Day_72 [오피스아워] 중국 딥러닝 엔지니어들의 삶 + 중국 기업의 데이터 이야기&다양한 (한국어) 데이터 구축 과정에서의 findings - 김재인, 조원익 멘토
작성일
[오피스아워] 중국 딥러닝 엔지니어들의 삶 + 중국 기업의 데이터 이야기&다양한 (한국어) 데이터 구축 과정에서의 findings - 김재인, 조원익 멘토
중국의 기술이 어떻게 빠르게 발전했을까?
단순히 사람이 많아서일까?
인력
- 중국의 학구열
- 학교에 공부만 하고 살 수 있도록 모든게 갖춰져 있음
- 기숙사, 교실, 연구실만 왔다갔다함
- 그를 받쳐주는 인프라
- 활발한 창업
- 높은 연봉
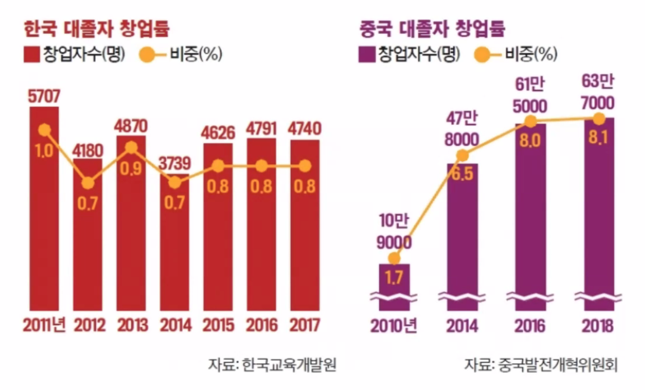
- 화웨이에서 딥러닝 엔지니어들의 연봉이 엄청 높아진다는 뉴스를 접할 수 있음
- 징동 200만 이면 연봉이 한국돈으로 3억8천만원
사내문화
- 낮잠 문화

- 수평관계?
- 호칭
- 동아리 활동
- 생일파티
- Team building 여행
- 연말 파티

데이터
- 자체 제작이 가능한 자본력
- 억단위의 사용자 데이터
데이터 공장의 하루: 왜, 어떻게, 얼마나 좋게 만들 것인가?
1. 데이터 구축의 동기
무언가를 하고 싶다 (or 무언가를 해야 한다!)
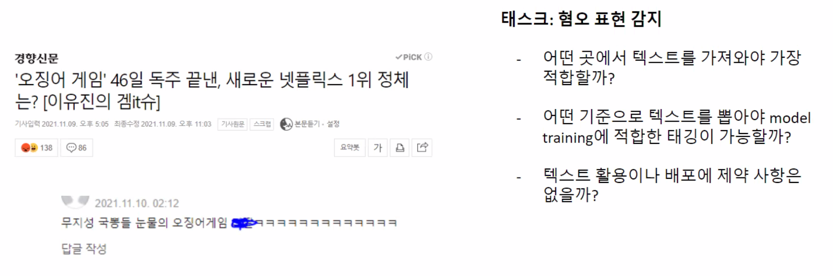
- 사람들이 쓰는 댓글에서 나쁜 말을 걸러내고 싶다
- TASK: 혐오표현/차별/욕설 감지 <- “혐오표현은 어떤 것인가? 차별적 발화의 정의는 무엇인가?”
- 내가 쓴 글과 이미 비슷한 글이 있는지 알아내고 싶다
- TASK: 문장/문서 유사도 측정 <- “두 문장/문서가 비슷한 정도는 어떻게 수치화할 수 있는가?”
- 시리를 부르지 않아도 반응하는 시리를 만들고 싶다
- TASK: 화행 및 의도 인식 <- “질문이나 명령과 그렇지 않은 표현은 어떻게 구별하는가?”
- 시리가 개떡같이 말해도 찰떡같이 알아들었으면 좋겠다
- TASK: 문장의 핵심 성분 추출 <- “문장에서 어떤 표현들이 내용 전달에 꼭 필요한가?”
그래서…. 그런 데이터가 존재하는가?
데이터가 없으면 만들어야 하는 상황이 존재
내가 원하는 언어로, 내가 원하는 양식으로 존재하는가?
언어마다 예시도 달라지고 의미 비교도 달라지기 때문에 이것을 먼저 search 하고 정성적인 접근을 알아본 다음에 해야함
없다면, 어떻게 만들 것인가?
2. 어떻게 만들 것인가?
데이터 구축도 ‘제품 생산’의 과정이다! (그러나 model training 에의 활용을 곁들인…)
- 원시 코퍼스: 원재료
- 신문 제목은 데이터로 활용하는데 저작권이 적용되지 않아서 문제없음
- 댓글도 댓글 작성자가 나의 작품이다라고 주장하지 않으면 사용하는데 지장 없음
- 연구 진행자: 작업 총괄(구상, 도면, 프로토타입, 파일럿, 대량생산)
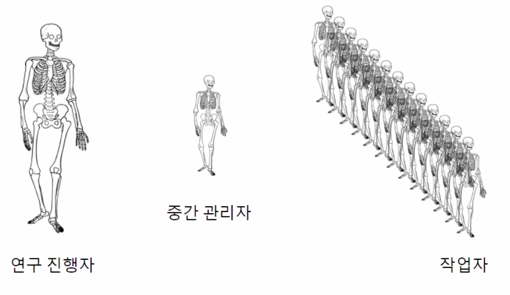
- 크게 3종류의 참가자들이 있음 연구진행자, 중간관리자, 작업자
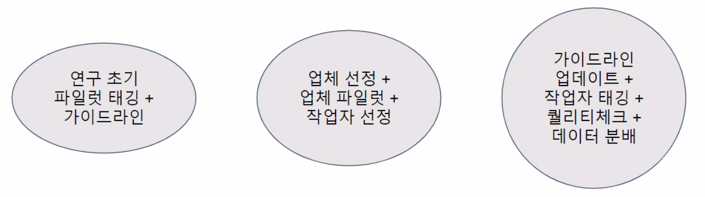
- 파일럿: 본 생산에 들어가기 전 proof of concept 를 체크하는 과정
- 컨텐츠 구상 및 In/Out 설정: 제품 구상
- 구축 가이드라인: 설계 도면
- 예시 문장/문서: 제품의 Proof of concept



- 파일럿 구축과 일치도 측정: 부분 생산 및 퀄리티 체크
- 본 구축: 풀스케일 생산 (파일럿의 iteration 은 한 번이 아닐 수 있음!)
- 자연어 데이터의 특성상 기계적으로만 하다보면 본질을 잃고 처음 의도와 다른 데이터가 구축될 수 있음
- 내가 왜 이걸하는지? annotator agreement 를 높이기 위해서 편의를 위해서 한 일들이 데이터의 품질을 떨어뜨리는 방향이 아닌지 환기할 필요 있음
3. 시행착오와 배운 점들
곳곳에서 다양한 이슈들이 발생!
- 왜 우리가 이 데이터셋을 만드는가? 에 대한 근원적인 질문
- 네이버 뉴스 댓글은 정말 저작권의 문제가 없는가?
- Hate speech 및 Social bias 를 바라보는 개개인의 시각이 모두 다를 수 있다
- ‘모두를 만족시키는 가이드라인’ 같은 것은 거의 존재하지 않는다고 보아도 무방
- 우리가 미처 생각하지 못했던 종류의 표현들의 등장 (창의적인 냉소, 비꼼, 돌려까기, 혹은 선의의 편견 등)
- 연구 진행자와 작업자들 간의 윤리관의 차이
- 레이블 간의 불균형 (사실 구축하기 전에는 알기 어려운 것)
- 데이터 구축에는 돈이 든다…
- 최근의 자연어 데이터 구축은 엄중한 윤리적 가이드라인을 필요로 한다…
Q&A
중국어는 (1) 띄어쓰기가 없고 (2) 단어의 순서가 중요하지 않고 (3) 모든 단어가 의미를 가지기에 NLP가 타 언어에 비해 쉽다고 생각하는데 혹시 타 언어에 비해 더 어려운 부분이 있을까요?
중국에선 띄어쓰기가 없는게 오히려 어려운 편
단어가 앞뒤로 어떻게 붙냐에 따라서 단어 뜻이 달라질 수 있기 때문에 분사 작업이 가장 어려운 것으로 알 고 있음
한국어 관련 NLP 연구도 많았는데 오히려 한국어 특성상 어려움이 많았던 것 같음
굳이 고르자면 한국어보다 띄어쓰기 없는 중국어가 더 쉬운 것 같음
중국어 위주로 데이터셋을 보셨는지? 작업하신 언어의 비율이 궁금하네요
한국어를 초반엔 많이 봤었고 굉장히 다양한 언어를 지원하기 시작할 때 한국어를 할 수 있는 사람은 본인 밖에 없어서 한국어 데이터를 많이 봤음
졸업 프로젝트 같은 경우는 중국어 smart reply 여서 중국어 데이터를 많이 봤음
중국에서 연구하실 때 주로 사용하시는 프레임워크는 무엇인가요? pytorch인가요? Paddle paddle이라는 것도 최근에 눈에 띄어서 궁금했습니다
도구의 사용은 세계적인 흐름과 비슷함
중국에서도 github 를 사용하고 한국과 마찬가지로 PyTorch 를 대부분 많이 사용하고 Paddle paddle 같은 경우에는 baido 에서 개발하고 나서 까먹고 있었는데 Paddle paddle 을 진짜 쓰는 사람이 있냐? 라는 질문이 있는걸보니 많이 사용하진 않는 것 같음
캠퍼들이 최종 프로젝트를 진행중인데 이런 데이터가 있을까? 데이터를 어디서 찾아야하지? 만들어야하나? 이런 생각을 하기 시작할텐데 이런 측면에서 사이드 프로젝트를 하실 때 문제정의 부터 하시는지 데이터를 먼저 확보하고 프로젝트를 하시는지?
김재인 멘토
회사에 데이터가 굉장히 많이 있었어서 먼저 목적을 가지고 어떤 데이터를 가지고 프로젝트를 할지 정했었던 것 같음
중국어 데이터가 많아서 따로 모을 필요가 없다보니 있는 데이터를 활용해서 프로젝트르 진행
조원익 멘토
중국어나 영어에는 적당한 키워드로 찾으면 데이터셋이 나오는 환경이 있음
데이터셋을 찾아서 번역을 해서 사용하는 경우도 종종 있음
그렇게 공개하는 것도 contribution 인 것 같고 그렇지만 그러다보면 레이블자체의 다른 나라의 문화가 반영되지 않을 수 있음
대량으로 pre-train 한 다음에 소량의 잘 만들어진 데이터로 fine-tuning 하는 것 같음
문제를 풀려면 이 데이터를 어디서 구하지? 이런 생각이 먼저 들기 때문에 문제를 단순화해서 데이터를 구축하는 방향으로 진행
최대한 비슷한 task 를 찾아서 간단한 추가 tagging 만으로도 원하는 결과를 얻을 수 있어서 잘 활용하면 좋을 듯
자연어 데이터를 augmentation 할 때 주의점이 있을까요? 아니면 tip이 있을까요?
paraphrase 를 해서 비슷한 의미의 데이터를 추가한다거나 문장의 일부를 바꿔서 추가하는 방법이 있는데
데이터를 추가하는 것이 모델의 최종 성능을 올리긴 하는데 이 과정에서 너무 규칙적인 변화를 넣음으로써 특정 추론이 특정 inference 로 이어지는 artifact 라고 하는 것들을 잘 방지한다면 좋은 것 같음
특정 부사가 있을 경우에 entailment 로 생각한다던지 이런 부분에서 좀 참고해서 어떤 걸 방지해야겠다라는 가이드라인만 방지해준다면 augmentation 은 항상 좋은 방법인것 같음
자연스럽진 않지만 backtranslation 도 좋은 방법인 것 같음
최종 프로젝트를 한달안에 완성해야 하는 상황에 짧은 기간에 나를 또는 우리 팀을 드러내야하는 상황에서 어떤 조언을 주실 수 있을까요?
조원익 멘토
data driven 하게 만드는 과정이 들어가게 되다 보니까 ‘많이 모으자’ 라거나 이런 ‘많이 모으자’는 항상 좋은 길은 아닌것 같고 모호한 부분 없이 더 명확하게 분류가 가능한 데이터가 효과적이다라고 말하고 싶음
어떤 task 를 하는지 몰라서 구체적인 조언을 주긴 힘듦
데이터 위주로 있는 데이터가 뭐가 있는지 보고 시작해보는것도 좋을 것 같음
김재인 멘토
관심 있는 것을 찾아서 지금과 같은 열정으로 하시면 좋은 결과나오지 않을까 합니다
댓글남기기