Day_67 [오피스아워] 데이터 제작 Behind: 퀄리티 있는 RE 데이터 제작을 위한 데이터를 제작하는 방법 - 전종섭, 조원익 멘토
작성일
[오피스아워] 데이터 제작 Behind: 퀄리티 있는 RE 데이터 제작을 위한 데이터를 제작하는 방법 - 전종섭, 조원익 멘토
Wikipedia 데이터는 어떻게 추출할까?
- wikipediaapi 사용하기
- https://github.com/Aiden-Jeon/ko-wiki-api
데이터를 받으면 어떻게 해야할까?
- 어떤 Entity 가 나올 수 있을지?
-
어떤 relation 이 나올 수 있을지?
-
KSS 와 같은 라이브러리를 활용해 문장으로 나누거나 필요하다면 Regex
- 여러 문장이 있어야 관계가 나오는 경우
- 단순히 룰베이스로 데이터를 나누는것보다는 직접 확인해보는게 좋을 듯
Tagtog 초기 세팅 방법
https://www.tagtog.net/
로그인
new project
Entity 생성
Relations 생성
Documents
+ content
text 추가
entity 드래그해서 선택
add relation
save
confirm
download
파일을 가지고 구글 스프레드시트에 만들기
퀄리티 있는 RE 데이터 제작을 위한 전략들
관측 가능한 관계들을 리스트업하고 토의를 ㅌ통해 확정
class_name (ko/en):
relation 에 대한 직관적인 네이밍
subj 의 entity type 이 앞에, obj 의 역할이 뒤에 배치됩니다.
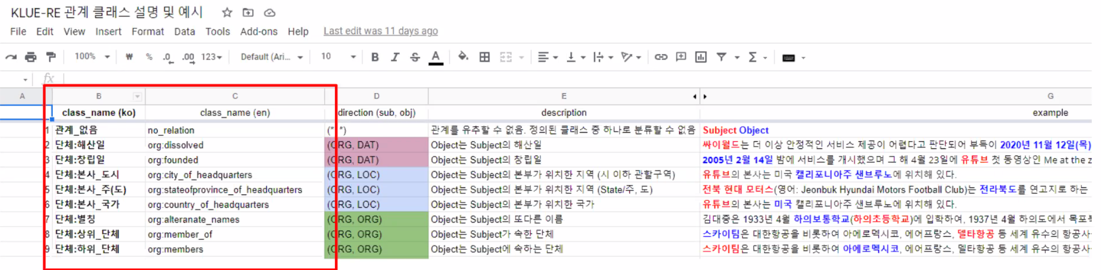
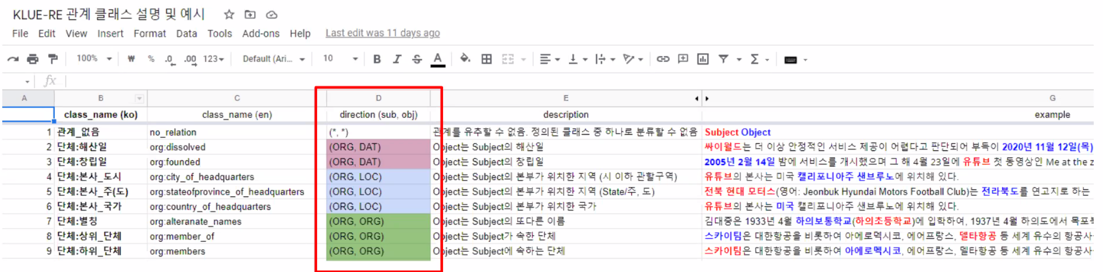
direction (subj, obj):
subj 와 obj 의 entity type 및 relation 의 방향성
Entity type 은 하나의 정형적인 형태 (org, loc, per 등)로 나오지 않을 수도 있습니다. (e.g., 물리학 - 전자기학 : relation 은 명확하지만
두 entity 에 해당하는 entity type 은 널리 사용되는 ne 가 아닐 수 있음)[잘 정의하여 사용할 수 있으면 상관 x!]
description:
subj 와 obj 의 관계에 대한 정의
선택되는 두 entity 사이의 관계를 정의합니다. TACRED 및 KLUE-RE 의 경우 org 혹은 per 이 subj 인 관계로, 창립일, HQ 의 위치, 출생일 등이
relation 으로 포착됩니다. 새로이 관계를 정의한다면, direction (subj, obj)
example:
해당되는 relation 이 등장하는 example
각 example 에는 물론 해당되는 relation 이외의 관계가 등장할 수도 있습니다. 즉, 한 문장에서 두 개 이상의 관계가 등장할수 있습니다.
Relation map 기술
가이드라인 작성
a. 관계를 정의 (define) - 가능한 관계의 수는 제한되지 않지만, 균등하게 나올 수 있는 관계들일수록, 그리고 너무 세부적이지 않은 관계들일수록 실용적인 분류 성능을 기대할 수 있음
해당 관계의 예시들을 문서에서 찾아 기재
도입 문구:
일반적으로 크라우드소싱 등의 다작업자 구축을 염두에 두고 작성됩니다.
본 강의에서는 그러한 절차를 거치지는 않지만, 추후 가이드라인을 활용하여 구축 작업을 재현하기 위해서, 어느 정도의 documentation 은 필수적입니다.
주어진 샘플과 꼭 같을 필요는 없지만, 읽는 사람으로 하여금 어떤 내용들이 들어가 있는지 파악하기 좋게끔 있으면 좋음
태스크 설명:
RE 라는 태스크, Subject 와 object 라는 개념의 역할, entity 의 개념들, 그리고 ‘관계’라는 레이블의 정의가 등장합니다.
태스크 소개에 해당하는 부분이며, 어떤 label 들이 있고 해당
이후, 태스크 수행에 관한 간단한 에시를 덧붙입니다.
이미 KLUE-RE 를 다루면서 이에 대해 익숙하시겠으나, 다시 한번 가이드라인을 통해 이를 정의합니다.

어노테이션 가이드라인:
Annotation 시 고려할 내용들을 설명합니다.
Task 설명에 들어간 내용이 여기 한번 더 반복되어도 상관없습니다.
작업자들이 Annotation 하면서 애매한 부분, 궁금해 할 만한 부분들을 서술합니다. KLUE-RE 에서는
- 관계의 방향성 유의
- ‘관계 없음’ 의 존재
- 외부 지식의 활용 가능 여부
- 관계 assign 시 ‘시점’의 반영 여부 등이 기재되었습니다.

‘외부 지식’ 산입 여부는 어떤 주제의 RE 태깅이든 고려해야 할 문제입니다.
문장 내에서 파악할 수 있어야면 pre-define 된 관계로 레이블링이 가능하며, 이는 common sense 혹은 외부적 지식만으로 유추되어서는 안되는 것이 원칙입니다.
이런한 이유로, entity 들의 존재에도 불구하고 실제로 no_relation 으로 태깅되는 경우가 생각보다 많을 수 있습니다.
이러한 원칙이 없다면, 특정 문장 구조 혹은 성분에서 relation 을 유추하고자 하느 ㄴ시도의 의미가 퇴색될 수 있습니다.

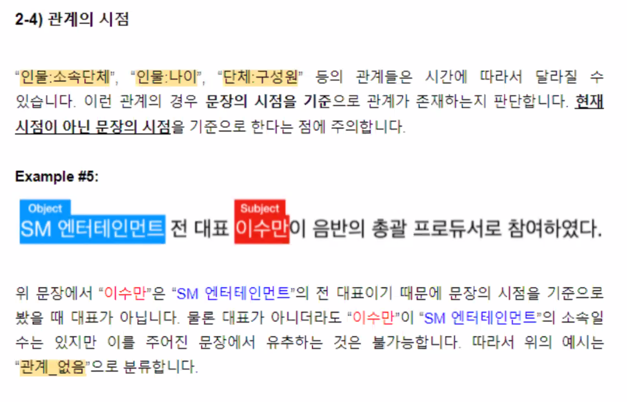
‘시점의 문제’는 상태가 변할 수 있는 여러 가지 관계를 포함한 문장들에서 등장할 수 있습니다.
이러한 경우, 시점이 맞지 않을 때 relation 태깅을 하지 않는 것이 이론 상으로는 맞지만, 협의를 통해 그런 관계까지 포함하도록 가이드라인을 재정의 할 수 있습니다.
어노테이션 환경:
실제 작업자가 어노테이션을 진행할 환경 및 해당 환경에서 등장하는 변수들을 기술합니다.
본 프로젝트에서는 tagtog 및 구글 스프레드시트가 작업 환경에 해당하며, 주어진 문장에서 entity 선정 및 relation tag 를 초벌로 작업할 때는 tagtog 을, 만들어진 문장-entity pair 에 대해서 relation 을 레이블 할 때는 구글 스프레드시트를 활용합니다.
예시에서 1-3) 는 작업 절차에 대한 가이드를,
Data error 은 자동으로 데이터가 태깅되는 경우 발생하는 문제이지만, 본 프로젝트처럼 manual 하게 데이터가 제작되는 상황에서는 발생할 확률이 크지 않습니다.
하지만 사람이 태깅한 entity 도 때로는 부적절한 것으로 인식될 수 있으므로, data error 플래그를 통해 report 를 받는 과정도 optional 하게 고려해볼 수 있습니다.
이는 조사와 entity 가 붙어 한 어절을 형성하는 경우가 많은 한국어에서 조금 더 조심해야 할 부분입니다.
Hate speech 나 social bias 를 포함한 문장과 같이 potential harm 이 있는 인스턴스의 경우 체크해두고 회의를 통해 이를 제거할 수 있습니다.
이에 관한 가이드라인을 별도로 만드는 것은 공수가 많이 들기 때문에, KLUE-RE 에 기술된 가이드라인을 활용하는 방안을 추천드립니다.

다행히, 프로젝트에서 활용되는 위키피디아에는 문제가 될 만한 표현들이 많이 등장하지는 않을 예정입니다:)
가장 주의해야 할 부분은 개인정보 부분입니다.
자주 묻는 질문:
FAQ 에서는 파일럿 태깅 및 가이드라인 제작 과정에서 발생하는 미묘한 문제들에 대한 해결 방안이 기술됩니다.
Relation 들 간의 관계가 잘 구분되고 명확할수록 이러한 모호함이 줄어들 수 있습니다. 또한, 이러한 FAQ 들을 서로 공유하고 난 후에 서로가 태깅한 내용들을 다시 한 번 보며 해당되는 부분들을 수정하는 시간도 필요합니다.

실제 어노테이션 진행
a. 파일럿 태깅
- 전체 코퍼스에서 일부를 태깅
- 총돌하는 부분들을 확인함으로써 서로의 가이드라인 이해가 맞는지 보기
b. 실제 어노테이션 진행
- 데이터를 나우어 각자가 맡은 데이터의 문장들에 대해 (Tagtog)
- entity (subject / object) 범위 설정
- 관계 태그 붙이기
- 각자가 entity 를 설정하고 관계 태그를 붙인 문장들을 (스프레드시트 or Labelstudio)
- 다른 사람들이 각각 tag
- Inter-annotator agreement 계산 (Fleiss’ Kappa)
실제 어노테이션 퀄리티 평가


평가지표

권장 역할분담

댓글남기기