Day_75 02. 대회 및 데이터셋 소개
작성일
대회 및 데이터셋 소개
1. 대회 소개 & FLOPs
1.1 대회 목표
경량화를 평가하기?
- 경량화의 다양한 관점; 어떤 것에 포커스를 둘까에 따라…
- 모델 크기(=파라미터 수)가 작으면?
- 속도가 빠르면?
- 연산횟수(MACs($\simeq$0.5FLOPs))가 작으면?
- 직접적으로 Inference 속도를 대회 기준으로 결정
- Task 는 비교적 익숙한 Image Classification; 경량화에 집중!
1.2 대회 평가 기준
성능이 좋으면서 Inference 속도가 가장 빠른 모델 찾기

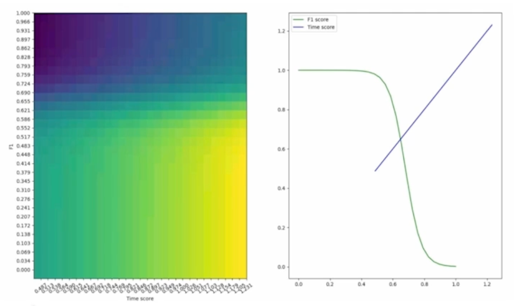
1.3 FLOPs 에 대해서
모델 최적화, 경량화 논문들에서 자주 언급되는 metric: FLOPs
- 연산속도를 가장 중요한 기준으로 볼 때, 연산횟수(FLOPs)는 속도 결정의 간접적인 factor 중 하나
-
어느정도의 경향성을 나타내기는 함
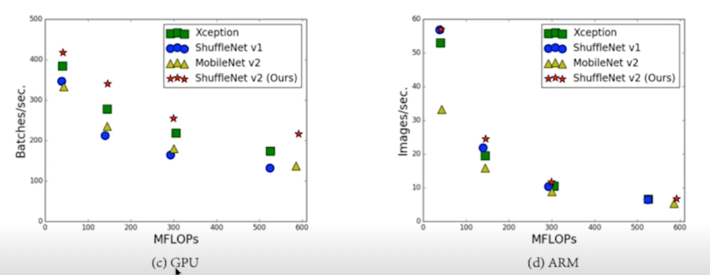
연산 횟수는 속도에 영향을 주는 간접적인 요소 중 하나
- Memory Access Cost 와 같은 다른 중요한 요소들 또한 존재
- 모델의 구조로 오는 병렬성 등은 고려하지 못함
- 더해서 HW platform 마다 동일 연산 간의 속도 차이도 존재
추천 논문: ShuffleNetv2, 속도에 영향을 주는 요소에 대한 insight
- FLOPs 이외에 Memory Access Cost 등의 관점에서 속도에 영향을 주는 요소를 추가로 고려
- 4가지의 가이드라인을 제시
- 입 출력의 채널 크기가 동일할 때 Memory Access Cost 가 최소
- 큰 Group convolution 은 Memory Access Cost 를 증가
- 여러 분기의 path 가 나오는 구조는 병렬화에 악영향
- Element-wise operation 은 무시하지 못할 비중을 가짐

2. Dataset 소개
2.1 TACO(Trash Annotations in Context Dataset)
TACO: 대회용 데이터셋의 reference
- 쓰레기 이미지의 label 과 bbox, segmentation 이 포함된 open image dataset
-
COCO format 으로 제공됨

COCO 데이터셋을 그대로 쓰지 않고 reference 로 사용
2.2 대회용 Dataset 소개
국내용 데이터
- Level 2 CV P-stage Object detection/Segmentation 에서 사용한 데이터와 동일
- 국내에서 발생한 쓰레기에 총 6개의 category 로 분류된 데이터(COCO format)
2.3 Task 소개
경량화에 집중!
- Object detection task 를 위해 제작된 데이터셋, 하지만 Object detection 에 경량화를 적용하는데에 더 많은 시간과 노력이 필요
- “경량화”라는 취지에 더욱 집중하기 위해, Bounding box 를 crop 하여 classification 문제로 완화하기로 결정
-
일부 Data 를 customizing 하였음(후에 설명)

3. EDA 및 데이터셋 생성 과정
3.1 간단 EDA
Category 분석
- 총 6개의 Category
- Train + Valid : 20851
- Test : 5217
- Private : 2611
- Public : 2606
-
Train + Valid 데이터셋에 대해 상위 3개의 category 가 전체의 약 79%를 차지
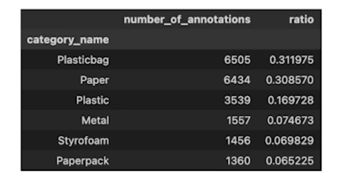
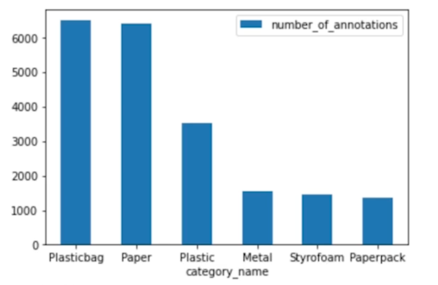
어느 정도 Imbalance 가 있지만 심하진 않다
3.2 레이블 별 Cropped image 예시
- Metal

- Paper

- Paper pack

- Plastic

- Plastic bag

- Styrofoam

총 6개의 레이블로 구성
3.3 분류 문제로의 customizing
Cropped image 데이터셋의 문제점
- Overlap 되는 이미지 다수 존재
- Aspect ratio 가 지나치게 불균형한 데이터 존재
Overlap 예시

몇가지 Customizing 을 통한 완화
- 기존 Dataset 에서 General Trash, Battery 등 불균형 심한 Class 제거
- IoU 40% 이상의 Cropped 이미지의 경우 둘 중 큰 이미지는 제거
- 특정 비율 이상의 심한 Aspect Ratio 의 이미지 제거
데이터 정제, Labeling 등의 중요성은 이전 대회들에서 너무너무 중요하지만 이 대회에서는 “모델 최적화”에만 집중!
댓글남기기