Day_76 01. 작은 모델, 좋은 파라미터 찾기: Data Augmentation & AutoML 결과 분석
작성일
작은 모델, 좋은 파라미터 찾기: Data Augmentation & AutoML 결과 분석
1. Overview: Image augmentation
1.1 Introduction
Data Augmentation
- 기존 훈련 데이터에 변화를 가해, 데이터를 추가로 확보하는 방법
- 데이터가 적거나 Imbalance 된 상황에서도 유용하게 활용 가능
- 직관적으로는 모델에 데이터의 불변하는 성질을 전달 $\rightarrow$ robust 해짐
- ex) 강아지 이미지는 “회전해도”, “늘려도”, “일부분만 보여도” 강아지 이미지
- 데이터의 종류마다 Augmentation 의 종류, 특성은 달라질 것
- ex) 음성, 정형데이터, 이미지, …
- 뒤의 내용은 이미지 데이터의 augmentation(image augmentation)에 대해서만 논함
경량화, AutoML 관점의 augmentation?
- 경량화 관점에서는 직접적으로 연결이 되지는 않으나, 성능 향상을 위해서는 필수적으로 적용되어야하는 기법
- Augmentation 또한 일종의 파라미터로, AutoML 의 search space 에 포함이 가능한 영역
Object detection 에서의 대표적인 Augmentation 기법들


- 실제 데이터에서는 보통 이보다 더 큰 효과를 얻음
1.2 Image augmentation list-up
Image classification 에서의 대표적인 Augmentation 기법들

ShearX(Y)
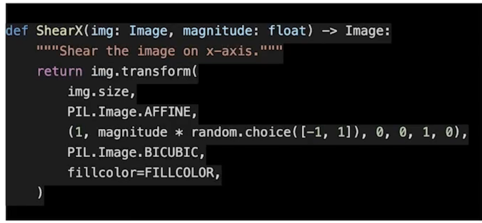
magnitude * random.choice([-1, 1]) 이 값에 의해서 양수면 오른쪽으로 음수면 왼쪽으로 비틀림
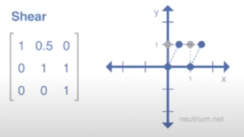
한쪽 축방향으로 이미지를 비튼다고 보면

TranslateX(Y)
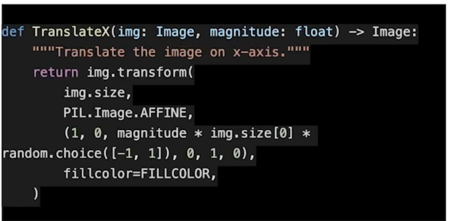
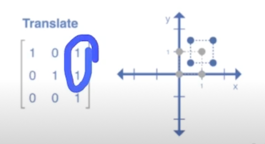
위에가 X 방향, 아래가 Y 방향

실제이미지가 특정 방향으로 이동된걸 확인할 수 있음
Rotate
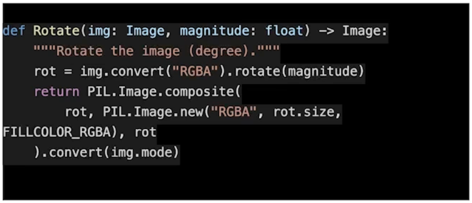
rot(각도 파라미터)를 주게되면 각도만큼 이미지를 회전하는 형태

회전한만큼 빈공간에는 색이 채워지게 됨
Contrast
밝은 픽셀과 어두운 픽셀의 차이값을 조절해주는 것
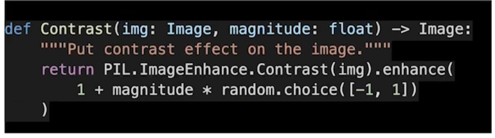
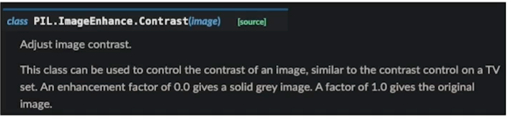
0을 주면 완전히 회색 이미지를 주고 1을주면 원본 이미지를 주고 1보다 크게되면 컬러상으로 좀 더 대비되는 이미지의 효과가 있음
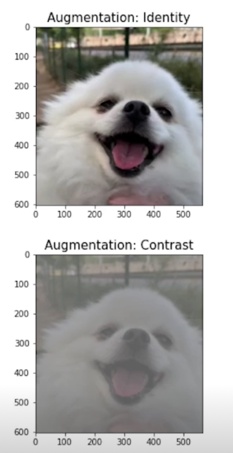
1보다 작은 값이어서 흐릿해짐
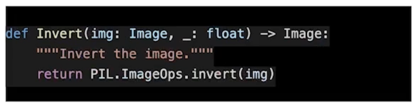
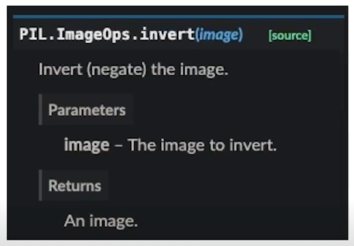
Invert
예를들어 256개의 RGB color 를 가지는 8bit 의 이미지라고 봤을때, 255에서 원래 픽셀값을 뺀 것
그래서 색이 뒤집어지는 효과를 볼 수 있음

Equalize
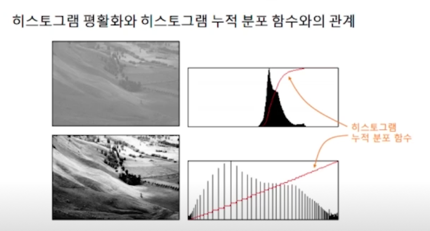
특정 픽셀값들의 빈도수가 굉장히 높음
색 구분이 제대로 되지 않는다라고 볼 수 있음
한곳에 모여있는 분포를 펼쳐준다라고 생각할 수 있음
그렇게 되면 누적분포가 모여있는곳에서 확 올라가는 경향이 있었다가 직선의 형태로 변경됨

색 표현이 좀 더 풍부해졌다라고 볼 수 있음
AutoContrast
contrast 와 동일하지만 여기에 histogram equalize 값을 사용해서 자동으로 밝은 픽셀과 어두운 픽셀의 대비를 좀 더 커지게 만드는 것
별도의 파라미터는 없음, 실제로 cutoff 라는 파라미터가 있지만 사용하진 않음
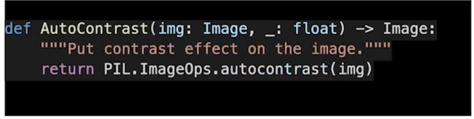

미미하지만 색표현이 좀 더 진해진 걸 볼 수 있음
Solarize

threshold 를 넘는 값들에 대해서 invert 를 취함
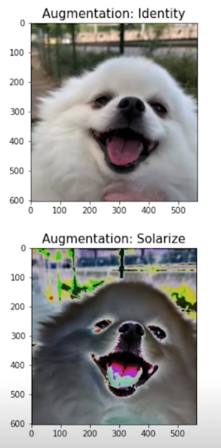
거의 바뀌긴 했는데 안바뀐 부분에 대해서는 그대로고 바뀐 부분에 대해선 색을 invert 하는 특이한 효과를 볼 수 있음
Posterize
일종의 Quantization 혹은 양자화라고 봐도 될 것 같음
원래 있던 bit 보다 더 적은 bit 로 표현하려는 것
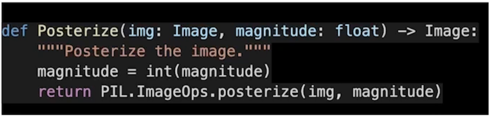
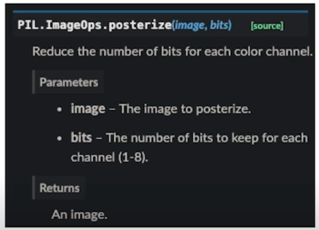

강아지 이마쪽을 보면 같은 색으로 바뀌어버림
비슷한 색들의 값을 다 같은 값으로 퉁쳐버림
그러면 더 적은 bit 로 8bit 로 표현된 이미지면 4bit 로 표현
촘촘하게 픽셀값들이 있었는데 넓직넓직하게 바꿔서 비슷한 값들로 맵핑
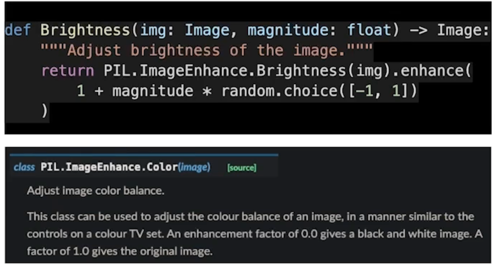
Color
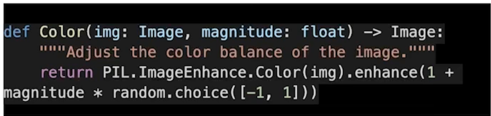
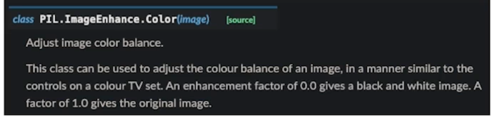
0의 경우에는 흑백사진이 나오고 1인 경우는 원본이미지가 나오고 1보다 크면 좀 더 쨍한 느낌으로 augmentation 이 적용
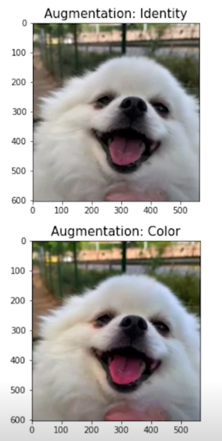
Brightness
밝기 조절

Cutout
조금은 특별한데 구멍을 뚫는다고 보면 됨
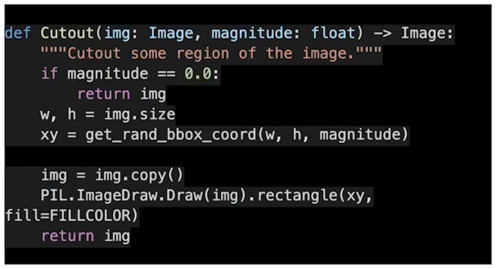

강아지의 입부분에 구멍을 뚫었지만 사람은 강아지라는 걸 알 수 있음
모델도 알아내야 함
Mix of things

하나만 적용하지 않고 막 여러개를 짬뽕 시킬 수 있음
회전도 시키고 색도 바꾸고 흐릿흐릿하게도 만들고 이것들을 중첩해서 적용할 수 있음
한 장의 이미지를 가지고 다양한 이미지로 만들 수 있음
2. Image Augmentation 논문 리뷰
2.1 Introduction
Image Augmentation: issue
- Task, Dataset 의 종류에 따라 적절한 Augmentation 의 종류, 조합, 정도(magnitude 가 다를 것)
- ex1) Capacity 가 작은 모델의 학습에 심한 augmentation 을 적용하면? 오히려 성능이 떨어질 수 있음
- ex2) 숫자 인식(MNIST) 데이터에 심한 rotation(180도) augmentation 을 적용하면?
2.2 초간단 리뷰: AutoAugment
AutoAugment: AutoML 로 augmentation policy 를 찾자
- Data 로부터 Data augmentation policy 를 학습
- 총 5개의 sub policy, 각 sub policy 는 2개의 augmentation type, 각 probability 와 magnitude 를 가짐
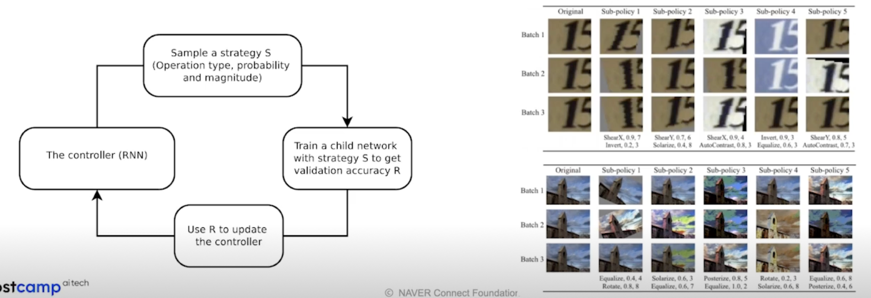
- 좋은 성능을 보이지만, 학습에 매우 큰 자원이 필요
- 속도를 바르게 만드려는 시도들(
[8], [9])


1.3 초간단 리뷰: RandAugment
RandAugment[10]: 좋은 절충안
- 2개의 파라미터(N: 한번에 몇개 적용, M: 공통 magnitude)로 search space 를 극단적으로 줄임
- (RandAug: 약 $10^2$, AutoAug: 약 $10^{32}$)
- 이 설정으로, policy 를 찾는 여타 알고리즘과 거의 동등한 성능을 보임

3. Rand Augmentation 적용하기
3.1 코드 설명
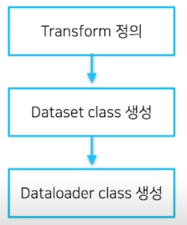
PyTorch 의 DataLoader
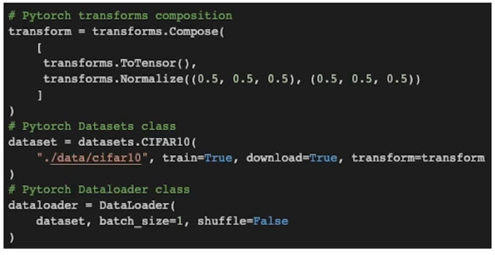
- Transform(데이터셋 변환)
- Dataset class
- DataLoader class
의 3과정을 거침
Transform 에 RandAugmentation 추가
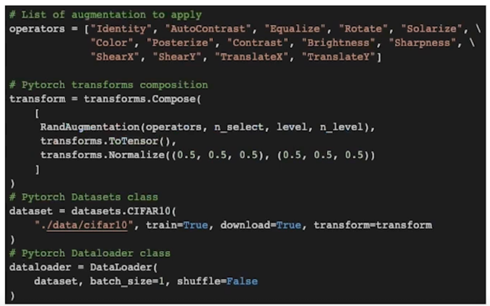
- RandAugmentation 이라는 custom transforms 를 추가
- transform 은 tensor 를 입력으로 받아 tensor 를 출력하는 함수
RandAugmentation 클래스
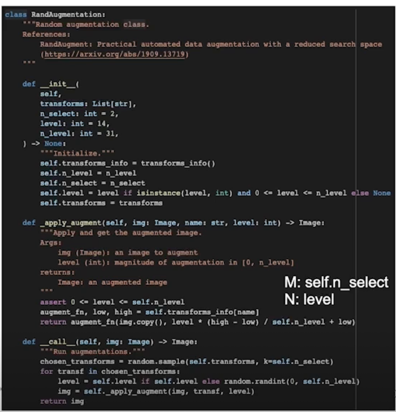
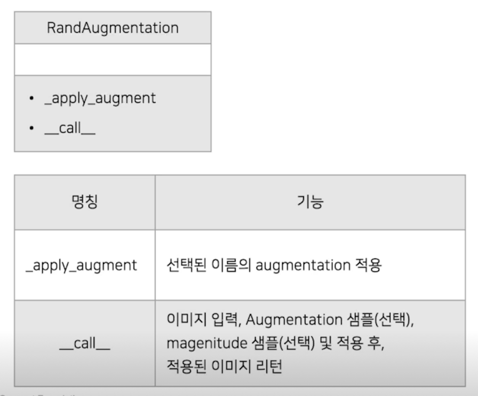
RandAugmentation 클래스: __call__
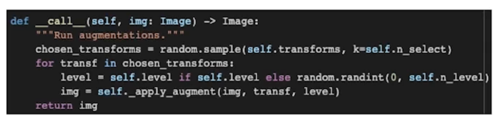
- Augmentation 의 크기(magnitude)를
[0, self.n_level]로 나눔 - 고정하거나(Constant Magnitude) random 하게 샘플(Random Magnitude)

RandAugmentation 클래스: _apply_augment
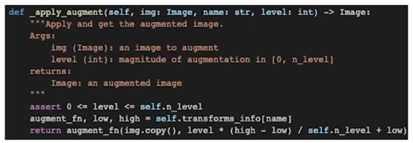
- self.transforms_info 에 아래와 같이 predefined 된 method 와 low, high 가 정의
- 선택된 level 크기의 augmentation 을 적용
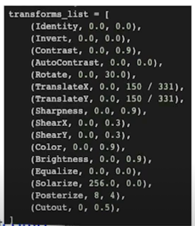
RandAubment 적용 결과

3.2 Baseline 에 적용
Overview
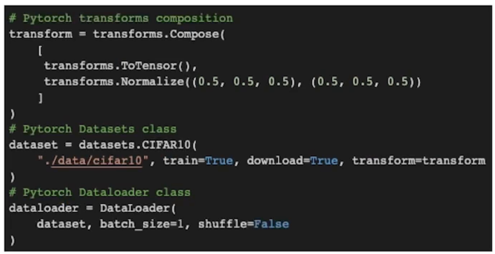
- 좌측과 흐름은 동일
- 약간의 모듈화를 적용
Overview: 호출 순서는 반대!
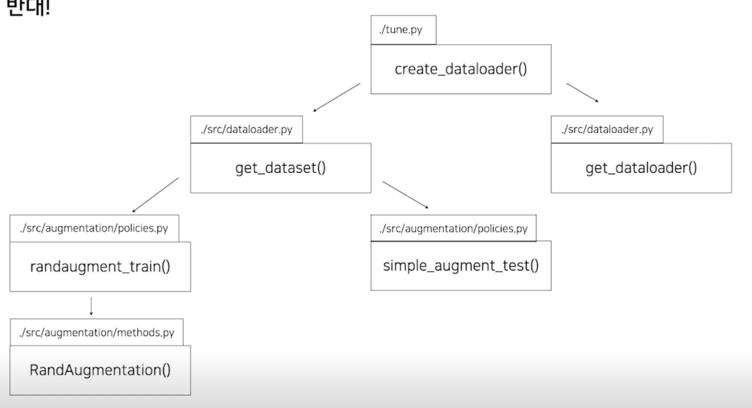
먼저 외부에서 create_dataloader() 함수를 호출하게 되면 dataloader 를 만들기 위해서는 dataset 이 필요하기 때문에 get_dataset() 을 호출하고 dataset 이 만들어지려면 transform 이 필요하기 때문에 randaugment_train() 을 실행하는 형태로 호출은 반대로되는걸 볼 수 있음
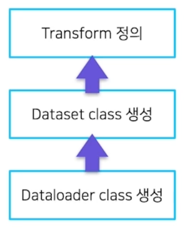
Dataloader 를 만드려면, dataset 이 필요함
Dataset 을 만드려면, transform 이 필요함
Dataloader 를 만드려면, Dataset 이 먼저 필요하고

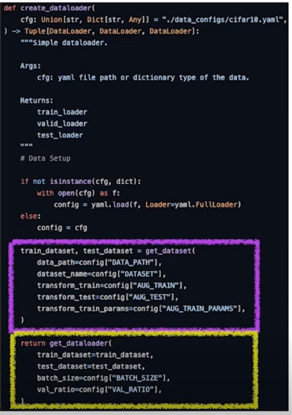
- ./tune.py 또는 ./main.py 에서 create_dataloader 함수 실행

- ./src/dataloader.py 속 create_dataloader 함수에서 get_dataset 함수 실행
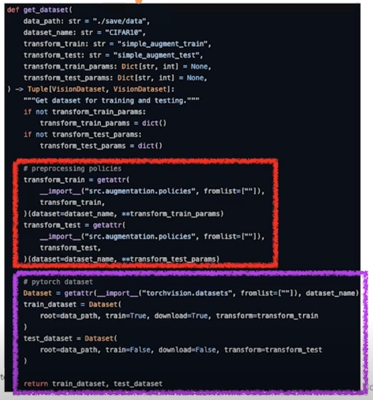
Dataset 을 만드려면, transform 이 필요함
- Yaml 에서 적용할 transform 함수의 이름을 지정하고, getattr 를 활용하여 해당 함수를 호출
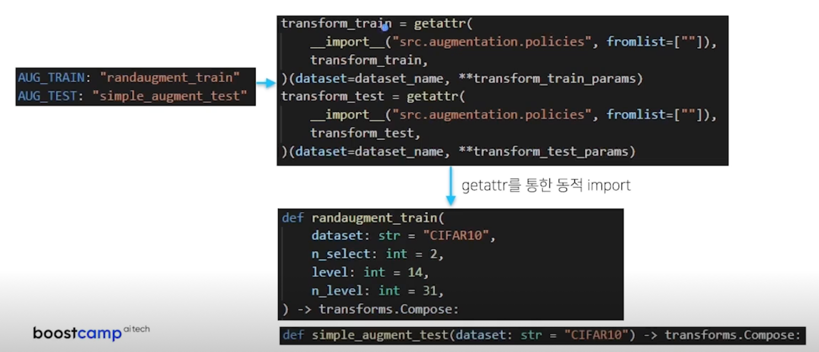
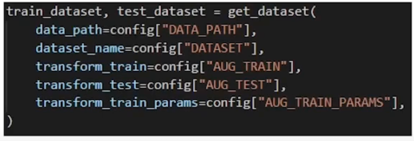
- DATA_PATH: 데이터를 저장할 폴더 이름
- DATASET: 사용할 dataset 이름
- AUG_TRAIN: train_dataset 에 적용할 augmentation 함수
- (./src/augmentation/policies.py 속 {}_train 함수 중 선택)
- AUG_TEST: test_dataset 에 적용할 augmentation 함수
- (./src/augmentation/policies.py 속 {}_test 함수 중 선택)
- AUG_TRAIN_PARAMS: AUG_TRAIN 함수 속 arguments
- (AUG_TRAIN 에 randaugment 이 들어갈 때만 설정, 아니면 null)
- n_select: 몇 개의 random augmentation 을 적용할 지
- level: 얼마나 강하게 augmentation 을 적용할 지(0 <= level <= n_level)
- n_level: level / n_level 의 강도로 augmentation 적용
- level 이 0에 가까울수록 약하게 적용, n_level 에 가까울수록 강하게 적용
- (AUG_TRAIN 에 randaugment 이 들어갈 때만 설정, 아니면 null)
- AUG_TEST_PARAMS: AUG_TEST 함수 속 arguments
- (arguments 를 필요로하는 함수가 없으므로 null 로 유지)
- BATCH_SIZE: train 에 사용할 batch size
- VAL_RATIO: train_dataset 중 validation 에 사용할 데이터 비율
4. AutoML 구동 및 결과 분석
4.1 가상의 시나리오
상황에 맞는 설정 셋업
- 가용가능한 자원(GPU, CPU) 수 파악
- 일반 모델을 학습하는데 걸리는 시간
- … 등등
가상의 시나리오 설정(현업에서는 훨씬 더 구체적)
- PC 1대 정도 리소스(CPU: 8코어, GPU: v100 1대) 할당해드릴게요,
cifar10 classification task 에 대해서 파라미터는 적고, 성능 좋은 모델 하나 만들어주세요.
내일(24시간)까지 부탁드립니다.
상황을 파악해보자
- Q: Objective 는?
A: Multi objective 문제(min Param, max Acc) - Q: 해당 task 를 한번 수행하는데 걸리는 시간은?
A: 모델의 크기에 따라 다르지만 약 2~4시간 -
Q: 해당 리소스에서 최대 몇개의 세션까지 구동가능?
A: 대략 2~3개까지 가능 - 일반적으로 100~200 회는 되어야 만족스러운 결과를 얻어낼 수 있다는 것을 경험적으로 알고있을때,
받은 업무를 그대로 처리한다면 약 24회 정도(기한 / 학습시간 * 세션 갯수, 24시간/3시간 * 3개)의 trial 을 처리 가능
시간을 줄여야 한다
- 학습 시간을 줄이고 싶은데, 데이터 셋을 소규모로 sample 해서 모델을 찾아도 될까?
- 모델의 성능에 가장 큰 영향을 주는 인자만 Search space 로 넣고 싶은데, 어떤 것들 일까?
- 등등
결국 해봐야 안다: 작고 강한 cifar10 classification 모델 만들기
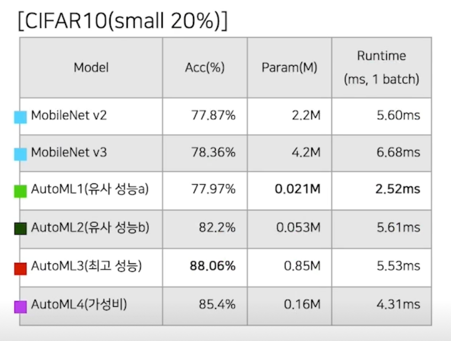
- 짧은 기한임을 고려하여, 데이터셋 축소(Train: 5만장 $\rightarrow$ 1만장(random sample), Test: 1만장); small cifar10
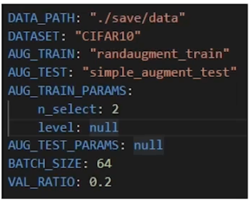
- Search space: 7개의 블록, 그 밖의 하이퍼파라미터는 전부 고정(모델 보다 중요하지 않다고 판단)
batchsize: 128, epoch: 200, SGD(+Momentum), Cosine annealing[11], Randaug 적용(N:2, M:15)

4.2 결과 분석 및 논의
AutoML 구동 결과
- 축소된 데이터셋에 대해서는 약 30분에 한 trial 이 종료됨
- 전체 89회 trial 이후, 충분히 유의미한 결과를 얻어서 미리 종료함
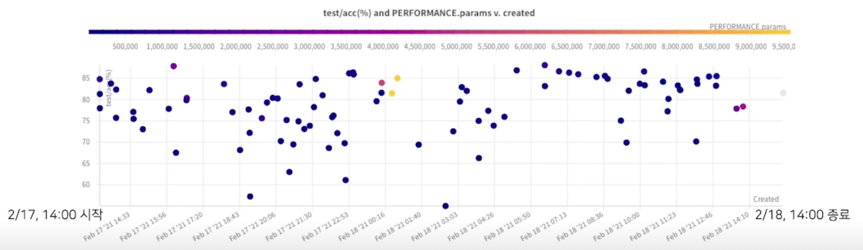
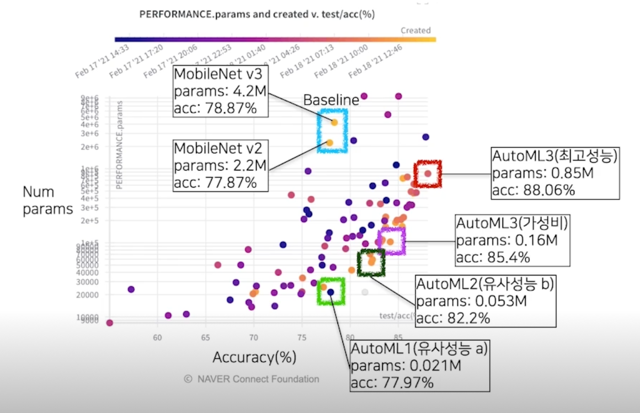
결과 분석(성능 - 파라미터 그래프)
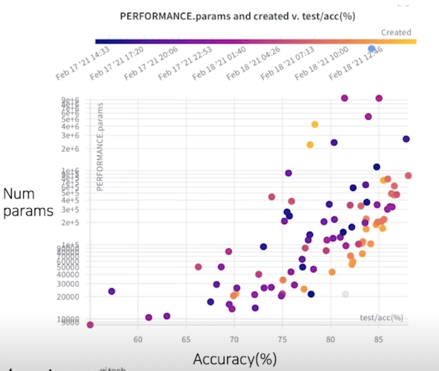
- 우측으로 갈수록 높은 성능(Acc), 하단으로 갈수록 적은 파라미터 수
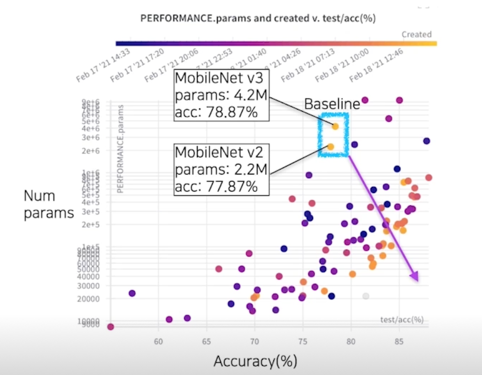
- 대체적으로 나중에 생성된 모델들(밝은 점들)이 좋은 경계(우측 하단)에 가깝게 분포 됨을 확인
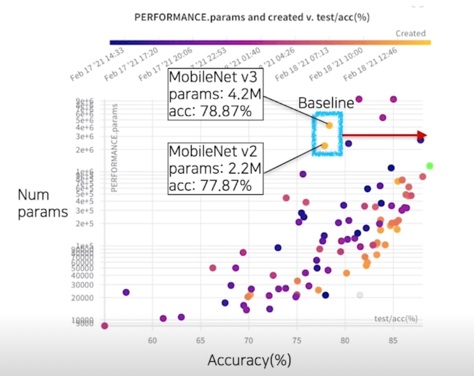
결과 분석(성능 - 파라미터 그래프); baseline
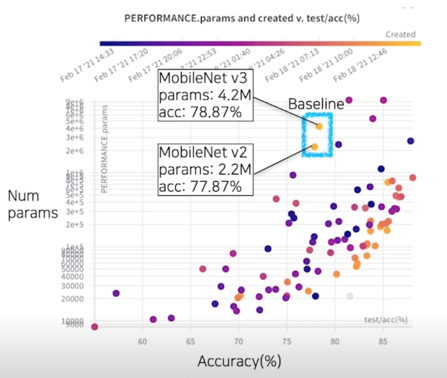
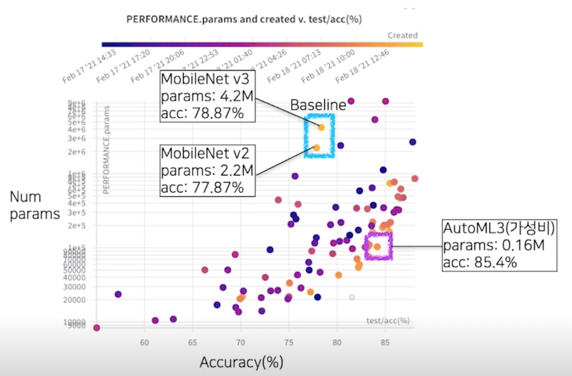
결과 분석(성능 - 파라미터 그래프); 유사 성능, 결과 내 최소 파라미터
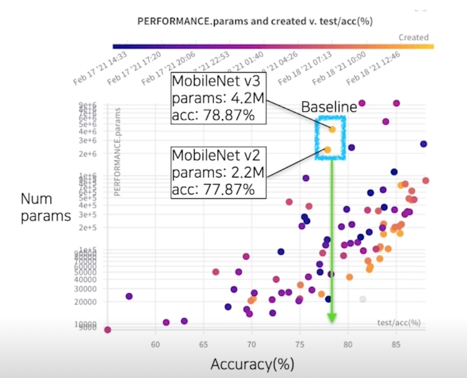
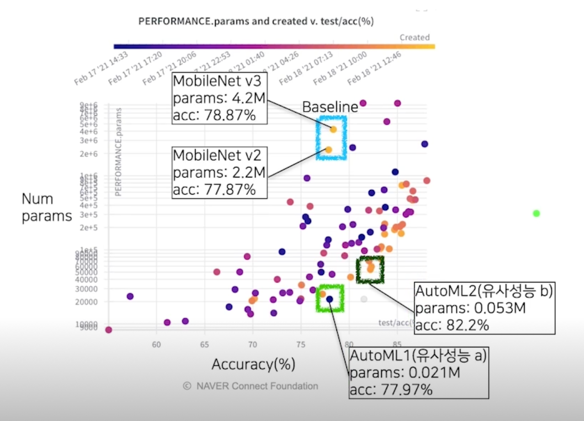
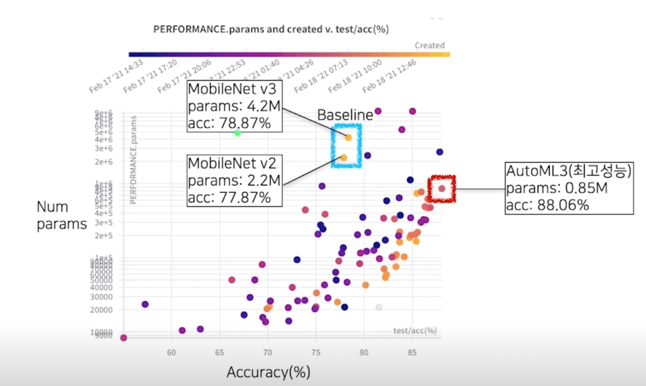
결과 분석(성능 - 파라미터 그래프); 최고성능
결과 분석(성능 - 파라미터 그래프); 적당히 좋은
결과 분석(성능 - 파라미터 그래프); 비교군 목록
과연 전체 데이터에서도 유효할까?
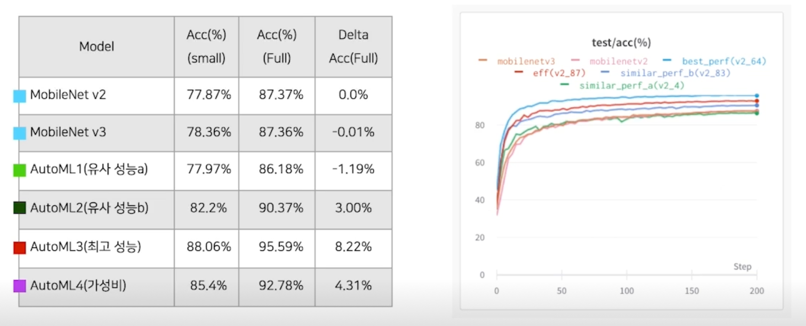
적합하고, 적당한 크기의 approximation 을 하더라도, 소기의 목적을 어느정도 달성할 수 있다.
다만, 이는 사용자의 몫
Use cases
- Q1) MobileNetV2 대비 성능은 비슷하면서 작은 모델을 찾아주세요!
A1) (Mbv2 대비) 성능: -1.18%, 크기: x0.0095, 속도 x0.45 - Q2) 가장 성능 높은 모델을 찾아주세요!
A2) 성능(약 8% 향상(95.6% > 87.37%)), 크기(x0.38(mbv2), x0.20(mbv3)), 속도(x1.00(mbv2), x0.84(mbv3)) - Q3) 적당히 좋은 모델 찾아주세요!
A3) 성능(약 4% 향상(92.78% > 87.37%)), 크기(x0.073(mbv2), x0.038(mbv3)), 속도(x0.77(mbv2), x0.65(mbv3))
약간의 discussion & open questions
- AutoML 로 데이터셋, task 에 특화된 모델을 찾는 것이 가능
- 현실적인 제약(시간, 리소스 등등)들을 해소하기 위한 엔지니어링은 (아직) 사람의 노하우가 필요
- (심화) 데이터셋이 계속 추가되고 변화하는 현실 상황에서 이전 결과를 지속적으로 활용하려면 시스템을 어떻게 구성해야 할까? (AutoML 에서의 CI/CD)
댓글남기기