Day_86 01. 머신러닝 프로젝트 라이프 사이클
작성일
머신러닝 프로젝트 라이프 사이클
문제 정의의 중요성
앞으로 여러분들이 겪을 일은 대부분 문제(Problem)로 정의할 수 있음
(회사 업무 외에도 인생에서 겪는 내용도 포함해서)
- 문제 정의 : 특정 현상을 파악하고 $\rightarrow$ 그 현상에 있는 문제(Problem)을 정의하는 과정
- 문제를 잘 풀기(Solve) 위해선 문제 정의(Problem Definition)이 매우 중요함
풀려고 하는 문제가 명확하지 않으면 그 이후 무엇을 해야할지 결정하기 어려워짐
예 : 저는 사람들을 행복하게 만들고 싶어요
$\rightarrow$ 어떤 사람들을 대상으로? 모든 사람들을 대상으로?
$\rightarrow$ 행복의 정의는 무엇인가? 금전적 부? 감정적인 상황?
$\rightarrow$ 행복의 정의에 따라 무엇을 할 수 있을지가 다름
머신러닝 알고리즘, 개발 능력도 중요하지만, 근본적인 사고 능력도 중요
문제를 충분히 정의하고 고민하는 습관 만드는 것이 중요함
머신러닝, AI, 데이터 사이언스, 개발 등 대부분 업무에서 항상 문제 정의가 선행되어야 함
How 보다 Why 에 집중

- 문제 정의란?
- 본질을 파악하는 과정
- 해결해야 하는 문제는 무엇이고 그 문제를 해결하면 무엇이 좋을까? 어떻게 해결하면 좋을까?
프로젝트 Flow
문제를 해결하기 위한 Flow
- 현상 파악
- 목적, 문제 정의 $\rightarrow$ 계속 생각하기, 쪼개서 생각하기
- 프로젝트 설계
- Action
- 추가 원인 분석
1) 현상 파악
어떤 현상이 발견되었는가? 현재 상황을 파악함
- 어떤 일이 발생하고 있는가?
- 해당 일에서 어려움은 무엇인가?
- 해당 일에서 해결하면 좋은 것은 무엇인가?
- 추가적으로 무엇을 해볼 수 있을까?
- 어떤 가설을 만들어 볼 수 있을까?
- 어떤 데이터가 있을까?
예) 레스토랑의 매출이 감소하고 있다. 3달 연속으로 감소되고 있으며, 전체적인 손님 수가 줄어들고 있다.
2) 구체적인 문제 정의
- 무엇을 해결하고 싶은가?
- 무엇을 알고 싶은가?
앞선 현상을 더 구체적으로 명확한 용어로 정리해보기
앞선 현상에서 더욱 데이터를 확인해보니 다음과 같은 내용을 알 수 있었음
처음 방문하는 손님들이 심하게 줄어들고 기존 손님들도 줄고 있다. 상대적으로 처음 방문하는 손님들이 더 줄어들고 있다.
여러가지로 문제를 해결할 수 있음
- 가게를 SNS 등에 홍보 $\rightarrow$ 마케팅 조직에서 진행
- 처음 방문하는 손님들이 어려움을 가지고 있을 수 있음 $\rightarrow$ 어떤 어려움인지 더 구체적으로 확인해보기
처음 방문하는 손님들의 어려움을 확인하기 위해 데이터를 확인해보고, 처음 방문하는 분들에게 인터뷰를 통해 질문
그 결과, 가게의 메뉴가 너무 다양하고 설명이 부족해서 메뉴를 선정하기 어려워서 아무렇게나 선택하고 만족도가 낮았다고 함
문제 상황 : “메뉴가 너무 다양해서 선정하기 어렵다”
이 문제를 일으키는 원인과 해결 방안을 고민해보기
문제 상황 : “메뉴가 너무 다양하고 설명이 부족해 선정하기 어렵다”
원인
- 메뉴가 다양하다
- 설명이 부족하다
해결 방안
- 메뉴를 줄인다? $\rightarrow$ 비즈니스 상황에 따라 일시적으로 줄일 수는 있찌만 궁극적인 해결일지는 반신반의
- 설명을 늘린다? $\rightarrow$ 당장 수정할 수 있는 요소. 어떤 상황에 이 음식을 먹으면 좋은지 가이드를 줄 수 있음
당장 진행할 수 있는 설명을 늘리는 방식을 사용하고, 병렬로 손님의 취향에 기반한 음식을 추천할 수 있지 않을까?
설명을 늘리는 방식 = 룰 베이스(만약 이런 음식을 좋아한다면 이런 부분을 추천드려요) $\rightarrow$ 당장의 문제 해결
추천 = 알고리즘 개발 $\rightarrow$ 문제 해결의 또 다른 방법
문제 정의는 결국 현상을 계속 쪼개고, 그 문제를 기반으로 어떤 어려움을 겪고 있는지를 파악함
데이터로 할 수 있는 일을 만들어서 진행하되, 무조건 알고리즘 접근이 최상은 아니라는 방법을 제시할 수도 있어야함(간단한 방법부터 점진적인 접근)
우리는 식나의 제약을 받고 있기 때문!
원인을 계속 파고 들면, 해결 방법이 구체적으로 나올 수 있음
여기서 인지하면 좋은 내용
- 문제를 쪼개서 파악해보자
- 문제의 해결 방식은 다양하다
- 해결 방식 중에서 데이터로 해결할 수 있는 방법을 고민해보기
- 점진적으로 실행하기
꼭 머신러닝이나 AI 가 만능은 아니다 하지만 우리는 간단한 걸 회사에 먼저 제시하고 AI 로 문제를 풀 수 있는 그런 것들을 잘 제시하면 좋겠다!
3) 프로젝트 설계 - 경험담
머신러닝 프로젝트 과정 - 최초 생각
- 문제 정의
- 데이터 수집
- 모델 개발
- 모델 배포
- 수익 획득!
머신러닝 프로젝트 과정 - 현실
- 문제 정의
- 최적화할 Metric 선택
- 데이터 수집, 레이블 확인
- 모델 개발
- 모델 예측 결과를 토대로 Error Analysis. 잘못된 라벨이 왜 생기는지 확인
- 다시 모델 학습
- 더 많은 데이터 수집
- 다시 모델 학습
- 2달 전 테스트 데이터에선 성능이 좋지만 어제 데이터엔 성능이 좋지 않음
- 모델을 다시 학습함
- 모델 배포
- 최적화할 Metric 이 실제로 잘 동작하지 않아 Metric 을 수정
- 다시 시작 ㅠ
이런 과정이 계속 반복되는데 이런 과정을 좀 편하게 하려고 MLOps 라는 분야가 있는 것임
이런 과정을 겪고 보니까
“문제 정의 후, 프로젝트의 설계를 최대한 구체적으로 하는 것이 좋구나..!”
- 미리 많은 것을 대비한 상황
- 대비하지 않은 상황
최대한 고려해볼 걸 다 고려해보고 이런건 우리 프로젝트에선 필요없다 필요하다를 잘 판단해야함
문제 정의에 기반해서 프로젝트 설계
- 해결하려고 하는 문제 구체화
- 머신러닝 문제 타당성 확인
-
목표 설정, 지표 결정
- 제약 조건(Constraint & Risk)
- 베이스라인, 프로토타입
- 평가(Evaluation) 방법 설계
3) 프로젝트 설계 - 머신러닝 문제 타당성 확인
-
머신러닝 문제를 고려할 때는 얼마나 흥미로운지가 아니라 제품, 회사의 비즈니스에서 어떤 가치를 줄 수 있는지 고려 해야 함
- 머신러닝 문제는 결국 데이터로부터 어떤 함수를 학습하는 것
- 머신러닝 문제 타당성 평가하기 : 복잡도를 평가하는 방법은 필요한 데이터의 종류 와 기존 모델이 있는지 살펴보기
- 머신러닝은 모든 문제를 해결할 수 있는 마법의 도구가 아님
- 머신러닝으로 해결할 수 있는 문제지만 머신러닝 솔루션이 최적이 아닐 수도 있음
유연한 사고가 필요함!
머신러닝이 사용되면 좋은 경우
- 패턴 : 학습할 수 있는 패턴이 있는가?
- 복권의 다음 결과 예측할 때 머신러닝 시스템을 구축하는 것이 좋을까?
- 생성되는 방식에 패턴이 없다면 학습할 수가 없음
- 주식 가격에서 가격이 완전히 무작위라고 믿으면 모델을 만드는게 불필요함.
데이터를 탐색해서 패턴을 발견하면 진행
- 목적 함수 : 학습을 위한 목적 함수를 만들 수 있어야 함
- 머신러닝 알고리즘은 유용한 패턴을 학습하거나 노이즈를 패턴으로 학습하는 경우도 존재
- 지도 학습은 정답 레이블과 예측 결과의 차이로 정의할 수 있음
- 복잡성 : 패턴이 복잡해야 함
- 주소 검색 문제 $\rightarrow$ 우편 번호에 기반해서 정렬되어 있으면 머신러닝이 필요하지 않음
- 집 가격을 예측할 경우 복잡한 패턴이 필요할 수 있음 : 동네의 평균 가격, 공원 유무, 침실 수, 건축 연식, 학교 수, 자연 재해 등
- 데이터 존재 여부 : 데이터가 존재하거나 수집할 수 있어야 함
- 학습할 데이터가 없으면 프로젝트 진행 전에 데이터 수집부터 진행해야 함
- 데이터가 없다면 룰베이스 알고리즘을 만든 후, 데이터 수집 계획부터 수립
- 룰베이스 알고리즘을 만드는건 데이터의 기준선을 만들기 위함
- 반복 : 사람이 반복적으로 실행하는 경우
- 사람은 반복에 능숙함. 아이에게 고양이 사진을 보여주고 고양이를 알아보게 할 수 있음
- 작업이 반복 $\rightarrow$ 패턴
- 사람의 노동력을 줄일 수 있는 관점
머신러닝이 사용되면 좋지 않은 경우
- 비윤리적인 문제
- 간단히 해결할 수 있는 경우
- 좋은 데이터를 얻기 어려울 경우
- 한번의 예측 오류가 치명적인 결과를 발생할 경우
- 시스템이 내리는 모든 결정이 설명 가능해야 할 경우
- 비용 효율적이지 않은 경우
3) 프로젝트 설계 - 목표 설정, 지표 결정
프로젝트의 목표
- Goal : 프로젝트의 일반적인 목적, 큰 목적
- Objectives : 목적을 달성하기 위한 세부 단계의 목표(구체적인 목적)
예를 들어, 랭킹 시스템에서 고객의 참여(Engage)를 최대화하고 싶은 Goal 이 있는 경우
Objectives
- NSFW(Not Safe For Work) 컨텐츠 필터링을 통해 사용자에게 불쾌감을 줄임
- 참여에 따른 게시물 랭킹 선정 : 사용자가 클릭할 가능성이 있는 게시물 추천
그러나 참여를 위해 최적화를 하면 윤리적인 의문이 존재할 수 있음
$\rightarrow$ 극단적으로 클릭을 유도할 자극적인 컨텐츠를 노출할 수 있음(Netflix 소셜 딜레마)
더 건전한 뉴스피드를 만들고 싶음
새로운 Goal : 극단적인 견해와 잘못된 정보의 확산을 최소화하며 사용자의 참여를 극대화하는 목표
새로운 Objectives
- NSFW 컨텐츠 필터링
- 잘못된 정보 필터링
- 품질에 따른 게시물 랭킹 선정 : 좋은 품질인 게시물
-
참여에 따른 게시물 랭킹 선정 : 사용자가 클릭할 가능성이 있는 게시물
- 목표를 설정하며 데이터를 확인해야 함(지표와 연결되는 내용이기 때문에)
- 데이터셋이 레이블링이 되지 않은 경우도 존재
- 데이터 소스 찾아보기
- 부정 거래 탐지 : 부정 거래자와 정상 거래자의 거래 내역, 계정 정보 등
- 정확히 찾으려는 데이터가 없는 경우가 있어서 여러가지 시나리오를 고려 하는 것이 좋음
- Label 을 가진 데이터가 있는 경우 $\rightarrow$ 바로 사용
- 유사 Label 을 가진 데이터가 있는 경우 $\rightarrow$ 음악 스트리밍 서비스에서 노래 재생, 건너뛰기 기록은 선호도를 예측하기 위한 유사 Label
- Label 이 없는 데이터 $\rightarrow$ 직접 레이블링 or 레이블링이 없는 상태에서 학습하는 방법 찾기
- 데이터가 아예 없는 경우 $\rightarrow$ 데이터 수집 방법부터 고민
- 데이터셋을 만드는 일은 반복적인 작업 $\rightarrow$ 이걸 위해 Self Supervised Learning 등을 사용해서 유사 레이블을 만드는 방법도 존재
Multiple Objective Optimization
- 최적화하고 싶은 목적 함수가 여러가지 있는 경우, 서로 충돌할 수 있음
- 품질에 따른 게시물 랭킹 선정 vs 참여에 따른 게시물 랭킹 선정
- 게시물이 매우 매력적이지만 품질이 의심스러울 경우엔? 이런 고민을 할 수 있음
품질에 따른 게시물 랭킹 성정 : 게시물 품질 예측(게시물 예상 품질 - 실제 품질 : quality_loss)
참여에 따른 게시물 랭킹 선정 : 게시물 클릭 수 예측(게시물 예상 클릭 수 - 실제 클릭 수 : engegement_loss)
방법 1
- 단일 모델
- 두 loss 를 하나의 loss 로 결합하고, 해당 loss 를 최소화하기 위해 모델을 학습하는 방법
loss = $\alpha$ quality_loss + $\beta$ engagement_loss
알파와 베타를 필요에 따라 조정해야 함
앞선 방식의 문제 : 알파와 베타를 조정할 때마다 모델을 다시 학습시켜야 함
방법 2
- 2개의 모델 (각각의 Loss 를 최소화)
- quality_loss 를 최소화하고 예상 품질을 반환하는 quality_model
- engagement_loss 를 최소화하고 게시물의 예상 클릭 수를 반환하는 engage_model
Rank : $\alpha$ quality_model(post) + $\beta$ engagement_model(post)
이제 모델을 재학습하지 않아도 조정할 수 있음
Objective 가 여러개인 경우 분리하는 것이 좋음
- 학습하기 쉬워야 함
- 하나의 objective 를 최적화하는 것이 여러 objectives 를 최적화하는 것보다 쉬움
- 모델을 재학습하지 않도록 모델을 분리
- Objectives 는 수정해야 하는 유지보수 일정이 모두 다를 수 있음
- 예) 스팸 필터링은 품질 순위 시스템보다 더 빠르게 업데이트해야 함
3) 프로젝트 설계 - 제약 조건(Constraint & Risk)
- 일정 : 프로젝트에 사용할 수 있는 시간
- 예산 : 사용할 수 잇는 최대 예산은?
-
관련된 사람 : 이 프로젝트로 인해 영향을 받는 사람은?
- Privacy : Storage, 외부 솔루션, 클라우드 서비스 등에 대한 개인정보 보호 요구
- 기술적 제약
- 기존에 운영하고 있던 환경 : 레거시 환경(인프라)가 머신러닝 적용할 때 큰 제약일 수 있음
-
윤리적 이슈 : 윤리적으로 어긋난 결과
- 성능
- Baseline : 새로 만든 모델을 무엇과 비교할 것인가? 기존에 사람이 진행하던 성능 or 간단한 회귀
- Threshold : 확률값이 0.5 이상일 경우 강아지라고 할 것인지, 0.7 이상일 경우 강아지라고 할 것인지?
- Performance Trade-off : 속도가 빠른데 Acc 0.93 vs 속도는 조금 더 느린데 Acc 0.95
- 해석 가능 여부 : 결과가 왜 발생했는지 해석이 필요할까? 해석이 필요한 사람은?
- Confidence Measurement : False Negative 가 있어도 괜찮은지? 오탐이 있으면 안되는지?
3) 프로젝트 설계 - 베이스라인, 프로토타입
- 모델이 더 좋아졌다고 판단할 수 있는 Baseline 이 필요
- 꼭 모델일 필요는 없음
- 자신이 모델이라 생각하고 어떻게 분류할지 Rule Base 규칙 설계
- 간단한 모델부터 시작하는 이유
- 어떻게든 모델의 위험을 낮추는 것이 목표가 되어야 함
- 가장 좋은 방법은 최악의 성능을 알기 위해 허수아비 모델로 시작하는 것
- 초기엔 단순하게 사용자가 이전에 선택한 행동을 제안할 수도 있고, 추천 시스템에선 제일 많이 구매한 것을 추천할 수도 있음
- 유사한 문제를 해결하고 있는 SOTA 논문 파악해보기 $\rightarrow$ 우리의 문제에선 어떤 시도를 해볼 수 있을까?
- 베이스라인 이후에 간단한 모델을 만들면 피드백을 들어보면 좋음
- 회사의 동료들에게 모델을 활용할 수 있는 환경 준비
- 프로토타입을 만들어서 제공
- Input 을 입력하면 Output 을 반환하는 웹페이지
- 이왕이면 좋은 디자인을 가지면 좋지만, 여기선 모델의 동작이 더 중요
- HTML 에 집중하는 것보다, 모델에 집중하는게 중요
- 이를 위해 Voila, Streamlit, Gradio 등을 활용

3) 프로젝트 설계 - Metric Evaluation
앞에서 Objectives 를 구해서 모델의 성능 지표는 확인함
모델의 성능 지표와 별개로 비즈니스 목표에 영향을 파악하는 것도 중요
앞선 문제를 해결할 경우 어떤 지표가 좋아질까? 를 고민해야 함
이 부분은 작게는 모델의 성능 지표(RMSE) 일 수 있고, 크게는 비즈니스의 지표 일 수 있음(고객의 재방문율, 매출 등)
지표를 잘 정의해야 $\rightarrow$ 우리의 Action 이 기존보다 더 성과를 냈는지 아닌지를 파악할 수 있음
(이를 위해 AB Test 를 진행하기도 함)
만든 모델이 비즈니스에 어떤 임팩트를 미쳤을지(매출 증대에 기여, 내부 구성원들의 시간 효율화 증대 등) 고려하면서 만드는 사람
대부분 기업 : 이익 극대화를 목표
머신러닝 프로젝트는 궁극적으로 수익을 높이는 것이 목표
간접적으로 기업의 이익 극대화에 영향을 미칠 수 있음
- 전환율 증대 $\rightarrow$ 매출 증대
- 반복 업무 자동화 $\rightarrow$ 내부 직원의 리소스 효율로 인한 비용 절감
- 간접적으로 더 높은 고객 만족도 창출, 웹사이트에서 보내는 시간 늘리기 등
-
개인화된 솔루션을 제공해 서비스를 더 많이 사용하도록 만들어 매출을 증가시킬 수 있음
- 개발 및 배포 중에 시스템의 성능은 어떻게 판단할 수 있을까?
- 정답 레이블이 필요한 경우 사용자 반응에서 어떻게 레이블을 추론할 수 있을까?
- 모델 성능을 비즈니스 Goal 과 Objectives 를 어떻게 연결할 수 있을까?
4) Action(모델 개발 후 배포 & 모니터링)
앞서 정의한 지표가 어떻게 변하는지 파악하기
- 현재 만든 모델이 어떤 결과를 내고 있는가?
- 잘못 예측하고 있다면 어떤 부분이 문제일까?
- 어떤 부분을 기반으로 예측하고 있을까?
- Feature 의 어떤 값을 사용할 때 특히 잘못 예측하고 있는가?
5) 추가 원인 분석
새롭게 발견한 상황을 파악해 어떤 방식으로 문제를 해결할지 모색
그 과정에서 앞서 진행한 과정을 반복

비즈니스 모델
회사에서 업무할 때 중요한 것이 무엇인지 알아야 함
회사에서 중요한 것 = 비즈니스
즉, 비즈니스에 대한 이해도가 높을수록 문제 정의를 잘 할 가능성 존재
비즈니스 모델 파악하기
회사는 비즈니스 모델을 만들고, 비즈니스 모델을 통해 매출이 발생함
해당 비즈니스 모델에서 어떤 데이터가 존재하고 그 데이터를 기반으로 어떤 것을 만들 수 있을지 생각
1) 회사의 비즈니스 파악하기 2) 데이터를 활용할 수 있는 부분은 어디인가? (Input) 3) 모델을 활용한다고 하면 예측의 결과가 어떻게 활용되는가? (Output)
비즈니스 모델 파악하기 - Uber Case Study
회사가 어떤 서비스, 가치를 제공하고 있는가?
- 우리가 대표적으로 알고 있는 Uber : Taxi 와 유사한 이동 서비스
- 보통 기업의 홈페이지에 보면 제품(Product) 라인업이 있음

Uber : 차량 서비스, Uber Eats, 수익 올리기, 도시 발전 촉진, 비즈니스
https://www.uber.com/kr/ko/about/uber-offerings/
차량 서비스


음식 배달 서비스
Gig Worker 를 위한 플랫폼

대중교통 개선 지원, 의료 서비스 접근성 증진
기업 대상 서비스 : 비즈니스

차량 서비스의 핵심 : 수요와 공급을 매칭시켜 손님과 드라이버가 만날 수 있는 플랫폼 역할
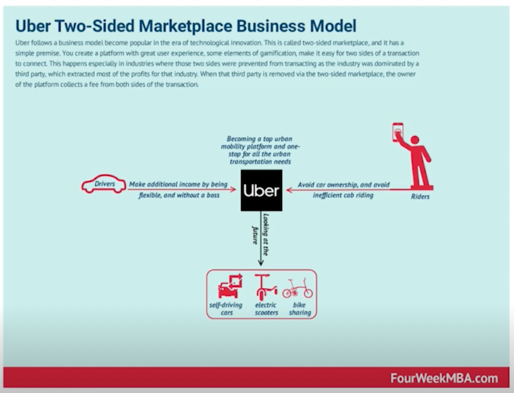
많은 드라이버 $\rightarrow$ 손님 관점에서 대기 시간 줄어듦 $\rightarrow$ 손님이 많아짐 $\rightarrow$ 시간당 많은 수입 $\rightarrow$ 많은 드라이버
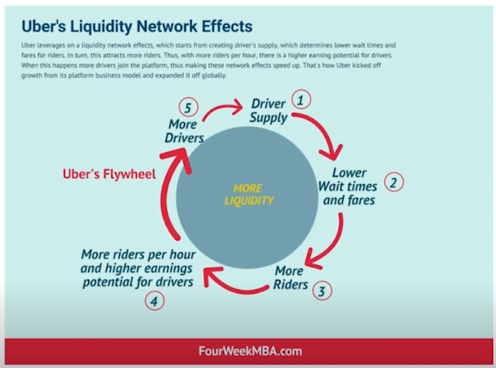
많은 드라이버가 결국 비즈니스 플아이휠의 시작 $\rightarrow$ 어떻게 하면 더 많은 수익을 얻을 수 있을까? $\rightarrow$ 수요와 공급의 불균형이 심각해진 상황
예) 비가 오는 상황, 드라이버 수가 적은 시간 $\rightarrow$ 더 많은 수익!
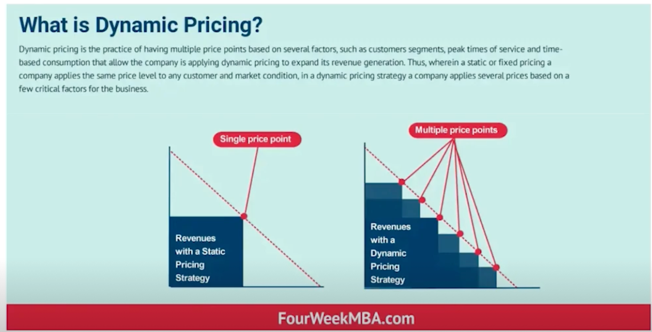

대기 시간 줄이기(ETA, Estimated time of Arrival) $\rightarrow$ 드라이버의 시간당 수익 증가, 고객의 기다리는 시간 줄임
어떤 차량을 어떤 고객에게 배정해야 하는가?
Uber Eats : 음식 추천 시스템 $\rightarrow$ 고객이 주문하려고 하는 주문 제안

Uber 의 기술블로그에 잘 나와있으니 관심있으면 찾아볼것!
Uber 엔지니어링 블로그에서 간접적으로 파악할 수 있음 : https://eng.uber.com/
누군가 산업에 대해 정리해둔 Paper 가 있는지 찾아보기
예) awesome mobility machine learning github
해당 산업군에서 사용하는 기술
$\rightarrow$ 해당 비즈니스에 어떻게 적용할 수 있을까
$\rightarrow$ 추가 가치 발견
$\rightarrow$ 머신러닝, AI 가 비즈니스에 영향을 주는 과정을 이해
https://github.com/zzsza/Awesome-Mobility-Machine-Learning-Contents
비즈니스 모델 파악하기
1) 회사의 비즈니스 파악하기 : 회사가 어떤 서비스, 가치를 제공하고 있는가?

1) 데이터를 활용할 수 있는 부분은 어디인가? (Input)
- 데이터가 존재한다면 어떤 데이터가 존재하는가?
- 데이터로 무엇을 할 수 있을까?
- 해당 데이터는 신뢰할만한가? 데이터 정합성은 맞는가? 레이블이 잘 되어있는가? 계속 받을 수 있는가?
- 다양한 팀에 있는 분들과 직접 인터뷰하는 것도 좋은 방법
무엇을 해볼 수 있을까?
- 왜 해야하는가?
3) 모델을 활용한다고 하면 예측의 결과가 어떻게 활용되는가? (Output)
- 고객에게 바로 노출(추천, 얼굴 필터 등) $\rightarrow$ 더 좋은 가치 제공 / 매출 증대
- 내부 인원이 수동으로 진행해야 하는 업무를 자동화 할 수 있음
Special Mission
부스트캠프 AI Tech 혹은 개인 프로젝트를 앞선 방식으로 정리해보기
실제로 회사에서 한 일이 아니더라도, 특정 회사에서 활용했다고 가정하거나 아예 크게 문제 정의해서 구체화해보기
이 모델이 회사에서 활용되었따면 어떤 임팩트를 낼 수 있었을까? 고민해서 정리해보기!
직접 일상의 문제라도 하나씩 정의하기
댓글남기기