Day_36 [특강] Full Stack ML Engineer - 이준엽
작성일
[특강] Full Stack ML Engineer
1. Full stack ML Engineer?
Full Stack ML 이란 무엇인지에 대한 생각을 나눕니다
1.1 ML Engineer 란?
- Machine learning (Deep learning) 기술을 이해하고, 연구하고, Product 를 만드는 engineer
- Deep learning 의 급부상으로 Product 에 Deep learning 을 적용하고자 하는 수요 발생
-
전통적인 기술의 경우 Research 영역과 Engineering 영역이 구분되지만, Deep learning 의 경우 폭발적 발전속도로 인해 그 경계가 모호함 (연구와 동시에 Product 에 적용)
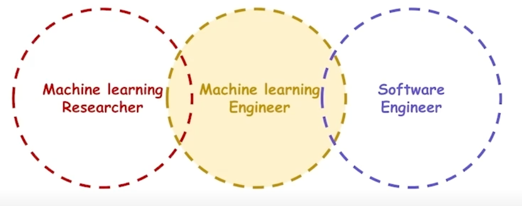
1.2 Full stack engineer 란?
-
서치 결과 부터 봅시다! (w3school)

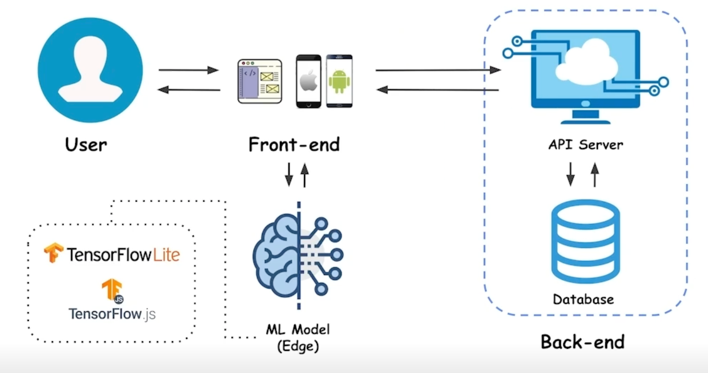
Web application 의 일반적 구조
- 네이버나 구글 (브라우저를 이용한 서비스)
- 웹 브라우저에 보여지는 화면을 개발하는 파트를 Front-end 라고 부름
- Front-end 가 Client 가 됨
- 뒷단에 있는 서버(API 서버)와 통신을 하게됨
- API 서버와 통신하는 데이터가 저장된 곳을 Database 라고 부름
-
API 서버와 Database 를 합쳐서 Back-end 라고 통칭
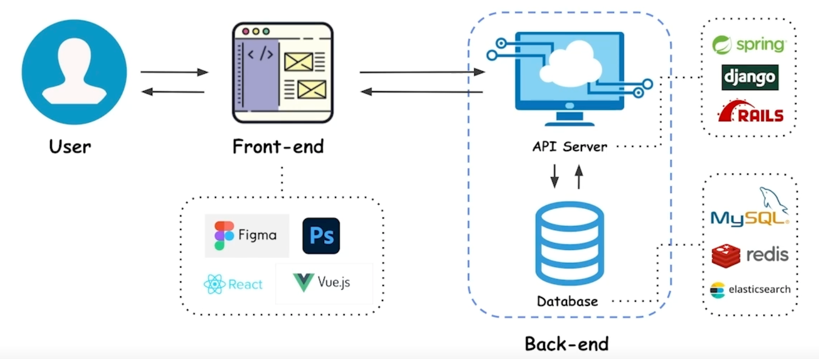
-
서치 결과 부터 봅시다! (Apple)

- 저의 생각은?
- Full stack engineer 란 표현은 각 포지션의 개발자들에게 달갑지 않은 표현일 수도 있다고 생각
(소개할 때 조심하자!) - Full stack engineer 은 상태가 아니라 방향성이라고 생각
- 모든 Stack 을 잘 다루려는 방향으로 가고있다면 Full stack engineer
- 기준을 세우자면 내가 만들고 싶은 Product 를 시간만 있다면 모두 혼자 만들 수 있는 개발자
- Full stack engineer 란 표현은 각 포지션의 개발자들에게 달갑지 않은 표현일 수도 있다고 생각
1.3 Full stack + ML ?
-
그렇다면 Full stack ML Engineer 란?
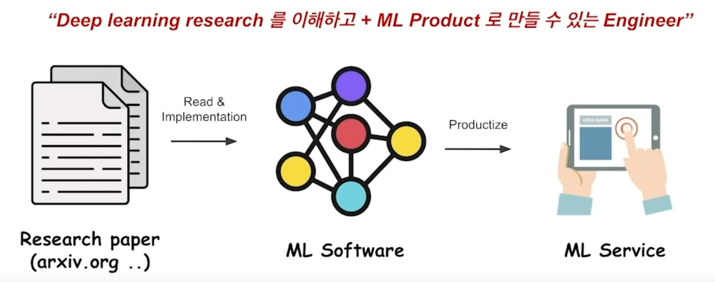
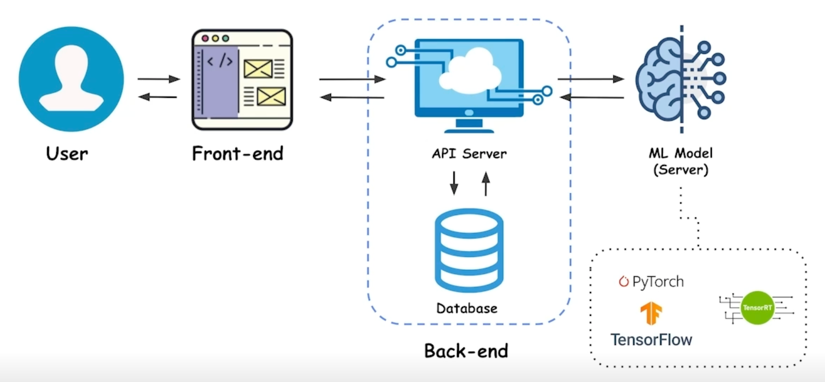
ML Service
- 앞 부분은 web application 과 동일
-
뒤에 ML Model 부분이 추가
Edge device service
- 얼굴인식이나 주민등록증 인식 같은 경우에는 데이터가 민감한 영역임
- 이런 데이터같은 경우 front-end 에서 서버로 보내지 않고 바로 처리하기도 함
-
ML Model 을 Edge 에 넣어서 front-end 에서 바로 모델을 돌리는 형태의 서비스도 있음
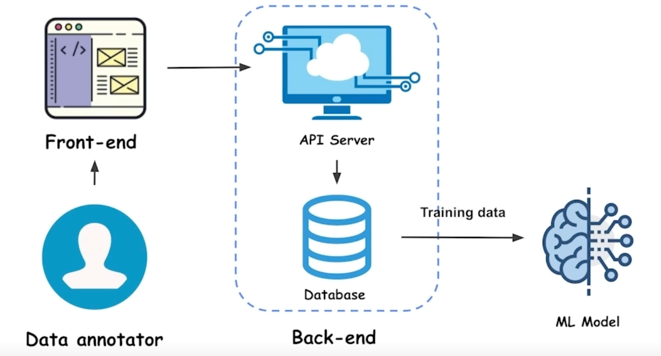
Data collection
- 유저에게 제공되는 서비스라기보다 ML 모델을 만들기 위한 Training Pipeline 이라고 보면 됨
- ML 모델을 만들기위해서 Training data 가 필요함
-
그 데이터를 모으기 위해서 Annotation tool or Data collection tool 을 만들어야하는데 그거를 웹 서비스로 만들 수 있음
2. Pros, cons of Full stack ML engineer
Full stack ML engineer 의 좋은점과 안 좋은점에 대해 알아봅시다.
2.1 Pros(장점)
- 아래 장점들이 반드시 Full stack engineer 가 되어야만 갖출 수 있는 것은 아님
- 한 분야의 구루가 되는 것도 Full stack engineer 가 되는것 만큼이나 혹은 그 이상 어려운 일
- 따라서 Full stack engineer 가 되는 것은 성향의 문제!
2.1.1 Pros: 재미있다!
- 저는 재미가 Full Stack ML engineer 가 되려는 가장 큰 이유가 되어야한다고 생각
- 소프트웨어 개발은 컴퓨터에서 돌아가는 작은 세상을 만드는 작업
- 협업을 통한 개발이 현대적 방법으로 정착했고, ML 쪽도 점점 그렇게 되어가고 있지만 처음부터 끝까지 내 손으로 만들었을 때가 더 재미있음
2.1.2 Pros: 빠른 프로토타이핑
- ML 모델의 빠른 프로토타이핑
- 검은 호마ㅕㄴ에서 돌아가는 모델과 실제로 프로덕트처럼 만들어서 보여주는 모델은 느낌도 반응도 다름
- 때로는 프로젝트의 GO/STOP 의 결정을 뒤 바꿀 수 있는 트리거가 될 수도 있음
-
프로토타이핑을 협업하기는 곤란한 경우가 많음

2.1.3 Pros: 기술간 시너지
- 연결되는 Stack 에 대한 이해가 각 Stack 의 깊은 이해에도 도움을 줌
- 결국 하나의 서비스로 합쳐지는 기술들. 연결되는 부분에 대한 이해가 중요
-
연결에 대한 고려가 들어간 개발 결과물은 팀의 불필요한 로스를 줄여줌
2.1.4 Pros: 팀플레이
- 다른 포지션 엔지니어링에 대한 이해. 어려운 일과 쉬운 일에 대한 구분. 서로 갈등이 생길 법한 부분에서의 기술적인 이해가 매우 도움이 됨
- 이러한 오해가 발생하는 이유는? 상대방 영역의 잠재적 위험(error 에 대한 handling)에 대한 고려를 하지 않기 때문
-
기술에 대한 이해 == 잠재적 위험에 대한 고려

2.1.5 Pros: 성장의 다각화
- 성장이 다각화됨
- 연구자 + 개발자 + 기획자가 모인 회의에서 모든 내용이 성장의 밑거름이 됨
-
사람에 따라서는 매너리즘을 떨치는 방법이 되기도 함

2.2 Cons(단점)
2.2.1 Cons: 깊이가 없어 질 수도 있음
- 아무래도 하나의 스택에 집중한 개발자 보다는 해당 스택에 대한 깊이가 없어질 수 있음
- 하루가 다르게 새로운 기술 + 새로운 연구가 나오는게 CS + ML 분야
- 모든 스택에서 최신 트렌드를 따라잡기가 어려운게 당연함
-
왜 없어진다가 아니라 없어질 수도 있다고 했을까?
2.2.2 Cons: 시간이 많이 들어감
- 공부할 분야가 많다보니 절대적으로 시간이 많이 들어감
- 절대적인 시간을 많이 투자한 만큼 깊이를 갖게 될 것
-
그렇다고 연봉이 꼭 비례하는 것도 아니라서..
3. ML Product, ML Team, ML Engineer
회사에서 ML Product 는 어떻게 만들어지는지, ML 팀은 어떻게 구성되어있는지, 팀에서 Full stack ML 엔지니어의 역할은 무엇인지 에 대한 저의 경험을 나눕니다.
3.1 ML Product
-
보통 ML Product 는 이런 과정을 통해 만들어 짐
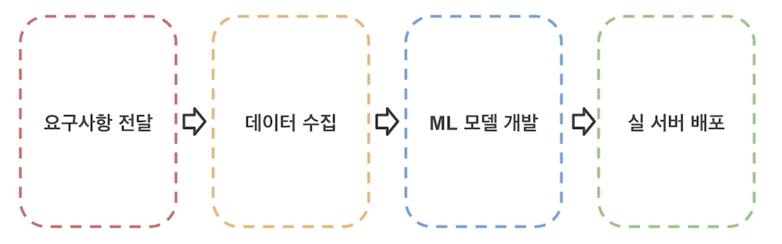
-
고객의 요구사항을 수집하는 단계
-
Model 을 훈련/평가할 데이터를 취득하는 단계


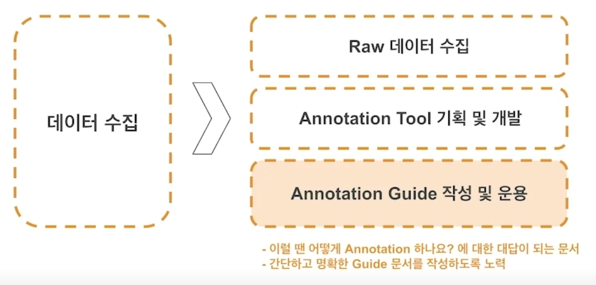
-
Machine learning 모델을 개발하는 단계
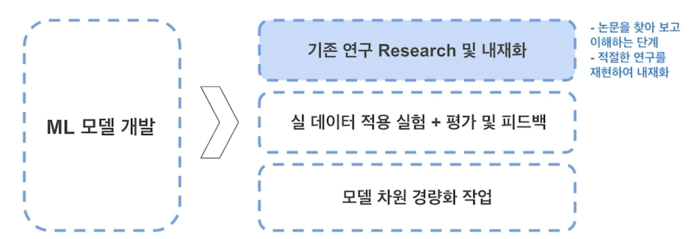
- baseline 모델 확보


-
서비스 서버에 적용하는 단계
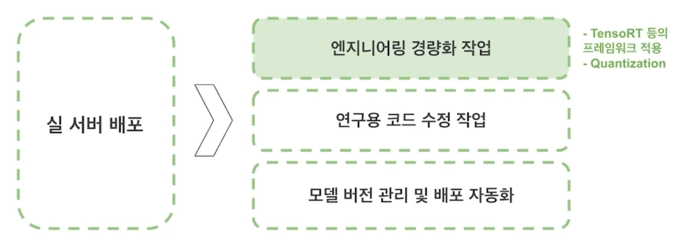
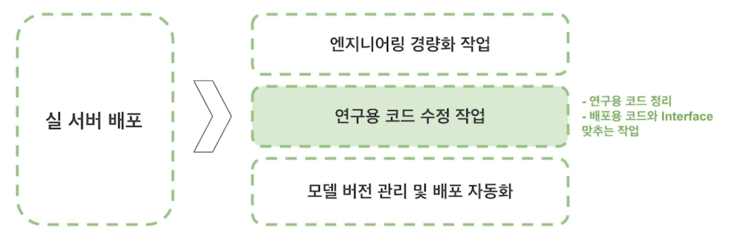
3.2 ML Team
-
제가 속했던 ML Team 의 일반적 구성은 다음과 같음

-
이렇게 되기도 함

3.3 Full stack ML Engineer in ML Team
- ML Product 가 만들어지는 과정과 ML Team 의 구성을 살펴보았음
-
이 과정에서 Full stack ML Engineer 가 하는 구체적인 업무에 대해 경험을 공유하겠음

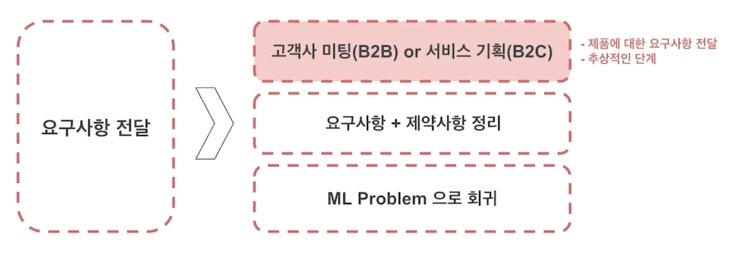
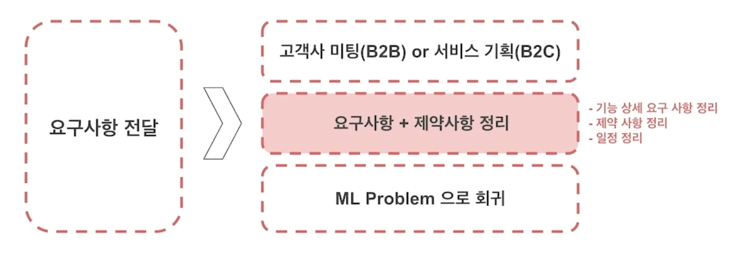
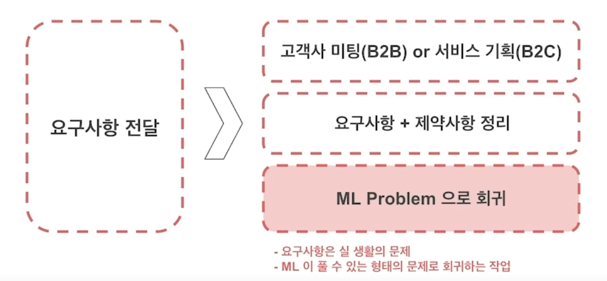
Job 1. 실 생활 문제를 ML 문제로 Formulation
- 고객 / 서비스 의 요구사항은 실 생활 문제!
- Machine learning 모델이 해결 가능한 형태로 문제를 쪼개는 작업 / 가능한지 판단하는 작업
-
기존 연구에 대한 폭 넓은 이해와 최신 연구의 수준을 파악하고 있어야 함

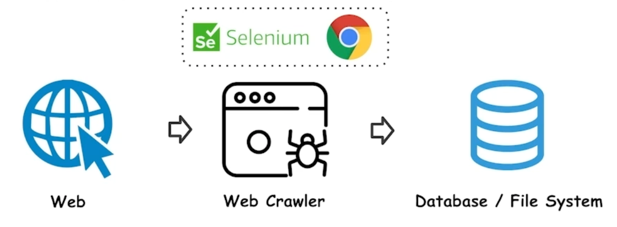
Job 2. Raw Data 수집
- 웹에서 학습데이터를 모아야 하는 경우도 있음
-
Web Crawler (Scraper) 개발해서 데이터 수집 (저작권 주의)
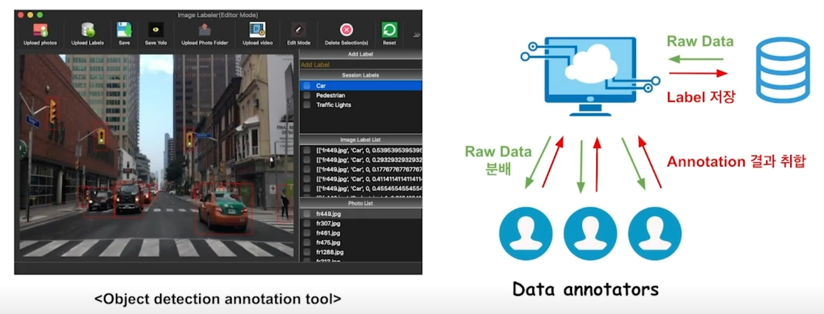
Job 3. Annotation tool 개발
- 수집 / 제공 받은 데이터의 정답을 입력하는 작업을 수행하는 web application 개발
- 작업 속도와 정확성을 고려한 UI 디자인이 필요
- 다수의 Annotator 들이 Client 를 통해 동시에 서버로 접속. Annotation 작업을 수행
-
새로운 Task 에 대한 Annotation tool 기획시 모델에 대한 이해가 필요할 수 있었음

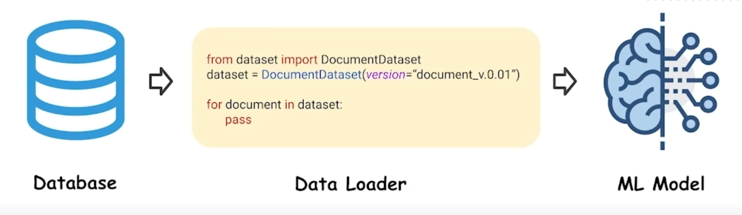
Job 4. Data version 관리 및 loader 개발
- 쌓인 데이터의 Version 관리
-
Database 에 있는 데이터를 Model 로 Load 하기 위한 Loader package 개발
Job 5. Model 개발 및 논문 작성
- 기존 연구 조사 및 재현 (재현 성능은 Public benchmark 데이터로 검증)
- 수집된 서비스 데이터 적용
-
모델 개선 작ㅇ버 + 아이디어 적용 $\rightarrow$ 논문 작성
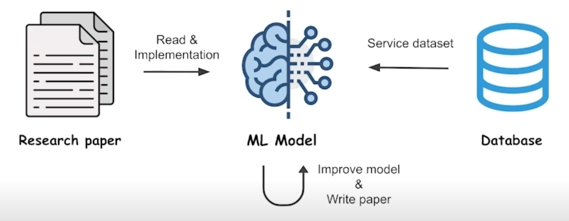
Job 6. Evaluation tool 혹은 Demo 개발
- 모델의 Prediction 결과를 채점하는 Web application 개발
- OCR 프로젝트 중 혼자 사용하려고 개발 (정/오답 케이스 분석) $\rightarrow$ 이후 팀에서 모두 사용
-
모두 사용하다보니 모델 특성 파악을 위한 요구사항 발생 $\rightarrow$ 반영하다보니 모델 발전의 경쟁력이 됨
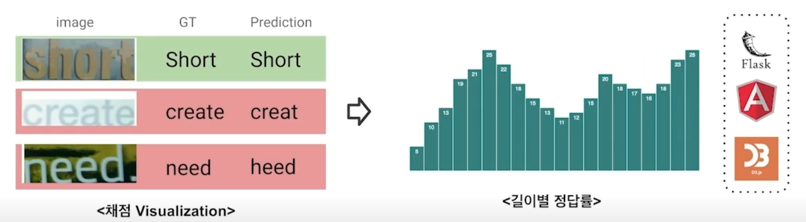
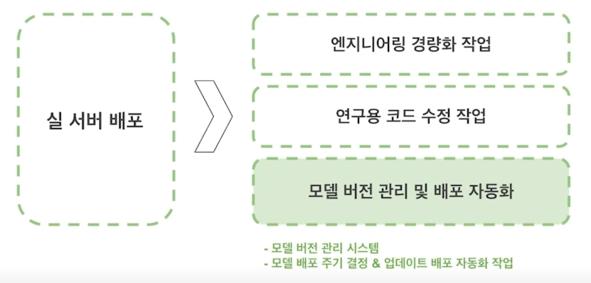
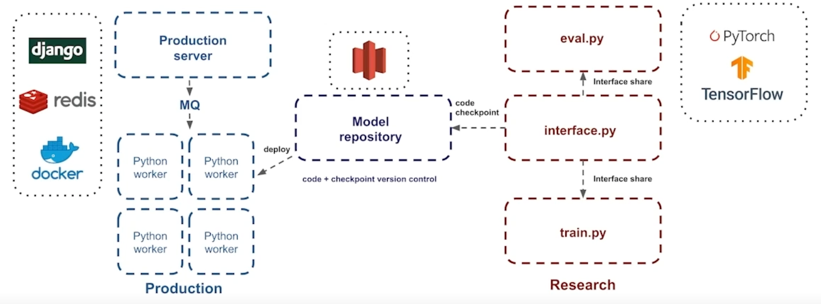
Job 7. 모델 실 서버 배포
- 연구용 코드를 Production server 에서 사용 가능하도록 정리하는 작업
- File server 에 코드 + Weight 파일 압축해서 Version 관리
-
Production server 에서는 Python worker 에게 MQ 를 통해 job 을 전달
4. Roadmap
어떻게 Full stack ML engineer 가 되는지 알아봅니다.
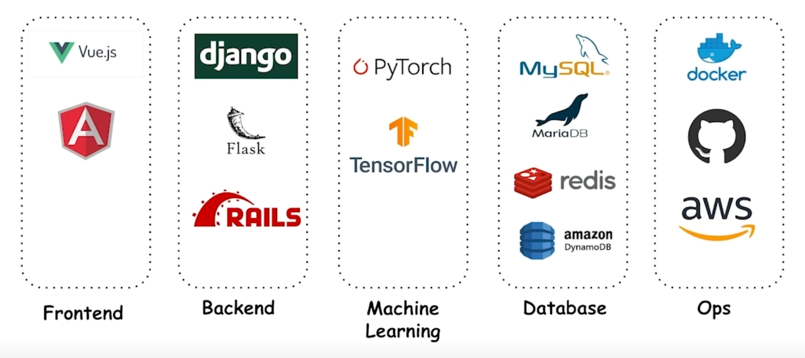
4.1 Roadmap: Stackshare
-
가장 위에있는게 선호되는 stack
Full stack ML Engineer 가 되기 어렵나요?
- 쉽다고 할 수는 없음
- 하지만 점점 더 Full stack ML Engineer 가 많아 질 것이라 생각. 제가 방향성이라고 생각했던 이유는?
- 각 스택에서 점점 더 framework 의 발전이 점점 더 interface 가 쉬워지는 방향으로 발전
-
특정 스택이 쉽다는 것은 아님. 하지만 초~중급 수준의 구현을 하는 것이 점점 쉬워질 것

염두하셔야 할 점이 있다면..!
- 시작이 반이다? $\rightarrow$ 시작이 80%
- 모든 Stack 이 공통적으로 시작이 가장 어려움
- 익숙한 언어 + 가장 적은 기능 + 가장 쉬운 Framework 로 시작하세요
- 하나를 배우고나면 나머지를 배우는 것은 훨씬 쉬움! Google + Stackoverflow 의 도움으로 쭉쭉!
-
시작의 허들을 넘은 뒤, 필요에 의해 원론을 공부하세요
- 처음부터 너무 잘 만들려고 하지 마세요. 최대한 빨리 완성하세요
- 많은 개발자들이 Full stack 으로 개발하다보면 가장 중요한 “완성” 이라는 가치에 도달하지 못하는 이유
- 모든 stack 의 안티 패턴을 모두 신경써서 개발하다가 포기하기보다는 완성에 집중하세요
- Full stack 개발의 매력은 “완성” 에서 오는 “재미” 입니다.
- 완성된 코드에 기능을 더하다보면 자연스레 리팩토링의 중요성에 대해 알게 됩니다.
-
재미를 느끼고 반복적으로 완성하다보면 실력이 늘게 됩니다.
- 전문 분야를 정하세요!
- 모든 Stack 에서 초~중급 개발수준을 계속 유지하는 것은 좋지 않은 선택입니다.
-
Andrej Karpathy 의 “Yes you should understand backprop” 이라는 글을 읽어보시길 추천합니다. (https://medium.com/@karpathy/yes-you-should-understand-backprop-e2f06eab496b)

- 새로운 것에 대한 두려움 없애기 위해 반복적으로 접하세요
- Frontend 개발이 어렵고 자신 없다면, 회사에서 Frontend 개발을 할 수 있는 기회를 찾으세요
- 배우고 싶었던 Stack 에 대한 문서 + 유튜브를 쉬운 것 부터 재미로 보면 좋습니다.
- 해당 Stack 을 잘 하시는 분에게 많이 질문하세요
어떻게 시작하는 것이 좋을까요?
- 제가 많이 들었던 말은 “만들고 싶은 것을 만드세요!”
-
만들줄 알아야 만들고 싶은 것이 생기던데..?
-
ML Engineer 라면, 하나의 논문을 구현하고, Demo page 를 만들어보는 것을 추천합니다.
댓글남기기