Day_66 03. 관계 추출 관련 논문 읽기
작성일
관계 추출 관련 논문 읽기
Position-aware Attention and Supervised Data Improve Slot Filling

Overview


Slot Filling = Relation Extraction
The TAC Relation Extraction Dataset

TAC KBP 나 SemEval-2010 데이터셋이 양이적고 목적에 맞지 않아서 우리가 데이터셋을 만들었다

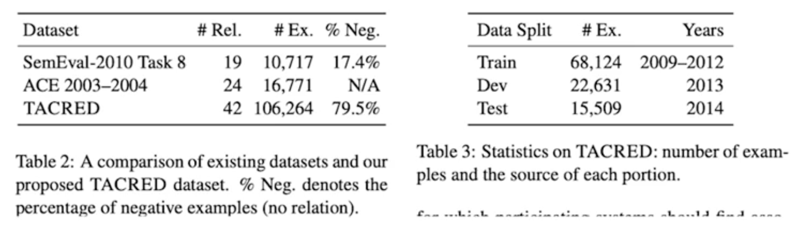
연도별로 데이터를 나눈것은 굉장히 편리하지만 label 이 균형있게 들어갈지는 미지수
통계를 미리 내보고 조정을 하는게 맞다고 생각함

Appendix

Data Collection 은 LDC 방법과 generated 방법을 사용
LDC 방식으로 10000개정도 generated 방법으로는 11만개 정도를 만들고 중복을 제거하니 10만6000개 정도의 샘플이 남았음
최소 5%의 여유분을 둬서 데이터를 제작하는것이 중요
크라우드소싱을 하는 경우엔 작업자들의 신뢰도향상을 위해서 현장검증을 끼워놓는 경우가 있음
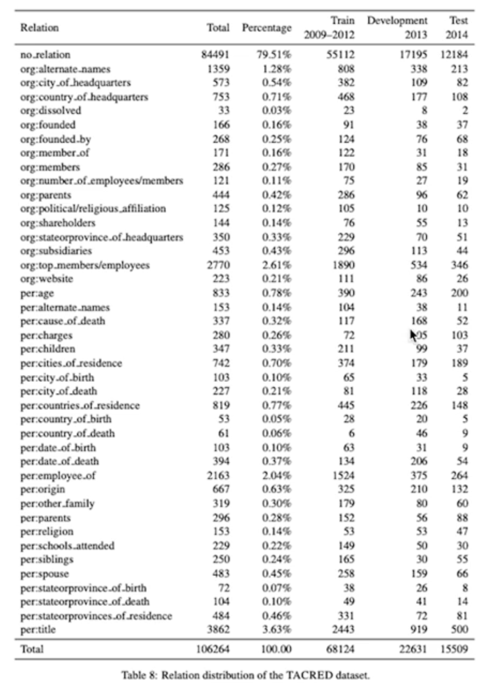

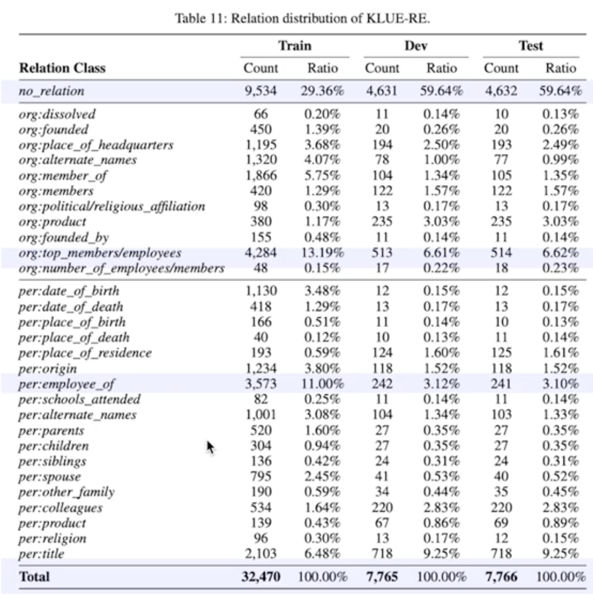
Train vs Dev vs Test 데이터셋의 레이블별 비율이 비슷한지 중간중간 계속 점검이 필요
참고 KBP 란? Knowledge Base Population (KBP)

https://nlp.stanford/edu/projects/kbp/
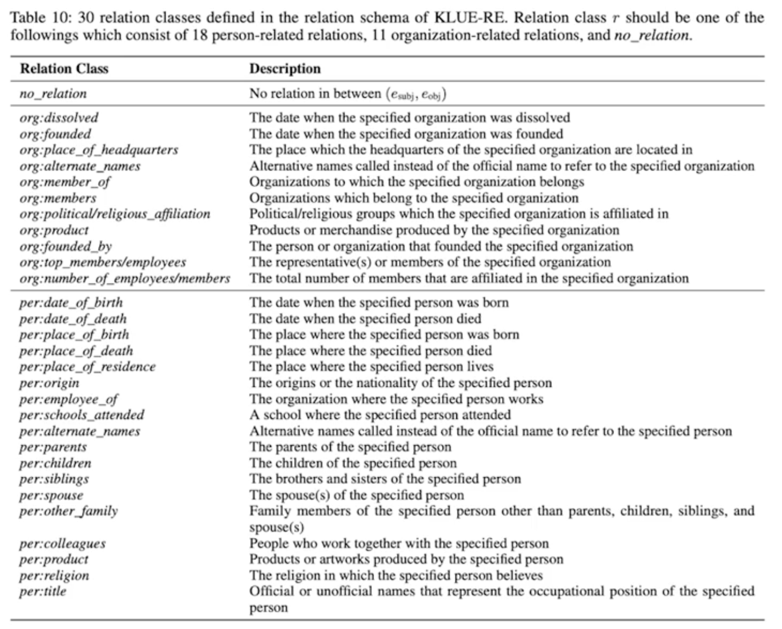
KLUE : Korean Language Understanding Evaluation
Overview

Data Construction

WIKIPEDIA : 문어
WIKITREE and POLICY : 신문기사

Entity 찾을 때 ELECTRA 를 사용해서 사람의 손을 타지않고 만듦

DeepNatural 크라우드소싱을 사용
Evaluation metrics

댓글남기기