Day_35 [특강] AI + ML 과 Quant Trading - 구종만
작성일
[특강] AI + ML 과 Quant Trading
Disclaimer
- 트레이딩 업계는 지적재산권을 매우 중시 (=비밀스러움)
- 제가 아는 것은 전체 산업의 일부에 불과
- 제가 아는 것에 대해서도 자세한 이야기는 하기 어려움
- 실제 딥러닝 리서치가 활용되는 예는 아직 드뭄
- 재미 삼아 들어주세요
트레이딩은 뭐하는 일인가?

- 투자(investment) 와 트레이딩(trading): 트레이딩은 상대적으로 단기간
- 트레이딩은 단기적인 가격 변화에서 이득을 봄
- 길어야 ~3일 정도의 보유기간
퀀트 트레이딩이 뭐하는 일인가?
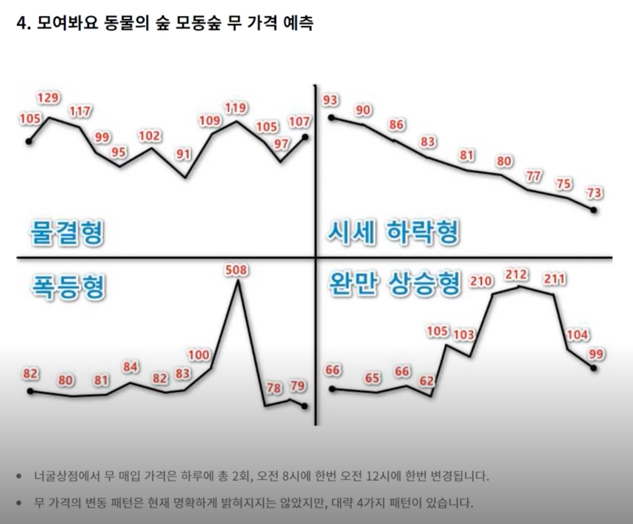
- Quantitative (계량적) 트레이딩
- 모델 기반 (가격이 특정 수학적 성질을 가진다고 가정) 혹은 데이터 기반 (시장의 과거 데이터에서 분포를 추정) 접근
- Automated/system/algorithmic trading 이라고도 부름
퀀트 트레이딩의 스펙트럼
- 수많은 종류의 전략이 존재함
- 포지션을 얼마나 오래 유지하는가? (1초 미만, ~3분, ~1시간, ~하루, ~3일)
- 어떤 상품군을 거래하는가? (주식, 선물, 옵션, 채권, 외환, 암호화폐, …)
- 100% 자동화되었는가, 혹은 트레이더의 주관이 들어가는가?
- 주문 집행(trade execution) vs 자체 수익
- 어디에서 엣지가 오는가? (시장의 특성을 이용? 훌륭한 통계적 모델?)
퀀트 트레이딩의 예 1: arbitrage
- 하나의 상품이 여러 곳에서 거래될 때 싼 곳에서 사서 비싼 곳에서 팜
- 예: 암호화폐 거래소마다 가격이 다름
- 아비트러지는 같은 상품의 가격을 맞춰주는 역할을 함
- 소비자는 어디 가더라도 같은 가격에 물건을 사고 팔 수 있음
- 김치 프리미엄(~2019)은 외환 반출 제한 때문에 아비트러지가 깨져서 생긴 사례
- 개념적으로 간단하기 때문에 속도 경쟁이 치열
- 90% 속도 + 10% 알파 경쟁
퀀트 트레이딩의 예 2: market making
- 매수 (구입) 주문과 매도 (판매) 주문을 동시에 냄
- 당연히 두 주문의 가격은 다름
- 두 주문이 동시에 체결되면 두 주문의 가격차만큼 이득
- “유동성을 공급”: 누구나 거래하고 싶을 때 쉽게 사고 팔 수 있게 함
- 모든 사람이 일제히 한 방향으로 거래하기 시작하면 그쪽으로 가격이 움직이면서 손해
- “눈치”를 잘 보면서 가격이 한 쪽으로 크게 움직일 것 같으면 어서 주문을 취소
-
50% 속도, 50% 알파 경쟁
퀀트 트레이딩의 예 3: statistical arbitrage
- 미래 가격의 변화를 예측해서 거래함
- 최근 호가 움직임을 이용한 가격 예측
- 종목간의 상관관계를 이용한 가격 예측 (cross section)
- 종목간의 가격 차이 예측 (basis trading)
- 정보의 출처는 중요하지 않음: 펀더멘털, 기술적 지표 모두 사용 가능
- 데이터 기반 접근이 필수적, 오늘 주로 얘기할 주제
- 10% 속도, 90% 알파
퀀트 트레이딩 플레이어들
- 퀀트 헤지펀드 / 로보 어드바이저
- 고객의 자본(수천억~수십조)을 운영하고 운용자금과 이익의 일부를 보수로 받음
- 상대적으로 긴 보유기간
- 프랍 트레이딩 (자기 자본 거래)
- 회사 파트너들의 자본(수십~수백억)을 거래
- 규모가 작은 대신 대개 HFT 나 market making 을 통해 높은 수익률을 추구
- 성공적인 팀은 꾸준히 연간 100% 이상의 수익률을 냄
- 금융위기 이후 규제 변경으로 은행들은 자기자본 거래를 하지 않음
- 퀀트 기반 트레이딩 서비스를 제공하는 쪽에 초점
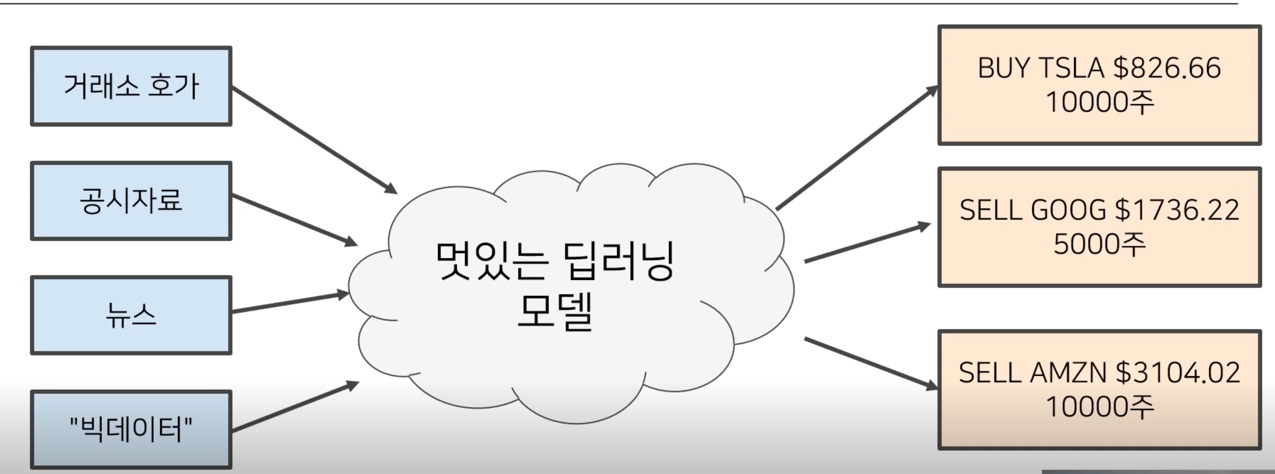
판타지 세계의 Stat Arb 전략
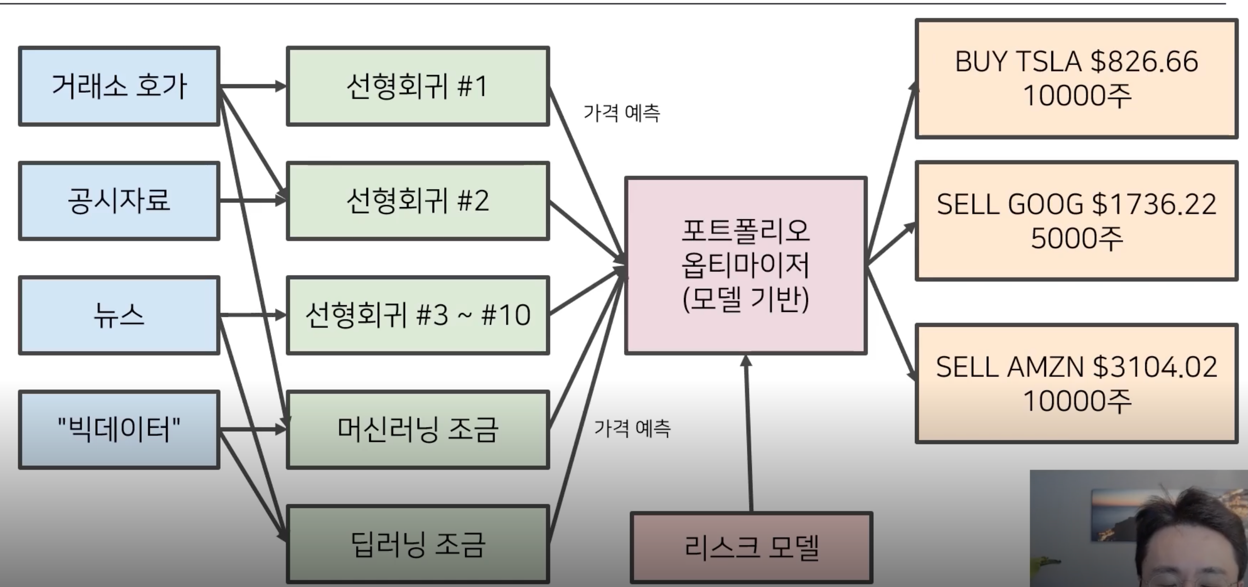
현실 세계의 (아마도) 흔한 Stat Arb 전략
떠오르는 질문들
- 정말 이게 되나요? (i.e. 정말 머신러닝으로 미래 가격을 예측할 수 있나요?)
- 선형회귀는 아무나 할 수 있는거 아닌가요? 그럼 왜 트레이딩이 어렵나요?
- 왜 아직 딥러닝이 정복하지 못했죠? 제가 이번에 딥러닝을 배웠으니 이걸 이용해 시장을 정복할 수 있나요?
1. 이게 정말 돼요?
- 효율적 시장 가설 (Eugene Fama)
- “가격은 상품에 대한 모든 정보를 포함하고 있기 때문에 장기적으로 초과수익을 얻을 수는 없다.”
- 안되다는 증거와 썰들은 많음
- 액티브 펀드 매니저들과 시장 인덱스의 퍼포먼스 비교
- 액티브 펀드 매니저와 원숭이의 대결
- Long Term Capital Management (1994 ~ 1998)
미래가 예측 가능한 이유들
- 예측 범위(horizon)에 따라 다르지만 미래를 예상할 수 있는 다양한 이유가 있음
- 포지션이 큰 참가자들은 움직이는 데 오래 걸림
- 큰 가격 변화가 있을 때 군중 심리가 나타남
- 프로페셔널 참가자들은 리스크를 줄이는 합리적 행동을 함
- 새로운 정보(뉴스, 공시 정보, 매출 및 펀더멘털)가 시장에 반영되기까지는 시간이 걸림
- 기술적인 문제들: 거래소/종목의 특성, 특정 규칙에 따라 움직여야 하는 참가자들, …
- 거래량이 많은 상품이나 거래소가 가격 발견 과정을 선도함
상품에 대한 새로운 정보가 가격에 포함되기 위해서는 누군가 거래를 해야 함
성공 기준이 우리의 직관과 다름
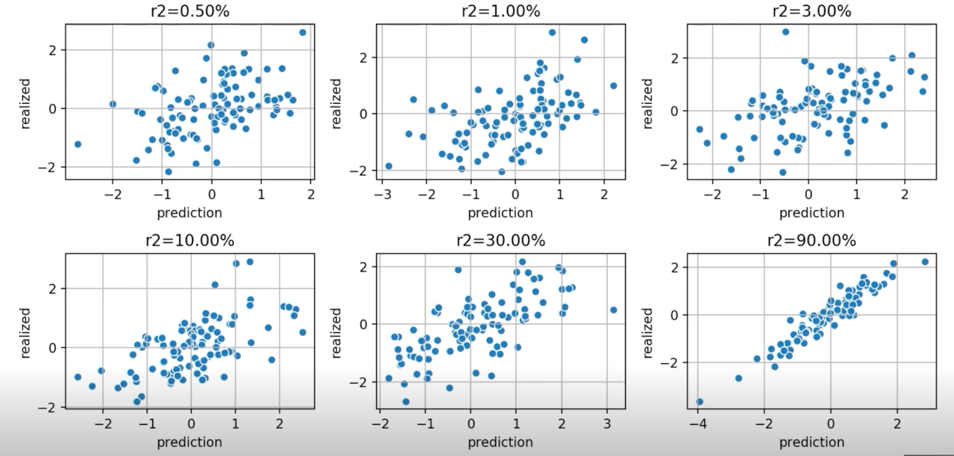
- 5분 후 가격 변화를 예측하는 6개의 forecast 가 있음.
- 어느 정도가 되면 돈을 벌 수 있고, 어느 정도가 현실적으로 가능할까?
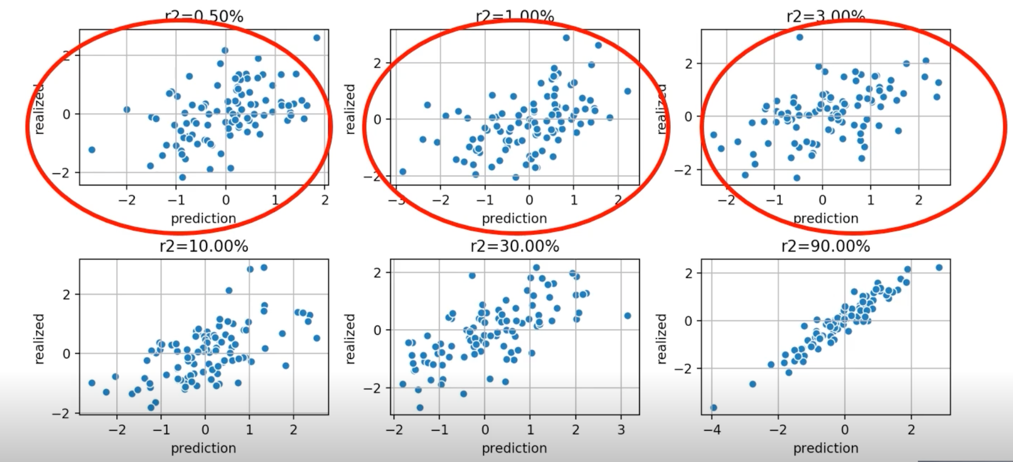
- 모든 forecast 가 돈을 벌 수 있음
- 실현 가능성있고 현실성 있는 것은 위에 3개임
- 0.5 $R^2$ 가 나와도 충분히 돈을 벌 수 있음
- $R^2$ 가 10% 혹은 15% 가 나오면 버그가 있나? data 유출? 이런 의심을 가질 수 있음
-
이론과 실제는 괴리가 있음
- 엄청나게 많은 작은 예측들
- 수천개의 종목에 하루에 수만번의 베팅
- 각 베팅이 성공할 확률이 51%만 되어도, 수백만번 반복하면 이론값으로 수렴 (대수의 법칙)
- 엄청나게 많은 forecast 알고리즘
- HFT 전략의 평균 수익은 거래량의 대략 0.01% (1 basis point)!
- 실제 수익은 훨씬 크거나 훨씬 작지만, 평균 내면 아주 작지만 이익
- 이것으로 연수깅ㄹ 100%+ 를 내려면 엄청나게 많은 양을 꾸준히 거래해야 함
어.. 저 정도 예측은 나도 하겠는데?
- 머신러닝 패키지 다운받아서
- 구글 파이낸스, DART, 트위터, 뉴스 크롤링해서 집어넣으면 되겠네?
- 오 캔들스틱도 넣고, MACD 도 넣고, 볼린저 밴드도 넣고!
- … 됩니다!
- 하지만 쉽지는 않더군요 (ㅠ.ㅠ)
2. 왜 딥러닝 안하나요?
-
근본적인 이유: 시장을 예측하는 것은 너무 어려움
- 시장에 영향을 미치는 수많은 원인 중 우리가 볼 수 있는 것은 극히 일부에 불과함
- 다른 참가자들의 포지션, 뷰, …
- 예측할 수 없느 ㄴ사건들: 코로나, 암호화폐 규제, 정치, 경제, 외교, 회사 경영진의 스캔들, …
- 우리가 보는 정보도 항상 뒤늦게 보게 도리 수 밖에 없음
- 시장은 (우리가 예측해야 하는 시장의 특성은) 계속 변함
- 참가자들은 계속 접근 방법을 고도화하고, 참가자들은 계속 바뀜: 가만히 있으면 모델이 점점 나빠짐
- 내 모델과 다른 참가자들 모델 사이의 피드백
- 달라지는 규제 조건
- 새로운 시장 및 상품군의 출현
- 다른 문제와 비교해 보자
- 이미지 인식: 고양이는 10000년이 지나도 고양이, 신호등은 10년이 지나도 계속 신호등. 많은 경우 사진만으로 무엇인지 알아볼 수 있음
- 바둑 AI: 바둑 규칙은 1백만 판을 둬도 그대로. 바둑판을 다 볼 수 있음
- NLP: 언어는 빠르게 변화하지만, 그 요체는 오랜 기간 동안 변화하지 않음
- 가격 예측 문제를 이미지 인식과 비교하자면?
- 털 한가닥만 보고 고양이인지 개인지 분류해야 함
- 고양이들이 분류를 피하기 위해 털 모양을 바꿈
- 개와 고양이의 기준을 종종 정부가 바꿈
- 문제가 어려움 = 오버피팅의 위험이 너무 큼
- 인샘플 에러를 낮추는 것은 쉬움
- 기존 데이터 셋 내에서 완벽하게 오버피팅을 막았다고 하더라도 미래에도 오버피팅이 아닐지는 장담할 수 없음
- 시장이 변화할 때 변화하지 않는 속성과 변화하는 속성을 구분할 방법?
- 가장 쉬운 방법은 내가 무엇을 모델링하는지, 왜 그것이 의미있는지 알고 있는 것
- 이것을 명확히 알고 있으면 선형회귀로도 대부분의 가치를 뽑아낼 수 있음
- 100% 블랙박스 학습 프로세스가 어려움: 딥러닝이 아직 잘 활용되지 않는 이유
그럼 무슨 리서치를 하나요?

- 오렌지: 새로운 정보
- 쥬서기: 새로운 정보에서 어떻게 요점만 뽑아낼 것인가?
- 쥬스: 알파
리서치 과정: 가설
- 대부분의 리서치는 가설로부터 시작됨
- 예: 여름에 홍수가 나고 날씨가 안 좋았다면 곡물 선물 가격은 오를 것이다
- 예: 같은 크기의 매수 주문이 계속 반복되어 들어온다면 가격이 오를 것이다
- 설득력 있는 가설이 없이 시작된 리서치는 결론이 조금만 안 좋아도 끝나기 쉬움
- 아무리 가설이 강력해도, 한번에 결과가 쑥쑥 나와서 프로덕션까지 가는 일은 거의 없음
- “데이터 모았으니 일단 알고리즘에 집어넣고 뭐가 나오는지 보자”가 잘 통하지 않음
- 학습된 모델의 형태나 성능으로부터 점진적으로 더 나은 가설을 얻기도 함
- 학습된 모델의 형태를 보고 더 간결한 형태의 모델을 만들기도 함
리서치 과정: 오렌지
- 퀀트 트레이딩 회사들은 굉장히 다양한 데이터를 구입해 사용
- 거래 시세, 공시자료
- 뉴스, 트위터, 웹 크롤링 결과, 애널리스트 리포트, …
- 인공위성 사진, 날씨 정보, 신용카드 사용 정보, …
- 어떻게 데이터에서 엑기스를 골라낼 것인가?
- 필터링, 노이즈 제거, 클리핑, outlier 감지, 데이터 정규화(normalization), 리그레션 정규화(regularization), NLP, …
리서치 과정: 쥬서기
- 어떤 알고리즘이 내가 가진 가설을 가장 잘 표현할 수 있을까?
- 내가 최적화하고 있는 목적함수가 정말 적절할까?
- 기존에 공개된 코드를 그대로 사용하기엔 데이터가 너무 많은데 어떻게 스케일링 해야 할까?
- 엔지니어링적 접근
- 모델링적 접근
리서치 과정: 쥬서기 이후 - monetization
- 어떤 거래소에 가서 거래할까?
- 어떤 주문 타입을 쓸까?
- 어떻게 포트폴리오를 관리해야 출렁임 없이 꾸준한 성능을 낼 수 있을까?
- 어떻게 하면 내 알파와 포지션을 노출하지 않고 거래를 할 수 있을까?
- 어떻게 하면 내 트레이딩이 시장에 미치는 영향을 최소화할 수 있을까?
- 시뮬레이터와 현실 세계의 차이는 어떻게 감안할까?
리서치 과정에서 흔히 주의해야 하는 것들
- 프로덕션 시스템과 백테스트 시스템의 차이
- 마켓 임팩트(market impace, 가격충격)
- 데이터 스누핑의 위험
- 최근 거래량 많은 주식 위주로 백테스트하기
- 거래 당일에는 아직 공개되지 않았던 데이터 사용 / 이후에 정정된 데이터 사용
- 평균 거래량 등의 통계지수가 실수로 당일을 포함
리서치 과정
- 모든 리서치가 그렇겠지만, 지루하고 반복적인 과정
- 새로운 아이디어가 떠오름 - 시뮬레이션도 잘 나옴 - 이제 우린 부자다! - 앗 버그가 있네 - 안되는구나의 무한한 반복
- 효율적으로 가설을 검증하고 확인할 수 있는 플랫폼에 대한 투자가 중요
- 회사 단위의 투자: 자체적인 노트북 리서치 플랫폼, 자체 클라우드, 자체 DSL, …
- 팀 단위의 투자: 쉽게 재현 가능한 리서치 스크립트, 리서치 효율성에 대한 투자, …
개발자 경력에서 여기까지
- 개발자 경력의 장점
- 남들의 프로세스를 개선하고 플랫폼화하는 과정에서 내 아이디어를 도입
- 수학적 모델링 기법/알고리즘과 그 구현 사이의 경계는 그렇게 확실하지 않음
- 리서치하다 막혀서 답답할 때 플랫폼 개선하면 속이 시원
- 개발자 경력의 단점
- 나는 개발로도 팀에 기여할 수 있기 때문에, 그 답답함을 이기지 못하면 계속 개발만 하게 됨
- $\rightarrow$ 리서치 과정의 느린 피드백에 익숙해지는 과정이 필요
- 내가 푸는 문제에 대해 결국 깊이 이해해야 함
- 잘 만들어진 알고리즘에 내 데이터를 꾸겨넣는 것만으로는 성공할 수 없음
- 시장의 구조와 다른 참가자들의 행동을 이해
- 내가 사용하는 알고리즘과 그 알고리즘이 표현할 수 있는 것/없는 것들
퀀트 트레이딩 일을 하려면
- 국내에도 관련 회사가 많음
- 트레이딩 스타트업, 전통적인 증권사 프랍 데스크, 로보어드바이저, 핀테크 스타트업, …
- 국외
- 아시아는 주로 홍콩/싱가폴, 유럽은 런던, 미국은 뉴욕/시카고
- 일할 곳을 찾으실 때는
- 플랫폼과 프로세스에 투자를 열심히 하고
- 내부적으로 연구 결과와 자료를 많이 공개하는 분위기의 회사가 좋음
댓글남기기