Day_36 [특강] 자연어 처리를 위한 언어 모델의 학습과 평가 - 박성준
작성일
[특강] 자연어 처리를 위한 언어 모델의 학습과 평가
1. 언어 모델링 (Language Modeling)
언어 모델링(Language Modeling)
주어진 문맥을 활욯해 다음에 나타날 단어 예측하기

P(“오늘은 햇살이 좋다.”)
= P(“오늘은”) * P(“햇살이”|”오늘은”) * P(“좋다.”|”오늘은 햇살이”)
문장에 대해서 확률을 부여하는 task 라고 할 수 있음
간단한 모델인 RNN 모델을 통해서 예시를 들면
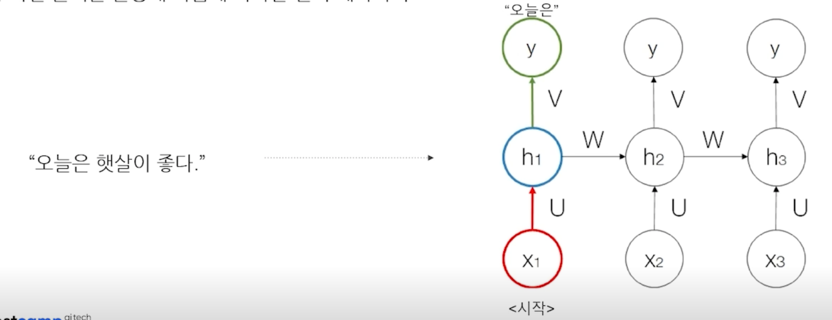
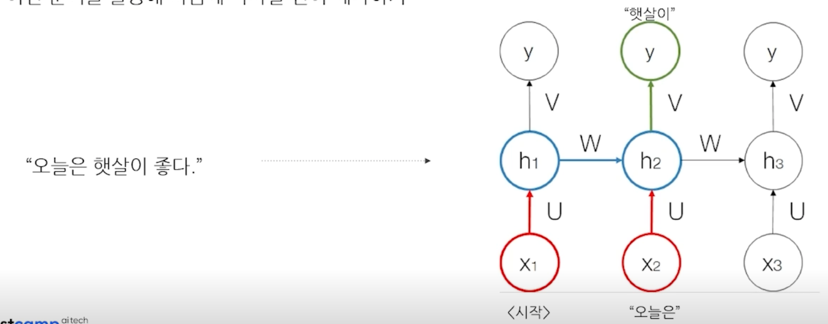
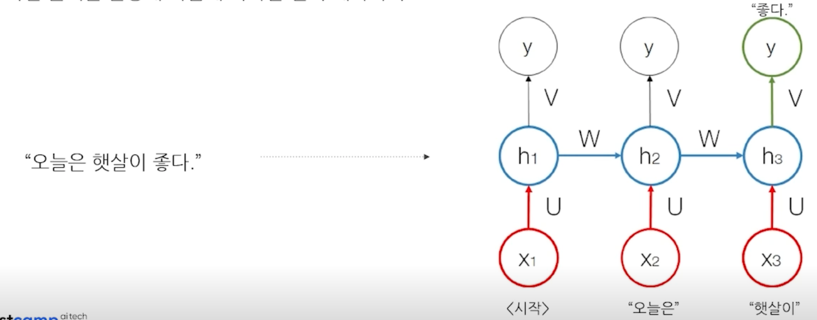
양방향 언어 모델링(Bidirectional Language Modeling)
Deep contextualized word representations (NAACL 2018)
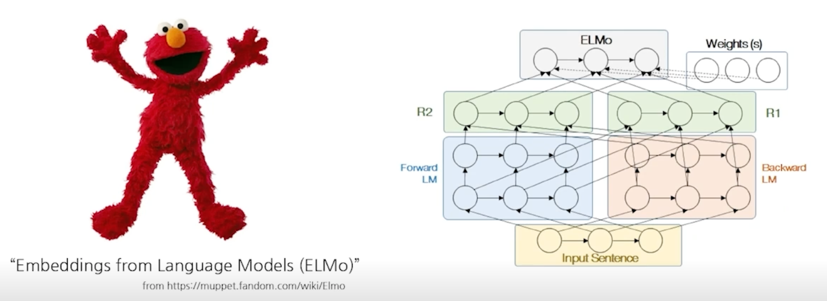
ELMO 의 기본적인 아이디어는 언어모델에서 Text 에 해당하는 언어 Embedding 을 뽑아서 그 Embedding 을 재료로 사용해서 특정한 Task 를 수행을 했을 때 다양한 Task 에서 모두 효과적임을 보여준 Paper
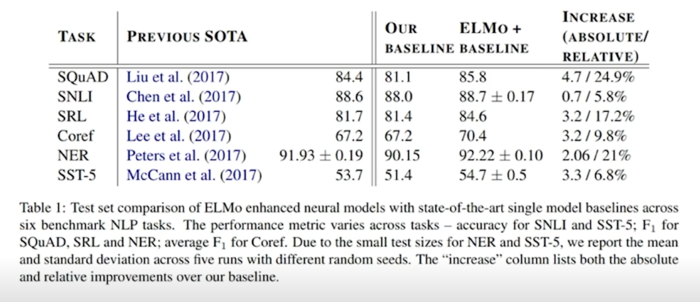
- SQuAD(질의응답)
- SNLI(두개의 문장의 모순이 있는지 없는지)
- SRL(의역 labeling)
- Coref(문단 안에서 이것, 저것 지칭하는게 있을 때 구체적으로 무엇을 지칭하는지)
- NER(Named Entity Recognition 개체명인식)
- SST-5(문장분류)
2018년도 이전까지는 각각 따로 모델링를 했는데
ELMO 부터는 언어모델의 힘을 빌리면 이 모든 Task 들을 한번에 다 잘하게 만들 수 있는 방법이 있다라는 걸 알게됨
BERT: Bidirectional Encoder Representations from Transformers (NAACL 2019)
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
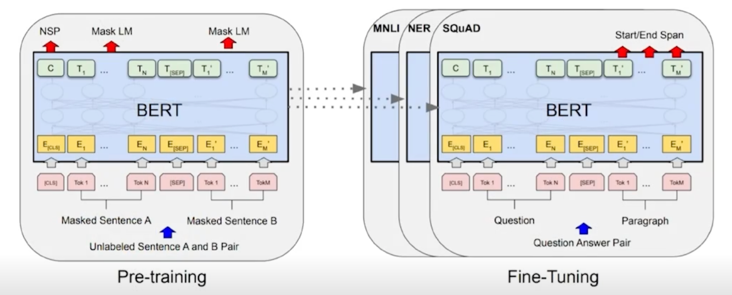
거대한 corpus 에서 Language Modeling Task 로 사전학습된 BERT 라는 구조를 활용해서 그 모든 Task 를 다 잘 할 수 있다가 결과고 대량의 Text 에서 BERT 라는 Transforemr Encoder 구조를 사전학습을 열심히 수행한다음에 각각의 Task 에 대해서 이 모델을 fine-tuning 만 하면 이 모든 Task 를 전부다 잘한다라는 것을 보여줌
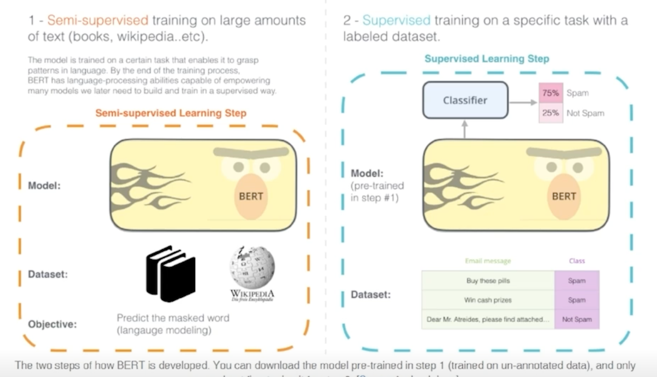
BERT 이후로 자연어 이해 Task 는 이렇게 진행해야한다 라는게 일반적인 상식처럼 굳어짐
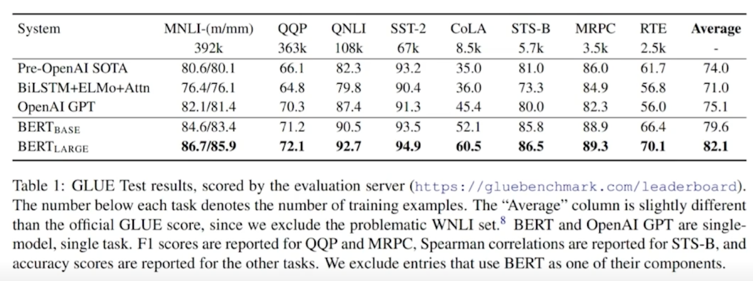
생각해보면 언어모델이 보여주고자 하는것은 사전학습된 언어모델이 살짝 튜닝만 하면 자연어이해 자체를 잘 한다 사람이 하는 말을 기계가 잘 이해할 수 있게 만들 수 있다라는 일반적인 주장을 하려고 하다보니 그러면 기존에 여러분야에서 활용이 되었던 자연어이해의 많은 Task 들이 있는데 그런 Task 들에서 나의 언어모델이 전부다 잘하는걸 보여줘야하기 때문에 다양하고 많은 Task 에서 실험을 진행함
- QQP(질문 두개를 임의로 뽑아서 두 질문이 사실상 같은 질문인지 아닌지를 분류하는 문제)
- QNLI(두개의 문장이 있을 때 두 문장사이에서 모순이 있는지 없는지 좀 더 상세하게 설명을 하는건지 분류하는 문제)
- SST-2(이 문장의 늬앙스가 긍정인지 부정인지 분류하는 문제)
- CoLA(사람이 문장을 읽었을 때 문법적인 오류가 있어 부자연스러운지 이 문장의 문법성을 문제없이 받아들일 수 있는지 언어 수용성을 평가하는 데이터셋)
- STS-B & MRPC(어떤 두개의 문장이 유사한지 아닌지를 평가하는 데이터셋)
- RTE(자연어 추론)
2. 언어 모델의 평가
GLUE 벤치마크 (General Language Understanding Evaluation)
언어 모델 평가를 위한 영어 벤치마크
- Quora Question Pairs (QQP, 문장 유사도 평가)
- Question NLI (QNLI, 자연어 추론)
- The Stanford Sentiment Treebank (SST, 감성분석)
- The Corpus of Linguistic Acceptability (CoLA, 언어 수용성)
- Semantic Textual Similarity Benchmark (STS-B, 문장 유사도 평가)
- Microsoft Research Paraphrase Corpus (MRPC, 문장 유사도 평가)
- Recognizing Textual Entailment (RTE, 자연어 추론)
- SQAUD 1.1 / 2.0 (질의응답)
- MultiNLI Matched (자연어 추론)
- MultiNLI Mismatched (자연어 추론)
- Winograd NLI (자연어 추론)
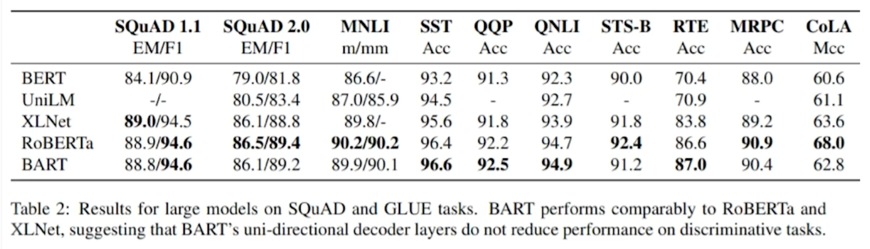
성능이 BERT 보다 뛰어난 자연어 이해 모델 등장의 계기가 됨

자연어 생성 모델의 평가에 활용됨
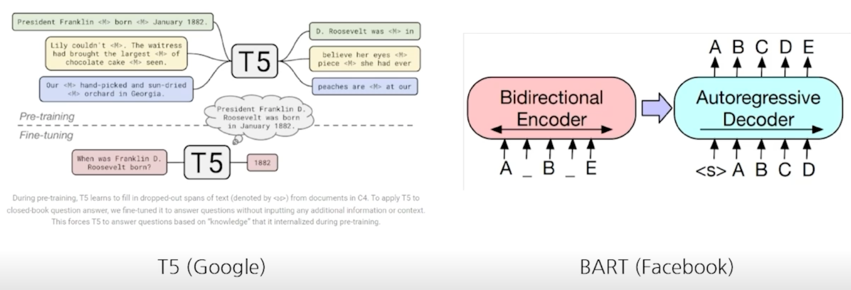
다국어 벤치마크의 등장
언어 모델 평가를 위한 다양한 언어의 벤치마크
- FLUE (프랑스어)
- CLUE (중국어)
- IndoNLU benchmark (인도네시아)
- IndicGLUE (인도어)
- RussianSuperGLUE (러시아어)
한국어 자연어 이해 벤치마크(KLUE: Korean Language Understanding Evaluation)
언어 모델 평가를 위한 다양한 언어의 벤치마크
- 개체명 인식(Named Entity Recognition)
- 품사 태깅 및 의존 구문 분석(POS tagging + Dependency Parsing)
- 문장 분류(Text classification)
- 자연어 추론(Natural Language Inference)
- 문장 유사도(Semantic Textual Similarity)
- 관계 추출(Relation Extraction)
- 질의 응답(Qeustion & Answering)
- 목적형 대화(Task-oriented Dialogue)
댓글남기기