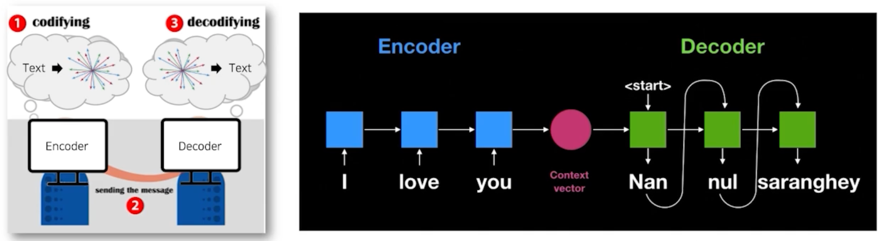
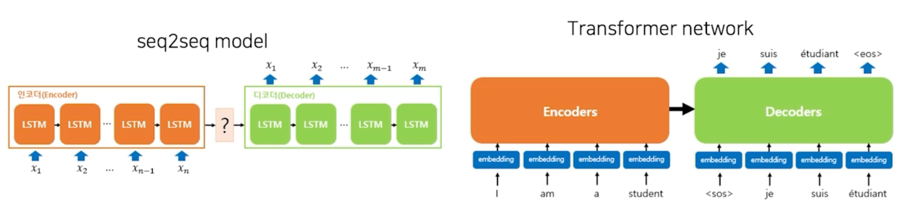
2.2 Sequence to sequence (seq2seq)
Recurrent Neural Network (RNN) 기반의 Seq2Seq
- Encoder layer: RNN 구조를 통해 Context vector 를 획득
- Decoder layer: 획득된 Context vector 를 입력으로 출력을 예측
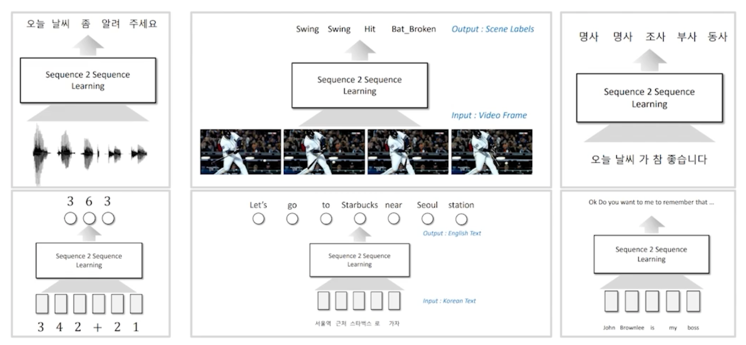
2.3 Attention
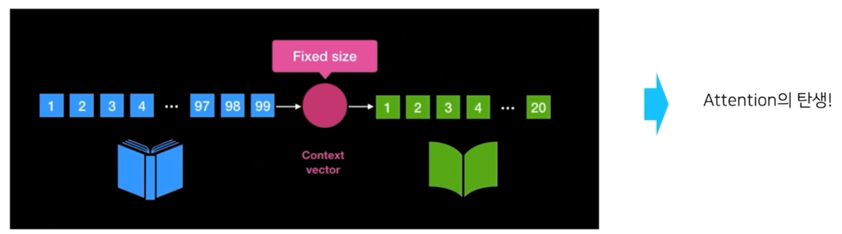
RNN 구조의 문제점
- 입력 sequence 의 길이가 매우 긴 경우, 처음에 나온 token 에 대한 정보가 희석
- 고정된 context vector 사이즈로 인해 긴 sequence 에 대한 정보를 함축하기 어려움
- 모든 token 이 영향을 미치니, 중요하지 않은 token 도 영향을 줌
Attention 모델
- 인간이 정보처리를 할 때, 모든 sequence 를 고려하면서 정보처리를 하는 것이 아님
- 인간의 정보처리 마찬가지로, 중요한 feature 는 더욱 중요하게 고려하는 것이 Attention 의 모티브
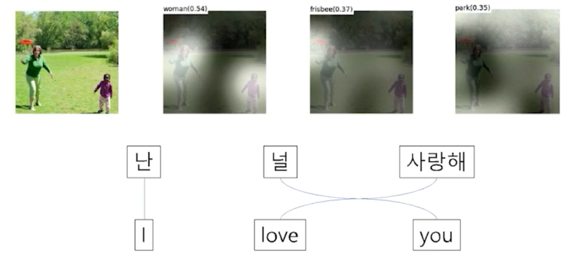
- 문맥에 따라 동적으로 할당되는 encode 의 Attention weight 로 인한 dynamic context vector 를 획득
- 기존 Seq2Seq 의 encoder, decoder 성능을 비약적으로 향상시킴
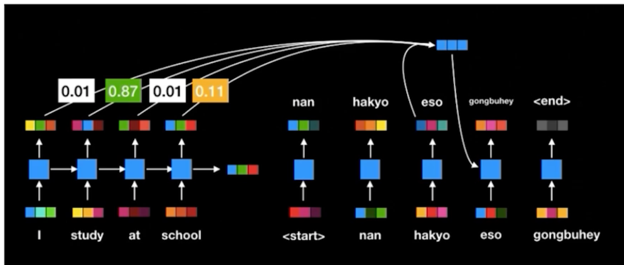
- 하지만, 여전히 RNN 이 순차적으로 연산이 이뤄짐에 따라 연산 속도가 느림
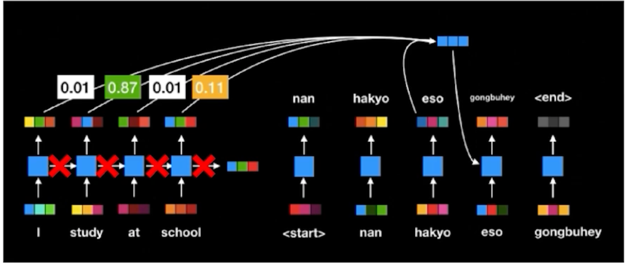
그래서 연구자들이 생각한 게 이 연결구조를 없애면 되지 않을까? 라고 생각하게 됨
그래서 Transformer self-attention 구조가 만들어지게 됨
2.4 Self-Attention
Self-attention 모델
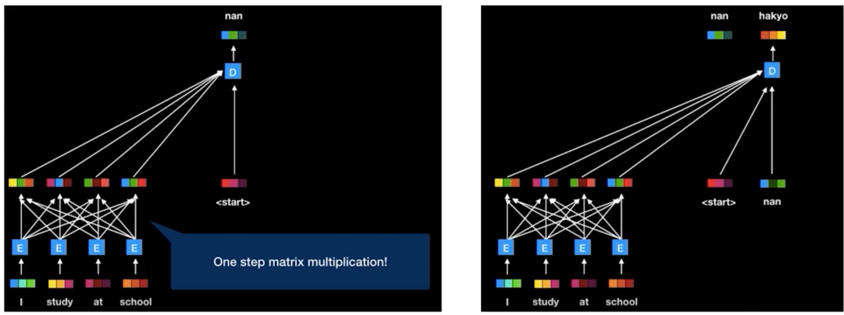
- RNN 구조에 있었던 이전 state 를 다음 state 로 전달하는 구조를 없애고 모든 token 들을 all-to-all 로 연결하게 됨
- 그래서 만들어진 모델이 Transformer 임
Transformer
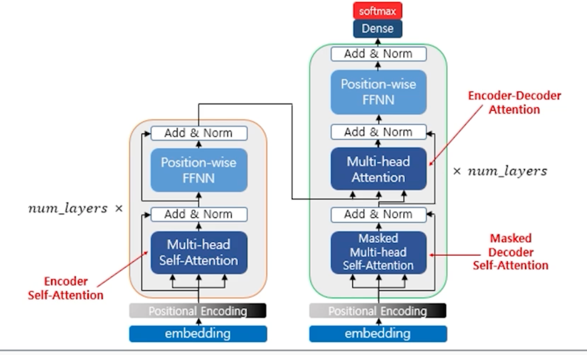
- 기존 seq2seq 모델은 Encoder RNN 구조가 따로 존재하고 그 다음에 Decoder RNN 구조가 따로 존재했음
- Encoder 의 역할은 Context vector 를 만들어내고 Decoder 의 역할은 Context vector 를 디코딩하는 역할
- Transformer 는 Encoder 와 Decoder 를 따로 분리해놓는 것이 아니라 하나의 network 내에 Encoder 와 Decoder 를 합쳐서 구조가 구성이 됨
Transformer Revolution!
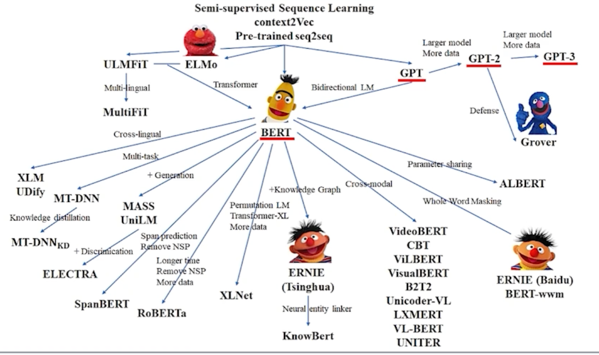
다양한 언어모델
댓글남기기