Day_82 02. 찢은 모델 꾸겨 넣기: Quantization 실습(with torch, tensorrt)
작성일
찢은 모델 꾸겨 넣기: Quantization 실습(with torch, tensorrt)
1. Quantization 종류
1.1 Review & Overview
Quantization
- 기존의 high precision(일반적으로 fp32) Neural network 의 weights 와 activation 을 더 적은 bit(low precision)으로 변환하는 것
- Quantized Matrix Multiplication, Activation, Layer fusion, …
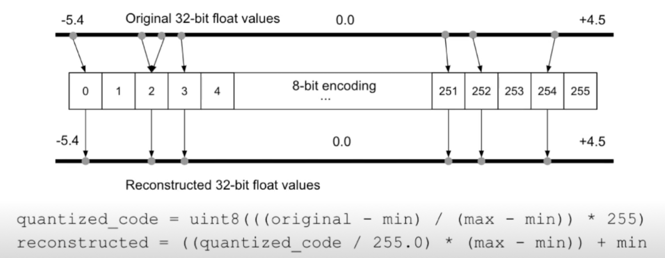
Quantization approach 구분
- Post Training Quantization(PTQ): 학습 후에 quantization parameter(scale, shift)를 결정
- Quantization Aware Training(QAT): 학습 과정에 quantization 을 emulate 함으로써, quantization 으로 발생하는 성능하락을 완화함
1.2 Post Training Quantization(PTQ)
PTQ 기법 정리
- Dynamic range quantization(weight only quantization): weight 만 quantize 됨(8-bit), inference 시에는 floating-point 로 변환되어 수행
- Full integer quantization(weight and activation quantization): weight 와 더불어 모델의 입력 데이터, activation(중간 레이어의 output)들 또한 quantize
- Float 16 quantization: fp32 의 데이터 타입의 weight 를 fp16 으로 quantize

어떨때 어떤 기법을 적용해야할까?(From TF[2])
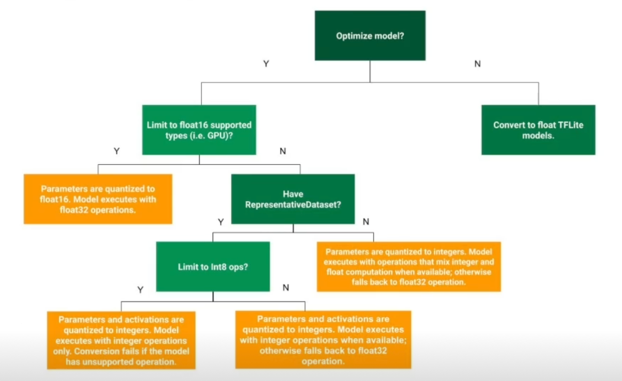

참고: PyTorch 의 구분
- Dynamic range quantization(Dynamic quantization)을 별도의 범주로 구분
- Post Training Quantization 은 Static quantization 이라고도 칭함
- Dynamic quantization 의 경우, model 수행 시간이 weights 를 load 하는 것이 실제 matrix multiplication 보다 더 오래 걸리는 LSTM, Transformer 기반의 모델에 효과적이라는 언급이 있음
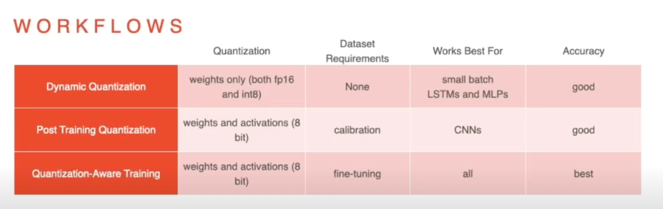
1) Dynamic range quantization(weight only quantization)
- 네트워크의 Weight 만 quantize 됨(8bit)
- Pros 😁:
- 별도의 calibration(validation) 데이터가 필요하지 않음
- 모델의 용량 축소(8bit 기준 1/4)
- Cons 😥:
- 실제 연산은 floating point 로 수행됨
- 실제 속도의 이점이 크지 않음
2) Full integer quantization(weight and activation quantization)
- Weight 와 더불어 모델의 입력 데이터, activation(중간 레이어의 output)들도 quantize 됨
- Pros 😁:
- 모델의 용량 축소(8bit 기준 1/4)
- 더 적은 메모리 사용량, cache 재사용성 증가
- 빠른 연산(fixed point 8bit 연산을 지원하는 경우)
- Cons 😥:
- Activation 의 parameter 를 결정하기 위하여 calibration 데이터가 필요함
(주로 training 데이터에서 사용, 약 100개의 데이터) $\rightarrow$ 항상은 아님 - TF 에서는 100개 정도면 되고 tensorRT 에서는 1000개 정도 필요
- Activation 의 parameter 를 결정하기 위하여 calibration 데이터가 필요함
- TensorRT 의 quantization 은 bias(zero point)가 없는 Symmetric quantization
Why? 연산이 훨씬 간단하고, (경험적으로) 성능에 큰 영향을 주지 않았다

2) Full integer quantization; TensorRT(NVIDIA) calibration 예시
- Calibration?; 성능 저하를 최소로 하는 threshold 찾기
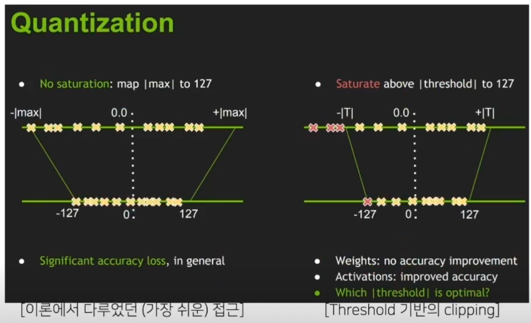
tensorRT 에서는 어느 정도 threshold 를 정해서 그 값을 넘어가는 값들은 cliping 혹은 saturation 을 시켰더니 왼쪽에 대비해서 더 좋았다
대신에 threshold 를 어떻게 정할까가 이슈가 됨
- Minimize information loss 관점으로 접근
- 각 네트워크, 각 레이어 마다 activation value 의 range, distribution 이 다르다
(x 축: value, y 축: normalized histogram counts)
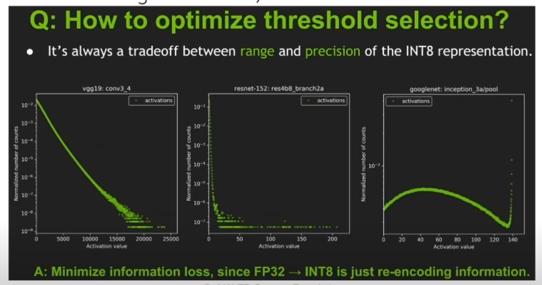
- “threshold 에서 saturated 된 normalized histogram 분포(ref_distr(P))” 와 “원 histogram 으로부터 quantized, normalized 된 분포(quant_distr(Q))” 의 KL div 가 최소인 지점을 결정




P 에 있던 0 은 Q 에서도 0이다
P 와 Q 의 bin 개수를 맞춰주는 작업
- Calibration 방법마다 필요한 데이터의 크기는 다를 수 있음

- 결과 예시
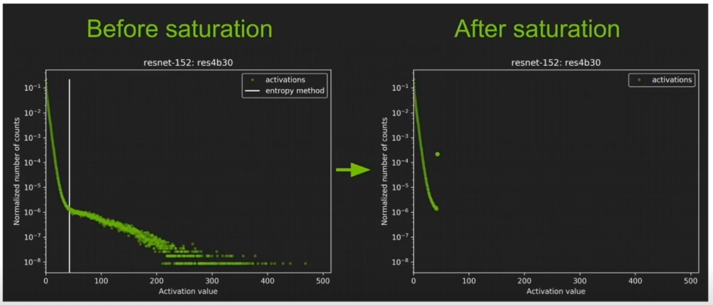
왼쪽 histogram 분포가 이렇게 되어있었는데 KL div 를 minimize 하는 위치가 흰 선이되고 여기까지가 값이 되는거고 흰 선 오른쪽에 있는 값들은 몰려서 맨끝에 값이 count 가 많은 것을 볼 수 있음
3) Float16 quantization
- Float 32 모델을 float 16 모델로 변환
- Pros 😁:
- 모델의 용량 축소(1/2)
- 적은 성능 저하
- GPU 상에서 빠른 연산(대체로 fp32를 상회)
- Cons 😥:
- CPU 상에서는 fixed point 연산만큼의 속도 향상이 있지는 않음
1.3 Quantization Aware Training(QAT)
Overview
- 학습 과정에 quantization 을 emulate 하여(fake quantization), inference 시에 발생하는 quantization error 를 training 시점에 반영가능하도록 함
- 보통은 일반적인 방법으로 학습을 진행하고, fine-tuning 으로 QAT 를 적용
- 학습 과정에 emulate 된 quantization 파라미터를 inference 에도 사용
- PTQ 대비 성능 하락 폭이 적음
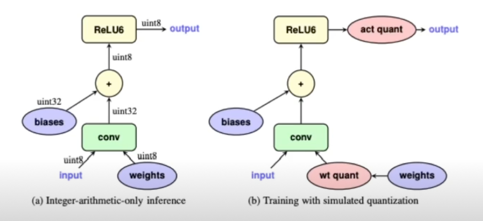
학습 과정
- 학습 과정 중 quantization 을 적용하고, 다시 floating pont 로 변환함(backprop 을 계산하기 위함)
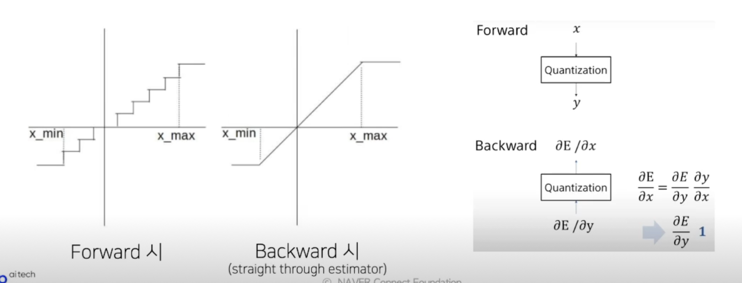
- In-out 에 대한 gradient 를 linear 로 가정(straight-through estimator)함으로써 네트워크 학습을 수행
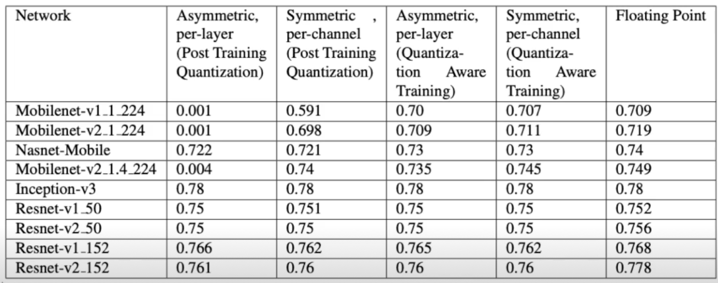
PTQ vs QAT 성능 비교
- Per channel(채널 단위), Per layer(레이어(텐서 단위))
- Asymmetric/Symmetric; zero point 유/무
2. Quantization 실습; PyTorch
2.1 Fp16 quantization
기본 모델 셋업
- 예제 용도의 간단한 모델 셋업 with CIFAR10

2.2 Fp16 inference
Fp32 $\rightarrow$ Fp16
- Input data, Model weight tensor 의 dtype 을 fp16 으로 변환(half() 로 간단히 사용 가능)
- 학습 과정에서 또한 Fp16 으로 학습이 가능한데, 이 경우 numerically unstable 한 연산이나 레이어의 일부는 fp32 로 유지하는 Mixed precision 기능을 활용해야함[9]


Fp32 $\rightarrow$ Fp16; 성능, 속도 비교

2.3 Post Training Quantization(PTQ)
PyTorch 에서 요구하는 준비사항

PyTorch 에서 요구하는 준비사항(PTQ, QAT)

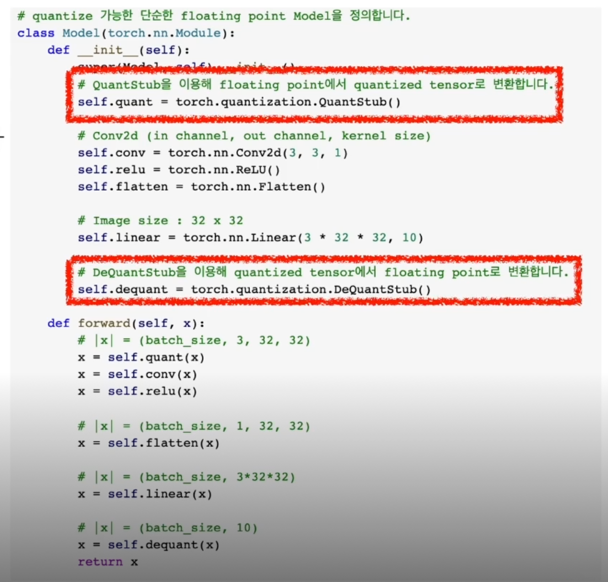
QuantStub, DeQuantStub 추가
__init__함수 내에 QuantStub(), DeQuantStub() 추가- QuantStub():
floating point tensor 를 quantized tensor 로 변환 - DeQuantStub():
quantized tensor 를 floating point tensor 로 변환
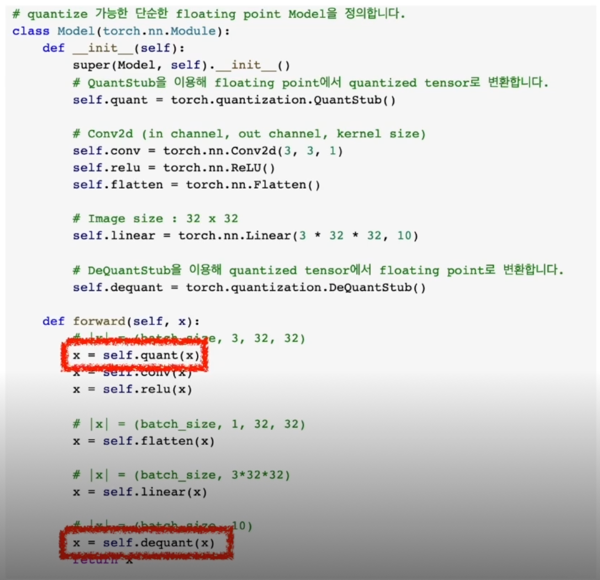
- Forward 함수 내에 모델의 앞 뒤에 선언한 quant, dequant 함수를 추가
PTQ 적용 과정 설명
1) Quantization configuration 을 수행(backend; X86 CPU: fbgemm, ARM CPU: qnnpack)
 2) fuse_modules 적용 및 prepare 수행
2) fuse_modules 적용 및 prepare 수행
 3) Calibration 수행
3) Calibration 수행
 4) Convert 수행
4) Convert 수행

예제 모델 적용 결과

QAT 적용 과정
1) Quantization configuration 을 수행(backend; X86 CPU: fbgemm, ARM CPU: qnnpack)
 2) fuse_modules 적용 및 prepare_qat 수행
2) fuse_modules 적용 및 prepare_qat 수행
 3) 모델 학습(QAT) 수행
3) 모델 학습(QAT) 수행
 4) Convert 수행
4) Convert 수행

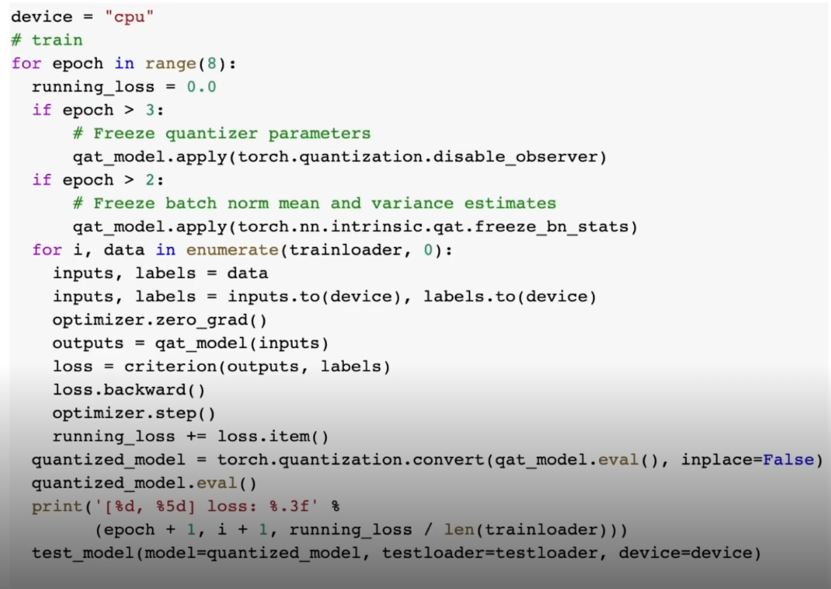
QAT 적용 과정; train 함수 snippet
- PyTorch(v1.8)에서 QAT 의 경우 cpu 만 지원을 하는 상태. 따라서, Fine tuning 정도로 사용하는 경우가 대다수(epoch 10 이내)
- Epoch 3 초과부터는 quantization parameter 를 고정
- Epoch 2 초과부터는 bn stats 을 고정
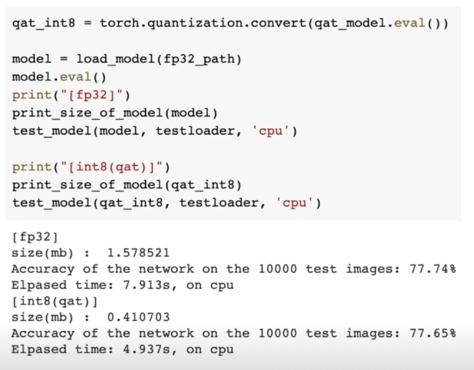
- Evaluate 시에는 quantization.convert를 수행하여 측정함을 주목
QAT 결과 예시
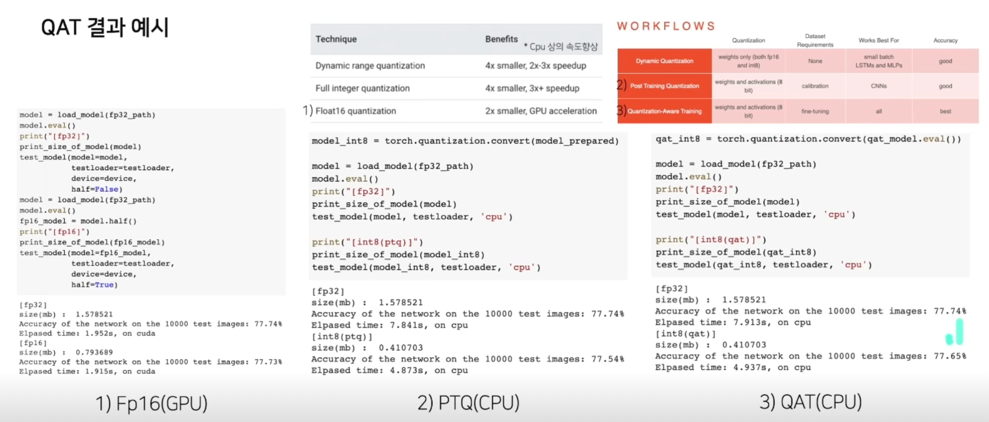
논의
- 모델이 사용될 target device 에 따라 적용할 방법이 달라질 것
- 일반적인 gpu 환경에서 쉽게 속도 및 용량에 대한 개선을 필요로 한다면 fp16 변환을
(+ 학습도 빠르게하고자 한다면 Mixed Precision) - CPU 에서 inference 를 하고자 한다면, fixed point quantization 은 거의 필수적
- Dynamic $\rightarrow$ PTQ $\rightarrow$ QAT 순으로 성능 하락의 폭은 줄어들지만, 더 더욱 많은 조건 및 작업이 추가됨
- 특히 PyTorch 의 경우 quantization 에 대한 지원이 완벽하지 않아 제대로 동작하지 않는 경우들도 존재
댓글남기기