Day_83 01. 학습 파이프라인 최적화 및 마무리
작성일
학습 파이프라인 최적화 및 마무리
1. TensorRT
1.1 TensorRT 소개
Overview
- 학습된 딥러닝 모델을 최적화하여 Nvidia GPU 상에서 Inference 속도를 크게 향상시키는 모델 최적화 엔진
- 다양한 Framework 를 지원
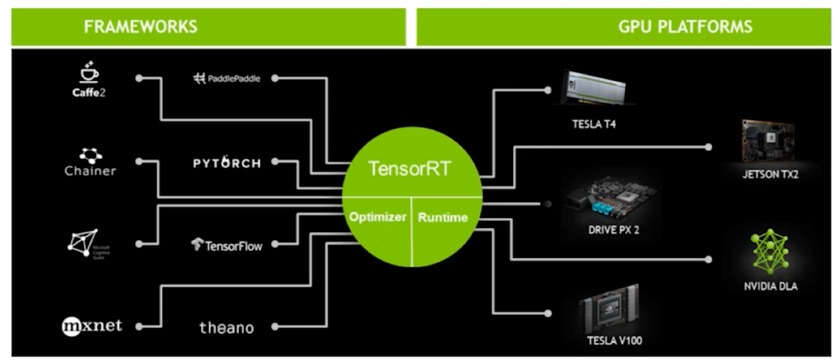
모델 최적화 과정?
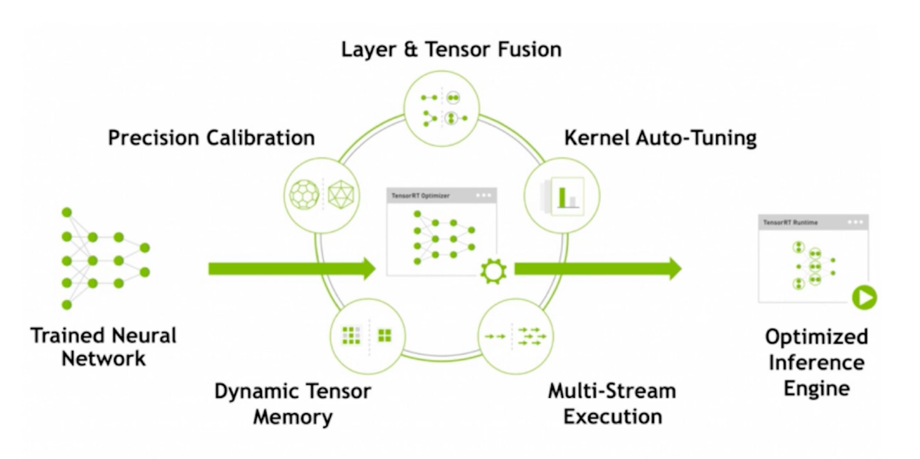
모델 최적화 과정?; 1) Precision Calibration
- 앞서 살펴보았던 quantization 기법
- TRT 의 경우 fp16, int8(PTQ, symmetric quantization)을 지원
entropy quantization 기법이 TensorRT 에서 적용되어 구현되어있음
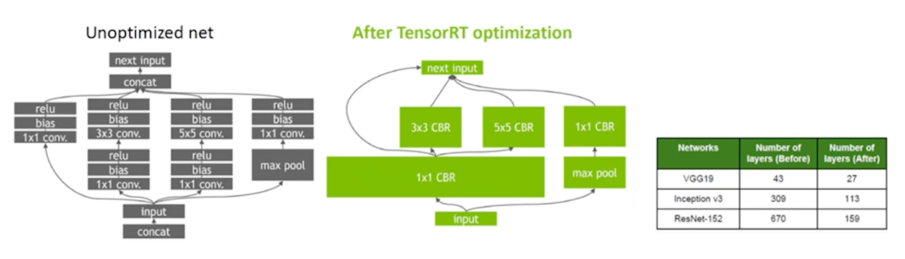
모델 최적화 과정?; 2) Graph optimization
- 1강에서 잠시 언급된 내용
- Platform 에 적합한 layer fusion 을 수행
모델 최적화 과정?; 3) Kernel Auto-tuning
- Nvidia platform 및 architecture 에 맞는 Runtime 생성을 수행
(CUDA engine 갯수, architecture, 등등을 고려)
1.2 TensorRT conversion
Overview
- PyTorch 에서 TensorRT 로의 변환은 일반적으로 ONNX 를 거쳐서 수행됨
(TRtorch: TorchScript $\rightarrow$ TensorRT 의 변환 방법 또한 존재) - ONNX(Open Neural Network Exchange): 서로 다른 딥러닝 프레임워크에서 생성된 모델이 상호 호환될 수 있도록 도와주는 프레임워크

ONNX
- 각 프레임워크들은 고유한 그래프 표현(ex: TF; static graph, PyTorch; dynamic graph)을 가지고 있지만, 모두 유사한 기능을 제공
- 그래프의 공통된 표현(operator)를 제공하여 프레임워크 간의 변환이 가능하게 하고자 함
- 각 프레임워크들 또한 활발하게 개발되고 있어, 버전에 따른 coverage 가 계속하여 변하는 중
(e.g. PyTorch 의 일부 레이어는 미지원, 최신 onnx 와 구부전 onnx 의 호환성 차이 등등)
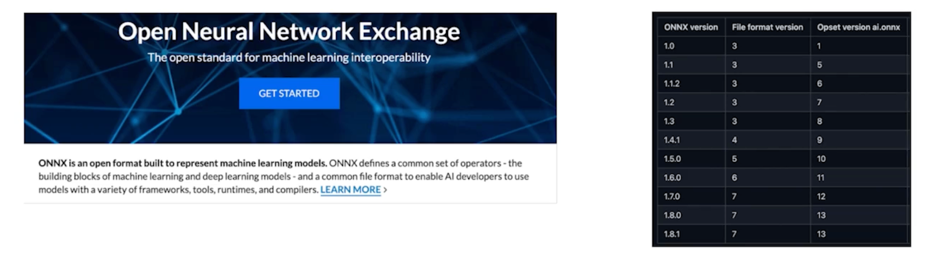
1.3 PyTorch $\rightarrow$ ONNX
PyTorch $\rightarrow$ ONNX
- PyTorch 에서 official 하게 onnx export 를 지원 (https://pytorch.org/docs/stable/onnx.html)
- But, 지원되는 opeartor 에 대한 숙지가 필요함[3]
- 변환 시, 모델의 입력 데이터 크기를 넘겨주어 이를 명시적으로 지정해주어야 함


1.4 TensorRT 실습 overview
TensorRT 구동 환경
- 도커를 활용한 가상환경 내 구성[6]
- 도커 구동 관련 수요가 있다면 별도 세션에서 다룰 예정

- Release note[7] 에서 TensorRT, CUDA, CUDNN 등의 라이브러리들의 변경이 있을때 새로운 버전이 업데이트
- 도커 이미지 구동 시 driver requirement(Nvidia driver version)등을 잘 확인할 것
(e.g. 도커가 구동되는 host 환경의 드라이버 버전에 따라 CUDA version 의 상한이 결정됨)


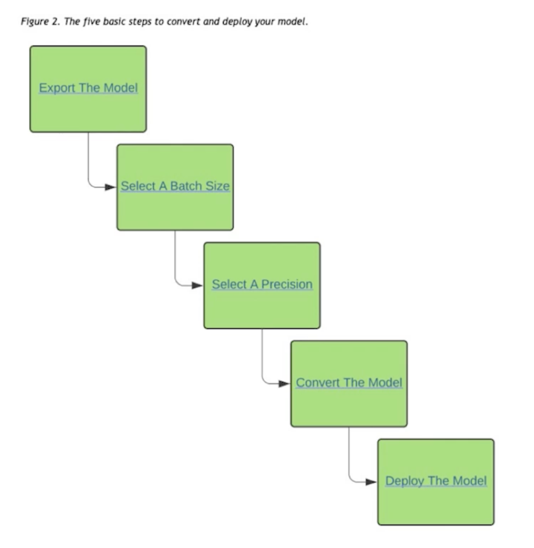
TensorRT 변환 과정 Overview
- 기본적으로 아래의 5단계를 거침
- 모델 준비(실습에서는 .onnx)
- Batch size 설정; batch size 에 따른 최적화 수행
- Precision 설정; float32, float16, int8
- 모델 변환; .engine
- 모델 deploy
1.5 ONNX $\rightarrow$ TensorRT; 방법 1. CLI(trtexec)
CLI(Command Line Interface); trtexec
- TensorRT 에서 제공해주는 CLI 툴, 별도의 코드 없이 아래 기능을 제공
- Random data 를 통한 모델 벤치마크(속도)
- TensorRT Engine 으로 모델(Caffe, UFF, ONNX) 변환

- 구동 예시

- 구동 결과 1. 상세 옵션 표시
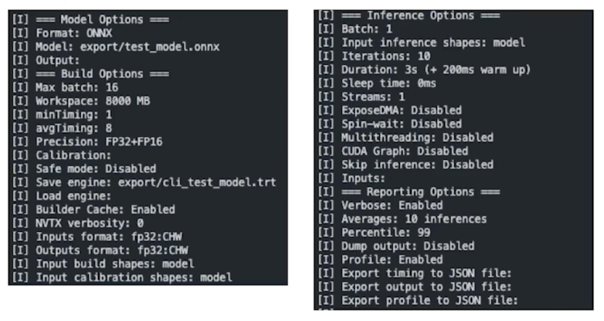
- 구동 결과 2. Inference test
설정해둔 횟수만큼 latency 를 계산(+throughput)
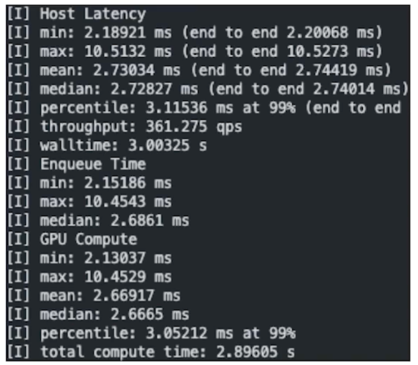
- 결과 비교(fp32, fp16, int8)
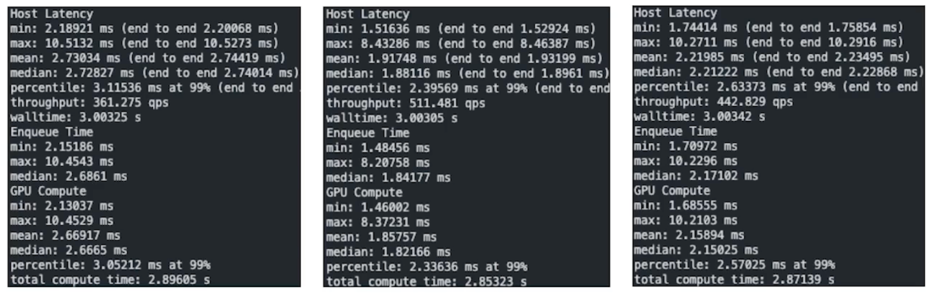
실제로 활용을 해보면 적당한 크기의 batch size 에서는 fp16 이 int8 보다 더 성능이 잘나옴
batch size 가 많이 커지면 int8 이 상회하는 지점이 나오게 됨
1.6 ONNX $\rightarrow$ TensorRT; 방법 2. API
API 를 통한 변환
- 변환 과정은 동일하게 수행됨
- cli 에서 argument 형태로 넘겨주었던 세팅을 코드 내에서 설정해주게 됨
- Int8 calibration 셋업(calibration 이미지)를 더 명확하게 설정할 수 있음
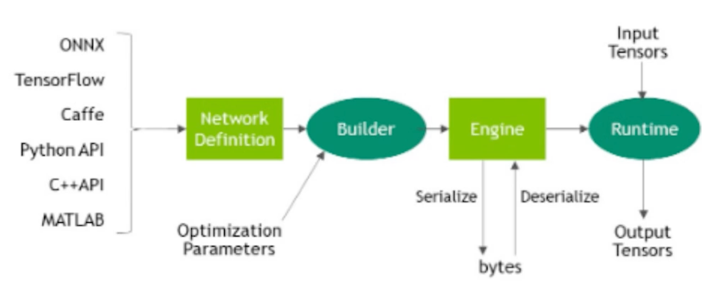
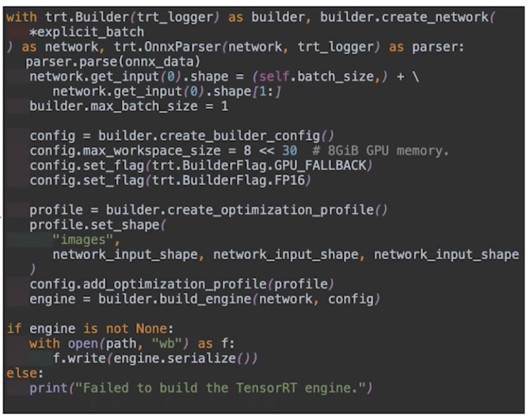
ONNX $\rightarrow$ TensorRT
- TensorRT 변환 준비
- 변환된 ONNX 모델 load
- Batch size, 모델 입력 데이터 크기 설정
- TensorRT 로거 세팅(디버깅 목적)
- 변환 관련 class
- builder: 모델 변환
- network: 모델 정의
- parser: ONNX 모델 parser 파싱된 모델을 network 로 전달
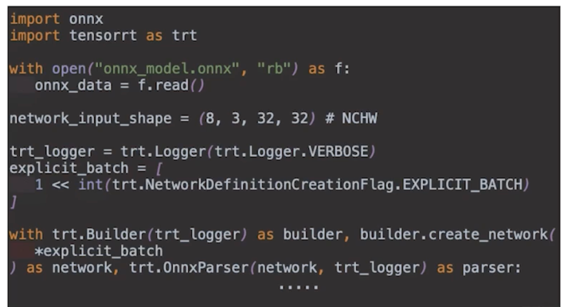
- 모델 변환 파라미터 설정
- GPU 최대 메모리할당량 설정
(max_workspace_size) - Fp16 변환 플래그 설정
- 모델 최적화 프로파일링 설정
(set_shape)
- GPU 최대 메모리할당량 설정
- 모델 변환
- Network 와 config 를 builder 에게 전달하여 TensorRT 모델 변환
(모델 최적화 수행과 동시에 각 GPU 에 최적화된 연산자를 이용하도록 변환됨)
- Network 와 config 를 builder 에게 전달하여 TensorRT 모델 변환
- Int8_calibrator(레포 내 int8_calibrator.py)
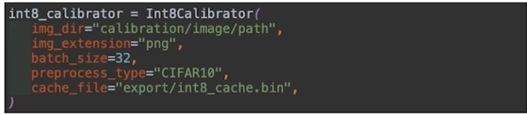
- Int8 calibration(entropy)을 위한 이미지 필요(학습 이미지 내 1,000장 샘플)
- cache_file 이 없는 경우 img_dir 내의 이미지를 통하여 calibration 을 수행하고, cache 를 생성
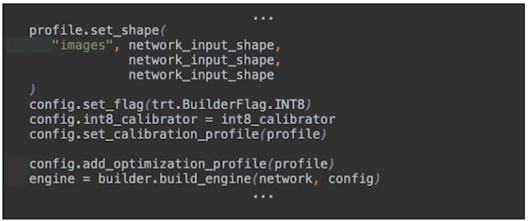
-
Config 내에 int8 flag 와 int8_calibrator 를 설정
- Repo 에 전체 코드가 포함되어 있음
- 부족한 일부 설명의 경우 API Documentation 을 참고해주세요
- 더해서 TensorRT 레포[15]의 튜토리얼 또한 따라해보시면 좋습니다

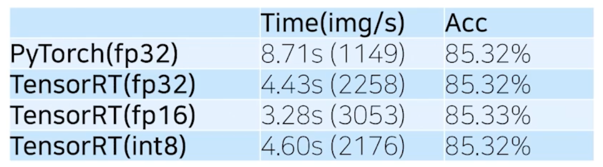
ONNX $\rightarrow$ TensorRT; 결과
- MobileNet v3, Cifar10(32, 32), batchsize: 64
- Pytorch Dataloader 활용
- Time 은 단순하게 iterator(for loop) 앞뒤로 측정(=부정확)
*(int8)의 경우 batch size 가 더 커지면 속도에서 이득이 있을 것이라 예상
1.7 정리 및 논의
쓰지 않을 이유가 없는 TensorRT
- Nvidia 플랫폼이라면 deployment 단계에서 TensorRT 는 거의 선택이 아닌 필수
- Quantization 등의 기법도 비교적 쉽게 적용이 가능
- 라이브러리 버전, 모델 구조 호환성 등의 이슈가 일부 있음
DALI(Data Loading Library)
2.1 DALI 소개
Overview; Motivation
- CPU, GPU 간의 연산 capacity 의 차이가 심화됨
- 데이터의 preprocessing(input data load, augmentation)의 복잡도는 계속하여 높아지는 추세
- 일반적으로 CPU 상에서 전과정이 이루어지고 있는 Preprocessing 에서 가능한 연산들을 GPU 에서 수행
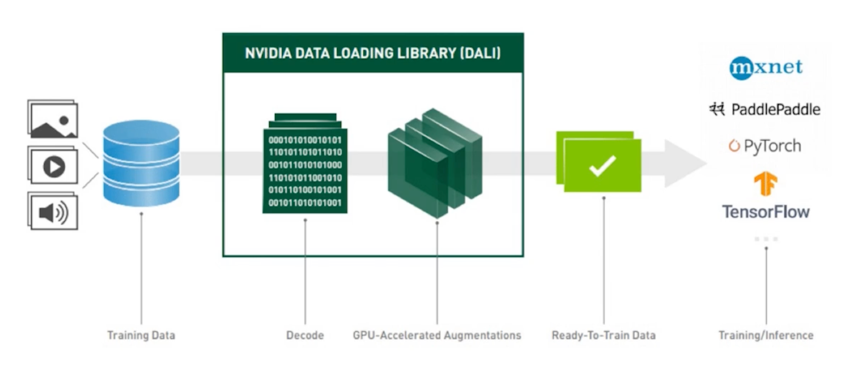
Overview; 이미지 처리 과정 예시
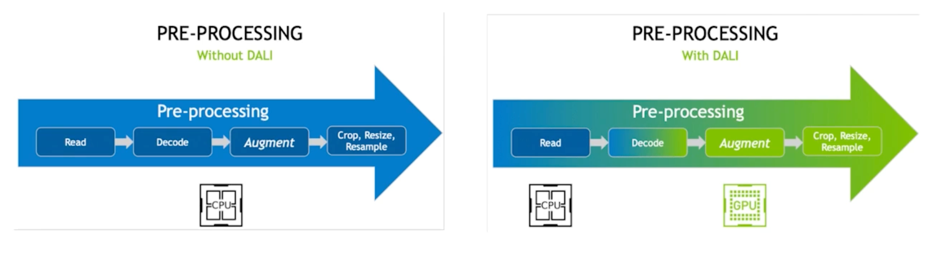

Data Feeding 해주는 곳도 bottleneck 이 있을수 있다라고 봄
- 보편적으로 사용되는 augmentation 기법들이 이미 구현되어 있음

2.2 예시를 통한 DALI API 설명
파이프라인 구성
- 그래프 기반의 구동 방식, 내부 과정을 sequential 하게 구성
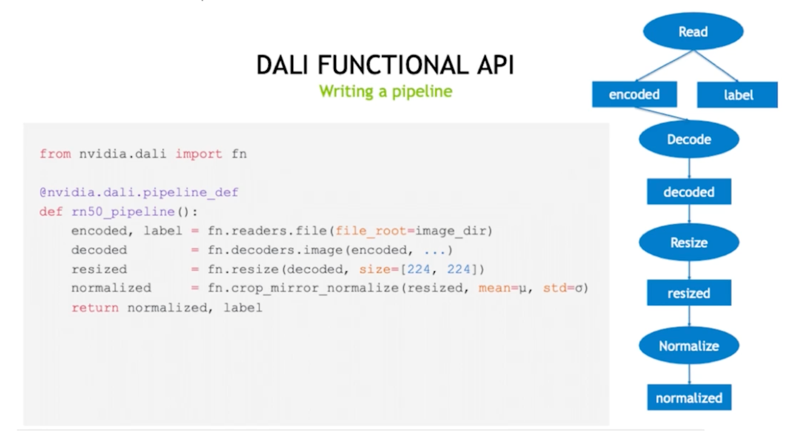
Build & Run
- 함수 콜을 통하여 object 를 생성하고, build 후 run 하는 방식

GPU offloading

초록색을 GPU 가 연산하는 영역이라고 생각하면 됨
2.3 PyTorch with DALI 실습
Overview: Dataloader 를 대체가능하게 iterator 를 제공
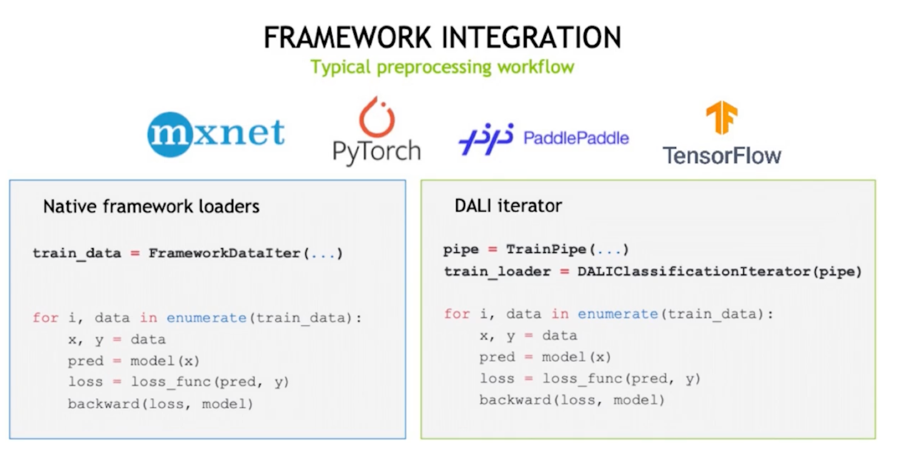
Overview
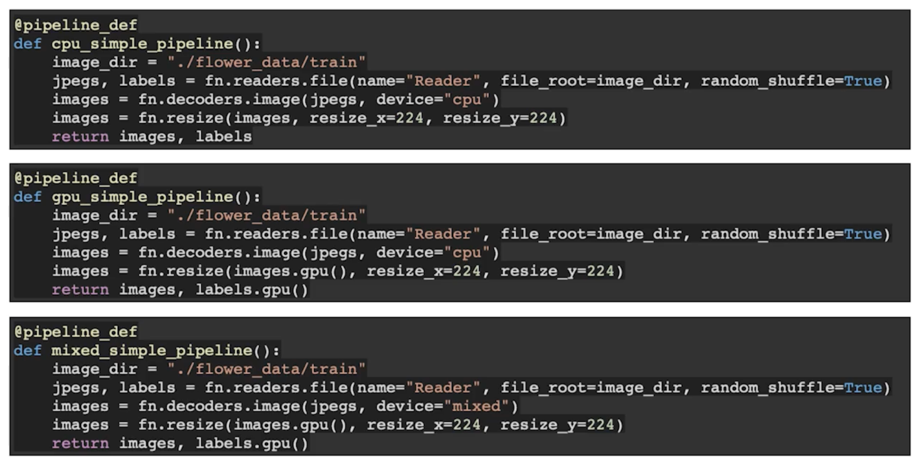
- 102개의 클래스를 가지는 Flower dataset 을 활용(클래스당 40~258장)
- Dataloading 비교
- 기타 augmentation 없이 resizing 만 수행 (224, 224)
- Training & Inference time 비교
- Resnet18 pretrained, FC layer 교체
- Dataloading 비교
앞에서 많이본 pipeline
Dataloading 속도 비교(with PyTorch Dataloader)
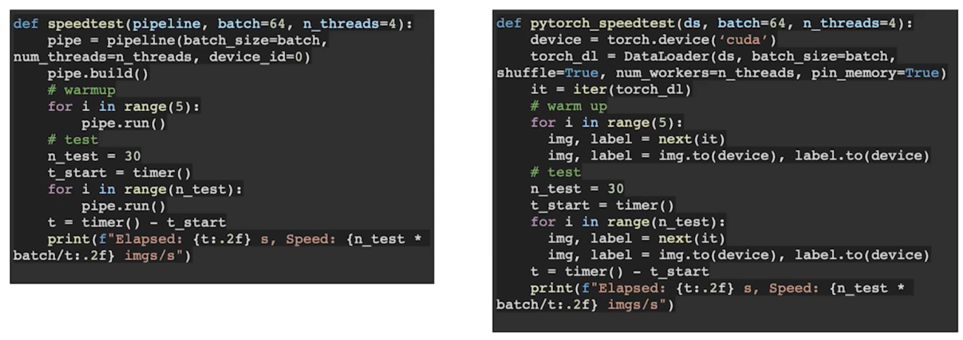
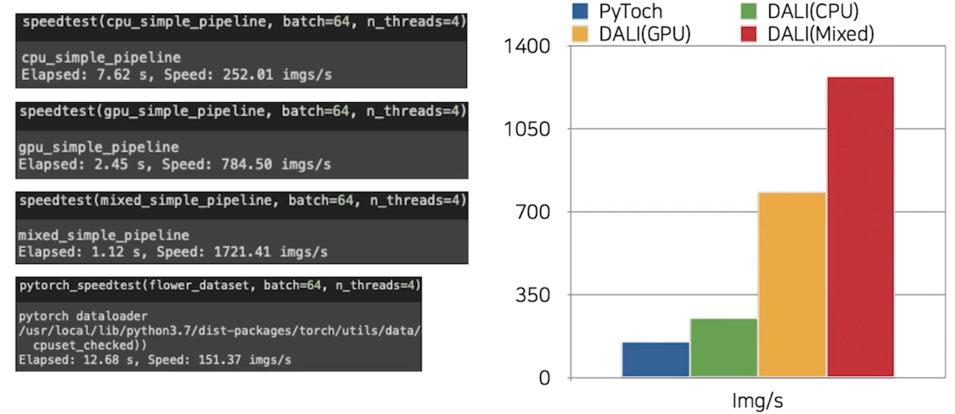
DALI 가 확실히 빠름 특히 mixed 할 때 가장 빠름
Training & Inference time 비교
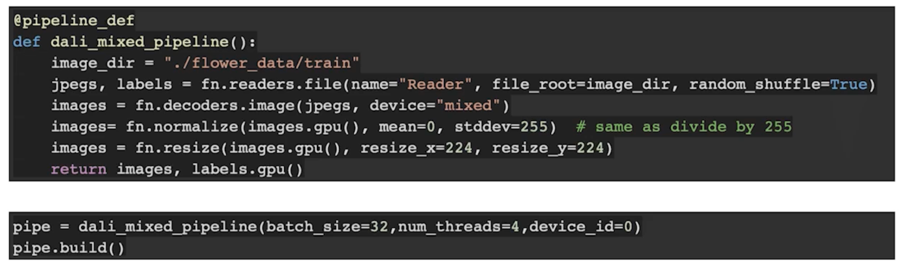
- DALI Pipeline 생성 및 빌드
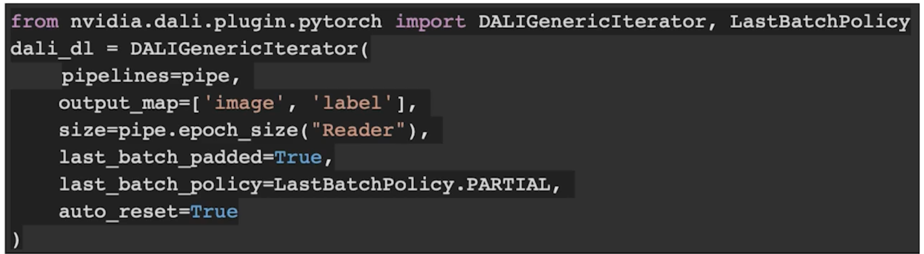
- DALI Dataloader(Iterator 생성)
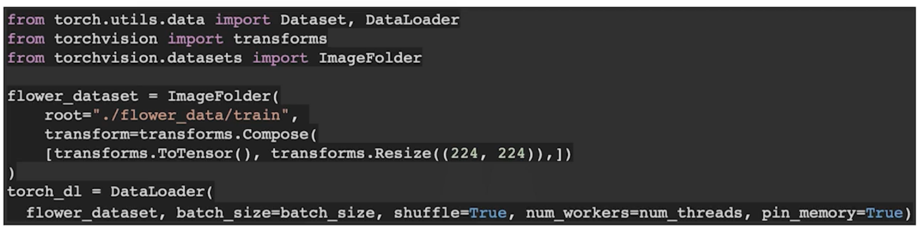
- Torch dataset, dataloader 생성
- 학습 코드
- Inference 코드
- 결과
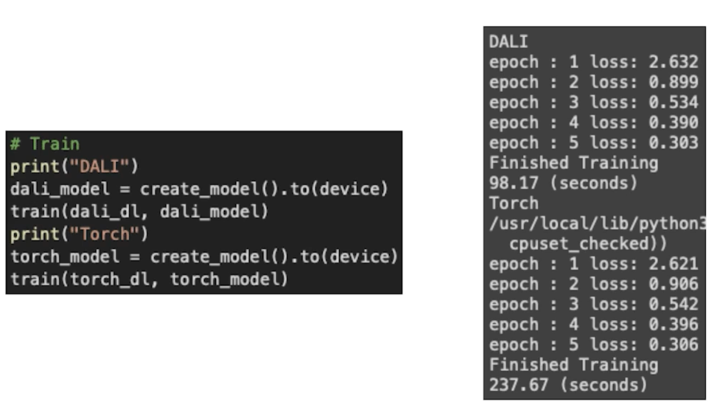
속도가 상당한 차이가 있음
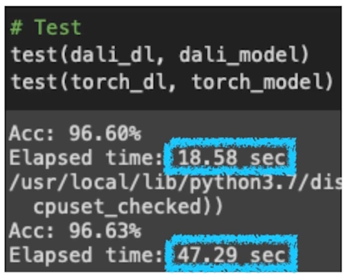
2배 이상의 속도개선을 Dataloader 만 바꿔도 볼 수 있음
2.4 정리 및 논의
속도 향상에는 탁월, 그러나?
- 학습 시간(+Inference 시간)을 1/2 이하로 줄일 수 있는 매우 매력적인 선택지
- TensorRT 와 DALI 를 활용하면 매우 빠른 inference 를 비교적 쉽게 구현 가능
- Define and run 기반이기 때문에, RandAug 과 같이 가변적인 기법은 아직 적용이 불가(Eager 지원 예정)
- Predefined 된 augmentation 을 활용한다면 좋을 라이브러리
댓글남기기