Day_80 [오피스아워] 데이터베이스 연동을 통한 분산 모델 최적화 하기 - 임종국 멘토
작성일
[오피스아워] 데이터베이스 연동을 통한 분산 모델 최적화 하기 - 임종국 멘토
기본 Optuna 의 최적화 구조
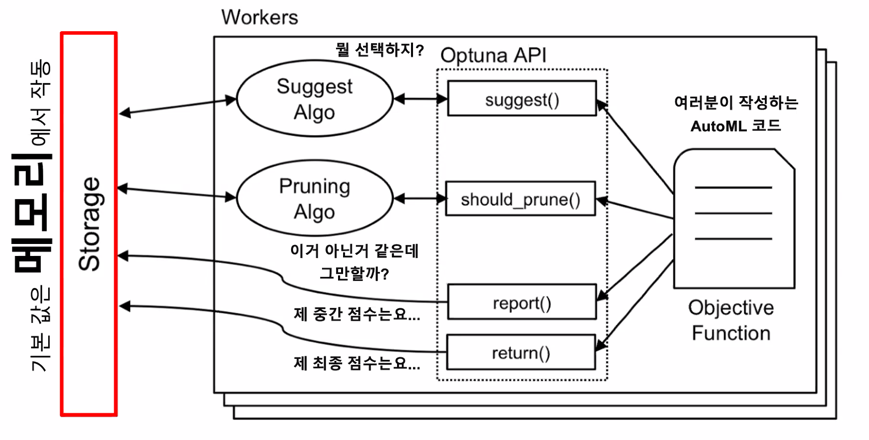
메모리 Stroage 쓰는게 뭐가 문제죠?

굉장히 오래걸리는데 도중에 코드 문제로 멈춘다면 지금까지 한걸 모두 날려버림…
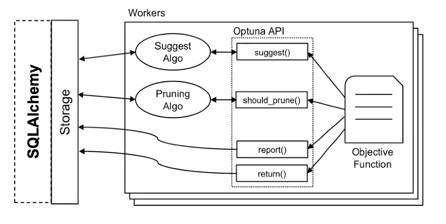
어떤 Storage 를 사용할 수 있나요?
- SQLAlchemy 에서 지원하는 데이터베이스 활용 가능
- https://docs.sqlalchemy.org/en/14/core/engines.html#database-urls
- 지원하는 데이터 목록
- PostgreSQL
- MySQL
- Oracle
- Microsoft SQL Server
- SQLite
- Local 에서만 사용 가능

가장 PostgreSQL 이 세팅하기 쉬웠음 그래서 추천
MySQL 도 사용할 수 있는데 두가지중에 PostgreSQL 이 디렉토리를 백업하기 편해서 이걸로 좀 추천했음
PostgreSQL 12.0 을 설치 해봅시다.
- PostgreSQL: https://www.postgresql.org/
- 대회 서버(우분투) 기준 설치 방법

- lsb-core : linux 버전 확인
- wget : 파일 다운로드
- psycopg2-binary : PostgreSQL 을 파이썬에서 사용하기 쉽도록 만들어주는 API
부스트캠프 서버에서는 sudo 를 제거하고 하면 정상작동 함
이 이후는 실습으로 진행되서 pdf 확인하자!
Q&A
머신러닝에서도 하둡을 많이 쓰나요?
확답은 하지 못하고 참고로 말씀드리면 하둡은 머신러닝보다는 엄청 많은 데이터를 정제하는 과정에서 사용함
그렇기 때문에 머신러닝과 아예 연관이 없다고 할수는 없지만 데이터사이언스쪽에서 쓰고
다른걸 더 많이씀
신입은 분산처리 경험을 어떻게 쌓으면 좋을까요?
신입도 경력도 경험을 쌓기가 만만치 않음
분산 처리를 요구할정도로 큰 task 를 할 일도 많이 없고 처음부터 분산처리 엔지니어 쪽으로 들어가는게 아닌이상 그거보다 다른 강점을 살리는게 좋을것 같음
어떻게든 경력을 쌓고싶다고하면 toy project 를 많이해보는게 좋을 듯
데이터처리 데이터 정제를 많이 하는게 좋을듯
실시간 분석이나 이런걸 한다면 elastic search 를 보는게 좋음
머신러닝 분산 파이프라인을 본다면 optuna 와 RDB 를 이용한걸 해보면 좋음
분산처리가 필요한 application 을 생각해봐서 그거에 맞는 toy project 를 하는게 좋을것임
학습된 모델 파라미터를 관리하는 방법으로 sql이 적합한지 궁금합니다. 비정형데이터로 관리하는 것이 더 좋을 것 같은데 정형데이터로 path만 저장하고 필요할 때 불러오는 방식이 더 효율적일까요?
어떤 형태든 편한대로 히스토리만 잘 남기고 관리만 잘하면 된다라고 생각함
비정형이든 정형이든 상관없음
optuna 에서 RDB 를 쓴 이유는 optuna 자체가 RDB 를 지원하기 떄문
학습된 파라미터같은 경우는 yaml 파일이든 json 파일로 저장해둠
training 할 때 argument 는 json 이나 yaml 로 저장해두는 편
어떤 형태로든 기록을 해두는게 좋다!
주로 wandb 를 이용해서 거기에 모든 학습파라미터를 저장해두는 편임
아까 말씀하셨던 이미지를 메모리에 캐싱하는 방법은 어떤 키워드로 찾아봐야 하나요??
pytorch image caching 정도로 찾으면 좋지 않을까 싶음
어렵지 않은게 데이터셋을 처음에 만들때 dataset class 에서 맨 처음 모든 이미지의 경로를 받아오는데 그때 이미지 경로만 받아오지 않고 이미지데이터를 모두 미리 받아놓는 형태
call 들어올 때 데이터를 load 하는게 아닌 미리 load 해놓는 것
pytorch dataset pre-caching 으로 검색해보는게 도움이 될 듯
간단하게 해보고 메모리 사용량이 어떻게 되는지 확인해보는게 좋을 듯
댓글남기기