Day_31 02. Advanced Self-supervised Pre-training Models
작성일
Advanced Self-supervised Pre-training Models
- 보다 최근에 나온 Pre-training model 로서 GPT-1 의 후속버전인 GPT-2 와 GPT-3 그리고 기타 추가적을 나오고 있는 모델들을 살펴보자.
GPT-2
GPT-2: Language Models are Unsupervised Multi-task Learners
- Just a really big transformer LM
- Trained on 40GB of text
- Quite a bit of effort going into making sure the dataset is good quality
- Take webpages from reddit links with high karma
-
Language model can perform down-stream tasks in a zero-shot setting - without any paramter or architecture modification
- 모델 구조의 측면에서는 GPT-1 에 비교해서 크게 다를바가 없고 다만 Transformer 모델의 layer 를 점점 더 많이 쌓아서 모델을 키웠고 그리고 여전히 Pre-training task 는 Language Modeling task 인 다음 단어를 예측하는 task 로 학습을 진행했음
- 그리고 training 데이터는 굉장히 훨씬 더 증가된 사이즈의 데이터를 사용
- 여기서 주목할만한 것은 데이터셋을 대규모로 사용하는 과정에서 되도록 데이터셋의 퀄리티가 높은 그래서 데이터로부터 잘 쓰여진 글로부터 효과적으로 다양한 지식을 배울 수 있도록 하는 그런 방식을 유도했음
-
그리고 여러 down-stream task 가 생성모델이라는 language 생성 task 에서의 zero-shot setting 으로서 다뤄질 수 있다는 잠재적인 능력도 보여줌

-
GPT-2 라는 모델은 기본적으로 지금까지 주어진 text 를 바탕으로 다음 단어를 순차적으로 예측하는 task 이기 때문에 결과를 활용할 때 학습된 모델을 활용할 때

-
주어진 첫 문단이 있다면
-
이 문단을 이어받아서 다음 단어 그리고 그 다음 단어를 순차적으로 예측해서 하나의 긴 글을 완성할 수 있는 능력을 가지게 됨

- 여기서 GPT-2 에서 생성된 글이 얼마나 훌륭하고 합리적으로 말이 되는 문장을 생성했는지를 보고자 잠깐 story 를 따라가 보면
-
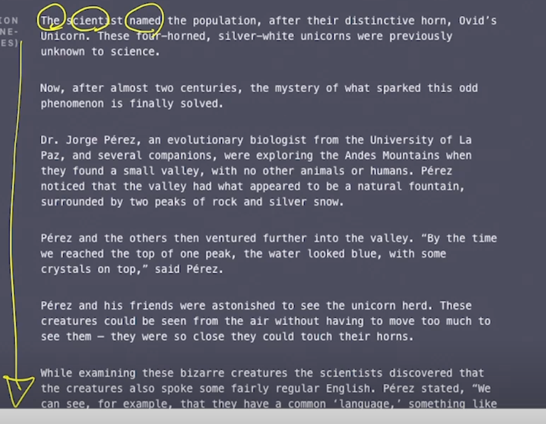
놀라운 발견으로서 과학자들이 유니콘의 떼를 많이 탐험이 되지 않았던 Andes 산맥에서 발견했다.

- 그랬더니 이를 GPT-2 가 이어받아서 다음 단어들로서 쭉 생성한 story 는
-
과학자가 유니콘 떼를 그들의 특징적인 뿔을 따라서 Ovid’s 유니콘이라고 불렀다고 하고

- 그 다음에는
-
Dr. Jorge Pèrez 라는 박사 이는 LaPaz 대학의 진화생물학자가 Andes 산맥을 탐험하다가 쭉 story 가 나름대로 그럴듯하게 이어진다는 것을 알 수 있음
- 그래서 이런 것처럼 GPT-2 가 사람이 봐도 굉장히 놀라울 정도의 퀄리티를 가지는 그런 글을 생성해줄 수 있다는 것이 굉장히 많은 사람들을 놀래켰음
GPT-2: Motivation (decaNLP)
- The Natural Language Decathlon: Multitask Learning as Question Answering
- Bryan McCann, Nitish Shirish Keskar, Caiming Xiong, Richard Socher
-
GPT-2 의 Motivation 을 간단히 설명해보자
- 3~4년 정도 전에 나왔던 Natural Language Decathlon 혹은 Multitask Learning as Question Answering 이라는 이런 task 를 착안을 한 것임
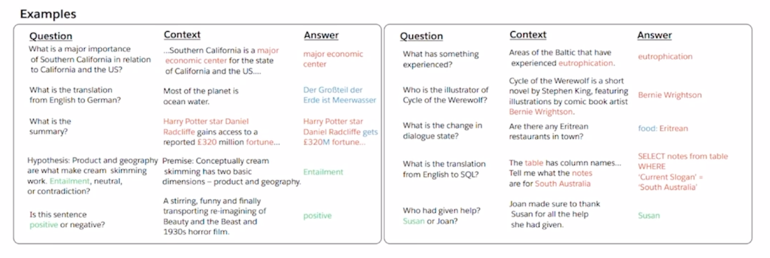
- 이 논문의 핵심은 주어진 문장이 긍정인지 부정인지 예측을 하면 “I love this movie” 에 대해서 문장을 encoding 하고 그 문장의 [CLS] 토큰을 뽑아서 그걸 Binary Classification task 를 하고 또 “How are you” 라는 문장이 주어졌을 때 대응하는 대화시스템에서의 문장을 생성하기 위해서 나와야 하는 문장이 “I’m fine” 이런 문장이 생성되는 경우 이 2개의 task 는 딥러닝 모델의 관점에서 보면 서로 모델구조가 상이한 왜냐면 output 의 형태가 굉장히 다르기 때문
- 그렇지만 이 논문에서는 모든 종류의 자연어처리에 관한 task 들이 질의응답으로 바뀔수 있다라는 그래서 통합된 자연어의 생성에 형태로 다양한 task 들을 통합해서 학습을 한 연구 사례가 됨
- 예를들면 “I love this movie” 라느 문장이 주어지면 그 문장이 긍정인지 부정인지를 분류하고자하면 그 이후에 질문 하나를 추가해서 “What do you think about this document in terms of positive or negative sentiment?” 이런식으로 질문을 만들수가 있고 혹은 조금 더 simple 하게는 “Do you think whether this sentence is positive or negative?” 이렇게 문장을 만들 수 있을 것임
- 요약의 task 의 경우는 주어진 문단에 대해서 마지막에 “What is the summarization of the paragraph?” 이렇게 할 수도 있고 아까의 번역 task 같은 경우 영어문장을 주고 “What is the translated sentence in Korean?” 라고 하면 그 뒤에 나올 질문에 대한 답은 자연어가 생성되는 형태로서 그에 해당하는 답으로 예측을 할 수 있는 이런 형태로 그 다양한 task 들을 다 자연어 생성의 output 을 가지는 질의 응답형태로 통합할 수 있다는 가능성을 보여준 연구사례가 됨
GPT-2: Datasets
- A promising source of diverse and nearly unlimited text is web scrape such as common crawl
- They scraped all outbound links from Reddit, a social media platform, WebText
- 45M links
- Scraped web pages which have been curated/filtered by humans
- Received at least 3 karma (up-vote)
- 45M links
- 8M removed Wikipedia documents
- Use dragnet and newspaper to extract content from links
- They scraped all outbound links from Reddit, a social media platform, WebText
- GPT-2 같은 경우 Dataset 의 측면에서 보면 굉장히 많은 데이터셋을 사용했지만 그 중에 높은 수준의 글을 선별적으로 그래서 좀 더 잘 쓰여진 글로부터 지식을 효과적으로 배울 수 있도록 Reddit 이라는 community 웹사이트 사람들이 질문을 올리면 그에 대해서 reply 를 쭉 달고 거기서 토론이 이루어지는 그런 형태의 플랫폼인데 가령 여기서 우리가 질문을 “스파게티를 어떻게 요리해야 맛있게 하나요?” 라고 질문을 올렸으면 그 밑에 쭉 답글이 달릴 수 있을 것임
- 근데 그렇게 답글이 달린 것들 중에 어떤 외부 링크를 포함하는 그런 포스팅이 있을 수 있고 그랬는데 그 외부링크를 포함한 포스팅 그 reply 가 많은 사람들로부터 좋아요를 받았을 경우에는 그 해당하는 외부링크로 갔을때의 그 해당 글이 가령 스파게티를 잘 요리할 수 있는 법을 잘 정리해둔 장문의 잘 쓰여진 글일 가능성이 높음
-
그래서 이러한 방식으로 3개 이상의 좋아요를 받은 그러한 글들 그리고 거기서 외부링크를 포함하는 경우 그 해당하는 외부링크를 실제로 가서 거기있는 document 들을 수집해서 그것들이 고품질의 잘 쓰여진 text 문서일 것이다 라고 해서 그 데이터들을 위주로 학습을 한 것이 GPT-2 에서의 특징중의 하나가 됨
- Preprocess
- Byte pair encoding (BPE)
- Minimal fragmentation of words across multiple vocab tokens
- 또 다른 기술적인 특징으로는 BERT 에 사용된 WordPiece 와 비슷하게 Byte pair encoding 이라는 sub-word 레벨의 word embedding 을 도출해주고 또 사전을 구축해줄 수 있는 알고리즘을 사용함
GPT-2: Model
- Modification
- Layer normalization was moved to the input of each sub-block, similar to a pre-activation residual network
- Additional layer normalization was added after the final self-attention block
- Scaled the weights of residual layer at initalization by a factor of $ \frac{1}{\sqrt{n}} $ where $n$ is the number of residual layer
- 세부적인 모델의 차이점을 원래 제안된 Transformer 모델의 self-attention blcok 과 비교를 해보면
- Layer normalization 이러한 layer 가 특정 위치에서 하나 더 위로가거나 아래로 가거나 이러한 세부적인 차이점들이 있고
- 각 layer 들을 random initialization 할 때 layer 가 위로가면 갈수록 layer 의 index 에 비례해서 혹은 반비례해서 initialization 되는 값을 더 작은 값으로 만듦
- 이는 layer 가 위쪽으로 가면 갈 수록 거기서 쓰이는 여러 선형변환에 해당하는 값들이 점점 더 0에 가까워 지도록 그래서 위쪽의 있는 layer 가 하는 역할이 점점 더 줄어들 수 있도록 모델을 구성했음
GPT2: Question Answering
- Use conversation question answering dataset(CoQA)
- Achived 55 $F_1$ score, excedding the performance 3 out of 4 baselines without labeled dataset
- Fine-tuned BERT achieved 89 $F_1$ performance
-
이렇게 만들어진 GPT-2 를 가지고 Question Answering 을 수행했을 때는 모든 task 들은 다 질의응답 형태로 바뀔 수 있다라는 사실에 입각해서 GPT-2 에서 했던 흥미로운 실험 중 하나는 대화형의 질의응답 데이터가 있을 때 실제로 이 task 를 수행하기 위해서는 이 해당 데이터로 물론 label 이 있는 그 학습데이터로 fine-tuning 하는 과정을 일반적으로 거치게 되지만 여기서는 아까 잠깐 나온 zero-shot learning 의 setting 에서 이 task 에 대한 예측 혹은 답을 맞추는 task 를 수행함에 있어서 질문글을 conversation 을 쭉 주고나서 바로 다음에 나올 답을 예측하도록 하는 결론적으로 학습데이터를 하나도 쓰지않고 이 task 에 맞바로 예측을 수행했을 때의 성능이 얼마나 나오는가를 테스트 해봤음
- 그랬더니 55% 정도의 F1-score가 나왔고 이는 당연히 해당하는 down-stream task 를 위한 데이터를 가지고 학습을 한 후에 fine-tuning 을 한 후 달성한 성능보다는 못미치지만 그래도 어느정도는 충분히 가능성을 보였다라는 사례가 있음
GPT-2: Summarization
- CNN and Daily Mail Dataset
- Add text TL;DR: ater the article and generate 100 tokens
- (TL;DR: Too long, didn’t read)

-
또 다른 예시로서 요약에 해당하는 task 를 수행하기 위해서도 이 fine-tuning 이라는 과정 없이 바로 zero-shot setting 으로 inference 를 수행할 수도 있음

- 이 경우 article 글을 쭉 주고 이 GPT-2 가 하는 역할이 다음 단어들 그리고 그 다음단어들을 순차적으로 생성하는 그런 역할을 하기 때문에 마지막에 TL;DR 이라는 단어를 마지막에 줌
- 그러면 학습데이터의 많은 글들 중에 이 TL;DR 이 나오면 앞쪽에 있었던 글을 한 줄 요약을 하는 형태로 문서가 형성된 경우들이 많았을 것이기 때문에 그 패턴을 통해서 TL;DR 을 바로 다음 단어로 붙임으로써 요약이라는 task 를 해당하는 요약글 위에 만들어진 그래서 labeled 된 데이터를 전혀 fine-tuning 에 혹은 학습에 사용하지 않고도 zero-shot setting 으로 요약을 수행할수 있게 됨
GPT-2: Translation
- User WMT14 en-fr dataset for evaluation
- Use LMs on a context of example pairs of the format:
- English sentence = French sentence
- Achieve 5 BLEU score in word-by-word substitution
- Slightly worse than MUSE (Conneau et al., 2017)


- Use LMs on a context of example pairs of the format:
- Translation 도 마찬가지로 주어진 문장이 있으면 그 다음에는 이 문장 다음에 우리가 번역을 하고픈 언어로해서 in other words in French 혹은 이렇게 they say in French 이런 식으로 마지막 부분을 붙여주면 앞서 나온 문장을 어느 정도 불어로 잘 번역을 하는 그런 사례를 보여줌
GPT-3
- 보다 더 최신에 나온 GPT-3 라는 모델임
GPT-3: Language Models are Few-Shot Learners
- Language Models are Few-Shot Learners
- Scaling up language models greatly improves task-agnostic, few-shot performance
- An autoregressive language model with 175 billion parameters in the few-shot setting
- 96 Attention layers, Batch size of 3.2M
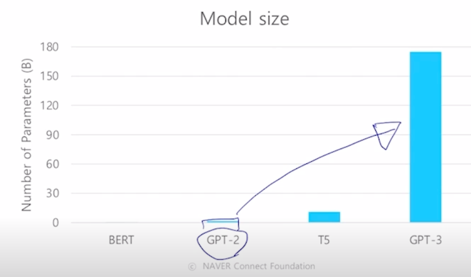
- GPT-3 는 앞서 봤던 GPT-2 를 훨씬 더 개선한 모델임
- 개선의 방향은 모델 구조 측면에서의 특별한 점이 있다기 보다는 기존의 있었던 GPT-2 의 모델사이즈 혹은 GPT-2 라는 모델이 가지던 파라미터 숫자들에 비해서 비교할 수 없을 정도로 훨씬 더 많은 파라미터수를 가지도록 Transformer 의 self-attention block 을 많이 쌓은 것임
-
그리고 역시 또 많은 데이터 그리고 더 큰 배치사이즈를 통해 학습을 진행했더니 성능이 점점 더 계속 좋아지더라 라는 그러한 결론을 내게된 모델임
- 이 GPT-3 는 작년에 NeurIPS 라는 인공지능의 가장 저명한 학회에서 best paper 상을 받은 것으로 알고 있음
GPT-3: Language Models are Few-Shot Learners
- Language Models are Few-shot Learners
- Prompt: the prefix given to the model
- Zero-shot: Predict the answer given only a natural language description of the task
- One-shot: See a single example of the task in addition to the task description
- Few-shot: See a few examples of the task

- GPT-3 라는 모델은 놀라운 점을 보여줬음
-
앞서 GPT-2 에서 말했던 zero-shot setting 에서의 어느 정도 가능성을 보여준 것을 굉장히 놀라운 수준으로 끌어올렸음

-
zero-shot setting 에서 번역에 대한 데이터를 직접적으로 학습에 전혀 활용하지 않았던 GPT-3 라는 모델 자체를 가져와서

-
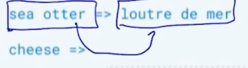
이런 text 를 주고

-
그 다음에 이런 text 를 주면 cheese 에 해당하는 French 단어를 번역을 하게 됨
-
그런데 이러한 zero-shot setting 즉, 영어를 불어로 번역하는 task 에 대한 학습데이터는 전혀 사용하지 않은 셈이 됨

-
여기서 또 흥미로운 실험을 한 것은

-
하고자 하는 task 를 text 로 주고
-
그 다음에는 예시를 하나 줌 그래서 주어진 이 부분에 대해서 불어로 번역된 예시를 하나 주고

-
그 다음엔 또 동일한 패턴으로 영어를 주고 나와야 하는 불어가 무엇일지를 자연어의 생성 task 로 수행을 해서 그 예측을 그 예측도를 정확도를 평가
-
그러면 이 경우, one-shot setting 이라고 볼 수 있음

- 이것은 결국 학습 데이터로서 번역을 위한 쌍에 해당하는 데이터를 한쌍만 주었다는 것이 됨
- 그렇지만 여기서 특이한 점은 이런 down-stream task 를 위한 학습데이터는 모델 구조를 일부라도 변경해서 즉 output layer 를 추가하고 그 output layer 를 추가적인 down-stream task 를 위한 학습 데이터로 학습을 하는 과정을 거쳤음
-
그렇지만 여기서는 학습데이터를 사용했지만 GPT-3 라는 모델 자체를 전혀 변형하지 않은 채 단지 inference 하는 과정중에 이 예시를 우리가 주는 text 의 일부로서 제시 했을 때 cheese 라는 단어를 주었을 때 다음에 나오는 번역의 결과가 zero-shot setting 보다 훨씬 더 좋아진다는 흥미로운 사실을 보여줌

-
이는 one-shot 에서 few-shot 으로 넘어간 즉 예시를 하나만이 아닌 여러개를 주었을 때 더 유의미하게 더 높은 성능을 내는 것을 알 수 있음

-
이는 별도의 fine-tuning 없이 GPT-3 모델을 그대로 가져와서 이러한 예시를 보여주고 그거를 이 시점에서 하나의 sequence 내에서 그 패턴을 동적으로 빠르게 학습한 후 task 를 수행할 수 있는 GPT-3 의 놀라운 능력을 보여줌
- Language Models are Few-shot Learners
- Zero-shot performance improves steadily with model size
- Few-shot performance increrases more rapidly
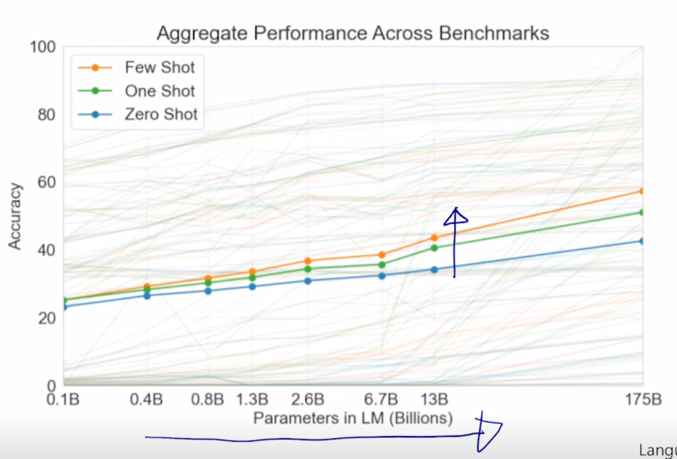
-
GPT-3 에서 보여준 다양한 결과중에 실제로 모델 사이즈를 점점 더 키우면 키울수록 방금 설명했던 zero-shot, one-shot 그리고 few-shot 에서의 성능이 올라가는 갭이 훨씬 더 빠르게 올라가더라 라는 것을 보여줌
- 즉, 큰 모델을 사용할수록 이 모델의 동적인 적응능력이 훨씬 더 뛰어나다는 사실을 보이게 됨
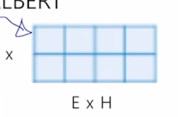
ALBERT
ALBERT: A Lite BERT for Self-Supervised Learning of Language Representations
- Is having better NLP models as easy as having larger models?
- Obstacles
- Memory Limitation
- Training Speed
- Solutions
- Factorized Embedding Parameterization
- Cross-layer Parameter Sharing
- (For Performance) Sentence Order Predition
- Obstacles
-
경량화된 BERT 모델로서 ALBERT 라는 모델을 살펴보자.
- 기본적으로 앞서 봤던 여러 Pre-training 모델들은 대규모의 memory 요구량과 많은 학습이 필요로하는 모델 파라미터를 가지는 형태로 점점 더 발전을 해왔음
- 이를 위해서는 점점 더 많은 GPU memory 를 필요로하고 이를 거대한 모델을 학습하는데 더 많은 학습데이터 더 많은 학습시간을 필요로 함
-
그래서 이 ALBERT 라는 모델에서는 기존에 있었던 BERT 모델이 가지던 모델이 굉장히 비대하다라는 부분들을 성능의 큰 하락없이 오히려 성능이 더 좋아지는 형태를 유지하면서도 모델 사이즈는 훨씬 더 줄이고 학습시간도 빠르게 만들 수 있는 그리고 또 추가적으로 새로운 변형된 형태의 문장레벨의 Self-supervised learning 의 Pre-training task 를 제안함
-
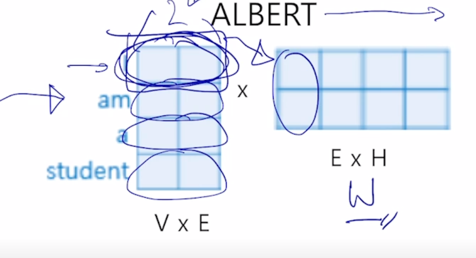
Factorized Embedding Parameterization
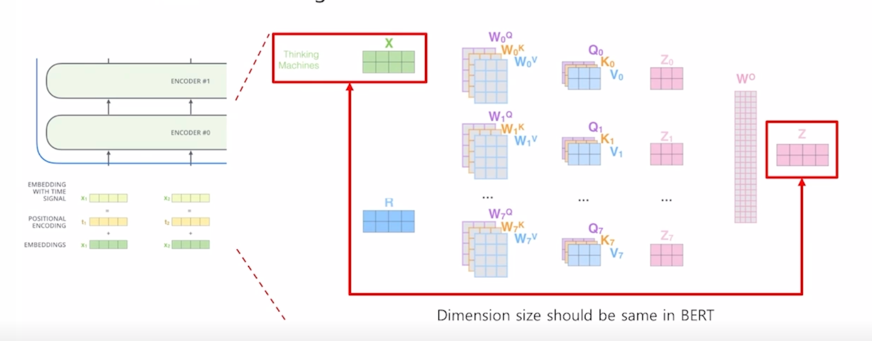
-
더 구체적으로 살펴보면 Factorized Embedding 이라는 부분은 Self-attention block 을 계속적으로 쌓아나감으로써 만들어지는 전체적인 BERT 나 GPT 등의 모델을 볼때에 항상 residual connection 혹은 skip connection 이 있기 때문에
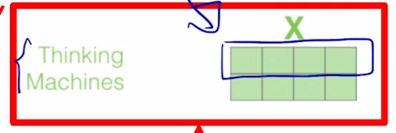
-
입력에 주어지는 word embedding 에 embedding vector 의 dimension 수 여기서는 “Thinking”, “Machines” 라는 2개의 단어로 이루어진 입력을 준다고 하면 여기서 예시로서 4개의 dimension 으로 이루어진 vector 를 word embedding 단에서 부터 준다고 하면
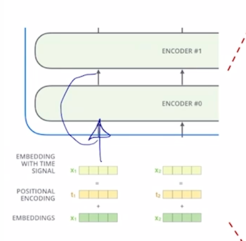
-
그러면 그것이 첫번째 self-attention block 에 들어갈 때도 4개의 dimension 이 유지가 되고 계속 skip connection 이 존재하기 때문에 그 다음 layer 에 self-attention block 에서도 4 dimension 도 결국 끝까지 동일한 dimension 이 유지되는 것을 알 수 있음
- 따라서 이 dimension 이 너무 작으면 정보를 담을 수 있는 공간자체가 굉장히 적이지게 되는 단점이 있을 수 있고 그렇지만 이 dimension 이 굉장히 크면 그만큼 모델사이즈도 커지고 거기에 필요로하는 연산량도 굉장히 증가하게 됨
- 그런데 생각을 해보면 이 layer 를 혹은 self-attention block 을 쌓아나가면서 거기서 점점 더 High-Level 의 semantically 유의미한 정보들을 계속적으로 추출해나가는 과정이 이 딥러닝에서의 layer 를 쌓는 과정이라고 볼 수 있음
-
이 첫번째 layer 에서 word 별로 주어지는 이 word 가 문장내에서 가지는 관계라든가 여러 contextual 한 정보들을 고려하지 않고 각 word 별로 독립적으로 상수형태 벡터로서 주어지는 embedding layer 가 있을 때, 그 embedding layer 에서의 word 가 가지는 정보는 위에서 전체의 sequence 혹은 그 문장을 고려해서 각 단어들을 encoding 을 해서 그 정보를 저장해야하는 그때의 그 hidden state vector 들에 대해서는 상대적으로 훨씬 더 적은 정보만을 저장하는 그런 정도로도 충분할 수 있음
-
그래서 이 ALBERT 라는 모델에 대해서는 embedding layer 에 dimension 을 줄이는 추가적인 기법을 제시함
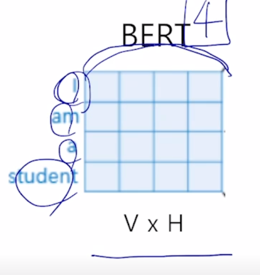
- Factorized Embedding Parameterization
- V = Vocabulary size
- H = Hidden-state dimension
- E = Word embedding dimension
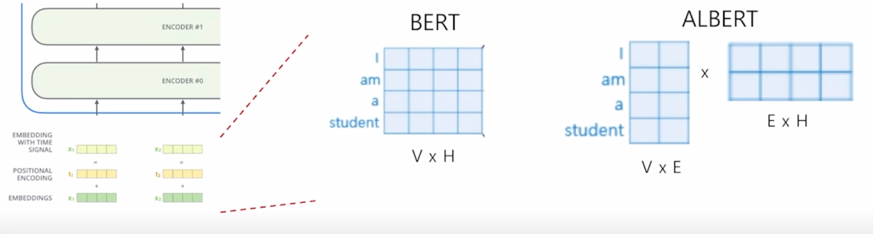
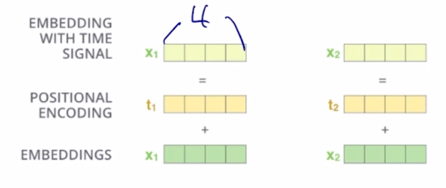
-
그러면 첫번째 두번째 self-attention block 에서 사용하는 어쩔수없이 고정해서 써야하는 dimension 이 가령 4 dimension 이라고 생각을 하면 일반적으로 word 가 가지는 embedding vector 의 positional embedding 을 더해주는 이런 형태로 진행이 됨
- 그러면 embedding layer 에서는 각각의 word 들이 위쪽 layer 에 self-attention block 에서 사용되는 dimension 과 동일한 dimension 을 어쩔 수 없이 가져야 되는 그래서 word embedding 의 dimension 도 4차원 벡터가 주어져야 하는데
-
이 경우에, word embedding 입력을 주기 전에 이 벡터를 뭔가 차원을 줄여서 필요로하는 파라미터와 계산량을 줄일 수 있는 그래서 첫번째 layer 에서 계산량이나 모델사이즈가 더 줄어들 수 있도록 하는 그런 형태로 기법을 제시
- 그 경우 실제로 아이디어는 이렇게 동작이 됨
-
어쨋든 위쪽에서 계속 나타나는 self-attention block 에 hidden state vector 의 dimension 이 4로 유지되어야 하는 만큼 첫번째 self-attention block 에서도 4차원의 입력벡터를 받아야 하는데 원래는 word embedding vector 도 4차원 이었어야 하는데
-
각 word 별로 그 보다 더 적은 차원수인 2차원 벡터만을 가지는 그런 word embedding 을 구성했다라고 하는 경우 입력이 2차원 벡터로 주어지기 때문에 4차원 벡터를 입력으로 받는 그래서 이 residual connection 이 다 성립하는 첫번째 self-attention block 에 입력 벡터를 만들어주기 위해서
-
추가적으로 layer 하나를 더 두고 그 layer 는 word 별로 구성되는 2차원 벡터 이 word embedding 벡터를 4차원으로 dimension 을 늘려주는 하나의 layer 를 더 추가하는 것임
-
추가된 layer 가 거기서 쓰여지는 선형변환에 해당하는 matrix 가 $W$ 라고 하면 이 matrix 에 왼쪽에서 row vector 를 입력으로 받아서 이 선형변환을 layer 에 output 을 생성하는 경우
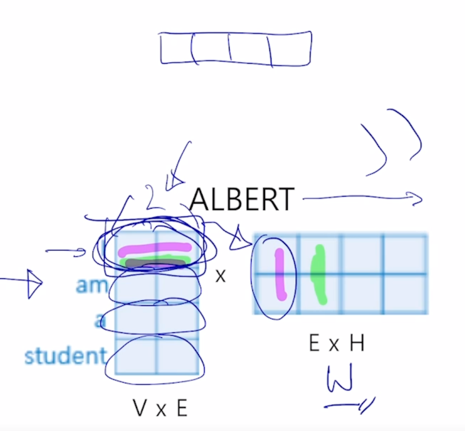
-
이 경우는 결과값으로서 2차원 vector 가 4차원 vector 로 차원이 늘어남을 알 수 있음
-
그래서 결국은 이 과정은 앞서 봤던 각각 word 들이 원래의 4차원의 embedding vector 를 가졌을 때를 생각해보면
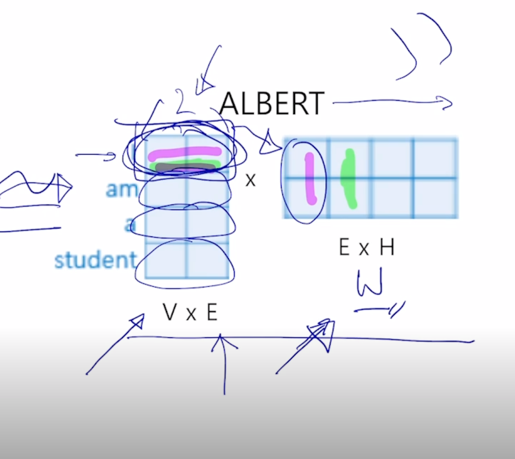
-
이것을 근사적으로 원래는 2차원 벡터로 주어지는 word embedding 벡터를 추가적인 layer 하나를 더 두어서 4차원 벡터로 불려주는 이 matrix 를 소위 row-rank matrix factorization 이라는 기법을 통해서 4차원 word embedding 벡터를 2차원 벡터 그리고 또 2차원의 word embedding 벡터에 공통적으로 적용되는 선형변환 matrix 하나가 있어서 이러한 방식으로 전체적인 파라미터 수를 줄여준 이런 방식을 생각할 수 있음
- 그래서 이것이 Factorized Embedding Parameterization 의 기술적인 detail 이 됨
-
그러면 이렇게하면 실제로 차원수나 여러 계산량이 줄어들 수 있는가를 살펴보면 이 경우는 simple 한 예제여서 차이가 극명하지 않게 보이긴 하지만
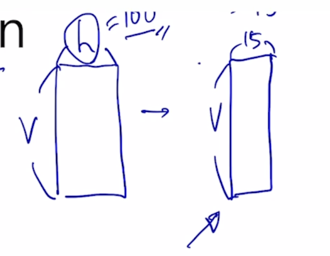
-
원래 가지는 vocabulary 사이즈가 있고 원래 사용해야하는 hidden state vector h 가 있을때, 이만큼의 파라미터가 필요한데 h 를 100 이라고 할 때 100 보다 훨씬 작은 15로 줄이도록 한다고 하면 15 만큼의 row dimension vector 로 word embedding matrix 를 구성하게 됨
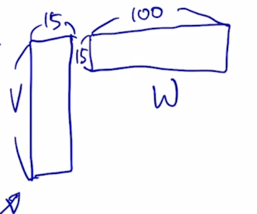
-
그 다음엔 15 dimension vector 를 다시 100 dimension vector 로 모든 self-attention block 에서 공통적으로 사용하여야 하는 dimension 수인 100 dimension 으로 다시 불려주기 위해서 앞서 봤던 그림과 마찬가지로 15 x 100 사이즈의 선형변환 matrix W 가 있다고 생각할 수 있음
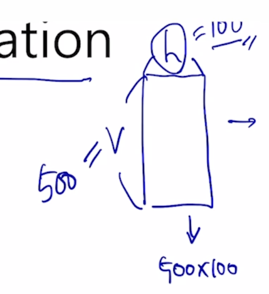
-
그러면 여기서는 V 도 예를들어서 500 이라고 한다면 500개의 각각의 word 를 다 100 dimension vector 로 정의하는데 필요한 파라미터는 500 x 100(= 50000) 이 되는 것인데
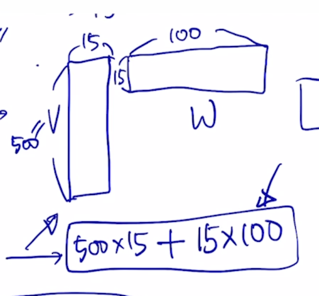
-
이 값이 500 x 15 + 15 x 100(= 15000) 만큼의 이러한 식으로 훨씬 더 적어진 숫자만을 학습에 사용하고 layer 의 파라미터 수 그리고 계산량 혹은 연산량도 이러한 방식을 통해서 훨씬 더 적어지는 것을 알 수 있음
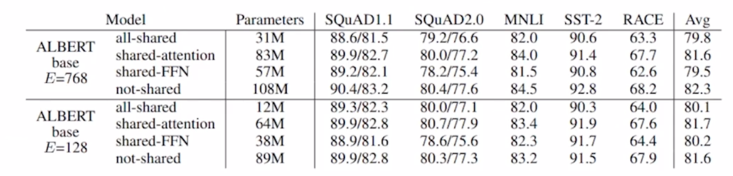
- Cross-layer Parameter Sharing
- Shared-FFN: Only sharing feed-forward network parameters across layers
- Shared-attention: Only sharing attention parameters across layers
- All-shared: Both of them
-
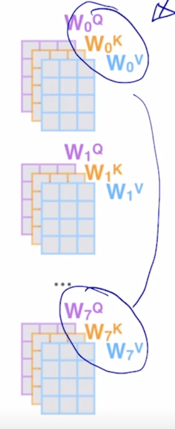
여기서 self-attention block 각각이 가지는 실제 학습을 해야하는 파라미터들이 무엇인가를 생각해보면
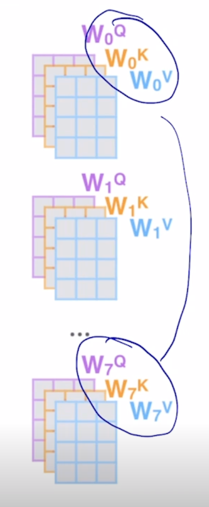
-
한 self-attention block 에서 학습해야하는 파라미터는 Query, Key, Value 각각의 vector 역할을 하도록 적용되는 선형변환 행렬들이 학습해야하는 파라미터가 되고 당연히 Multi-Head 를 사용하기 때문에 Head 수가 8개인 경우는 이러한 선형변환 행렬이 8 set 가 있음
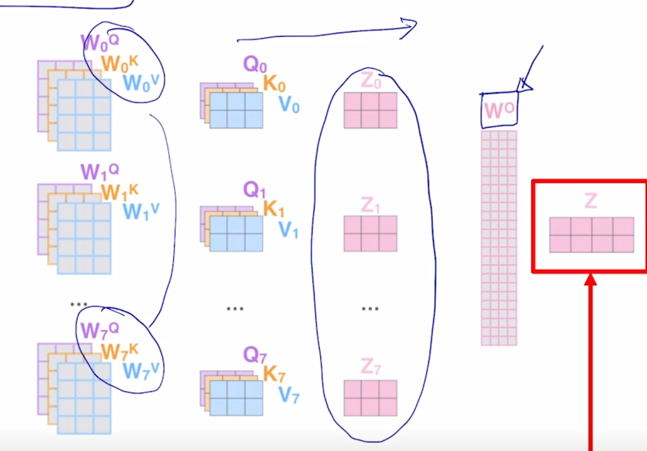
-
앞서 self-attention block 이 어떻게 구성되어 있는지를 상기해보면 여기서 얻어진 attention weithed Value vector 들을 각각 얻은 후 이 vector 들을 각 Head 별로 나온 vector 들을 다 concat 한 후 거기에 추가적으로 다시 원래의 hidden state vector 로 dimension 을 줄여주기 위한 output layer 로서의 또 다른 추가적인 선형변환 행렬이 있었던 것은 알 수 있음
-
그러면 학습의 실체 혹은 주체는 여기서의 $W^Q$, $W^K$, $W^V$ 각 Head 별로 존재하는 선형변환 matrix 와 각 Head 에서 나온 output 값들을 다 concat 한 후
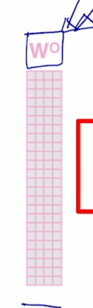
- 다시금 한번의 선형변환을 통해서 dimension 이 같은 형태의 vector 로 변환되도록 하는 matrix 가 학습에 필요한 matrix 가 되는데
- 이게 self-attention block 이 계속 쌓아지게 되면 이러한 행렬들이 self-attention block 별로 존재하게 됨
-
당연히 두번째 self-attention blcok 은 첫번째 self-attention block 과는 별개의 파라미터 셋을 가지게 됨
-
그런데 ALBERT 에서는 적층해서 쌓는 self-attention block 에서 서로 다른 self-attention block 에서 존재하는 이 선형변환 matrix 들을 공통적인 shared 되는 파라미터로 구성하면 어떨지 이런식으로 layer 가 총 12개면 12개 각각에 존재하는 $W^Q$, $W^K$, $W^V$ 그리고 output layer 에 해당하는 $W^O$ matrix 를 shared 된 하나의 set 의 파라미터로 동일하게 적용하는 layer 들로 기존의 BERT 모델을 개선한 것임
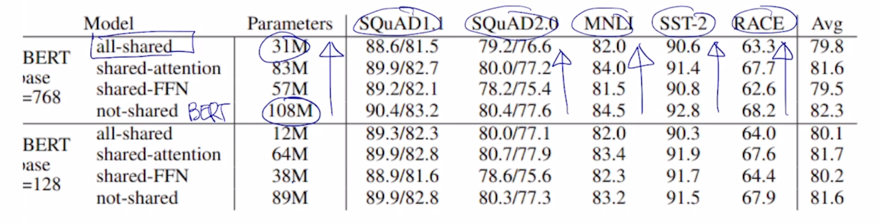
- 그래서 여기서 여러가지 실험들을 했음
- output layer 에 해당하는 feed-forward network parameter 이 부분만을 share 했을 때,
- 그리고 attention 을 수행하기 위해서 쓰이는 $W^Q$, $W^K$, $W^V$ 이 파라미터들 만을 share 했을 때,
-
그리고 이 둘을 모두 다 share 했을 때,
-
각각에 대해서 모델을 구성해서 학습을 진행한 후, 그 학습한 모델을 다양한 task 에 적용해서 fine-tuning 이후에 성능들을 살펴봤더니 실제로 두가지 모두를 share 한 모델이 가장 파라미터수는 적게 되고 성능에 있어서는 share 되지 않던 original BERT 모델에 비해서 성능의 하락폭이 그렇게 크지 않음을 보여줌
-
이러한 방식으로 모델의 사이즈를 혹은 모델에서 학습에 필요로하는 파라미터 개수를 굉장히 줄여준 모델이 ALBERT 에서 사용된 Cross-layer Parameter Sharing 이라는 기법임
- Sentence Order Prediction
- Next Sentence Prediction pretraining task in BERT is too easy
- Predict the ordering of two consecutive segments of text
- Negative samples the same two consecutive segments but with their order swapped

- 마지막으로 ALBERT 에서 제시한 또 다른 기법은 Sentence Order Prediction 이라는 기법임
-
이것은 기존의 BERT 에서 사용되던 Pre-training 기법이 2가지가 있었는데 2가지 중 하나는 Masked Language Modeling 으로서 어떤 단어를 [MASK] 라는 토큰으로 치환한 후 그 단어를 맞추는 첫번째 task 가 있었고 2개의 문장을 [SEP] 토큰으로 concat 해서 하나의 sequence 로 만들어 준 후 이 두 문장이 실제로 같은 document 에서 나온 연속된 문장인지 아니면 이 두 문장이 전혀 관련이 없는 두 document 로부터 랜덤하게 뽑아서 만든 그래서 이 2개의 문장을 [SEP] 토큰으로 concat 한 그런 형태의 문장인지를 구분하는 Next Sentence Prediction 이라는 두번째 Pre-training task 를 해서 BERT 모델이 학습이 되었었음
-
그런데 BERT 이후에 후속 연구들에서 Next Sentence Prediction 이라는 이 Pre-training task 는 그다지 BERT 모델에서 실효성이 많이 없더라 그래서 이 task 를 빼고 Masked Language Modeling 만을 수행했을 때에 fine-tuning 에서 나타나는 성능들이 Next Sentence Prediction task 를 포함했을때의 나온 완전체로서의 BERT 성능에 비해 그다지 떨어지지 않더라 라는 사실을 많이 지적을 함
- ALBERT 에서도 이러한 실제로 실효성이 많이 없던 Next Sentence Prediction task 를 좀 더 유의미한 task 로 바꾸어서 Pre-training 과정에서 이 모델이 task 를 통해서 유의미한 정보를 혹은 지식을 깨우칠 수 있도록 하는 그런 task 로 확장을 함
-
이는 어떻게 했냐면 2개의 문장이 실제 Next Sentence 인지 아닌지를 Prediction 하는 것이 아니라 항상 같은 문장내에서 연속적으로 등장하는 문장을 가져오고 그 문장을 원래 정순서 원래 있었던 순서대로 concat 을 해서 주었을 때는 원래 Sentence Order 가 맞는 Sentence Order 다 라는 형태로 예측을 하고 혹은 분류를 하고 그 다음엔 이 2개의 문장을 순서를 바꿔서 뒤에 나오는 문장이 앞서나오도록 그렇게 두 문장을 구성해서 Order 가 이번에는 자연스러운 순서가 아니라 이게 앞뒤가 역전된 순서인 것 같다라는 식으로 정Order 인지 혹은 역방향 역으로 된 Order 인지를 예측하는 Binary Classification task 로서 Next Sentence Prediction task 를 좀 더 변현을 함
-
그러면 이러한 task 는 기존의 BERT 에서 제안된 Next Sentence Prediction 에 비해 어떤 차이가 있는지를 생각해보자.
- 기본적으로 핵심은 Negative samples 임
- Negative sample 이라는 것은 구체적으로 BERT 에서 Next Sentence 에 해당하지 않는 그러한 예제를 학습데이터로서 만들기 위해서 랜덤하게 골라진 서로다른 두 문서에서 추출된 두개 문장에 [SEP] 토큰을 통해 concat 을 해서 그 경우는 Next Sentence 가 아니다라고 분류하도록 학습을 시켰었는데 이 경우에는 이 두 문장을 뽑아내는 두 개의 document 간에 내용이 그렇게 겹치지 않을 가능성이 높게 됨
- 가령 첫번째 문서는 정치면에서의 특정기사를 가져왔을 수 있고 두번째 문서는 가령 사회면에서 어떤 기사였을 수 있다면 별개의 두 문서로부터 추출된 두 문장간에는 실제로 내용이 굉장히 상이할 수 있음
- 가령 이 두문장간에 겹치는 단어들이 거의 존재하지 않다거나 그러한 방식으로 이 두문장이 별도의 문서에서 추출된 경우는 이것이 Next Sentence 의 관계가 아니다라는 것을 예측하기가 굉장히 쉬운 그런 형태가 될 수 있음
-
거꾸로 Next Sentence 관계가 있는 경우 같은 문장에서 인접한 문장을 실제로 뽑아온 경우에는 단어들이 굉장히 유사한 단어들이 두 문장간에 많이 나타나고 그렇게 되면 두 문장간에 자연스러운 논리적인 흐름 그런 미묘한 고차원적인 추론 과정에서 task 를 풀어야 되는 것이 아니라 단순히 내용적으로 볼 때 겹치는 단어가 많이 있느냐 아니냐로 심플하게 task 가 풀리는 그래서 너무 쉬운 task 를 BERT 를 통해서 Pre-training 과정에서 학습을 하게되면 이를 통해 얻게 되는 혹은 학습하게 되는 지식이 많이 없는 그러한 결과가 나왔던 것임
-
그래서 이 부분에 이 ALBERT 에서의 Sentence Order Prediction 에서는 Negative sample 그러니까 Next Sentence 가 아닌 경우를 여전히 동일 문서에서 뽑힌 여전히 인접문장 2개를 사용하되 그래서 단어의 Overlapping 면에서는 정방향이나 혹은 역방향으로의 순서간에 단어의 overlap 에서는 차이가 없는 그래서 정말로 논리적인 흐름을 아주 주의깊게 파악해야 이 task 를 풀 수 있는 그러한 형태로 Pre-training task 를 제안했고 이를 통해 좀 더 성능향상을 얻을 수 있게 됨

-
Sentence Order Prediction 의 효과를 보면 table 에서 보이는 것처럼 Sentence Prediction task 를 전혀 쓰지 않았을 때 그래서 Masked Language Modeling 만으로 학습했을 때, 그리고 BERT 에서 원래 제안됐던 Next Sentence Prediction task 그리고 그 task 를 ALBERT 에서 제안된 Sentence Order Prediction task 로 교체했을 때 그때의 성능의 어떤 패턴을 보면 실제 Sentence Prediction task 가 아예 없었을 때와 Next Sentence Prediction task 가 추가되었을 때 상황에서는 성능이 그렇게 차이가 많이 나지 않는 오히려 성능이 떨어지는 경우도 존재하는 양상이 보여졌는데 Sentence Order Prediction 을 추가했더니 성능이 다른 두 케이스보다 유의미하게 더 좋은 성능을 내는 그런 형태로 나오게 됨
-
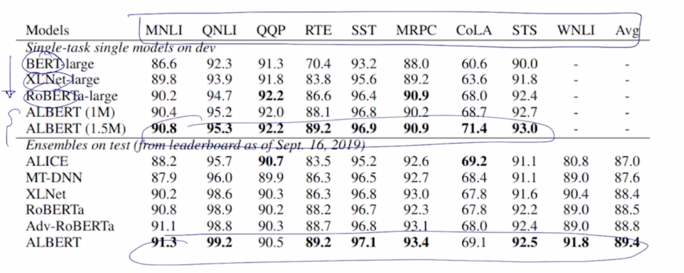
GLUE Results
-
다음으로는 다양한 자연어처리 task 를 Benchmark 데이터셋으로 포함하는 GLUE 데이터셋에 대한 Benchmark 결과도 보면 여기서 제시된 다양한 task 들에 대해서 BERT 그리고 XLNet, RoBERTa 이런 BERT 및 변종 모델들에 비해 ALBERT 모델이 전체적으로 가장 좋은 성능을 내는 것을 볼 수 있음
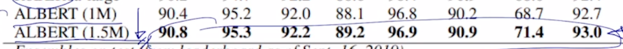
- 그리고 BERT 에서도 BASE 모델과 LARGE 모델 즉, layer 를 얼마나 많이쓰고 그리고 Multi-HEAD attention 의 Head 수나 hidden state vectord 의 dimension 수를 더 늘려서 더 큰 모델로 사용하느냐 작은 모델로 사용하느냐에 따라서 모델의 2가지 버전이 있었다면 ALBERT 에서도 역시 모델사이즈나 필요로 하는 파라미터수를 변환해서 더 큰 모델을 사용했을 때 좀 더 좋은 성능을 내는 것을 볼 수 있음
ELECTRA
ELECTRA: Efficiently Learning an Encoder that Classifies Token Replacements Accurately
- Efficiently Learning an Encoder that Classifies Token Replacements Accurately
- Learn to distinguish real input tokens from plausible but systhetically generated replacements
- Pre-training text encoders as discriminators rather than generators
- Discriminator is the main networks for pre-training
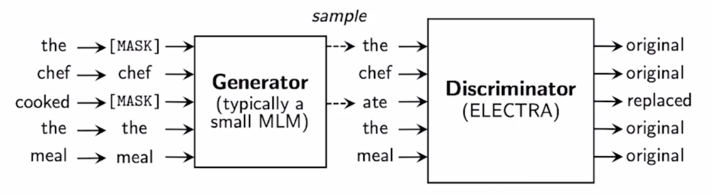
- 또 다른 Pre-training 모델은 ELECTRA 라는 Efficient Learning an Encoder that Classifies Token Replacements Accurately 이런 제목을 가지는 논문임
-
이 논문은 작년에 출판된 논문으로 기존의 BERT 나 GPT-2 등의 모델들과는 조금은 다른 형태로 Pre-training 을 한 모델이 되는데 여기서는 실제로 BERT 에서 사용한 Masked Language Modeling 그리고 GPT 계열에서 사용한 standard 한 형태 다음단어를 예측하는 standard 한 Language Modeling 이 task 에서 한 발 더 나아가서 그런 Language Modeling 을 통해 단어를 복원해주는 그런 모델을 하나 더 두고 그래서 이를 Generator 라고 부르고
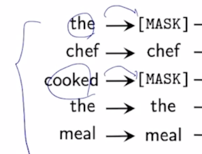
-
이 모델이 Masked Language Modeling 을 가령 수행하는 경우 주어진 문장에서 일부 단어를 [Mask] 토크으로 치환을 했고
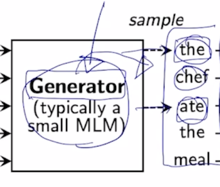
-
이를 다시 예측한 단어로 복원해 놓은 주어진 문장에 대해서
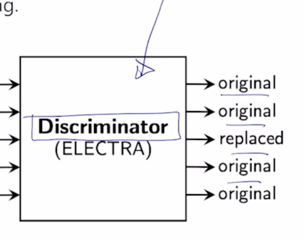
-
이 문장이 실제로 각각의 단어가 기존의 딥러닝 예측모델에 의해서 실제로 이렇게 replace 된 (대체된) 혹은 예측된 단어인지 혹은 이 단어는 원래부터 있었던 단어였는지를 단어별로 예측하는 그런 형태의 구분자 혹은 Discriminator 라는 두번째 모델을 별도로 둔 그런형태가 ELECTRA 모델의 가장 핵심적인 특징이 됨
- 그러면 Generator 는 앞서 배웠던 BERT 모델로 생각할 수 있고 이 BERT 모델은 Masked Language Modeling 을 통해서 기존 학습데이터에 일부 데이터를 가려준 입력을 받아서 각 단어들을 필요한 단어 필요한 부분에서 복원한 이런 문장을 다시 입력으로 받은 두번쨰 모델이 존재함
- 이 Discriminator 의 모델구조는 기존의 BERT 나 GPT-2, GPT-3 와 비슷하게 역시 Transformer 에서 제안된 self-attention block 을 쭉 쌓은 그런 형태의 모델임
- 이 모델에서는 각 단어별로 예측을 하는데 그 예측이 Binary Classification 혹은 이진분류로서 이 단어가 원래 있었던 단어다 혹은 이 단어는 뭔가 어색한 부분이 있기 때문에 replaced 된 예측에 의해서 채워진 그래서 조금은 불완정성이 보이는 단어다 라는 그런 것을 예측하는 모델이 됨
- 그러면 이 경우는 이 두가지 모델이 서로 적대적 관계 혹은 Adversarial Learning 이라고 부르는 그런 형태로 학습이 진행이 되고 그러한 모델은 대표적으로 Generative adversarial network 혹은 이를 GAN 이라고 부르는데 이 GAN 모델에서 사용된 아이디어에 착안해서 Language Modeling 혹은 자연어처리에서 Pre-training 모델을 제안함
- 그래서 이 Generator 를 혹은 BERT 모델과 흡사한 이 모델을 학습을 함으로써 문장을 복원하는 모델을 학습하고 그 복원된 문장에서 이 단어가 실제로 Masked 된 단어였어서 실제로 replaced 된 단어고 혹은 어떤 단어는 원래 있었던 단어고 이 정보를 알고 있기 때문에 이 ground-truth 정보를 알고 그 정보를 통해서 이 두번째 network 인 Discriminator 를 학습하게 됨
- 그러면 이 과정을 반복적으로 수행함으로써 이 Discriminator 를 점점 더 고도화를 시킬 수가 있음
-
그러면 최종적으로 이러한 방식으로 모델 학습을 진행한 후에는 Pre-training 된 모델로서 사용할 수 있는 부분이 이 두 부분인데 여기서는 Generator 부분에 해당하는 Masked Language Modeling 을 담당하던 Generator 부분을 Pre-training 모델로 사용하는 것이 아닌 Discriminator 즉 각 단어가 Original 이었는지 Replaced 된 단어였는지를 예측하는 혹은 분류하는 그 모델을 실제 다양한 main down-stream task 들에 fine-tuning 형태로 사용하는 Pre-training 된 모델로 사용하게 됨
- Replaced token detection pre-training vs masked language model pre-training
- Outperforms MLM-based methods such as BERT given the same model size, data, and compute
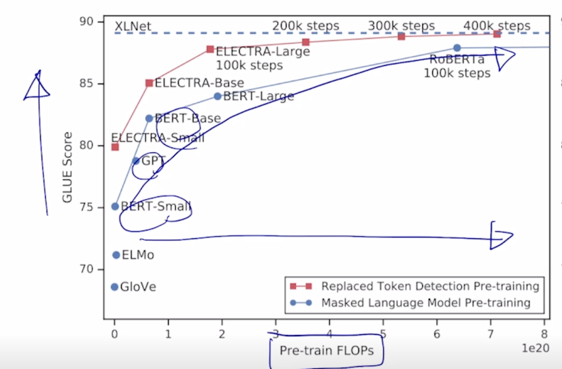
-
그렇게 학습을 해서 만들어진 ELECTRA 라는 모델은 실제로 masked language modeling 을 통해서 학습된 BERT 모델에 비해 Pre-training 하는데 사용되는 학습에 필요한 계산량을 기준으로 본다면 계산량이 점점 더 많아지면 많아질수록 여러 모델이 존재하는 가운데 일반적으로 학습을 더 많이하게 되면 모델의 성능이 GLUE 라는 Benchmark 점수가 올라가는 것을 알 수 있음
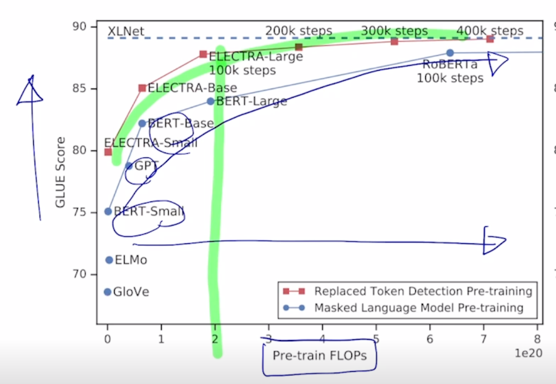
-
ELECTRA 모델 같은 경우 같은 Pre-training 계산량에 비해서 더 좋은 성능을 보여줌을 알 수 있음
- 그래서 앞서 말했던 ALBERT 라는 모델과 더불어 ELECTRA 라는 모델도 굉장히 많은 down-stream task 들에서 실질적으로 많이 활용이 되고 있음
Light-weight Models
- DistillBERT (NeurIPS 2019 Workshop)
- A triple loss, which is a distillation loss over the soft target probabilities of the teacher model leveraging the full teacher distribution
- TinyBERT (Findings of EMNLP 2020)
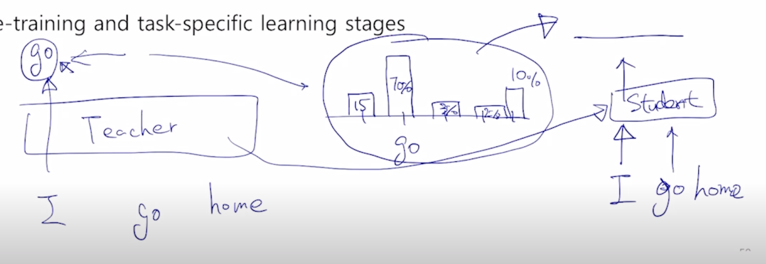
- Two-stage learning framework, which performs Transformer distillation at both the pre-training and task-specific learning stages
- 그 이외에는 이 Pre-training 된 모델을 다양한 방식으로 고도화하는 그런 연구들이 최근까지 활발하게 연구되고 있음
- 그 중에 한 방향으로서는 이 모델의 경량화라는 부분이 있음
-
경량화 모델은 기존의 BERT, GPT-2, GPT-3 그리고 ELECTRA 등의 모델들이 self-attention block 을 점점 더 많이 쌓음으로써 점점 더 좋은 성능을 내는 그렇지만 이런 모델들을 Pre-training 하는데에 많은 GPU resource 와 학습시간 혹은 계산량이 필요했던 그것이 어떻게보면 이 모델들을 실제 다양한 연구나 현업에 활용하는데에 걸림돌이 되었다면 이 굉장히 비대해진 모델을 좀 더 적은 layer 수나 적은 파라미터수를 가지는 형태의 경량화된 모델로 발전시키는 혹은 확장하는 그런 형태의 연구가 됨
- 그래서 경량화 모델의 연구 추세는 기존의 원래는 굉장히 큰 사이즈의 모델이 가지던 성능을 최대한 유지하면서도 이 모델의 크기와 그리고 모델의 계산속도를 빠르게 하는것에 초점이 맞추어져 있음
- 이 경량화된 모델은 클라우드 서버나 고성능의 GPU resource 를 사용하지 않고서도 가령 휴대폰 등의 소형 디바이스에서도 이러한 모델을 load 해서 더 적은 양의 전력소모 혹은 배터리 소모량으로 빠르게 계산을 수행하고자 할 때에 주로 사용이 됨
-
이 모델을 경량화하는 방식은 다양하게 존재하지만 여기서는 Distillation 을 사용한 2개의 모델만 짧게 설명해보자.
- 먼저 DistillBERT 라는 논문은 Transformer 모델의 구현체 그리고 그 구현체를 다양하게 라이브러리 형태로 편하게 쓸 수 있도록 제공을 해주는 것으로 유명한 Huggingface 라는 회사에서 2019 년도 NeurIPS 라는 학회의 워크샵에서 발표한 논문임
- 이 논문에서는 기본적으로 teacher 모델과 student 모델이라는 것이 있음
- 말 그대로 teacher 모델은 student 모델을 가르치는 역할을 하는 그런 형태가 됨
- student 모델은 teacher 모델에 비해서는 더 layer 수나 여러가지 파라미터 측면에서 더 작은 경량화된 형태의 모델로 설계되어 있어서 훨씬 더 큰 사이즈의 모델인 teacher 모델이 내는 여러 output 이나 패턴을 잘 모사할 수 있도록 학습을 진행함
-
조금더 구체적으로 설명하자면 경량화된 혹은 작은 사이즈의 student 모델은 teacher 모델이 주어진 문장에서 Masked Language Modeling 을 수행할 때 단어를 예측하는 형태에서 output 즉 softmax를 통과하고 난 vocabulary 상에서 존재하는 어떤 확률 distribution 이 있을때에
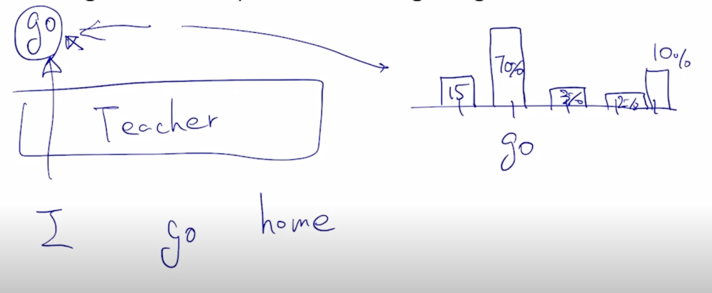
-
그 확률 distribution 이 “I go home” 에서 “I” 라는 단어가 주어져 있을 때 “go” 가 나와야 하지만 실제 우리의 굉장히 큰 teacher 모델의 예측값은 단어가 가령 5개의 단어로 이루어진 vocabulary 가 존재한다고 하면 “go” 라는 단어가 두번째 단 그리고 softmax 확률이 70% 그리고 또 다른 단어에서는 15% 그리고 다른곳에서는 3% 그 옆에서는 2% 그리고 옆에서는 10% 정도의 비율로 vocabulary 사이즈 만큼의 확률 distribution 을 예측값으로 줬다면
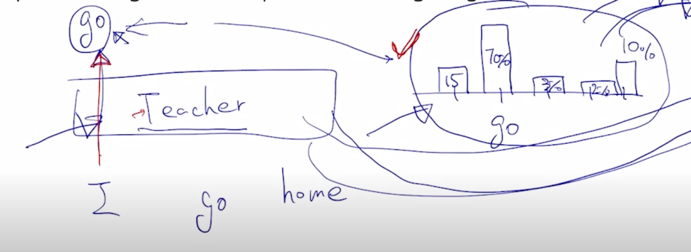
-
아까 말한것처럼 student 모델은 teacher 모델에 비해서 훨씬 더 작은 수의 파라미터를 가지는 경량화된 모델인데 “I” 라는 단어가 들어갔을 때 나오게 되는 vocabulary 사이즈 만큼의 확률 distribution 이 softmax 의 output 으로 나올 때 거기에 적용하는 ground-truth probability 를 바로 teacher 모델이 가지는 확률분포를 softmax 에 주는 ground-truth probability 로서 사용하는 것임
- 이렇게 함으로써 student 모델이 teacher 모델이 하는 여러 행동 혹은 예측 결과를 최대한 잘 모사할 수 있도록 학습을 진행하게 됨
-
그래서 이러한 것이 Knowledge Distillation 이라는 개념을 사용한 것을 BERT 라는 Pre-training 모델에 적용해서 모델을 경량화시킨 DistillBERT 라는 모델이 됨
- 두번째로 TinyBERT 라는 모델은 역시 Knowledge Distillation 이라는 테크닉을 사용한 형태로 BERT 를 보다 경량화한 모델이 됨
- 여기서도 마찬가지로 teacher 모델 그리고 student 모델이 있음
-
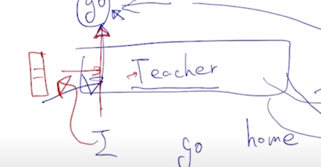
그렇지만 DistillBERT 와는 달리 target distribution 을 모사해서 이를 ground-truth 로서 softmax loss 를 적용해서 teacher 모델을 닮도록 student 모델을 학습하도록 하는 이러한 방식뿐만 아니라 어떤 embedding layer 그리고 각 self-attention block 이 가지는 $W^Q$, $W^K$, $W^V$ 등의 attention matrix 그리고 그 결과로 나오는 hidden state vector 들 까지도 유사해지도록 결국은 파라미터들 그리고 중간 결과물들 까지도 모두다 student network 가 닮도록 하는 그러한 형태로 학습을 진행하게 됨
-
가령 teacher 모델에서 최종적인 output 의 예측값이 이렇게 나왔긴 하지만
-
그 중간결과물 중간에 layer 에 있는 hidden state vector 가 3차원 벡터로 “I” 에 대한 벡터가 주어지면
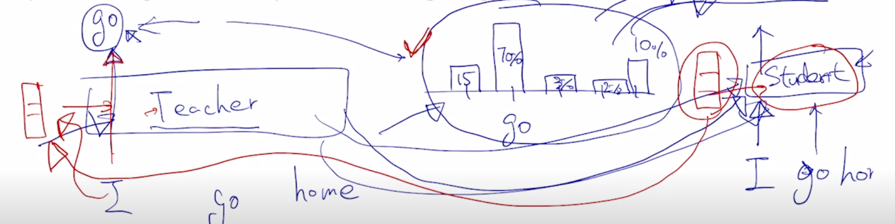
-
student 모델에서의 해당하는 중간 layer 에서의 hidden state vector 도 역시 3차원 벡터라고 한다면 이 중간 결과물에 해당하는 벡터도 teacher 모델의 중간 결과물에 최대한 가까워지도록 MeanSquaredError 이 MSE loss 를 통해 학습을 동시에 진행하게 됨
-
그렇지만 이 경우 일반적으로 student 모델은 hidden state vector 가 기존 teacher 모델의 hidden state vector 의 차원수보다 더 작을 수 있기 때문에 이 차원이 달라짐으로써 이러한 벡터가 곧이곧대로 동일한 차원만큼의 벡터와 유사해지도록 해야한다라는 loss 를 적용하기 어려울 수도 있음
-
그래서 이 논문에서는 서로 차원이 다른 hidden state vector 와 최대한 유사해지도록 하고자 하는 그 loss 를 적용하기 위해 teacher 모델의 hidden state vector 가 student 모델의 더 적은 수의 hidden state vector 로 차원이 변환되는 그러한 형태의 Fully connected layer 하나를 더 두어서 그 부분도 역시 학습 가능한 파라미터로 두어서 이런 dimension 간의 mismatch 를 해결했음
- 그래서 TinyBERT 의 핵심은 가장 최종 output 즉, vocabulary 사이즈 만큼의 어떤 softmax output 으로서 나타나는 예측값만 똑같아지도록 학습할 뿐만 아니라 이 중간 결과물들도 teacher 와 student network 가 최대한 닮도록 혹은 유사해지도록 학습을 했다르는 부분이 TinyBERT 의 가장 큰 특징이 됨
Fusing Knowledge Graph into Language Model
- ERNIE: Enhanced Language Representation with Informative Entities (ACL 2019)
- Informative entities in a knowledge graph enhance language representation
- Information fusion layer takes the concatenation of the token embedding and entity embedding
- KagNET: Knowledge-Aware Graph Networks for Commonsense Reasoning (EMNLP 2019)
- A knowledge-aware reasoning framework for learning to answer commonsense questions
- For each pair of question and answer candidate, it retrieves a sub-graph from an external knowledge graph to capture relevant knowledge
-
다음으로 소개하고자 하는 최신 연구 흐름은 기존의 Pre-training 모델과 어떤 지식 그래프라고 부르는 혹은 Knowledge Graph 라고 불리는 외부적인 정보를 잘 결합하는 형태의 연구 방향임
- BERT 라는 모델이 2018년도에 등장하 이후에 모델이 언어적 특성을 잘 이해하고 있는지 혹은 잘 이해하고 있지 못하는지에 그러한 부분이 어떤것인지를 알아보는 분석하는 연구들이 많이 진행됨
- 그 결과로 결론적으로 BERT 는 주어진 문장이 있을 때 혹은 이보다 더 긴 글이 있을 때에 문맥을 잘 파악하고 각 단어들간의 어떤 유사도라던지 관계들은 굉장히 잘 파악하긴 합니다만 주어진 문장에 포함되어 있지 않은 추가적인 정보가 필요한 경우에는 그 정보를 효과적으로 활용하는 능력은 잘 보여주지 못함
- 가령 주어진 문장에서 “땅을 팠다” 라는 문장이 주어져있는데 앞뒤 문맥을 볼 때 “꽃을 심기위해서 땅을 팠다” 라는 문장이 있다라고 생각을 하고 또 다른 문장의 경우에는 우리가 “집을 짓기 위해서 땅을 팠다” 라는 문장이 주어져있다고 생각을 해보자
- 이때 여기서 Question Answering 이라는 task 를 예를 들었을 때 “땅을 무슨 도구로 팠을까?” 를 질문으로 한다면 그러면 앞서 말했던 문장에서는 땅을 무엇으로 팠는지에 대한 도구의 정보는 문장내에서는 나타나 있지 않음
- 이런 경우 사람의 경우에는 이 두가지 경우에서도 꽃을 심는 경우에는 작은 부삽같은 도구를 사용해서 땅을 팠을 수 있고 집을 짓는 경우는 훨씬 더 대규모로 땅을 파야하기 때문에 포크레인이나 대규모의 중장비를 통해서 땅을 팠을 수 있음
- 그래서 이러한 질문에 대해 답을 어느 정도 알 수 있는 것은 주어진 문장에서 담고 있는 정보뿐만 아니라 기본적으로 가지고 있는 외부지식 혹은 이를 상식이라고 표현할 수 있게되는 것인데 이미 알고 있는 여러 상식들이 역시 또 자연어 처리를 할 때 중요한 요소가 되는 것임
- 그래서 이러한 외부정보 혹은 외부지식들이 바로 전통 인공지능 분야에서 Knowledge Graph 라는 형태로 표현이 됨
- 가령 이 경우는 땅이라는 개체 그리고 파다라는 행동이라는 개체 이 두가지의 개체를 이어주는 어떤 관계로서 그 도구는 가령 부삽이라는 도구도 있을 수 있고 포크레인 같은 중장비의 도구도 있을 수 있음
- 그래서 이 세상에 존재하는 다양한 개념이나 개체들을 잘 정의하고 그들간의 관계를 잘 정형화해서 만들어 둔 것이 Knowledge Graph 라는 것이 됨
- BERT 는 주어진 문장에서 여러 정보들을 잘 추출하는 것은 잘 할 수 있지만 설명한 외부지식이 필요한 경우에는 취약점을 보이기 때문에 그러한 부분을 Knowledge Graph 로서 잘 정의하고 이를 어떻게하면 기존에 우리가 하던 BERT 등의 Language Modeling 혹은 이런 Pre-training 모델에 잘 결합해서 이런 외부지식이 필요한 경우에도 다양한 task 를 잘 할 수 있을까에 대한 연구가 바로 여기서 소개하는 연구방향이 됨
댓글남기기