Day_75 01. 최적화 소개 및 강의 개요
작성일
최적화 소개 및 강의 개요
1. Introduction (경량화)
1.1 경량화의 목적
ML is everywhere!


머신러닝과 딥러닝은 모든 분야에서 사용되고 있음
다양한 application 들이 계속해서 나오고 있는 상황
1) On device AI
- Smart Phone, Watch, other IoT Devices, …
- Limitation:
- Power usage(Battery)
- RAM Memory usage
- Storage
- Computing power
디바이스에 자체적으로 올라가서 딥러닝이나 머신러닝을 수행하는 경우
4가지 limitation 을 해소할 수 있는게 경량화방법임
2) AI on cloud(or server)
- 배터리, 저장 공간, 연산능력의 제약은 줄어드나, latency 와 throughput(처리량) 의 제약이 존재
- e.g. 한 요청의 소요 시간, 단위 시간당 처리 가능한 요청 수
- 같은 자원(=돈)으로 더 적은 latency 와 더 큰 throughput(처리량)이 가능하다면?
latency : 한 요청에 대해서 소요되는 시간
throughput : 단위 시간당 처리가능한 요청 수
3) Computation as a key component of AI progress
- 2012년 이후 큰 AI 모델 학습에 들어가는 연산은 3,4개월마다 두배로 증가해옴
- 2012년 기준, 2018년에는 약 300,000x 증가됨
- (참고)연산 측정 방법
- Counting operations(FLOPs)
- GPU times
- [1. VGG16]
- 1.2M images * 74 epochs * 16 GFLOPS * 2 add-multiply * 3 backward pass = 8524PF = 0.098 pfs-day
- [2. VGG16]
- 4 Titan Black GPU’s * 15 days * 5.1 TFLOPS/GPU * 0.33 utilization = 10,000 PF = 0.12 pfs-days
- [1. VGG16]
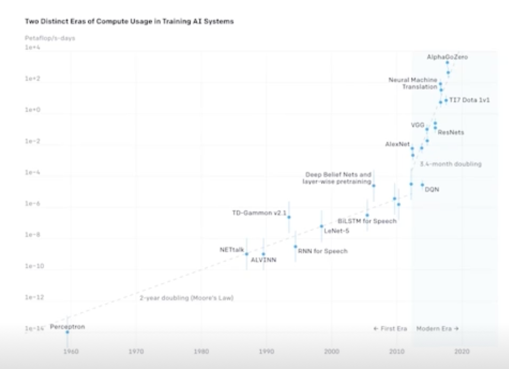
전체적으로 연산량이 증가하고 있다
경량화는?
- 모델의 연구와는 별개로, 산업에 적용되기 위해서 거쳐야하는 과정
- 요구조건(하드웨어 종류, latency 제한, 요구 throughput, 성능)들 간의 trade-off 를 고려하여 모델 경량화/최적화를 수행
1.2 경량화 분야 소개
경량화, 최적화의 (대표적인) 종류
- 네트워크 구조 관점
- Efficient Architecture Design(+AutoML; Neural Architecture Search(NAS))
- 비전에서의 module block 들 e.g. mobilenet, resnet, vgg, efficientnet 등
- NAS : 경량모델을 사람이 디자인 하는게 아니라 최적화를 통해서 경량모델을 찾아보자
- Network Pruning
- 중요도가 낮은 파라미터를 제거해 사이즈를 줄여보자는 접근
- Knowledge Distillation
- 학습된 큰 규모의 teacher 네트워크가 있을 때 작은 student 네트워크에 teacher 네트워크가 가지고 있는 knowledge 를 Distillation(전달)하자 라는 내용으로 봐도 됨
- Matrix/Tensor Decomposition
- 학습된 네트워크에 대해서 convolution weight 들이 학습이 될건데 이 convoution weight 들을 더 작은 단위의 tensor 들의 곱과 합으로 표현 실제로 들고있어야하는 weight 의 양도 줄어들고 연산량도 줄어듦 …
- Efficient Architecture Design(+AutoML; Neural Architecture Search(NAS))
- Hardward 관점
- Network Quantization
- 일반적으로 학습된 네트워크가 float32 로 표현되는데 더 작은 타입인 float16, int, 더 작은 사이즈로 맵핑
- Network Compiling
- 하드웨어가 정해져있을때 inference 를 효과적으로 수행할 수 있도록 자체 Compile 하는 과정을 의미 …
- Network Quantization
- Efficient architecture design
- 매년 쏟아져 나오는 블록 모듈들
-
각 모듈 블록마다의 특성이 다름(성능, 파라미터 수, 연산횟수, …)
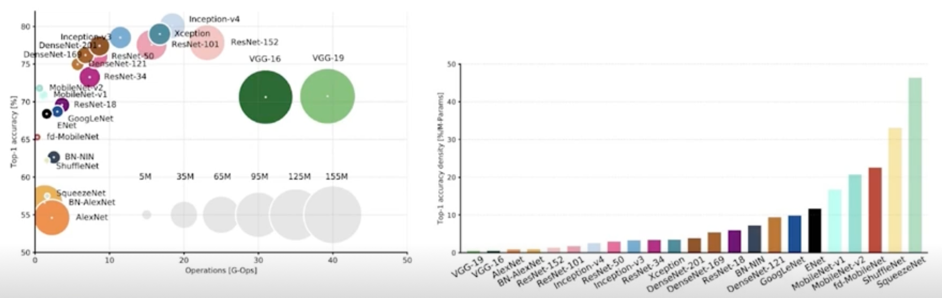
왼쪽에 있는 모듈들이 경량모델임
accuracy density 에 대해서 파라미터가 어느정도로 기여하고 있느냐인데 맨 오른쪽에 squeezenet 같은 경우가 엄청 좋은 효율을 가지는 것을 볼 수 있음
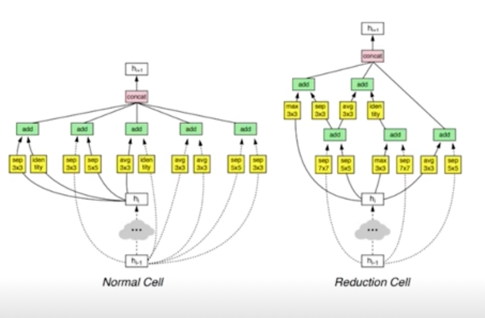
- Efficient architecture design: AutoML, Neural Architecture Search
- Software 1.0: 사람이 짜는 모듈
-
Software 2.0: 알고리즘이 찾는 모듈
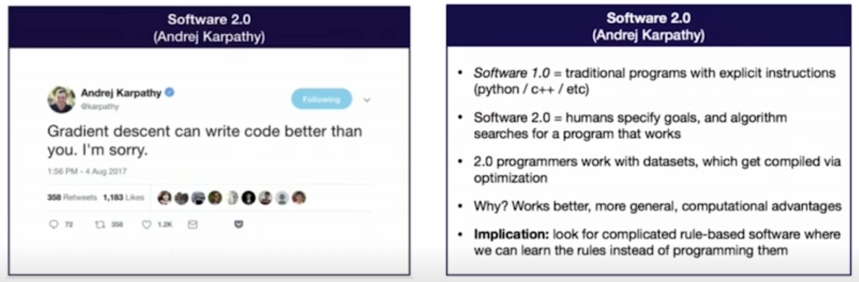
-
모델을 찾는 네트워크(controller)
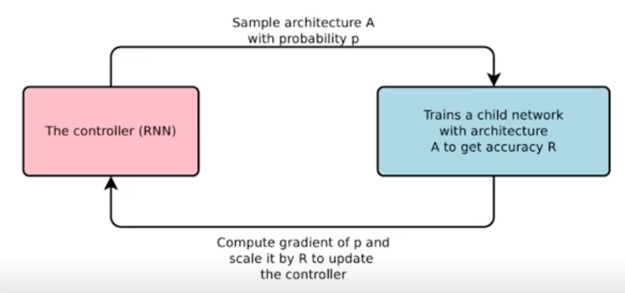
-
사람의 직관보다 상회하는 성능의 모듈들을 찾아낼 수 있음
- Network Pruning: 찾은 모델 줄이기
- 중요도가 낮은 파라미터를 제거하는 것
- 좋은 중요도를 정의, 찾는 것이 주요 연구 토픽 중 하나
- (e.g. L2 norm 이 크면, loss gradient 크면, 등등)
-
크게 structured/unstructured pruning 으로 나뉘어짐
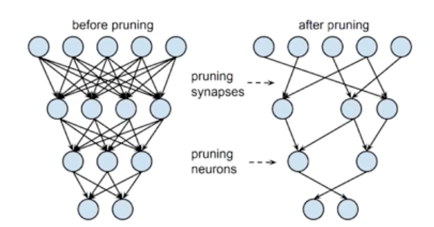
- Network Pruning: Structured pruning
- 파라미터를 그룹 단위로 pruning 하는 기법들을 총칭(그룹: channel / filter, layer 등)
-
Dense computation 에 최적화된 소프트웨어 또는 하드웨어에 적합한 기법
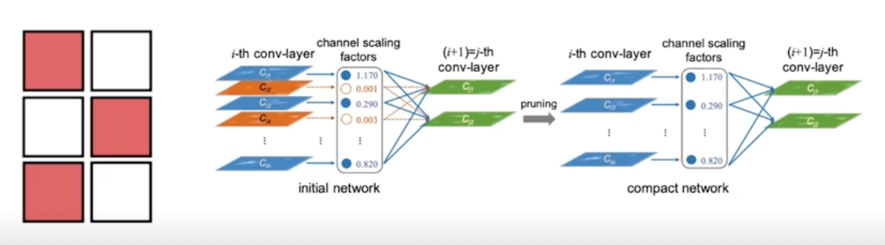
왼쪽 그림은 filter 인데 빨간색은 살리고 흰색은 날린다고 보면 됨
- Network Pruning: Unstructured pruning
- 파라미터 각각을 독립적으로 pruning 하는 기법
- Pruning 을 수행할수록, 네트워크 내부의 행렬이 점차 희소(sparse)해짐
-
Structured Pruning 과 달리 sparse computation 에 최적화된 소프트웨어 또는 하드웨어에 적합한 기법
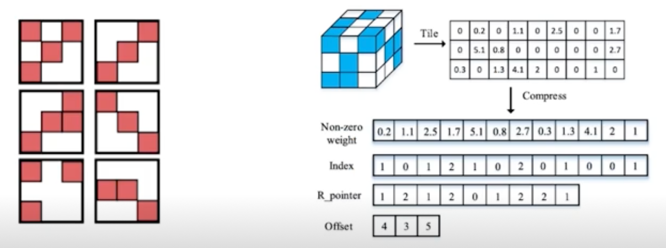
convolution filter 를 각각의 matrix 마다 하나하나 확인해서 pruning 을 진행
- Knowledge distillation
- 학습된 큰 네트워크를 작은 네트워크의 학습 보조로 사용하는 방법
- Soft targets(soft outputs)에는 ground truth 보다 더 맣은 정보를 담고 있음
-
(e.g. 특정 상황에서 레이블 간의 유사도 등등)
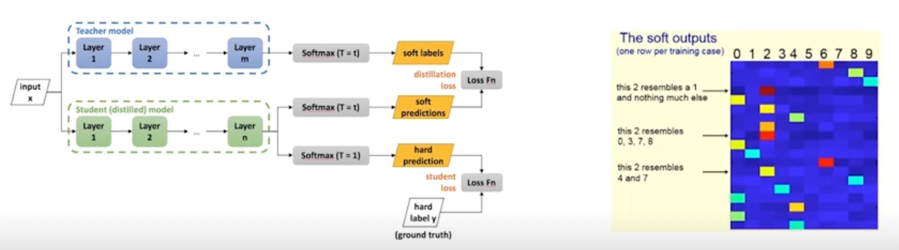
- Student network 와 ground truth label 의 cross-entropy
-
teacher network 와 student network 의 inference 결과에 대한 KLD loss 로 구성
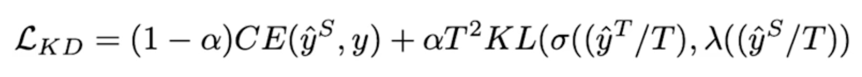
- $T$ 는 large teacher network 의 출력을 smoothing(soften) 하는 역할을 한다.
- $\alpha$ 는 두 loss 의 균형을 조절하는 파라미터다.
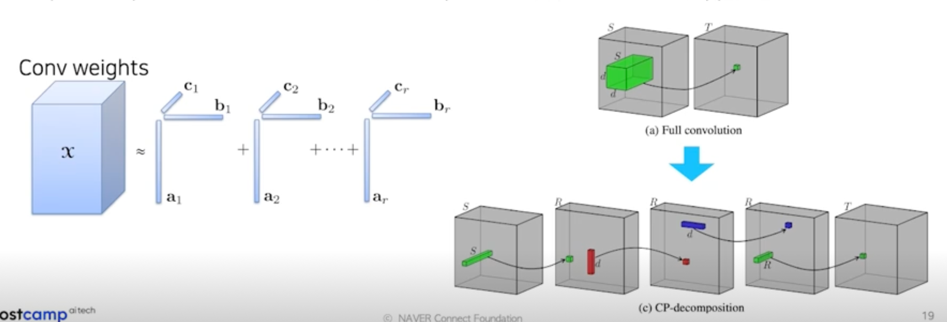
- Matrix/Tensor decomposition
- 하나의 Tensor 를 작은 Tensor 들의 operation 들의 조합(합, 곱)으로 표현하는 것
-
Cp decomposition: rank 1 vector 들의 outer product 의 합으로 tensor 를 approximation
- Network Quantization
-
일반적인 float32 데이터타입의 Network 의 연산과정을 그보다 작은 크기의 데이터타입(e.g. float16, int8, …)으로 변환하여 연산을 수행
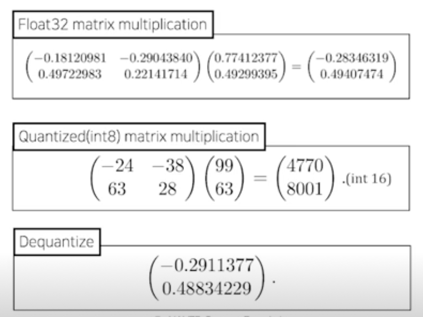

결과가 달라지는 Quantization Error 가 발생함
그렇지만 Quantization Error 에도 Robust 하게 동장하는게 경험적으로 밝혀져 있음
그래서 보편적으로 많이 적용이 되고 있는 기법중에 하나임 - 사이즈: 감소
- 성능(Acc): 일반적으로 약간 하락
- 속도: Hardware 지원 여부 및 사용 라이브러리에 따라 다름(향상 추세)
-
Int8 quantization 예시(CPU inference, 속도는 pixel2 스마트폰에서 측정됨)
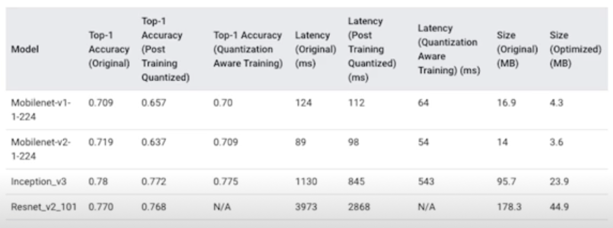
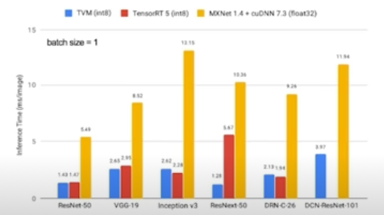
- Network Compiling
- 학습이 완료된 Network 를 deploy 하려는 target hardware 에서 inference 가 가능하도록 compile 하는 것(+ 최적화가 동반)
- 사실상 속도에 가장 큰 영향을 미치는 기법
- e.g. TensorRT(NVIDIA), Tflite(Tensorflow), TVM(apache), …
-
각 compile library 마다 성능차이가 발생
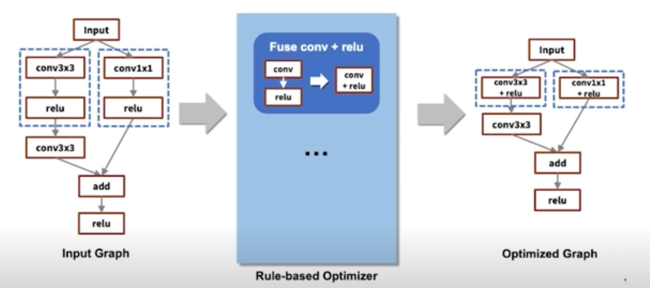
- Compile 과정에서, layer fusion(graph optimization) 등의 최적화가 수행됨
-
예를들어 tf 의 경우 200개의 rule 이 정의되어 있음
- Framework 와 hardware backends 사이의 수많은 조합
-
HW 마다 지원되는 core, unit 수, instruction set, 가속 라이브러리 등이 다름

-
Layer fusion 의 조합에 따라 성능차이가 발생(동일 회사의 hw 임에도)
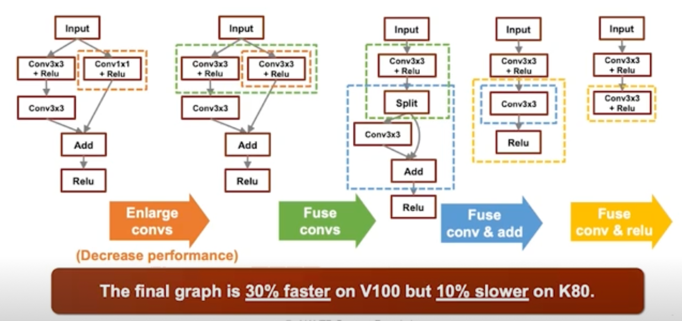
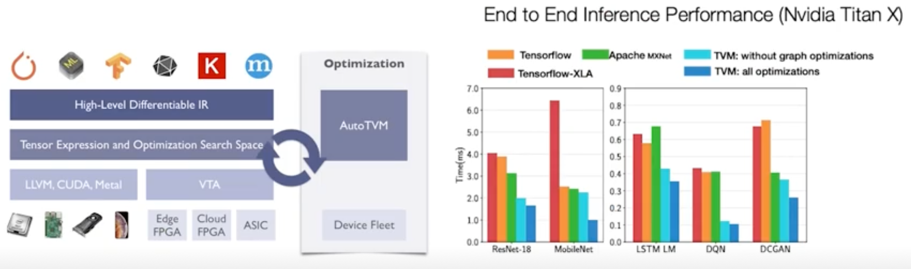
- AutoML 로 graph 의 좋은 fusion 을 찾아내자
-
e.g. AutoTVM(Apache)
2. 강의 목표, 구성
2.1 강의 목표
일련의 과정을 따라가 보자! 경량화 컬렉션
- 경량화, 최적화라는 넓은 분야
- 특정 주제들은 구체적이고 지엽적
- 다양한 분야로 나아가실 수강생 분들께 도움이 될만한 broad 한 토픽을 고민(+ 가능하면 재미있게…)
AutoML 에 비중을 두고 강의하기로 결정 $\rightarrow$ 알아두면 이곳 저곳 두루 사용가능한 유용한 기법
Pruning, Distillation 같은 경우는 활발히 연구되고 있지만, 일반화하여 적용하기는 아직 어려움
Tensor Decomposition 같은 경우는 (깊이 볼 수록)수학적으로 복잡하나, 간단한 구현으로 좋은 효과를 내기 때문에 유용하다고 판단
Quanstization 과 Compiling 은 성능에 가장 큰 영향을 주는 요소라서 강의에 포함

강의 Overview
- 강의 개요
- 대회 소개 및 코드 제출 방법 설명
- 작은 모델, 좋은 파라미터 찾기: AutoML 이론
- 작은 모델, 좋은 파라미터 찾기: AutoML 실습
- 작은 모델, 좋은 파라미터 찾기: Data Augmentation & AutoML 결과 분석
- 찾은 모델 잘게 찢기: Tensor Decomposition 이론
- 찾은 모델 잘게 찢기: Tensor Decomposition 실습
- 찢은 모델 꾸겨 넣기: Quanstization 이론
- 찢은 모델 꾸겨 넣기: Quanstization 실습
- 학습 파이프라인 최적화 및 마무리
댓글남기기