Day_27 02. Beam Search and BLEU score
작성일
Beam Search and BLEU score
2. Beam search
Greedy decoding
- Greedy decoding has no way to undo decisions!
- Input: il a m’mentartè (he hit me with a pie)
- he __
- he hit __
- he hit a __ whoops, no going back now …
-
How can we fix this?
- seq2ses with attention 과 같은 자연어 생성 모델에서 바로 다음 단어만을 예측하는 task 를 학습하고 test-time 에서는 다음 단어 생성하는 과정을 순차적으로 수행함으로써 예측을 수행함
- 여기서 우리는 매 timestep 마다 가장 높은 확률을 가지는 단어 하나만을 택해서 Decoding 을 진행하게 됨
- 이를 Greedy decoding 이라고 부름
-
어떤 sequence 로서의 전체적인 문장의 확률값을 보는게 아니라 근시안적으로 현재 timestep 에서 가장 좋아보이는 단어를 그때그때 선택하는 이런 approach 를 Greedy approach 라고 보통 부름

- 이러한 입력문장을 영어문장으로 번역해야 하는 경우에
- 처음 단어는 he
-
두번째 단어는 hit 까지 잘 생성을 했고 그랬는데 세번째 단어를 생성하는 과정에서 attention 을 잘못 배정 혹은 할당 했다든지해서 잘못 단어를 예측한 상황을 보자

-
a 가 pie 앞에 나오는데 me with 라는 부분을 건너뛰고 a 라는 단어를 이미 생성해버렸기 때문에 고정된 a 까지 생성된 결과를 바탕으로 뒤쪽을 생성해야 됨

- 뒤에서 단어를 생성하려고 할 때, 비로소 뒤늦게 앞에서 단어를 잘 못 생성했다는 것을 깨달았다고 하더라도 하나씩하나씩 단어를 생성한 후 그 단어를 다 고정을해서 예측을 진행을 하는 과정에서는 뒤로 돌아갈 수 없는 결국은 최적의 예측값을 내어주지 못하는 이런 상황에 빠지게 됨
- 이를 어떻게 해결할 수 있을까?
Exhaustive search
- Ideally, we want to find a (length $T$)
translation $y$ that maximizes
-
$P(y x) = P(y_1 x)P(y_2 y_1, x)P(y_3 y_2, y_1, x)…P(y_T y_1, …, y_{T-1}, x) = \prod_1^TP(y_t y_1, …, y_{t-1}, x)$
-
- We could try computing all possible sequences $y$
- This means that on each step $t$ of the decoder, we are tracking $V^t$ possible partial translations, where $V$ is the vocabulary size
- This $O(V^t)$ complexity is far too expensive!
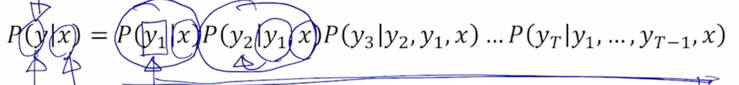
-
기본적으로 입력문장을 $x$ 라고 하고 출력문장을 $y$ 라고 하면 출력 문장 $y$ 에서의 첫번째 단어를 $y_1$ 이라고 생각하고 $y_1$ 에 대한 확률값 $P(y_1|x)$ 을 이렇게 구하고 그 다음엔 $x$ 라는 입력문장과 $y_1$ 까지의 단어를 생성한 후 2번째 출력단어를 생성하는 $y_2$ 에 해당하는 확률 $P(y_2|y_1, x)$ 을 쭉 곱하는 식으로 주어진 문장 $x$ 에 대한 출력문장 소위 joint probability 라고 부르는 동시사건에 대한 확률분포를 수식으로 쓸 수가 있음
-
그러면 이러한 확률값을 최대한 높은 확률을 가지는 출력문장 $y$ 전체로서 확률값을 최대가 되도록하는 그런 답을 뽑는 것이 우리가 할 수 있는 최선이라고 볼 수 있음
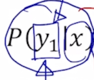
-
첫번째 생성하는 단어를 $P(y_1 x)$ 이 당시에는 가장 큰 확률값을 가지는 단어였다고 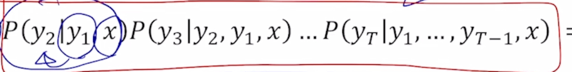
- 뒷부분에서 나오는 부분에 대한 확률값이 아무리 큰 값으로 도출했을때도 그 확률이 그렇게 크지 않을 수 있는 그런 경우가 발생될 수 있음
-
그러면 첫번째에서 제일 큰 확률값이 아니더라도 확률값이 그거보다는 조금은 작지만 뒤쪽에서 상대적으로 더 큰 확률값들을 내어줄 수 있는 그런 시나리오 혹은 그런 선택을 첫번째에서 하는 것이 전체적인 joint probability 의 값을 최대화하는데 더 좋은 결과를 낼 수도 있음
- 결국 timestep $t$ 까지의 가능한 모든 경우를 따진다면 그 경우는 매 timestep 마다 고를수 있는 단어의 수가 vocabulary 사이즈가 되고 그것을 $V$ 라고 할 때, 매 timestep 마다 $V$ 의 가지수 그리고 timestep $t$ 가 있으면 $V^t$ 으로 가능한 가지수를 다 고려해야한다는 사실을 알 수 있음
-
이 경우 기하급수적으로 증가하는 경우의 수를 현실적으로 다 일일히 계산하기에는 너무 많은 시간과 계산량이 필요로 하게 됨
- 그래서 차선책으로 나온 방법이 Beam search 라고 함
Beam search
- Core Idea: on each time step of the decoder, we keep track of the k most probable partial
tranlations (which we call hypothese)
- $k$ is the beam size (in practice around 5 to 10)
-
A hypothesis $y_1, …, y_t$ has a score of its log probability:
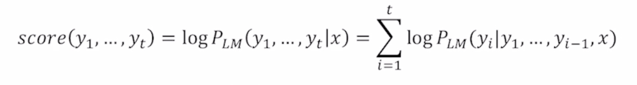
- Scores are all negative, and a higher score is better
- We search for high-scoring hypotheses, tracking the top k ones on each step
-
하이레벨에서는 앞서 말한 Greedy 알고리즘 혹은 Greedy decoding 과 가능한 모든 경우를 다 따지는 Exhaustive search 의 중간쯤에 있는 approach 라고 생각을 할 수 있음
-
매 timestep 마다 단 하나의 단어만을 고려하는 Greedy decoding 과 매 timestep 마다 가능한 모든 조합을 고려하는 기하급수적으로 굉장히 많은 수의 경우를 고려해야하는 이 2가지의 approach 중 그 사이의 있는 차선책으로서의 approach 가 Beam search 알고리즘이라고 함
- 핵심 아이디어는 decoder 의 매 timestep 마다 정해놓은 $k$ 개의 가짓수를 고려하고 timestep 이 진행함에도 $k$ 개의 경우의 수를 유지하고 마지막까지 decoding 을 진행한 후 최종적으로 나온 $k$ 개의 candidate 중에서 가장 확률이 높은 것을 택하는 방식
- $k$ 개의 경우의 수에 해당하는 decoding 의 output 을 하나하나의 가설 혹은 hypothesis 라고 부름
- 미리 정한 $k$ 의 값은 Beam search 에서 beam size 라는 용어로 부름
- 일반적으로는 5 ~ 10개의 beam size 를 가지도록 설정
- 여기서 우리가 최대화하고자 하는 그런 값은 $P_{LM}(y_1, …, y_t|x)$ 에 해당이 되는데 이는 앞서 보여준 $P(y|x) = P(y_1|x)P(y_2|y_1, x)P(y_3|y_2, y_1, x)…P(y_T|y_1, …, y_{T-1}, x)$ 수식처럼 단어를 하나씩 생성하면서 그 때의 확률값을 순차적으로 곱하는 형태로 수식을 전개할 수 있지만 여기에 log 를 붙이게 되면 이 값들은 $\sum_{i=1}^t \logP_{LM}(y_i|y_1, …, y_{i-1}, x)$ 결국은 다 덧셈, log 버전의 확률값들을 다 더한값으로 식이 변경됨
- 여기서 사용된 log 함수는 단조증가하는 함수이기 때문에 이 확률값이 가장 큰 그러한 때는 이 log 를 취한값도 다른 경우와 비교할 때에 비해서 가장 큰 값으로 유지됨
-
매 timestep 마다 이 score 가 가장 높은 $k$ 개의 candidate 을 고려하고 추적하는 것이 Beac search 의 핵심 아이디어가 됨
- Beam search is not guaranteed to find a globally optimal solution
-
But it is much more efficient than exahustive search!
- 모든 경우의 수를 따져서 가장 좋은 것을 뽑는것은 아니지만 그래도 모든 경우의 수를 다 따지는 것보다는 훨씬 더 효율적으로 계산할 수 있게됨
Beam search: Example
-
Beam size: $k = 2$

-
예를 들어서 beam size 를 2라고 설정할 때 어떤 입력문장이 주어지고 매 timestep 마다 순차적으로 이 단어를 출력값으로 예측한다고 생각해보면
댓글남기기