Day_75 04. 작은 모델, 좋은 파라미터 찾기: AutoML 실습
작성일
작은 모델, 좋은 파라미터 찾기: AutoML 실습
1. Overview
1.1 Review
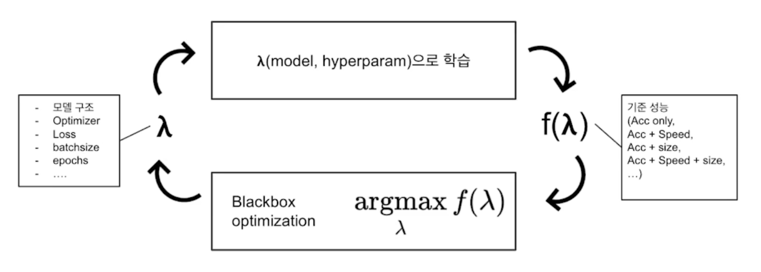
AutoML: 기준 성능을 잘 만족하는 적절한 모델, 파라미터 탐색

소요 시간과 scalability 등의 현실적 문제
1.2 Objective
지난 강의: 충분히 좋은 configuration 찾기
- 어느정도의 prior 를 개입, 적은 search space 를 잡고,
- 적지만, 대표성을 띄는 좋은 subset 데이터를 정하고(+ n-fold Cross validation 등의 테크닉)
- 학습 과정의 profile 을 보고 early terminate 하는 기법 적용
- ASHA Scheduler, BOHB(Bayesian Optimization & Hyperband)
등등의 방법으로 Human in the loop 의 결과보다 “충분히 좋은” configuration 을 찾을 수 있습니다.
Main Focus $\rightarrow$ 어느정도의 prior 를 개입, 적은 search space 를 잡고
2. 코드: Sample 파트
2.1 이론과 코드의 연결
Overview
- Optuna API 활용(https://optuna.org/)
- SOTA 알고리즘 구현, 병렬화 용이, Conditional(⭐️) 파라미터 구성 용이
- 과정 overview
- Optuna Study 생성(blackbox optimizer 및 관리 담당)
- Study 에 최적화할 목적함수 및 시도 횟수, 조건 등을 주고,
- Optimize!

구현(끼워맞추기)
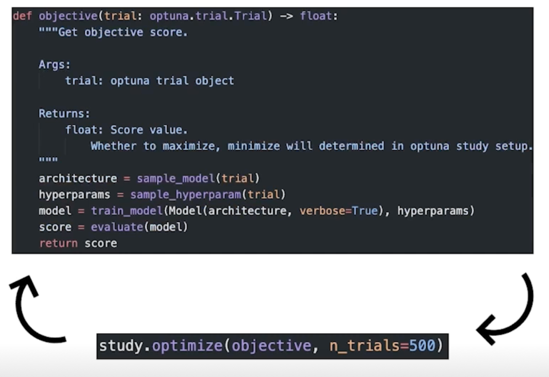
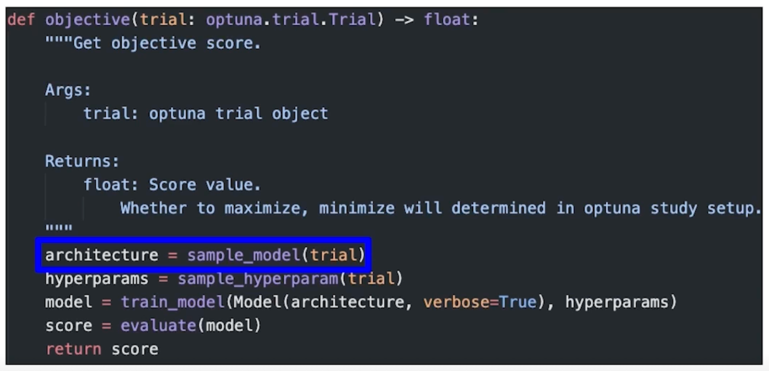
코드로 구현하면
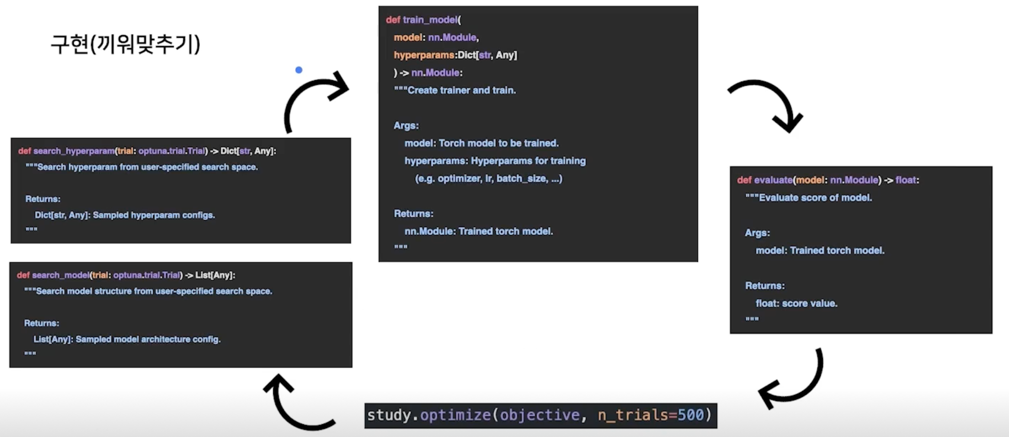
구현(실제)
2.2 Architecture config
다양한 Backbone model
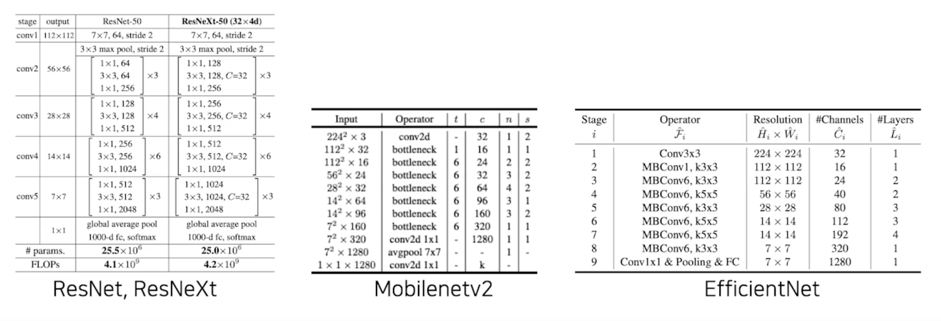
특정 data structure 에 block 들을 넣어서 모델을 “조립” 할 수 있을까? = block 들을 임의로 쌓아서 모델을 “생성” 할 수 있을까?


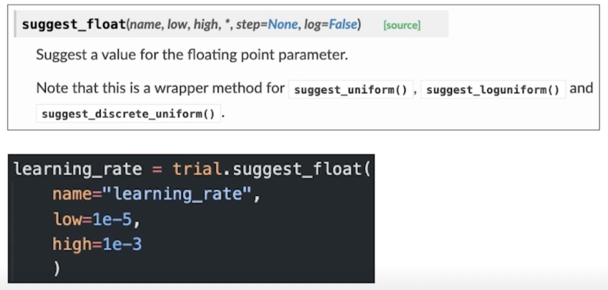
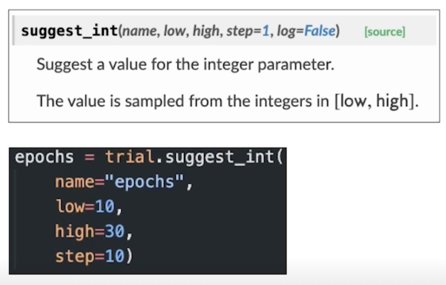
Prerequisite: Optuna search space[1]
- Categorical

- Continuous
- Integer
- Conditional(⭐️)
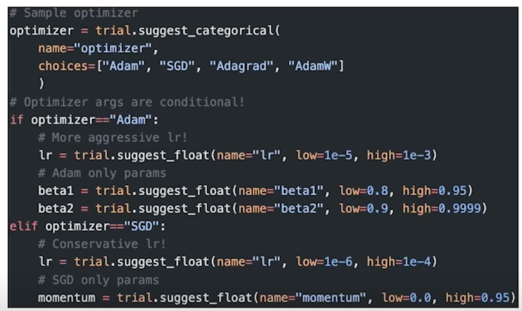
Custom search space 구성하기: 예시

- Research Topic 중 하나인 Neural Architecture Search(NAS) 논문
- 모듈 block 들의 조합 및 구성(macro)을 탐색하는 것이 아닌, 모듈 block(micro)을 탐색하는 것에 초점(주요 연구 방향)
$\rightarrow$ 성능은 좋지만, 아직은 높은 Computational cost -
아래처럼 모듈 block 으로 생성된 네트워크 구조는 고정함
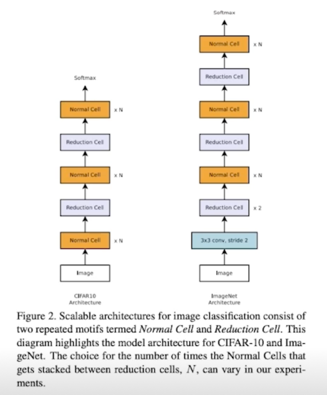
Application 레벨에서는?
이미 나와있는 좋은 모듈 block 들로 + macro 한 구조는 오른쪽 이미지를 차용
예시 1. 나의 작고 이상한 첫번째 model: 고정된 N, NC, RC
-
N, NC, RC 각각 고정 파라미터로 sample, 모델을 구성
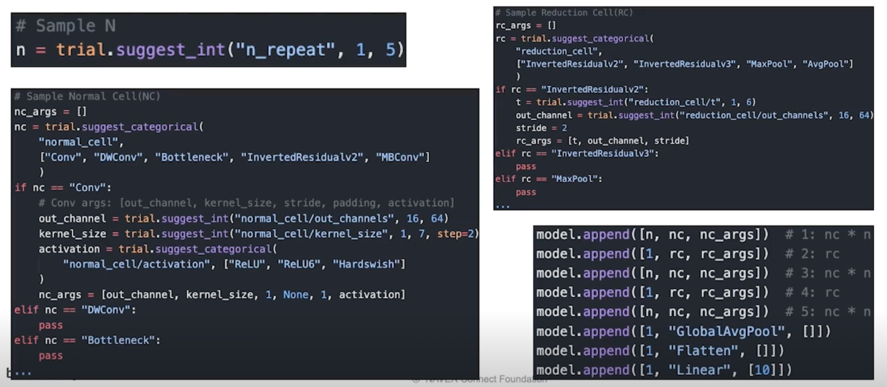
몇번 반복할 건지 N 을 sample 하고 Normal Cell(NC) 을 결정
후보로는 ["Conv", "DWConv", "Bottleneck", "InvertedResidualv2", "MBConv"] 이 중에서 그냥 고를거임
NC 로 “Conv” 가 선택된 경우에는 out_channel 을 16, 64 사이에서 랜덤하게 샘플하고, kernel_size 도 1, 3, 5 중에서 선택하고 activation 도
["ReLU", "ReLU6", "Hardswish"] 중에서 선택
Reduction Cell(RC) 를 만듦
후보로는 ["InvertedResidualv2", "InvertedRedisidualv3", "MaxPool", "AvgPool"] 로 잡아놨음
stride 를 줘서 feature map 을 줄여야하니 stride 를 고정시켜놓되 들어가는 parameter 를 바꾸는 식으로 구현
레이어가 깊어질 수록 더 많은 feature 를 뽑아야 더 잘되지 않나?
$\rightarrow$ N 을 깊어질수록 더 크게 만들자!
-
N, NC, RC 각각 고정 파라미터로 sample, 모델을 구성, N 은 점점 커지게!(1)

-
N, NC, RC 각각 고정 파라미터로 sample, 모델을 구성, N 은 점점 커지게!(2)
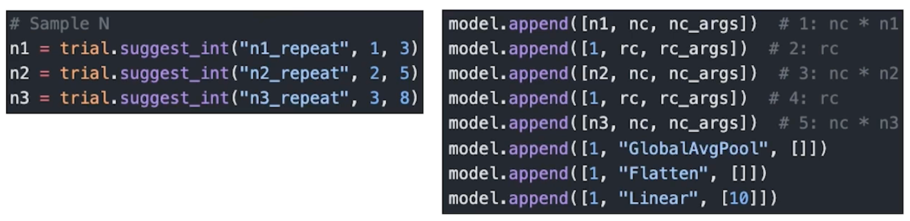
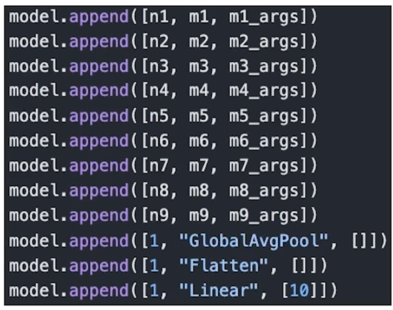
예시 2. 나의 N 번째 model: 가변, N, NC, RC
-
동일한 방법으로 탐색의 범위를 넓힐 수 있음
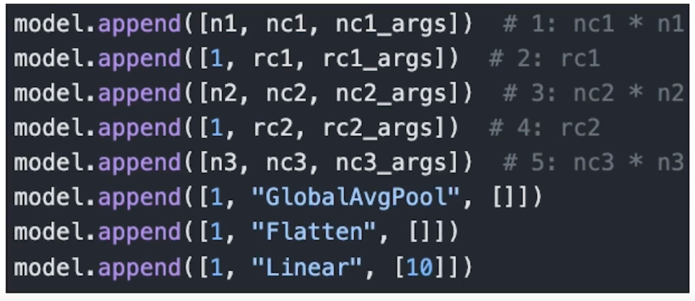
예시 3. 나의 N + 1 번째 model
-
(형식과 조건만 맞추면) 더욱 자유로운 모델도
2.3 Hyperparam config
이제는 sampling 에 친숙할 때
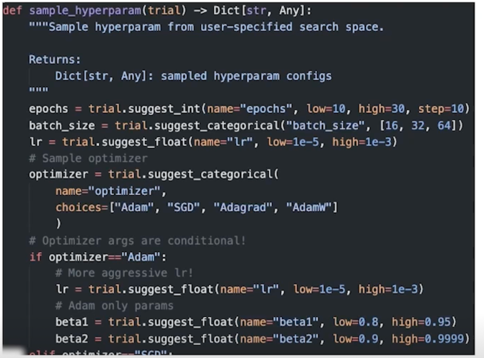
고정할 것은 고정, 원하는 변수는 자유롭게 추가
3. 코드: Parse 파트
Config 로부터 모델과 학습 파라미터를 셋업하는 코드를 살펴봅니다.
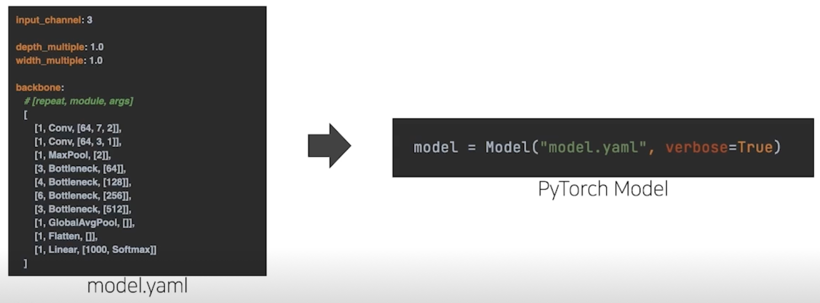
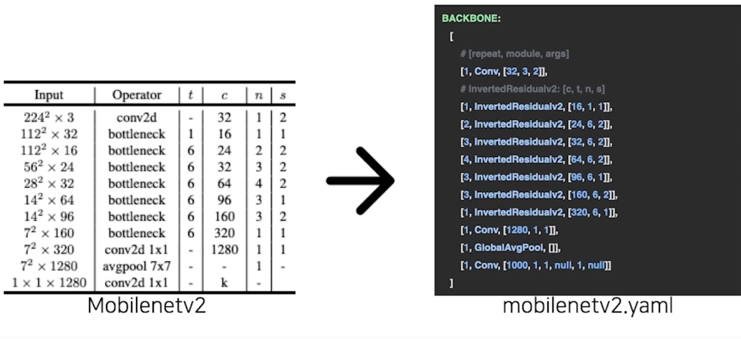
3.1 yam 에서 Model 만들기 구조
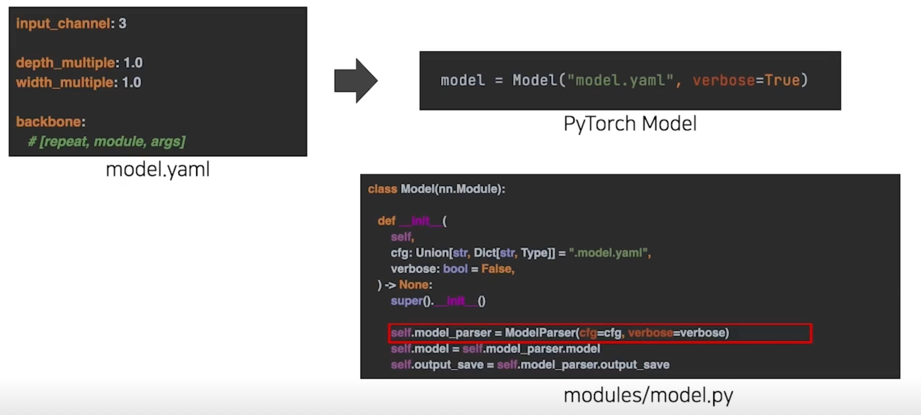
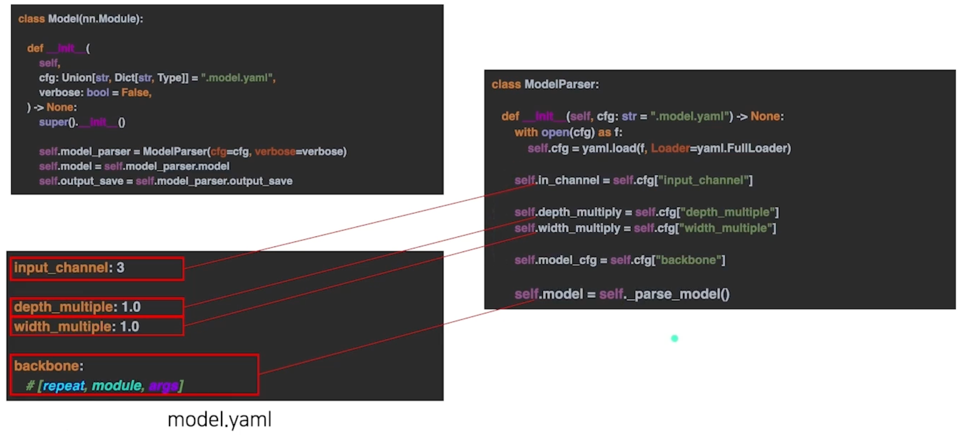
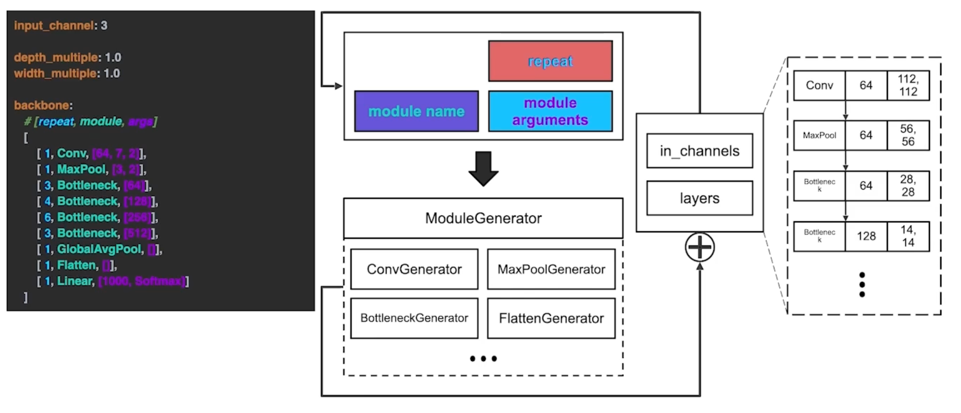
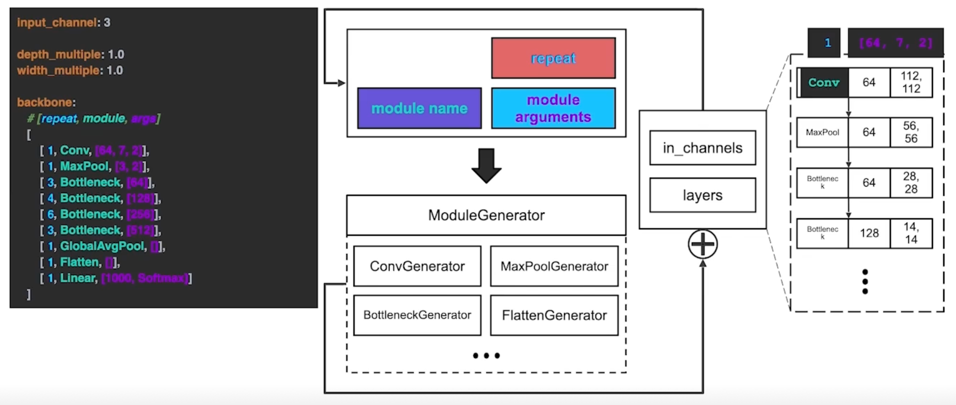
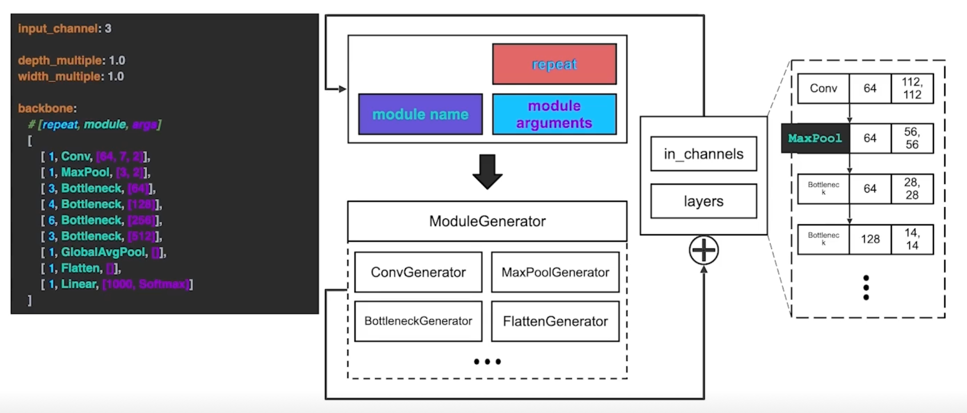
3.2 yaml 에서 Model 만들기 parsing 코드
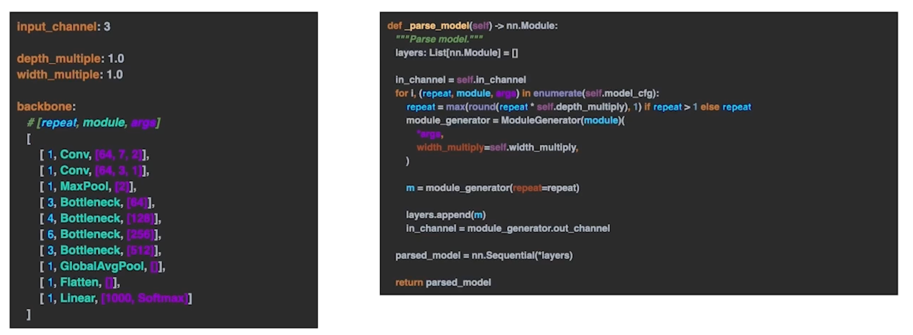
3.2 yaml 에서 Model 만들기 parsing 코드 - 반복 횟수
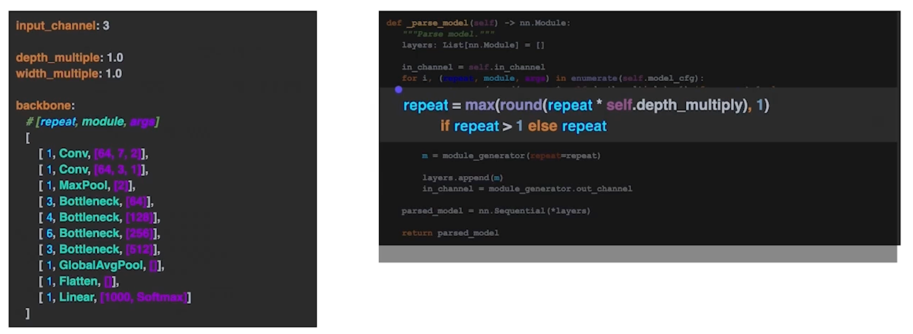
depth_multiply : 깊이를 조절하겠다는 의미
3.2 yaml 에서 Model 만들기 parsing 코드 - 모듈 생성기

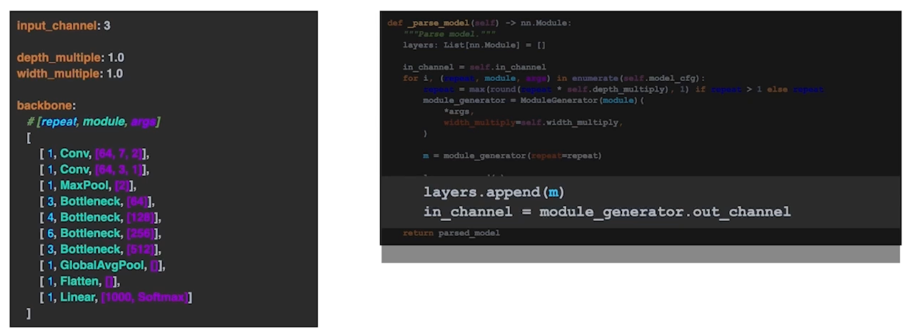

4. 코드: 모듈 추가하기
4.1 모듈 파트 구조
File Tree
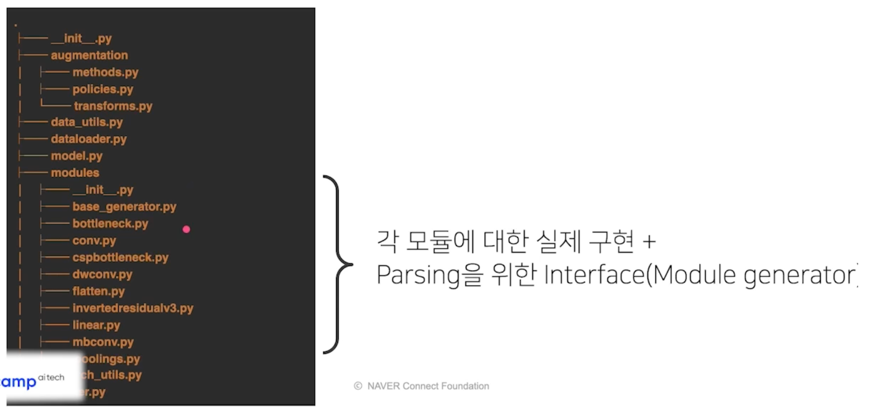
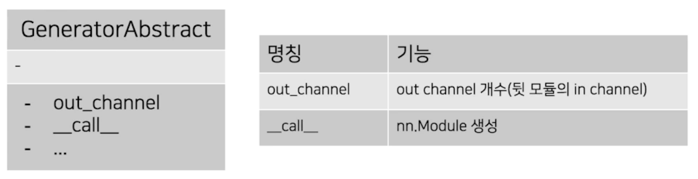
Module generator(Interface 또는 abstract class)
-
각 모듈을 parsing 하기 위해서 필요한 최소 기능 구현
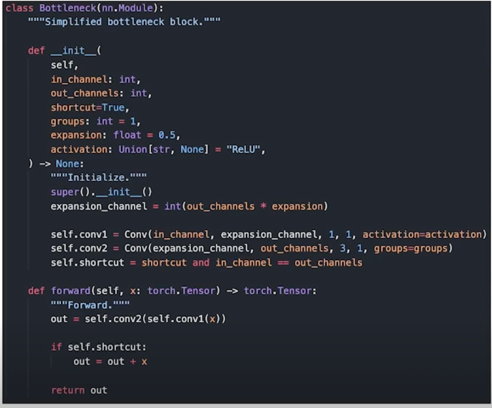
4.2 모듈 파트 예시: Simplified Bottleneck
Bottleneck.py 예시: 1. 모듈 구현
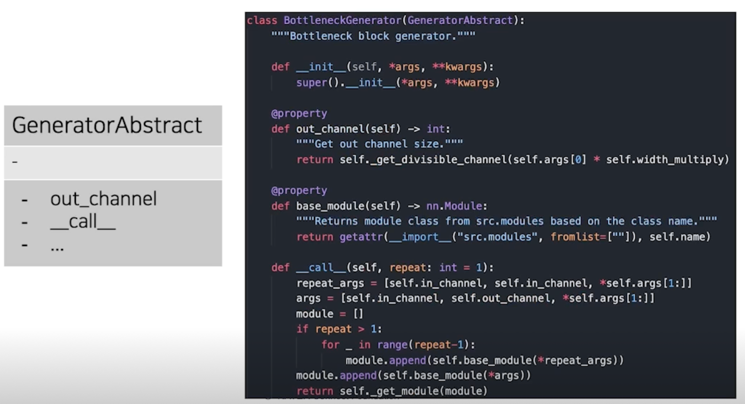
Bottleneck.py 예시: 2. ModuleGenerator
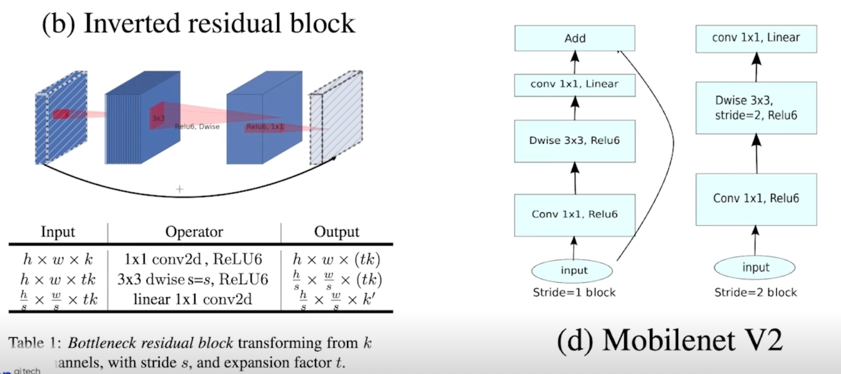
4.3 모듈 추가하기: Inverted Residual v2
모듈 추가 과정
-
구현체 추가(https://github.com/pytorch/vision/blob/master/torchvision/models/mobilenetv2.py)
-
Module generator 인터페이스 작업

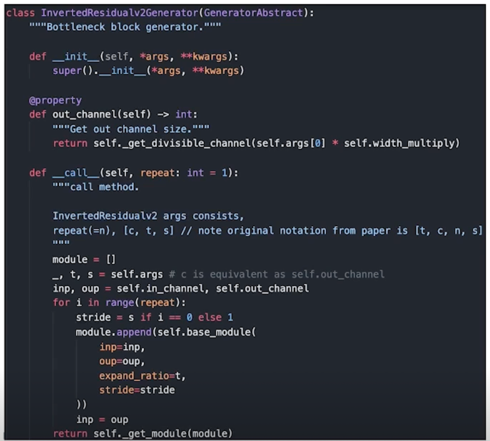
-
__init__.py에 추가(생략)
댓글남기기