Day_31 01. Self-supervised Pre-training Models
작성일
Self-supervised Pre-training Models
- 앞서 배운 Transformer 모델을 사용해서 Self-supervised Learning 이라는 Task 를 통해 Pre-Training 그리고 다양한 다른 Task 에 fine-tuning 의 형태로 NLP 의 많은 Task 의 성능을 올린 GPT-1 그리고 BERT 모델을 살펴보자.
Recent Trends
-
Self-supervised learning 과 BERT 를 위시한 다양한 Pre-Training Model 에 대한 최신 발전 동향을 먼저 살펴보자.
- Transformer model and its self-attention block has become a general-purpose sequence (or set) encoder
and decoder in recent NLP applications as well as in other areas
- Transformer 및 여기서 제안한 self-attention block 은 범용적인 sequence encoder 그리고 decoder 로서 최근 자연어처리 다양한 분야에서 좋은 성능을 내고 있고 심지어 다른 분야에서도 Transformer 및 self-attention 기반 모델이 활발히 사용되고 있음
- Training deeply stacked Transformer models via a self-supervised learning framework has significantly
advanced various NLP tasks through transfer learning, e.g., BERT, GPT-3, XLNet, ALBERT, RoBERTa, Reformer,
T5, ELECTRA…
- 앞서 배운 Transforemr 는 self-attention block 을 대략 6개 정도만 쌓아서 사용했다면 최근 모델의 발전동향은 Transformer 에서 제시된 self-attention block 을 점점 더 많이 쌓아서 12개 혹은 24개 혹은 그 이상의 layer 를 모델 구조자체에 대한 변경은 없이 deep 하게 쌓은 모델을 만들고 이를 대규모 학습 데이터를 통해서 학습할 수 있는 Self-supervised learning framework 로 학습한 후 이를 다양한 task 들의 transfer learning 형태로 fine-tuning 하는 형태에서 좋은 성능을 내고 있음
- Other applications are fast adopting the self-attention and Transformer architecture as well as
self-supervised learning approach, e.g., recommender systems, drug discovery, computer vision, …
- self-attention 모듈은 추천시스템, 신약개발 그리고 영상처리 분야까지도 확장 폭을 넓혀가고 있음
- As for natural language generation, self-attention models still requires a greedy decoding of words
one at a time
- 그렇지만 Transformer 에서의 self-attention 에 기반한 모델들도 자연어 생성이라는 task 에서 단어를
토큰부터 시작해서 처음부터 왼쪽에서 하나씩하나씩 생성한다는 그러한 greedy decoding framework 에서 벗어나지는 못하고 있는 한계점도 동시에 가지고 있음
- 그렇지만 Transformer 에서의 self-attention 에 기반한 모델들도 자연어 생성이라는 task 에서 단어를
GPT-1
-
Pre-Training 모델의 가장 시초격인 GPT-1 이라는 모델에 대해 살표보자.
- Tesla 의 창업자인 일론머스크가 세운 비영리 연구 기관인 OPEN-AI 에서 나온 모델
- 최근에 GPT-2, GPT-3 까지 이어지는 모델을 통해 굉장히 놀라운 자연어 생성에서의 결과를 보여주고 있음
Improving Language Understanding by Generative Pre-training
- GPT-1
- It introduces special tokens, such as
<S>/<E>/$, to achieve effective transfer learning during fine-tuning - It does not need to use additional task-specific architectures on top of transferred
- It introduces special tokens, such as
-
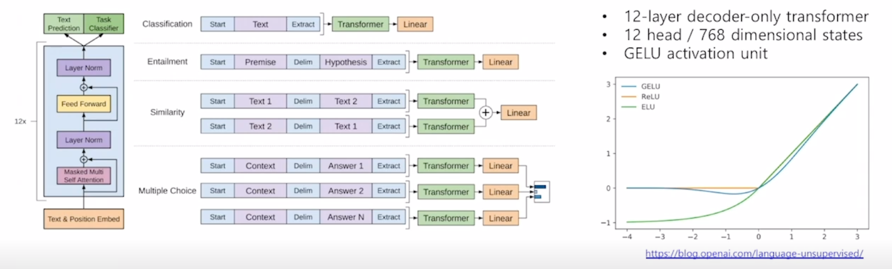
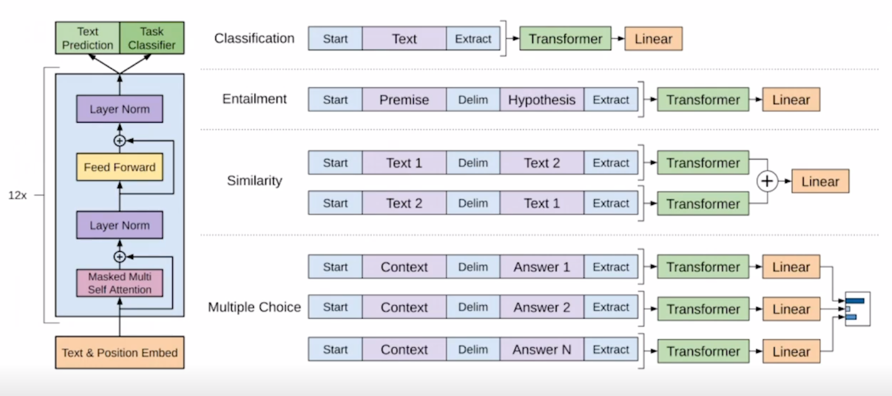
GPT-1 의 특징은 기본적으로 다양한 special token 을 제안해서 simple 한 task 뿐만 아니라 다양한 자연어처리에서의 많은 task 들을 동시에 커버할 수 있는 통합된 모델을 제안했다는 것이 중요한 특징임
-
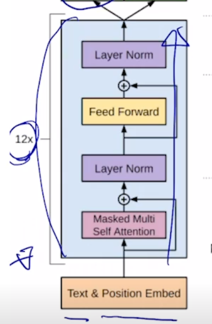
기본적으로 GPT-1 의 모델구조와 모델의 학습되는 방식에 대해서 살펴보자.
-
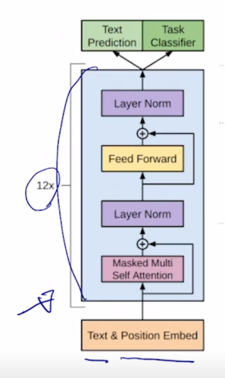
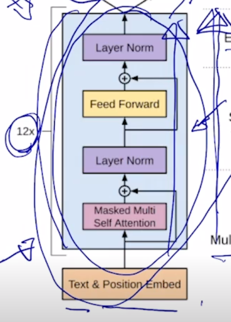
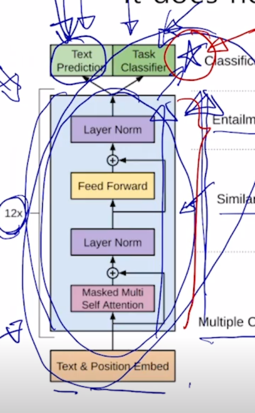
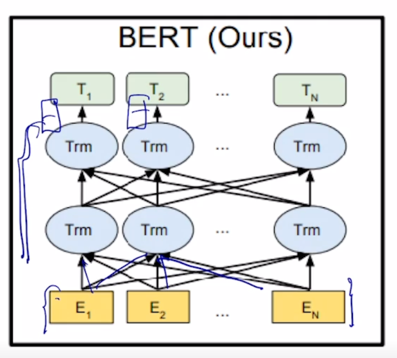
그림은 비록 달라보여도 주어진 text sequence 의 position embedding 을 더한 후 self-attention block 을 총 12개를 쌓은 그러한 형태의 모델
-
그 다음에 여기서 Text Prediction task 는 우리가 알고있는 첫 단어부터 그 다음 단어를 순차적으로 예측하는 Lanugage modeling task 를 수행하는 것임
-
seq2seq 즉, 입력과 출력 sequence 가 별도로 있는 것이 아니라 가령 영어데이터로 이루어진 수많은 웹페이지들을 다운받아서 그 데이터를 가지고 추출된 문장 그리고 그 문장에서 “I go home” 이라는 문장이 발견되었으면 이전 post 에서 봤던것과 비슷하게
에서 "I" 라는 단어, 그리고 "I" 까지 생성한 후의 입력을 받아서 그 다음 단어인 "go" 라는 단어를 생성하는 순차적으로 다음 단어를 예측하는 Language Modeling 이라는 task 를 통해 전체 12개의 self-attention block 으로 이루어진 GPT-1 모델이 학습됨 -
이와 동시에 GPT-1 은 simple 한 Language Modeling task 뿐만 아니라 문장 레벨 혹은 다수의 문장이 존재하는 경우에도 이 모델이 손쉽게 모델이 큰 변형이 없이 활용될 수 있도록 학습의 framework 을 제시했음

-
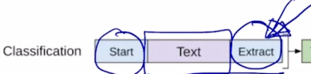
가령 sentiment analysis 혹은 classification 에 해당하는 일부 label 된 데이터가 있다고 할 때, 그 경우 GPT-1 이라는 모델을 multi-task learning 에 의해서 학습할 수 있는데 이 경우 문장레벨의 감정 분류라는 task 를 수행하기 위해 주어진 한 문장을 넣고 그 문장 앞에 START 토큰을 넣고 그 다음에 End of Sentence 에 해당하는 토큰을 Extract 라는 특별한 역할을 하는 토큰으로 바꾼 후
-
이런 sequence 를 쭉 encoding 을 한 후
-
최종적으로 나온 Extract 라는 토큰에 해당하는 encoding vector 를 최종 output layer 에 입력벡터로 줌으로써 이 문장이 긍정인지 부정인지를 분류하는 task 로 학습을 하게 됨

-
그래서 주어진 문장이 있을 때, Transformer 모델을 통해 word 별로 encoding 을 한 후 extract 토큰 만을 linear transformation 을 통해서 긍, 부정에 대한 output 을 예측하는 task 로 다음 단어를 예측하는 task 와 동시에 우리가 가지고 있는 일부 감정분석을 위한 label 된 데이터를 동시에 학습할 수 있음

-
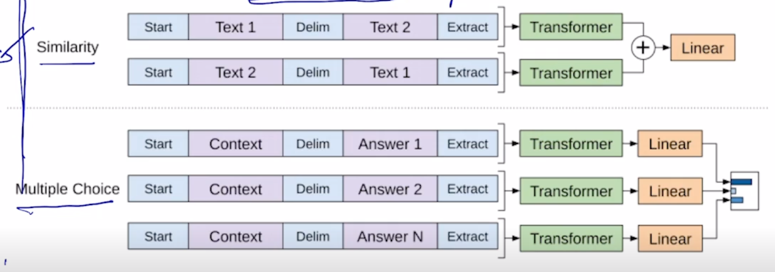
또 마찬가지로 가령 Entailment prediction task 예를 들어 “어제 존이 결혼했다” 라는 문장 그리고 “어제 최소한 한명은 결혼했다” 라는 문장이 주어지는 경우 첫번째 문장이 참이면 두번째 문장은 당연히 참이어야 하는 그런 논리적인 내포관계가 있는데 이러한 task 에서는 다수의 문장으로 이루어진 이런 입력을 받아서 예측을 수행해야 하고 이런 경우를 대비하기 위해 GPT-1 모델에서는 2개의 문장을 단순하게 하나의 sequence 로 만들되 Start 토큰을 넣고 문장 사이에는 또 다른 특수문자 혹은 특수 word 에 해당하는 delim 토큰을 추가하고 마지막에 Extract 토큰을 추가하고 그 다음엔 encoding 과정을 통해서 얻어진 word 별 encoding vector 에서 Extract 토큰에 해당하는 vector 를 최종적인 output layer 에 통과를 시켜주게되고 이것이 논리적으로 내포관계인지 논리적으로 모순관계인지에 대한 분류 task 를 수행하게 됨
-
이렇게되면 Extract 라는 토큰은 처음에는 문장의 마지막부분에 추가한 단어일 뿐이었지만 결국 문장을 잘 이해하고 문장이 긍정인지 부정인 혹은 이 두개의 문장간의 관계를 잘 이해해서 이 둘이 논리적으로 내포관계에 있는지 모순관계에 있는지를 예측하는 거기에 필요한 정보가 바로 self-attention 을 통한 encoding 과정 중에 Extract 토큰이 Query 로 사용되어서 이 task 에 필요로하는 여러 정보들을 주어진 입력 문장들로부터 적절하게 정보를 추출할 수 있어야 함
-
마찬가지로 여러 문장이 존재하는 다양한 task 들이 두 문장간의 유사도를 측정하는 문장 그리고 Multiple Choice 를 할 수 있는 다양한 task 들이 있음
-
이 다양한 사례들에 대한 예는 밑에서 더 설명하기로 하자.
-
그러면 다음 단어를 예측하는 task 와 더불어 일부 label 이 되어져 있는 소량의 특정 task 를 위한 데이터가 있는 경우, 이러한 데이터를 통합적으로 다 학습한 GPT-1 모델을 기타 제 3의 다른 task 에 transfer learning 의 형태로 활용할 때에는 다음과 같은 방식으로 동작하게 됨
-
이러한 방식의 학습과정을 거쳐서 나온 모델에서 가령 긍부정 예측을 하는 그러한 형태의 output 도 산출해내고 했다면 이번에는 모델을 통해서 주제분류를 한다거나 어떤 document 가 정치면인지, 경제면인지, 사회면에 실려야되는가에 대한 정보를 예측하기 위해서는 이 task 는 down-stream task 로서
-
기존의 긍부정 분류를하는 task 와는 다르기 때문에 output layer 로서의 원래 가지던 긍부정 예측을 위한 다음 단어를 위한 output layer 는 떼어내버리고
-
그 전단계에서 나오는 Transformer 에서 나오는 output 인 word 별 encoding vector 들을 사용해서 우리의 task 를 위한 추가적인 한 layer 를 붙이고 그 layer 는 random initialization 을 한 후 기 학습된 Transformer encoder 와 main task 를 위한 추가적인 layer 하나를 덧붙이고 그 다음엔 main task 인 문서에 대한 주제 분류를 하기 위한 학습 데이터를 통해 전체 network 를 학습하는 과정을 거치게 됨
-
그러면 여기서 마지막 layer(빨간색 원안의 별) 는 random initialization 을 통해 시작이 되기 때문에 학습이 충분히 되어야 하지만 이전에 있는 이미 기 학습된 layer 에는 learning rate 를 상대적으로 굉장히 작게 줌으로써 큰 변화가 일어나지 않도록 기존의 학습하던 task 를 통해서 배우던 지식들을 충분히 잘 담고 있으면서 그 정보를 우리가 원하는 task 에 활용할 수 있는 이런 형태로 Pre-training 및 main task 를 위한 fine-tuning 과정이 일어나게 됨
-
그러면 여기서 Pre-training 된 다양한 task 로 부터 우리가 유용한 지식을 얻을 수 있는 그 요소는 어디서 오는가에 대해 살펴보자.
- 여기서 필요로하는 Language Modeling 이라는 Pre-training 당시에 쓰이던 main task 는 별도의 label 이 필요로 하지 않는 데이터이기 때문에 굉장히 많은 양의 데이터를 통해서 이 simple 한 task 인 다음 단어 예측 하는 task 를 통해 이 모델을 학습할 수 있음
-
그렇지만 main task 인 문서분류의 task 의 경우는 그 해당하는 label 이 일일히 부여되어 있어야 하는 데이터여야 하고 그 데이터는 상대적으로 소량의 데이터만이 존재할 수 있기 때문에 앞서 Pre-training step 에서 대규모 데이터를 통해 별도의 label 이 필요하지 않는 그래서 self-supervised learning 이라고 부르는 framework 를 통해 대규모 데이터로부터 얻을 수 있는 지식을 소량의 데이터만 있는 target task 에 전이학습의 형태로 그 지식을 활용해서 성능을 올려줄 수 있는 그런 양상으로 Pre-training 및 transfer learning 이 일어남
-
Experimental Results
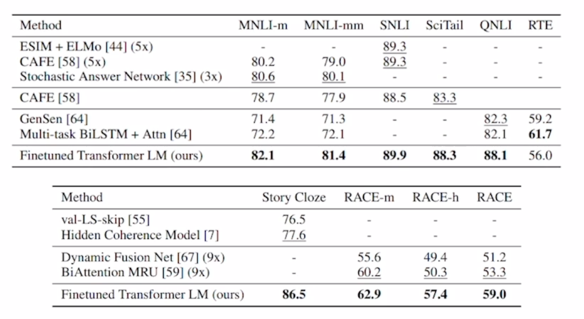
- 이러한 방식으로 Pre-training 된 GPT-1 모델을 다양한 task 에 fine-tuning 해봤을 때 기존의 각 task 별로 존재하던 task 만을 위해 customize 된 모델과 그 모델을 task 만을 위해 label 된 상대적으로 소량의 데이터 만으로 학습한 그 경우의 정확도보다 일반적으로 더 높은 성능을 내주는 것을 알 수 있음
BERT
- 다음으로는 앞서 말한 사전학습 모델의 두번째 모델로서 BERT 라는 모델을 살펴보자.
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- Learn through masked language modeling task
-
Use large-scale data and large-scale model
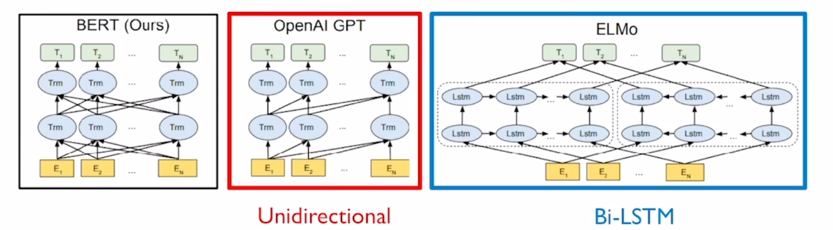
- BERT 모델은 현재까지도 가장 널리 쓰이는 Pre-training 모델이 되고 기본적으로 BERT 도 GPT-1 과 마찬가지로 Language Modeling 이라는 task 로서 문장에 있는 일부 단어를 맞추도록 하는 task 로서 Pre-training 을 수행한 모델이 됨
- 그렇지만 이러한 Pre-training task 즉, 다음 단어를 예측하는 등의 이런 simple 한 self-supervised learning 을 Transformer 모델 이전에 LSTM 기반의 Encoder 로 Pre-training 한 접근법도 존재했음
- 그러한 method 는 ELMo 라는 method 였음
- 그래서 Transformer 모델로 LSTM 인코더를 다 대체를 한 그러한 모델들이 비슷한 단어를 맞추는 Pre-training taks 에서도 훨씬 더 많은 양의 지식을 배울 수 있는 형태로 모델이 점점 더 고도화되는 형태가 됨
Masked Language Model
-
그러면 이 BERT 에서의 기본적인 Motivation 을 살펴보자.
- Motivation
- Language models only use left context or right context, but language understand bi-directional
- If we use bi-directional language model?
- Problem: Words can “see themselves” (cheating) in a bi-directional encoder

- 그전에 GPT-1 같은 경우 standard 한 Language model 즉,
I study math 라고 하는 경우 라는 정보만을 주고 I 라는 단어를 맞추고 그 다음에 I 까지를 보고 study 를 맞추고 이러한 과정으로 Pre-training 을 진행했는데 이 경우는 전후 문맥을 보지 못하고 앞쪽에 있는 문맥만을 보고 다음 단어를 예측해야 한다는 한계점이 존재 -
그렇지만 가령 전화를 하다가도 중간에 끊겨서 잘 안들리는 경우에는 앞쪽 뿐만 아니라 뒤쪽의 문맥까지도 같이 고려해서 못들은 부분이 무엇이었을지 감을 잡을 수 있게되고 또한 독해문제에서 모르는 단어를 만났을 때에도 역시 앞쪽 뿐만 아니라 뒤쪽의 문맥을 전체으로 보고 그 단어가 어떤 뜻인가를 유추할 수 있게 됨

- 그래서 한쪽의 정보만으로 예측하는게 아니라 왼쪽 뿐만 아니라 오른쪽에 해당하는 정보를 다 보고 예측했을 때 좀 더 유의미한 예측과정 및 그리고 거기서 배울 수 있는 지식들이 더 많은 그런 형태가 이어질 수 있음
Pre-training Tasks in BERT
-
이런 motivation 에서 나온 것이 Masked Language Modeling 이라고 하는 BERT 에서의 Pre-training task 가 됨
- Masked Language Model (MNM)
- Mask some percentage of the input tokens at random, and then predict those masked tokens
- 15% of the words to predit
- 80% of the time, replace with [MASK]
- 10% of the time, replace with a random word
- 10% of the time, keep the sentence as same
- Next Sentence Prediction (NSP)
-
Predict whether Sentence B is an actual sentence that proceeds Sentence A, or a random sentence


-
-
이 경우에는 “I study math” 라는 문장이 주어졌을 때, 각각의 세 단어의 대해 일정한 확률로 각 단어를 [MASK] 라는 단어로 치환하고 그 단어가 무엇인지를 맞추도록 하는 그런 형태로 이 모델의 학습이 진행됨
- 그러면 여기서 과연 몇 %의 단어를 [MASK] 단어로 치환해서 그 단어를 맞추도록 할지에 대한 사전에 잘 결정해주어야 하는 하이퍼파라미터에 해당됨
- 여기서 15% 에 해당하는 정도의 단어를 비율로 해서 [MASK] 로 치환을 하게 됨
Pre-training Tasks in BERT: Masked Language Model
- How to
- Mask out $k$% of the input words, and then predict the masked words
-
e.g., use $k$ = 15%

-
- Mask out $k$% of the input words, and then predict the masked words
- Too little masking: Too expensive to train
-
Too much masking: Not enough to capture context
- 그 경우, [MASK] 로 치환하는 비율을 15% 보다 더 높이게 되면 그러면 주어진 문장에서 너무 많은 부분을 [MASK] 로 처리한 경우에는 그 해당하는 [MASK] 각각의 자리에 단어를 맞추기에 충분한 정보가 제공되지 않는 그런 문제가 생김
-
그와 동시에 비율을 상대적으로 작게하는 경우에는 가령 100 단어 중에서 한 단어만을 [MASK] 로 처리해서 맞추도록 학습을 진행하면 이 100 단어를 읽어들여서 Transformer 모델이 전체 정보를 다 encoding 하는 과정이 시간적으로 그리고 학습의 과정에서도 많은 계산을 필요로 하는데 그 경우에 단 한문제만 출제해서 task 를 수행하게 되면 학습이 전체적으로 효율이 떨어진다거나 학습속도가 충분히 빠르지 않은 형태가 나타날 수 있음
- Problem
- Mask token never seen during fine-tuning
- Solution
- 15% of the words to predict, but don’t replace with [MASK] 100% of the time. Instead:
- 80% of the time, replace with [MASK]
- went to the store $\rightarrow$ went to the [MASK]
- 10% of the time, replace with a random word
- went to the store $\rightarrow$ went to the running
- 10% of the time, keep the same sentence
- went to the store $\rightarrow$ went to the store
- 80% of the time, replace with [MASK]
- 15% of the words to predict, but don’t replace with [MASK] 100% of the time. Instead:
- 그러면 BERT 에서 찾은 적절한 비율은 15% 정도 만으로 [MASK] 로 단어를 치환하고 그 단어를 맞추도록 하는 그러한 값을 도출했음
- 그렇지만 15%의 단어를 맞추도록 했을 때, 해당 단어들을 100% 다 [MASK] 로 치환하는 경우는 여러가지 부작용이 생길 수 있음
- 첫번째 부작용은 Pre-training 당시에는 주어진 문장에서 평균적으로 15%의 단어가 [MASK] 라는 단어로 치환이 되어있는 이런 상황에 익숙해진 모델이 나올 것인데 이 모델을 가령 문서의 주제 분류 task 를 수행한다거나 다른 down-stream task 를 수행할 때는 [MASK] 라는 토큰은 더이상 존재하지 않게 됨
- 그러면 이러한 경우 Pre-training 당시에 주어지는 입력벡터의 양상이나 패턴이 실제 down-stream main task 를 수행할 때에 주어지는 입력문장과는 다른 특성을 보일수가 있고 그래서 이런 상이한 차이점이 학습을 방해하거나 Transfer learning 의 효과를 최대한 올리는데에 문제가 될 수 있음
- 그래서 여기서는 [MASK]로 치환하기로 한 15%의 단어들을 그 내에서도 서로 다른 형태로 단어들을 변경하게 됨
- 가령 100개의 단어 중 15개 단어가 맞추어야 하는 원래는 [MASK]로 치환되어야 하는 단어라고 하면 이중에 대략 80% 즉, 15개 중에 12개 정도만 실제 [MASK] 라는 특수한 토큰으로 치환한 후 그 해당 단어를 맞추도록 하고 그 다음엔 약 10% 대략 1.5개의 단어는 random 한 word 로 바꾸게 됨
- 그러면 이 경우는 그 해당하는 단어를 맞추어야 할 때, 가령 “I love this movie” 를 “I him this movie” 그래서 중간에 들어간 him 이라는 단어가 전혀 동사와는 부합하지 않는 그래서 문법적으로 잘못된 형태로 random 한 word 로 바뀌었을때도 그 해당 단어가 [MASK] 가 아닌 regular 한 단어라 하더라도 그 단어를 원래 써야 하는 단어로 잘 복원해 줄 수 있도록 하는 이러한 형태로 문제의 난이도를 좀 더 높여준 것으로 생각할 수 있음
- 그다음엔 추가적으로 나머지 1.5개의 단어는 그 단어를 전혀 바꾸지 않고 원래 단어로 그대로 둔 채 그러면 그 단어가 혹시 다른 단어로 바뀌어야 하는지 그 해당 단어에 대한 토큰을 가지고 encoding vector 를 output layer 를 통해 예측을 했을 때, 이 경우는 원래 있었던 단어와 동일해야 한다고 소신있게 예측을 할 수 있는 이러한 형태의 학습도 세팅에서 유도했음
Pre-training Tasks in BERT: Next Sentence Prediction
-
To learn the relationships among sentences, predict whether Sentence B is an actual sentence that proceeds Sentence A, or a random sentence

- BERT 에서 쓰인 Pre-training 기법은 방금 설명한 Masked-Language Model 을 통한 word 별로 원래 있어야 하는 단어를 예측하는 task 이외에 GPT 에서도 있었던 문장 레벨의 task 에 대응하기 위한 그러한 Pre-training 기법도 제안했음
-
그 기법은 Next Sentence Prediction 이라는 기법임

-
예를 들어서 default 로 BERT 모델을 학습할 때, 주어진 하나의 글에서 2개의 문장을 뽑고 그 문장을 연속적으로 이어주고
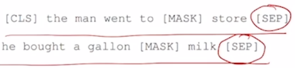
-
그 문장 사이에는 [SEP] 토큰 혹은 문장이 끝날때에도 [SEP] 토큰을 추가해서 이 문장이 끝났다는 것을 알려줌

-
그리고 동시에 이 문장 혹은 다수의 문장 레벨에서의 예측 task 를 수행하는 그 역할을 담당하는 토큰으로서 [CLS] 토큰 혹은 Classification 토큰을 문장의 앞에 추가함
- 이는 GPT 에서 Extract 토큰이 가장 다수의 문장에 마지막에 등장하고 그 Extract 토큰을 통해서 문장이나 다수 문장 레벨의 예측 task 를 수행할 수 있도록 한 그 토큰에 해당
- 그래서 이 BERT 에서는 해당 토큰을 [CLS] 토큰 이라고 부르고 그것을 문장의 앞에 넣어준다는 사실이 특징이 됨
-
그리고 여기서는 별도의 문장 레벨에서의 label 이 필요한 task 가 아닌 여전히 입력데이터 만으로 무언가 예측을 수행할 수 있는 그런 task 를 학습시키기 위해 연속적으로 주어진 2개의 문장이 과연 인접한 그래서 연속적으로 이 순서대로 나와야 하는 문장인지 혹은 이 두 문장은 전혀 연속적인 문장으로서 나올 수 없는 그런 문장인지를 예측하는 Next Sentence 인지 아닌지에 대한 Binary Classification 을 수행하는 task 를 추가했음
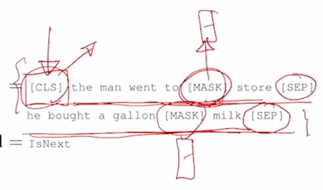
-
이 경우, 주어진 글에서 default 로 이 2개의 문장을 뽑고 아까 말했던 [MASK] 단어로의 치환을 해서 [CLS] 토큰 까지를 맨 앞에 포함해서 전체 sequence 를 Transformer 를 통해 encoding 을 하고 그러면 [MASK] 에 해당하는 자리의 토큰에서는 그 해당하는 encoding vector 를 가지고 [MASK] 자리에 있어야 하는 단어 예측을 수행하게 됨
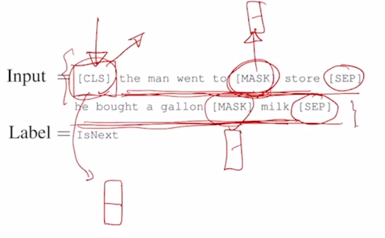
-
그리고 [CLS] 토큰은 여기에 해당하는 encoding vector 를 가지고 output layer 하나를 둬서 Binary Classification 을 수행하도록 하고 그 Binary Classification 에서의 ground-truth 는 실제로 이 두 문장이 정말로 인접한 문장인지 아닌지를 예측하는 task 로 만들었음
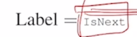
-
그러면 어떤 하나의 글에서 두 문장을 연속된 문장에서 뽑았으면 그 경우는 이 task 에서의 ground-truth 는 당연히 IsNext 라는 다음 문장이 맞다라는게 됨

- 의도적으로 두 문장을 완전히 다른 2개의 글에서 뽑아서 그 2개의 문장을 연속되게 이어두면 이 경우는 이 두 문장은 원래 같이 인접하게 있던 문장이 아니기 때문에 여기서는 Next Sentence 가 아니라는 NotNext 라는 label 을 통해서 학습을 진행하고 학습의 backpropagation 을 통해서 [CLS] 토큰을 통해 이 전체 네트워크가 학습이 진행됨
BERT Summary
- Model Architecture
- BERT BASE: L = 12, H = 768, A = 12
- BERT LARGE: L = 24, H = 1024, A = 16
- Input Representation
- WordPiece embeddings (30,000 WordPiece)
- Learned positional embedding
- [CLS] - Classification embedding
- Packed sentence embedding [SEP]
- Segment Embedding
- Pre-trianing Tasks
- Masked LM
- Next Sentence Prediction
- BERT 에 대한 좀 더 자세한 내용을 알아보면 모델 구조 자체는 Trnasformer 에서 제안된 self-attention block 을 그대로 사용했고 그것을 두가지 버전으로 학습된 모델을 제안함
- 첫번째는 BERT BASE 로서 self-attention block 을 총 12개 BERT LARGE 는 총 24개의 self-attention block 을 쌓았고 그 다음에 여기서 보이는 A 는 각 layer 별로 정의되는 attention head 의 숫자임
- 이 경우는 각 self-attention block 에서 더 많은 수의 attention block 을 혹은 head 를 사용한다는 것을 알 수 있음
- 그 다음에 H 라는 것은 각 self-attention block 에서 항상 똑같게 유지를 하는 encoding vector 의 차원 수가 됨
- BERT BASE 에서는 상대적으로 BERT LARGE 보다 전반적으로 더 경량화된 모델 형태로 볼 수 있음
- 추가적으로 BERT 에서는 입력 sequence 를 넣어줄 때 word 별로의 embedding vector 를 사용하는 것이 아니라 그 word 를 좀 더 잘게 쪼개서 각각의 sequence 의 단위를 sub-word 라 불리는 단위로 먼저 embedding 을 하고 그것을 입력 벡터로 넣어주는 방식을 취함
- 그래서 sub-word 를 어떤식으로 encoding 하고 그 해당하는 사전을 구축하는가는 이 강의에서는 다루지 않겠지만 직관적으로 설명하자면 pre-training 이라는 단어도 ‘-‘ 이 없었을 때(pretraining) 조차 하나의 단어로 주어지게 되는 경우 이 경우 명확하게 해당하는 의미가 pre 라는 의미와 training 이라는 두개의 명확하게 구분되는 두개의 의미를 가지는 단어와 합성화된 word 로 생각할 수 있음
- 그래서 이 경우는 비록 단어 하나라도 2개로 나눠서 의미 단위로 생각하는 것이 좋을 수 있음
-
그래서 그러한 요소를 반영한 것이 진보된 형태의 WordEmbedding 인 sub-word 레벨을 단위로 삼을 수 있는 WordPiece embedding 이라는 것이 쓰임
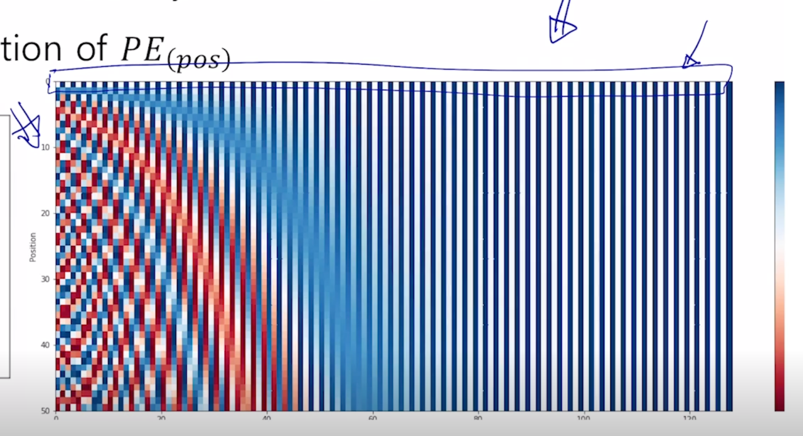
- 앞서 보여줬던 Transformer 에서 제안된 사전에 미리 특정한 방식을 통해 정의된 $sin$, $cos$ 그리고 특정 주기들도 사전에 다 결정된 값을 써서 거기서 추출된 첫번째, 두번째 position 에 해당하는 embedding vector 를 사용했다면
- Learned positional embedding 은 이 matrix 조차 word2vec 에서 embedding matrix 를 학습하듯이 이 부분도 random initalization 에 의해서 전체적인 학습과정을 통해 end-to-end 로 첫번째 position 그리고 두번째 position 에 더해주어야 하는 embedding vector 도 학습에 의해서 최적화된 값으로 도출할 수 있음
- 그래서 BERT 에서는 positional embedding 자체도 학습에 의해서 결정되도록 했음
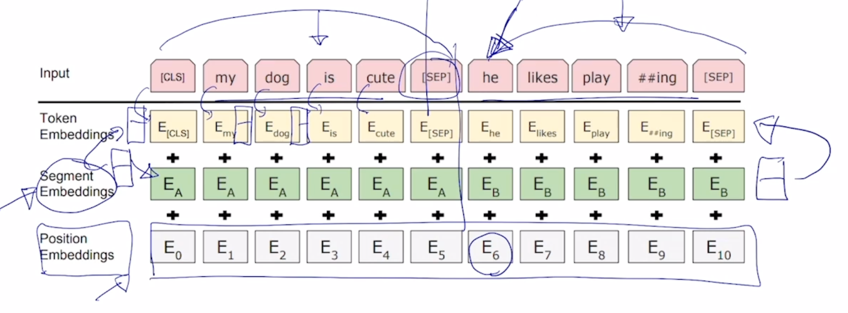
- [CLS] 토큰 그리고 문장 끝에 한번씩 나오는 [SEP] 토큰들이 추가 된 것을 알 수 있음
- 그 다음에 하나더 Segment Embedding 이라는 것이 있음
-
Segment Embedding 은 BERT 를 학습할 때 일반적으로 단어별 Masked 된 단어를 예측하는 task 와 주어진 두 문장으로 이루어진 한 sequence 가 그게 실제 인접문장인지 아닌지를 예측하는 문장 레벨에서의 task 가 있음

-
두개의 문장을 연속으로 [SEP] 토큰으로 구별해서 넣는 경우
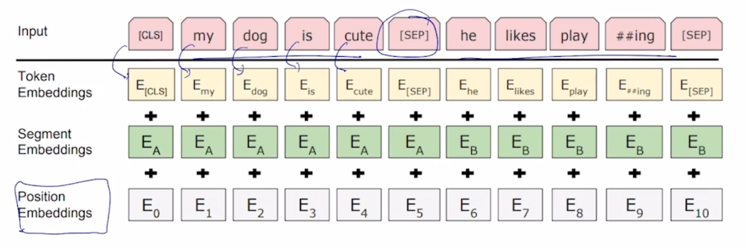
-
각각에 해당하는 word embedding vector 에 postional embedding 이 추가적으로 더해질텐데
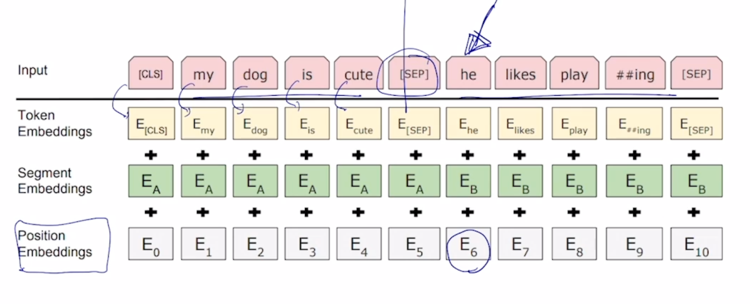
-
그렇지만 이 경우, 가령 he 라는 단어의 경우는 전체 sequence 에서 6번째 position 에 위치한 단어는 맞지만 문장을 하나의 독립된 정보를 나타내는 단위로 본다면 이 경우는 첫번째 단어로서 보되 두번째 문장에 속하는 그런 문장이다라는 정보를 분리해서 넣어줘야 할 필요성도 생기게 됨

-
그렇게 되면 그러한 요소를 보완하기 위해서 positional embedding 은 순차적으로 반영하되

- 여기에 또 다른 종류의 positional embedding 으로서 setment embedding 을 넣게 됨
-
이는 첫번째 문장과 두번째 문장 이 문장 레벨에서의 어떤 position 혹은 index 를 반영한 그런 형태의 vector 가 됨

-
embedding vector 가 2차원이라고 하면 postional embedding vector 도 역시 2차원일텐데 이 벡터를 더해주는 것 뿐만 아니라
-
첫번째 문장에서는 첫번째 segment 혹은 첫번째 문장이다라는 것을 나타낼 수 있는 또 다른 2 dimensional embedding vector 를 역시 또 더해 주고 그 벡터는 첫번째 문장에서는 모든 word 들에 대해서 동일한 vector 를 더해주게 되고 두번째 문장에서는 두번째 segment 를 나타내는 벡터를 또 학습에 의해서 최적화를 해서 그 벡터를 embedding vector 에 더해주는 형태로 동작하게 됨
-
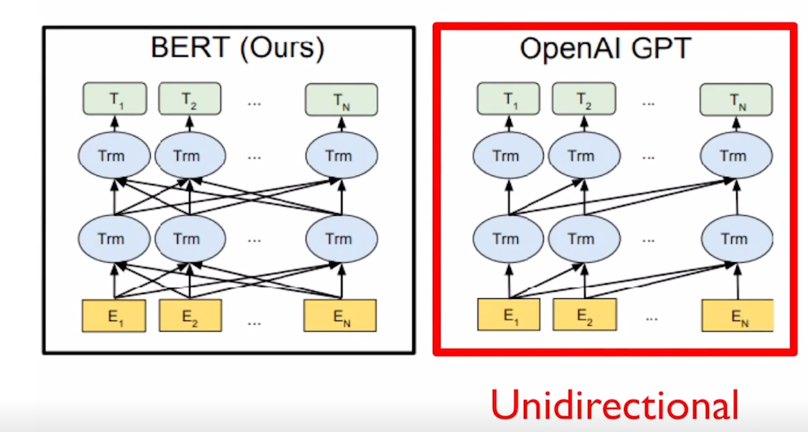
그러면 아까 봤던 High-Level 의 도식화된 그림에서 BERT 와 GPT-2 간의 차이점을 좀 더 살펴보도록 하자.
-
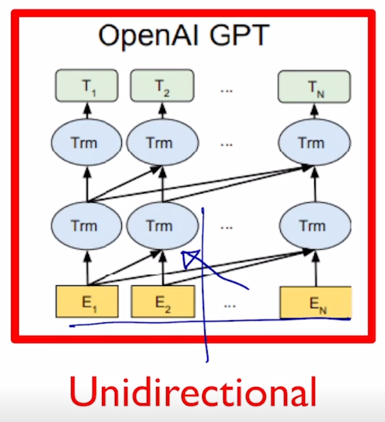
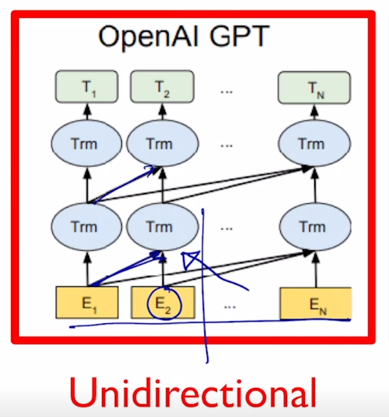
GPT-2 의 경우 주어진 sequence 를 encoding 할 때에 바로 다음 단어를 예측해야하는 task 를 수행해야 하기 때문에 특정한 timestep 에서 다음에 나타난 단어를 접근을 허용하면 안됨
-
마치 그 Transformer 에서 decoder 에서의 self-attention 이 masked 형태의 self-attention 으로 사용된 것처 그래서 여기 보이는 것처럼 각각의 특정한 timestep 에서는 항상 자기 자신을 포함해서 그 왼쪽에 있는 정보를 access 하고 있는 그런 패턴을 보여주고 있음
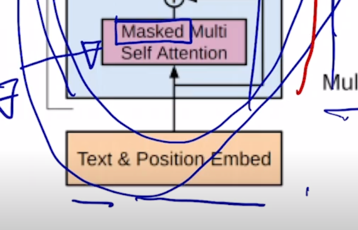
-
그래서 GPT 모델 같은 경우 기본적으로 쓰이는 sequence 인코딩을 하기 위한 attention block 은 Transformer 에서 decoder 부분에서 사용되던 Masked self-attention 을 사용하게 됨
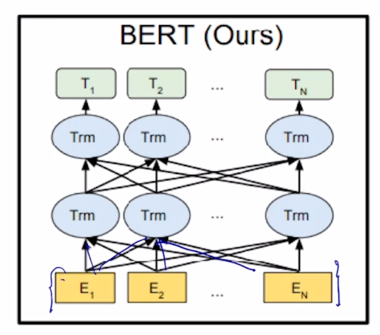
- 그렇지만 BERT 같은 경우 [MASK] 로 치환된 토큰들을 주로 예측하게 되고 그래서 [MASK] 단어를 포함하여 전체 주어진 모든 단어들에 접근이 가능하도록 허용함으로써 attention 패턴은 모두가 모두를 볼 수 있도록 하는 그래서 Transformer 에서 encoder 에서 사용되던 self-attention 모듈을 사용하게 됨
BERT: Fine-tuning Process
-
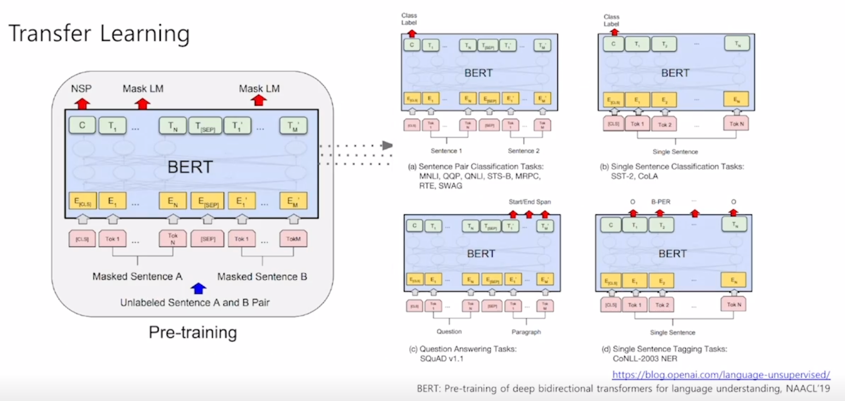
다음으로는 이렇게 Masked Language Modeling 과 Next Sentence Prediction 이라는 task 둘을 Pre-training 에 task 로 사용해서 사전학습한 이 모델을 여러가지 다양한 down-stream task 에 fine-tuning 하는 형태의 어떤 모델 구조를 살펴보도록 하자.
-
Transfer Learning
-
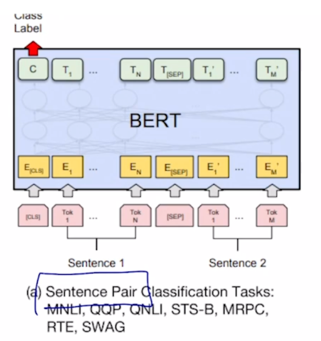
어떤 Sentence pair 에 대해서 Classification 을 하는 논리적으로 내포관계 혹은 모순관계를 예측하는 등의 task 에서는
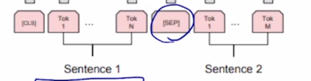
-
이 2개의 문장을 쭉 하나의 sequence 로 그렇지만 [SEP] 토큰으로 구별을 지은 후
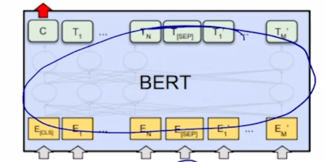
-
BERT 를 통해 encoding 을 하고나서
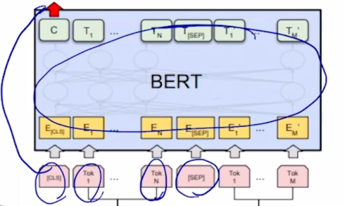
-
각각의 word 들에 대한 encoding vector 를 얻었다면 [CLS] 토큰에 해당하는 encoding vector 를 output layer 의 입력으로 주어서 다수 문장의 대한 예측 task 를 수행할 수 있음
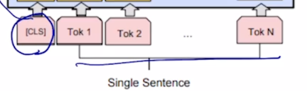
-
단일 문장에 대한 예측 task 는 입력으로 주는 문장이 한번에 하나씩 밖에 없기 때문에 문장을 하나만 주고 첫번째 [CLS] 토큰을 주고
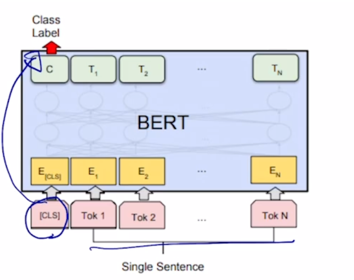
-
이 [CLS] 토큰의 encoding output 을 최종 output layer 에 넣어주어서 classification 을 수행
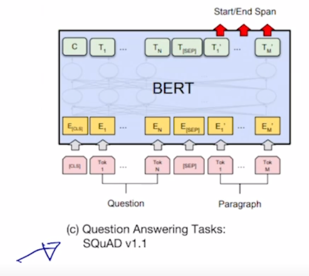
-
그리고 좀 더 복잡한 task 인 Question & Answering 같은 경우 뒤에서 좀 더 자세히 설명하기로 하자
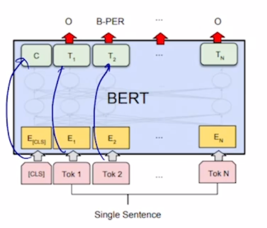
-
그 다음엔 주어진 문장에서 각각의 단어별로 classification 해줘야 하는 task 가령 POS 태깅처럼 문장에서 각 단어의 문장 성분이나 품사가 무엇인지를 예측해야하는 경우 각각의 [CLS] 토큰을 포함해서 첫번째 두번째 단어에 대한 encoding vector 가 얻어지면 그 vector 를 동일한 공통의 output layer 를 통과해서 최종 각 word 별 classification 이나 prediction 을 수행하게 됨
BERT vs GPT-1
-
지금까지 배운 GPT-1 과 BERT 간의 세부적인 차이점들을 살펴보자.
- Comparison of BERT and GPT-1
- Training-data size
- GPT is trained on BookCorpus(800M words) ; BERT is trained on the BookCorpus and Wikipedia (2,500M words)
- Training special tokens during training
- BERT learns [SEP], [CLS], and sentence A/B embedding during pre-training
- Batch size
- BERT = 128,000 words ; GPT - 32,000 words
- Task-specific fine-tuning
- GPT uses the same learning rate of 5e-5 for all fine-tuning experiments; BERT chooses a taks-specific fine-tuning learning rate
- Training-data size
- training data size 의 측면에서는 GPT 는 대략 800M 개수의 토큰을 가지는 학습데이터를 사용해서 학습했고 BERT 는 대략 3배정도의 2,500M 개의 달하는 토큰수로 이루어진 데이터베이스로 학습을 진행함
- 그래서 상대적으로 훨씬 더 많은 양의 데이터로 학습을 진행 함
- 그리고 BERT 에서는 GPT-1 과는 달리 Extract 토큰 대신 사용되는 [CLS] 토큰 그리고 문장 간의 분류하는 [SEP] 토큰과 이와 더불어 여러문장이 주어졌을 때 각 문장별로 인덱스를 나타낼 수 있는 segment embedding 혹은 sentence A 냐 B 냐에 대한 각기 다른 embedding 을 입력단에서 더해줌으로써 두 문장을 좀 더 잘 구분할 수 있도록 함
- 그리고 하이퍼파라미터로서 학습 당시에 BERT 와 GPT 간의 한번에 학습하는 배치사이즈로서 word 수를 서로 다르게 쓴 것을 알 수 있음
- 한번 학습 당시에 BERT 가 훨씬 더 많은 word 들을 load 해와서 그 word 들에 대한 Masked Language Modeling 과 Next Sentence Prediction 을 수행을 하게 됨
- 실제로 이 배치사이즈라는 하이퍼파리미터는 일반적으로 더 큰 사이즈의 배치를 사용하게되면 최종 모델 성능이 더 좋아지고 학습도 더 안정화가 되는 그런 현상을 보여줌
- 이는 gradient descent 라는 알고리즘을 수행할 때 일부의 데이터 만으로 도출된 gradient 로 직접적인 파라미터를 매번 업데이트 할지 아니면 보다 더 다수의 더 많은 양의 데이터를 바탕으로 종합적으로 나온 평균 gradient 를 바탕으로 한번 한번의 파라미터의 업데이트 혹은 최적화를 수행할지에 따라 더 많은 숫자의 데이터를 사용해서 한번 단위의 업데이트를 수행할 때가 학습이 더 안정적이고 성능이 좋다는 그런 사실이 알려져 있음
- 그렇지만 배치사이즈를 키우기 위해서는 한번에 load 해와야 하는 입력데이터 뿐만 아니라 Forward propagation 과 Back propagation 상에서 필요로하는 memory 도 이에 비례해서 증가하기 때문에 더 많은 GPU memory 그리고 그에 따른 더 고성능의 GPU 가 필요로 하게 됨
- 그리고 좀 더 세부적인 요소로서 GPU 같은 경우 fine-tuning 당시의 learning rate 을 여러 자연어처리의 donwstream 에서 동일한 값을 썼지만 BERT 는 각 task 별로 learning rate 도 각기 optimize 를 수행해야 한다라는 그런 사실에 입각해서 서로 다른 learning rate 를 사용함
BERT: GLUE Benchmark Results
-
GLEU Benchmark Results
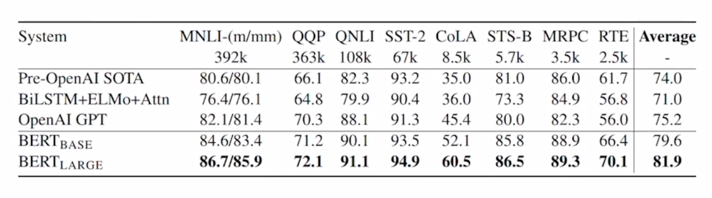
-
BERT 논문에서도 GPT 와 마찬가지로 다양한 down-stream task 에 대한 성능들을 보여줌
-
기본적으로 BERT 를 down-stream 에 사용하는 방식은 GPT 와 비슷하게 최종적인 Transformer 모델에서 나오는 encoding output vector 들을 얻고난 후에 그 이후 각 [MASK] 된 토큰에 대한 prediction 을 수행하는 output layer 가 있었을 것인데 그 layer 를 제거하고 main task 를 위한 output layer 를 추가적으로 접붙이기를 하듯이 모델을 구성해서 가장 윗 layer 는 random initialization 으로 부터 main down-stream task 를 위한 데이터를 통해 학습하고 아래쪽에 기학습된 Transforemr encoder 의 파라미터들은 상대적으로 더 작은 learning rate 을 사용해서 조금만 변화하도록 그래서 일반화가능한 지식이 최대한 많이 유지될 수 있도록 하는 형태로 학습이 진행됨
- 그렇게 BERT 를 다양한 자연어처리 task 에 fine-tuning 형태로 적용했을 때 기존의 여러 알고리즘에 비해 일반적으로 더 좋은 성능을 내는 것을 알 수 있음
- 그리고 참고로 여러 task 들을 한데 다 모아놓은 그런 데이터셋 혹은 Benchmark 셋이 있는데 그 데이터를 GLUE 데이터라고 부름
- 이 GLUE 데이터에 대한 공식적인 웹사이트라던지 공개되어서 사용할 수 있는 각각 task 에 해당하는 다양한 데이터셋들이 존재함
Machine Reading Comprehension (MRC), Question Answering

-
BERT 를 통해 더 높은 성능을 fine-tuning 을 통해 얻을 수 있는 대표적인 task 로서 Machine Reading Comprehension task 라는 것을 살펴보자.
- 이는 기본적으로 질의응답에 한 형태임
-
그렇지만 질문만 주어지고 그 질문에 대한 답을 예측하는 task 가 아니라 기계독해에 기반한 즉, 주어진 지문이 있을 때 지문을 잘 이해하고 그래서 질문에서 필요로 하는 정보를 잘 추출해서 해당 정답을 예측해내는 task 를 기계독해 기반의 질의응답이라고 부름
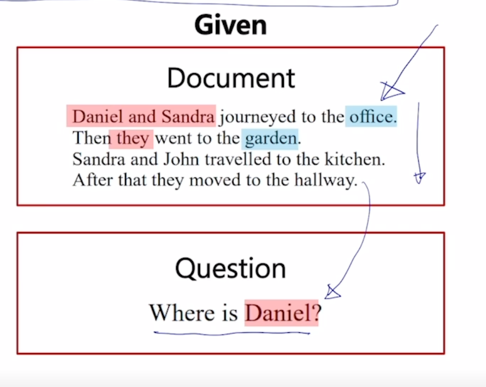
- 이 경우, 간단한 예이기는 하지만 Daniel 이 현재 어디있는가? 에 대한 질문에 대해 문장을 쭉 읽었을 때 Daniel 과 Sandra 가 지금 office 에 갔는데 여기서 they 는 우리가 원하는 Daniel 을 포함하고 있음
-
그러면 they 가 office 에서 garden 으로 갔고 지금 현재 Daniel 은 garden 에 있는데 그 다음에는 등장인물이 Sandra 와 John 이 등장함

- 그리고 이 둘은 kitchen 으로 갔고 그 다음엔 they 그들이 hallway 로 갔다는 story 에서 앞에서의 they 는 Daniel 을 포함하고 있고 뒤에서의 they 는 Daniel 을 포함하고 있지 않기 때문에 이 글에서 나타나는 총 4개의 장소 중 최종적인 Daniel 이 있는 곳이 정답은 바로 garden 이 됨
- 이러한 task 가 기계 독해 기반의 질의 응답 task 이고 이 task 는 이런 간단한 예제에서 더 나아가서 실제로 좀 더 어려울 수 있고 유의미한 수준의 공개된 데이터셋이 존재하고 그 데이터셋의 대표적인 예가 SQuAD 데이터가 있음
BERT: SQuAD 1.1
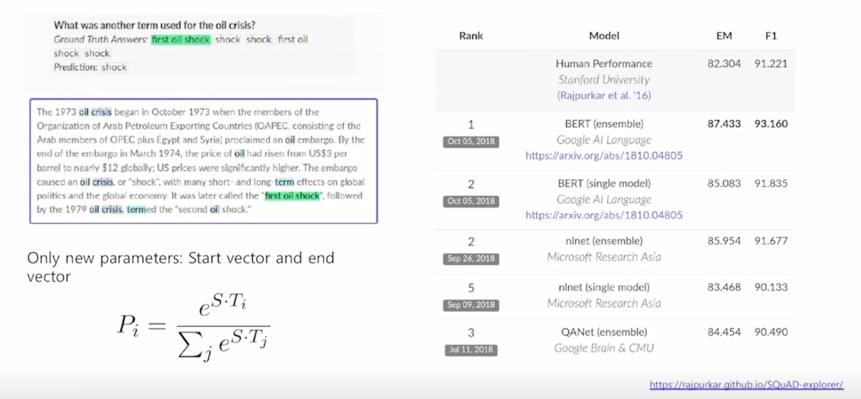
-
이 SQuAD Data 는 실제로 크라우드소싱을 통해 많은 사람들로부터의 task 를 수행토록 해서 수집된 그렇게 구축된 데이터에 해당이 됨

-
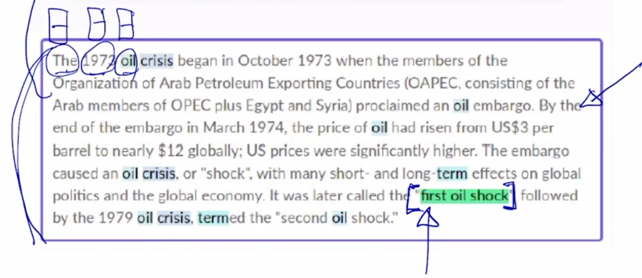
지금 이 예시에서 보면 이 document 를 wikipeida 에서 random 하게 뽑은 한 document 로 추출하고 각각의 crowd worker 들에게 이 지문을 읽고 그 해당하는 독해를 통한 풀 수 있는 문제를 그 해당문제와 그 해당하는 답까지 문제 출제를 하도록 한 그렇게 구축된 데이터셋임
-
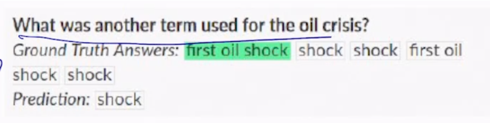
이 질문에 대해서 출제자가 지정한 정답은 바로
first il shock가 됨
-
출제자가 여러명인 경우 정답은 조금씩 다를 수 있지만

-
기본적으로는 특정한 정답에 해당하는 지문상의 문구가 존재하는 이런 형태로 task 를 위한 데이터가 꾸며져 있음
-
이러한 데이터는 실제로 SQuAD 데이터라고 불리고 full name 은 Stanford 에서 만드어졌기 때문에 Stanford Question & Answering Dataset
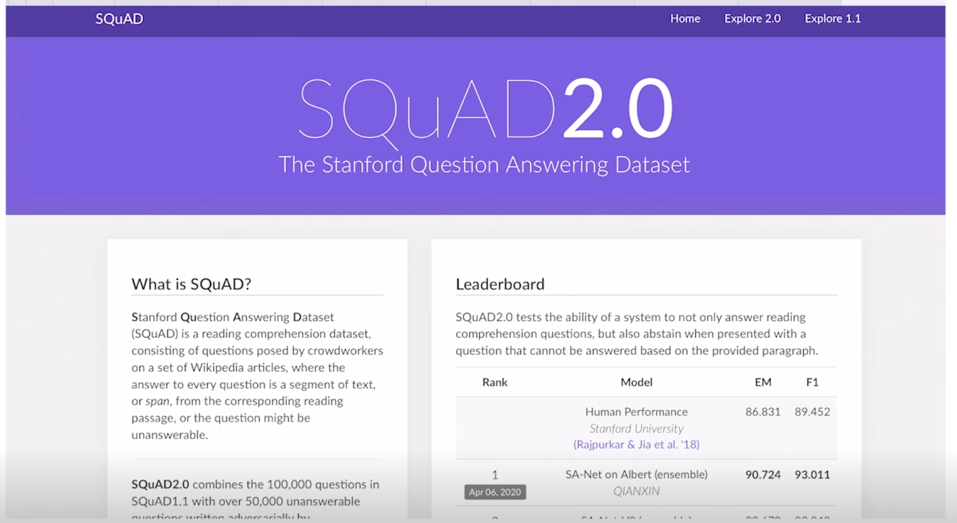
-
실제로 1.1 버전과 2.0 버전이 있는데 해당 웹사이트를 가보면 SQuAD 데이터에 대한 공식적인 웹사이트임
- 현재 SQuAD 2.0 에 대한 Leaderboard 가 있고 아래쪽에 쭉 가보면 그 전버전의 데이터셋인 SQuAD 1.1 버전에 해당하는 데이터셋이 존재하고 그에 해당하는 Leaderboard 가 존재
- 여기서 순위권을 다투고 있는 다양한 모델들에서 BERT 라고 하는 단어들을 굉장히 많이 볼 수 있음
-
이런 양상은 가장 위에서 위치하던 SQuAD 2.0 버전에서도 ALBERT 라고 하는 모델들 그리고 또 뒤에서 간단하게 배울 ELECTRA 라는 모델들도 순위권에 위치하고 있고 ELECTRA, ALBERT 이러한 형태의 모델 그리고 ROBERTA 라는 모델도 있고 BERT 를 조금씩 변형해서 성능을 개선한 다양한 모델들이 이 task 에서의 순위권으로 차지하고 있는 것을 알 수 있음
-
그러면 기계독해 기반의 Question & Answering 을 BERT 라는 모델을 통해 푸는 그런 모델을 간단히 설명해보자.

-
기본적으로 BERT 의 입력으로서 주어진 지문과

- 답을 필요로하는 질문을 2개의 서로 다른 문장처럼 [SEP] 토큰을 통해 concat 을 해서 하나의 sequence 로 만들어서 BERT 를 통해 encoding 을 진행함
-
그러면 각각의 지문상에서의 단어별로의 word encoding vector 가 나올 것이고 그러면 그 vector 들에서 정답에 해당할 법한 위치

-
즉, 그 위치는 지문상에서의 특정한 문구로 보통 정답이 주어지는데 그 문구의 위치를 기본적으로 예측하도록 이 모델을 수행하게 됨
-
그래서 구체적으로는 지문에서 답에해당하는 문구가 시작하는 위치를 예측하기 위해 각 word 별로 최종 encoding vector 가 output 으로 나왔을 때 이를 공통된 output layer 를 통해서 scalar 값을 뽑도록 하는 그런 output layer 를 통한 결과값을 얻게 됨

-
그러면 가령 각각의 word 가 2차원 벡터로 최종 encoding 벡터가 나온 경우

-
여기의 각 word 에 적용해야 하는 output layer 는 단순히 이런 2차원 벡터를 단일한 차원의 혹은 scalar 값으로 변경해주는 Fully connected layer 가 됨
- 그러면 이 Fully connected layer 의 파라미터가 random initlaization 에서 부터 fine-tuning 되는 그 대상에 해당하는 파라미터가 됨
- 그러면 이 scalar 값을 각 word 별로 얻은 후에는 이 word 상에서 여러 word 들 중에 답에 해당하는 문구가 어느 단어에서 시작하는지를 먼저 예측함
-
그러면 여기서 가령 단어가 총 124개의 단어가 있다라고 하면 해당하는 scalar 값이 124개가 있을 것이고 거기에 softmax 를 통과해주고 그 softmax 의 ground-truth 로서 첫번째 단어의 해당하는 그 logit 값에서 그 word 에 배정되는 확률이 100%에 최대한 가까워지도록 softmax loss 를 통해서 이 모델을 학습하게 됨

- 그 다음엔 또 모델이 정답 구문이 끝나는 시점도 예측해야 하는데 그 경우는 starting position 을 예측하도록 하는 output layer 로서의 Fully connected layer 를 하나를 둠과 동시에 또 다른 fully connected layer 를 두번째 버전으로 만들고 그래서 그것을 통과해서 각 word encoding 벡터가 scalar 값이 나오도록 하고 거기에 또 softmax 를 통과한 후 두번째 버전의 output 단어 (ending word) 에 대한 position 을 예측하도록 하는 역할을 하는 Fully connected layer 를 마찬가지로 ground-truth 를 실제 해당하는 답에 마지막 단어의 위치가 되도록 softmax 를 통해 학습함으로써 이 2개의 starting 및 ending position 을 예측하는 fully connected layer 를 학습하게 됨
BERT: SQuAD 2.0
-
다음으로는 SQuAD 2.0 버전의 이 데이터셋 혹은 task 에 대해서 간략히 설명해보자.
- Use token 0 ([CLS]) to emit logit for “no answer”
- “No ansewr” directly competes with answer span
-
Threshold is optimized on dev set

-
이 경우 주어진 지문에 대해서 항상 정답이 있을 법한 질문을 뽑아놓고 이러한 경우에 가령 질문에 대한 답이 없는 경우 지문에서 질문에 대한 답을 찾을 수 없는 경우에 데이터셋들 까지도 원래 있었던 데이터에 같이 포함을 한 그러한 버전의 데이터셋이 SQuAD 2.0 데이터 셋임
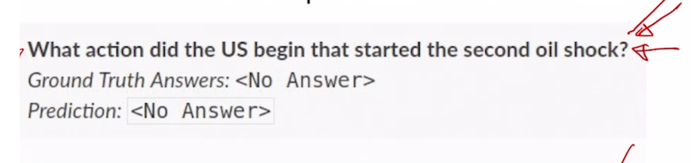
- 여기서는 예측해야 하는 task 가 이 질문에 대해서 먼저 답이 있는지 없는지를 판단하고 그 다음에 답이 있다면 위에서 본 방식대로 답에 해당하는 문구를 예측하게 됨
- 그러면 실제로 주어진 지문과 질문에 대해 답이 있다 없다를 예측하는 task 는 High-Level 에서 보면 이 문단과 질문을 다 종합적으로 보고 판단해야 하는 task 가 됨
- 그래서 그 경우 [CLS] 토큰을 활용할 수 있음
- 이 지문과 질문을 concat 해서 하나의 sequence 로 만들고 BERT 를 통해 encoding 을 하고 거기서 나온 [CLS] 토큰에서 주어진 질문과 지문에 대한 쌍에서 답이 실제로 없는 ground-truth 가 “No answer” 라고 표시된 경우는 [CLS] 토큰을 binary classification 하는 output layer 를 둬서 그 결과값이 “No answer” 로 적절히 예측되도록 하는 CrossEntropyLoss 를 통해서 학습을 하게 됨
- 그리고 최종적으로 예측에 이 모델을 사용할 때는 먼저 [CLS] 토큰을 통해 답이 있는지 없는지를 예측하고 답이 있는 것으로 예측결과가 나온 경우 그 때 비로소 위에서 설명한 starting 및 ending position 을 예측하는 output layer 를 구동함으로써 답에 해당하는 문구를 예측할 수 있게됨
BERT: On SWAG
-
또 다른 다수 문장을 다뤄야하는 task 의 BERT 를 사용한 사례를 보자.
- Run each Premise + Ending through BERT
-
Produce logit for each pair on token 0 ([CLS])

- 이 경우는, 주어진 문장이 있을 때, 그 다음에 나타날법한 적절한 문장을 고르는 task 가 됨
-
이 경우도 기본적으로 [CLS] 토큰을 사용하게 됨

-
여기서는 가능한 경우가 4가지가 있기 때문에 조금 비효율적일 수 있지만 첫문장과 가능한 4개의 선택지 중 첫번째를 concat 해서 BERT 를 통해 encoding 을 하고

-
나온 [CLS] 토큰 그리고 그 [CLS] 토큰의 encoding vector 가 2차원이면 여기에 Fully connected layer 를 output layer 로서 달아서 scalar 값을 예측하도록 함

-
그 다음에는 동일한 문장을 두번째 선택지와 같이 이어 붙여서 BERT 를 통해 encoding 하고 [CLS] 토큰에서 나오는 encoding vector 에 동일한 fully connected layer 를 통과를 시켜주면 두번째 문장을 concat 했을 때 output layer 의 최종 결과인 scalar 값이 나오게 됨
-
이런식으로 4번의 서로 다른 문장을 concat 을 해서 그리고 [CLS] 토큰의 output layer 까지 통과를 해서 각기 얻은 scalar 값이 4개가 나오게 되면 그 4개의 scalar 값을 softmax 에 입력으로 주고 그 다음에 정답이 가령 1번이라고 하면 그 4개 중에 ground-truth 확률을 첫번째 choice 가 100% 가 나올 수 있도록 하는 softmax loss 를 통해 이 전체 모델을 학습하게 됨
- 그래서 이 다양한 형태의 down-stream task 에 대해 이 BERT 를 fine-tuning 의 형태로 활용하는 사례들을 살펴봤음
BERT: Ablation Study
- Big models help a lot
- Going from 100M to 340M params helps even on datasets with 3,600 labeled examples
- Improvements have not asymptoted
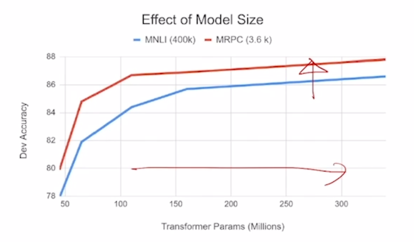
- BERT 에서의 또 다른 결과는 BERT 에서 제안한 모델 사이즈가 있을 때 그 모델을 점점 더 layer 를 깊게 쌓고 각 layer 별 파라미터를 점점 더 늘리는 방식으로 학습을 진행하면 그러면 모델사이즈를 점점 더 키울수록 여러 down-stream 에 대한 성능들이 계속적으로 끊임없이 좋아지더라 라는 것임
- 이는 모델사이즈를 GPU resource 가 허락가능한 키울 수 있는 만큼 키웠을 때에도 개선이 끝을 모르고 올라가는 형태의 결과를 보여줌
- 이 논문에서 시사하는바는 가능하다면 모델사이즈를 더 키울 수 있다면 이런식의 Pre-training 을 통한 여러 다양한 down-stream task 에 적용했을때의 성능이 점점 더 오를 수 있을것이다라고 전망함
댓글남기기