Day_65 03. 자연어처리 데이터 소개 1
작성일
자연어처리 데이터 소개 1
국내 언어 데이터의 구축 프로젝트
국가 주도

민간 주도

21세기 세종 계획과 모두의 말뭉치
21세기 세종 계획
‘21세기 세종계획’은 1997년에 그 계획이 수립되었고 이듬해인 1998년부터 2007년까지 10년 동안 시행된 한국의 국어 정보화 중장기 발전 계획(홍윤표, 2009) 총 2억 어절의 자료 구축, 공개
XML 형식, 언어정보나눔터 누리집을 통해 배포하다 중단 후 DVD 로만 배포

21세기 세종 계획 - 세종 현대 문어 원시
<head>.*</head> : 제목
<p> : paragraph, 단락, 절
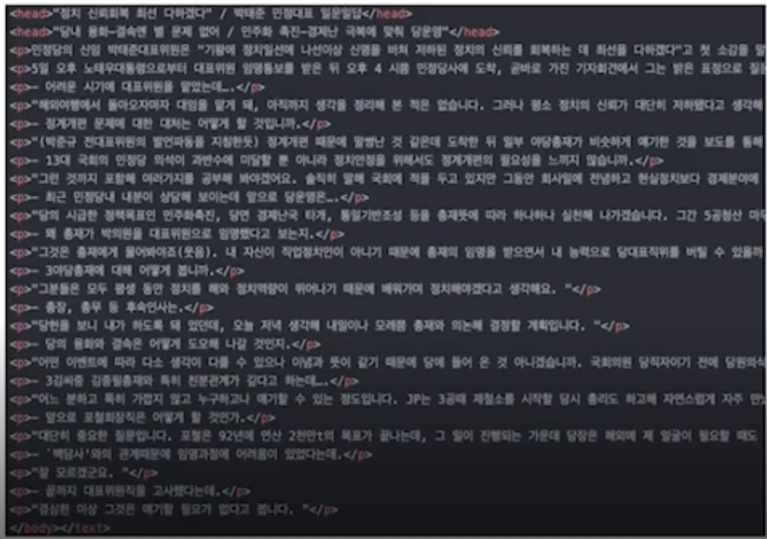
tag 안에 정돈되어 들어가있긴 하지만 언어학적인 주석 labeling 은 되어있지 않은 상태가 바로 세종 현대 문어 원시 texgit t 임
21세기 세종 계획 - 세종 현대 구어 원시
<u> : utterance 발화
<who> : 발화자
s : 억양 단위 표시, n을 이용하여 일련 번호 붙임
desc : description
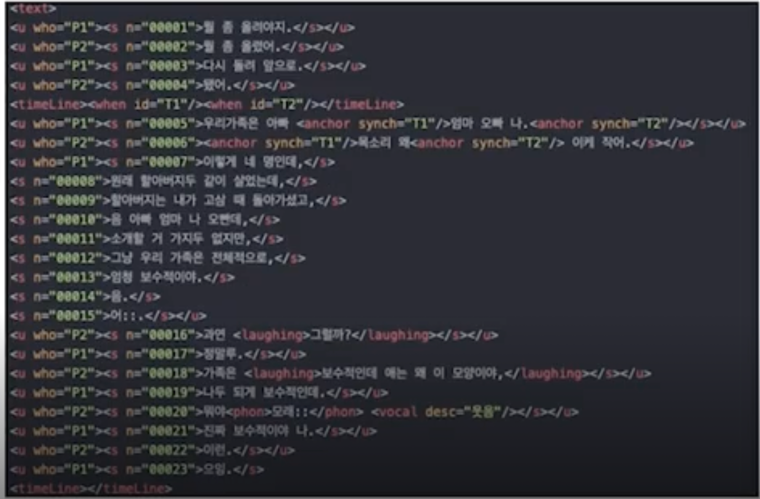
구어라는 것은 음성을 전체로 한 것이기 때문에 소리로 된 데이터가 있고 그걸 듣고 직접 만든 것이기 때문
21세기 세종 계획 - 세종 현대 문어 형태 분석
한국어 형태소 분석 방식의 원류
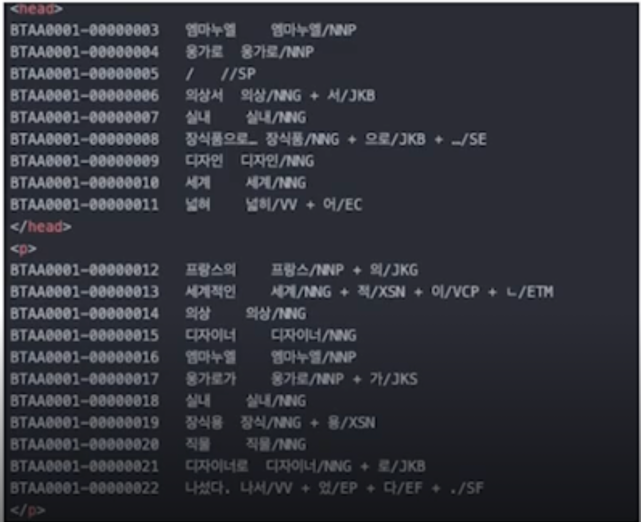

체언, 용언, 수식언, 독립언, 관계언 은 품사라고 불리고 의존형태는 품사가 아님
21세기 세종 계획 - 세종 현대 문어 구문 분석
Penn TreeBank 의 구구조 분석 방식을 따름
추후 모두의 말뭉치에서는 의존 구문 분석 방식으로 변경
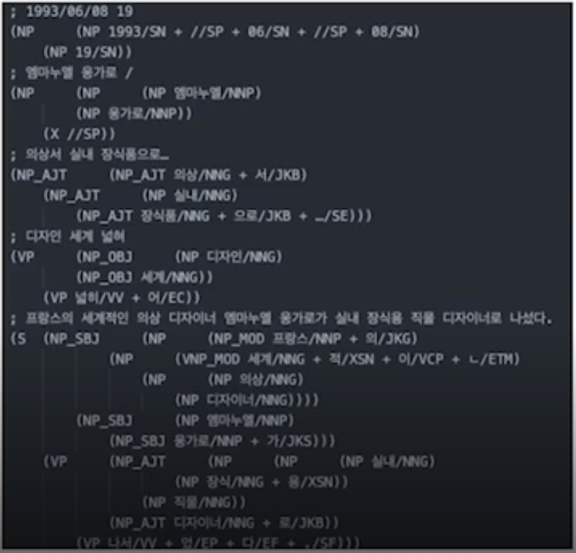
모두의 말뭉치
인공지능의 한국어 처리 능력 향상에 필수적인 한국어 학습 자료 공개 플랫폼. ‘21세기 세종계획’에 비해 일상 대화, 메신저, 웹 문서 등 구어체 자료의 비중을 높임
다층위 주석 말뭉치 포함(형태, 구문, 어휘 의미, 의미역, 개체명, 상호 참조 등)
JSON 형식, 모두의 말뭉치 누리집(https://corpus.korean.go.kr/)에서 배포
학습, 검증, 평가용 데이터가 나누어져 있지 않으므로 사용자가 직접 나누어 사용해야 함
원시 말뭉치와 주석 말뭉치로 구성
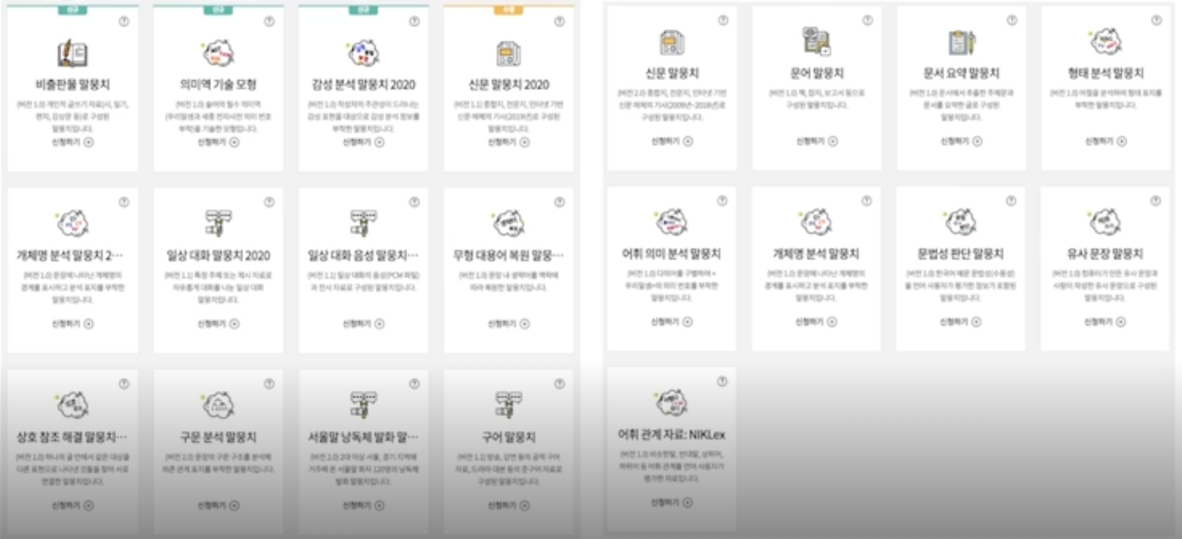
엑소브레인
엑소브레인(ExoBrain) : 내 몸 바깥에 있는 인공 두뇌
엑소브레인은 인간의 지적 노동을 보조할 수 있는 언어처리 분야의 AI 기술개발을 위해, 전문직 종사자(예: 금융, 법률, 또는 특허 등)의 조사 $\cdot$ 분석 등의 지식노동을 보조 가능한
- 언어 문법 분석을 넘어선 언어의 의미 추론 기술 개발
- 전문부야 원인, 절차, 상관관계 등 고차원 지식 학습 및 축적 기술 개발,
- 전문분야 대상 인간과 기계의 연속적인 문답을 통한 심층질의응답 기술 개발 및 국내외 표준화를 통해 핵심 IPR 을 확보
하는 우리나라 대표 인공지능 국가 R&D 프로젝트
21세기 세종 계획에서 개발된 주석 말뭉치의 체계를 확장하고 추가하여 TTA 표준안 마련(형태, 구문, 개체명)
http://exobrain.kr/pages/ko/business/index.jsp

ETRI 의 오픈 AI API, DATA 서비스 누리집에서 데이터셋 배포

https://aiopen.etri.re.kr/service_dataset.php
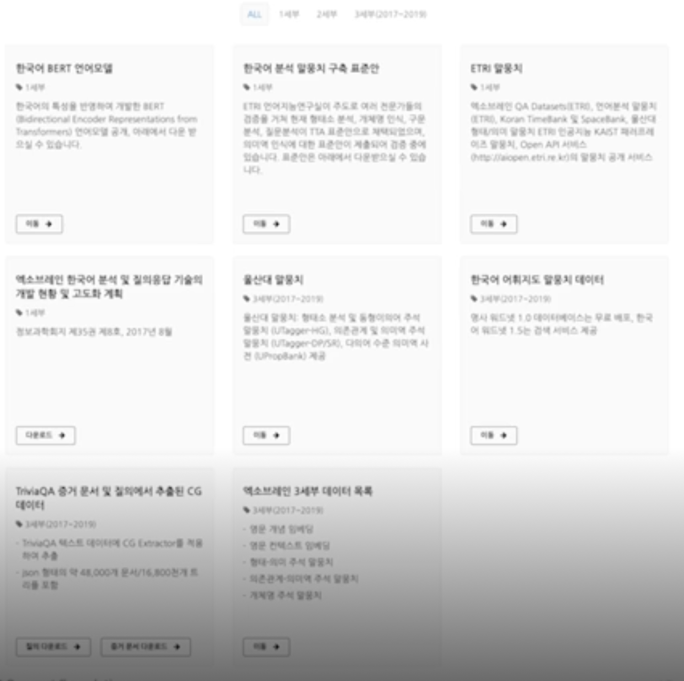
AI 허브
AI 허브는 AI 기술 및 제품 $\cdot$ 서비스 개발에 필요한 AI 인프라(AI 데이터, AI SW API, 컴퓨팅자원)를 지원하는 누구나 활용하고 참여하는 AI 통합 플랫폼
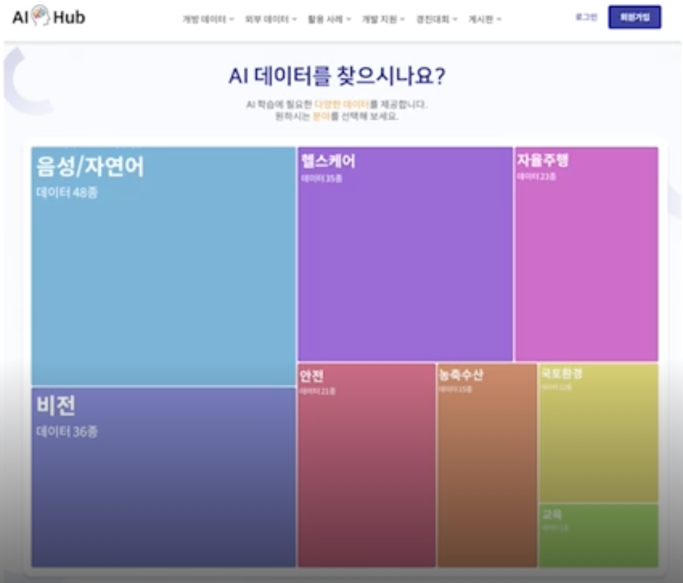
데이터별로 데이터 설명서, 구축활용 가이드 제공
JSON, 엑셀 등 다양한 형식의 데이터 제공
실제 산업계 수요 조사를 반영하여 다양한 TASK 를 수행할 수 있는 자원 구축
민간 주도 데이터셋
KLUE
한국어 이해 능력 평가를 위한 벤치마크
- 뉴스 헤드라인 분류
- 문장 유사도 비교
- 자연어 추론
- 개체명 인식
- 관계 추출
- 형태소 및 의존 구문 분석
- 기계 독해 이해
- 대화 상태 추적
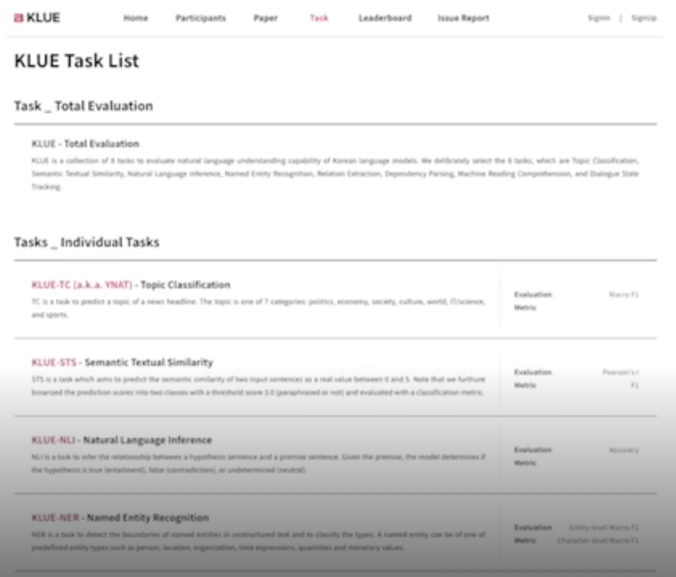
순수하게 한국어로 된 원시 말뭉치에서 그걸 가공해서 각각의 데이터를 만들었다는 점이 특별함
KorQuAD 1.0 & 2.0
KorQuAD 2.0 은 KorQuAD 1.0 에서 질문답변 20,000+ 쌍을 포함하여 총 100,000+ 쌍으로 구성된 한국어 기계 독해(Machine Reading Comprehension) 데이터셋)
스탠포드 대학교에서 공개한 SQuAD(https://rajpurkar.github.io/SQuAD-explorer/)를 벤치마킹
CC BY-ND 2.0 KR

https://korquad.github.io/
KorNLU
영어로 된 자연어 추론(NLI, Natural language inference) 및 문장 의미 유사도(STS, semantic textual similarity) 데이터셋을 기계 번역하여 공개
CC BY-SA 4.0
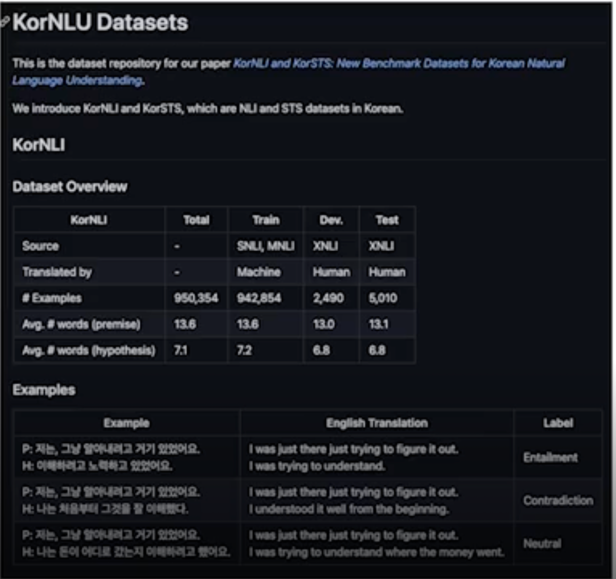
https://github.com/kakaobrain/KorNLUDatasets
순수한 한국어가 아니라서 가지고 있는 문제점을 안고있음
댓글남기기