Day_65 02. 자연어처리 데이터 기초
작성일
자연어처리 데이터 기초
인공지능 개발을 위한 데이터
데이터의 종류

워드넷이나 시소러스 같은 경우는 단어간의 관계를 나타낸 것
온톨로지나 지식그래프 같은 것들은 지식을 표상하기위한 체계에 따라서 각각 어휘들을 연결해 놓은 것 혹은 어휘들의 의미를 분석해 놓은 것
인공지능 기술의 발전
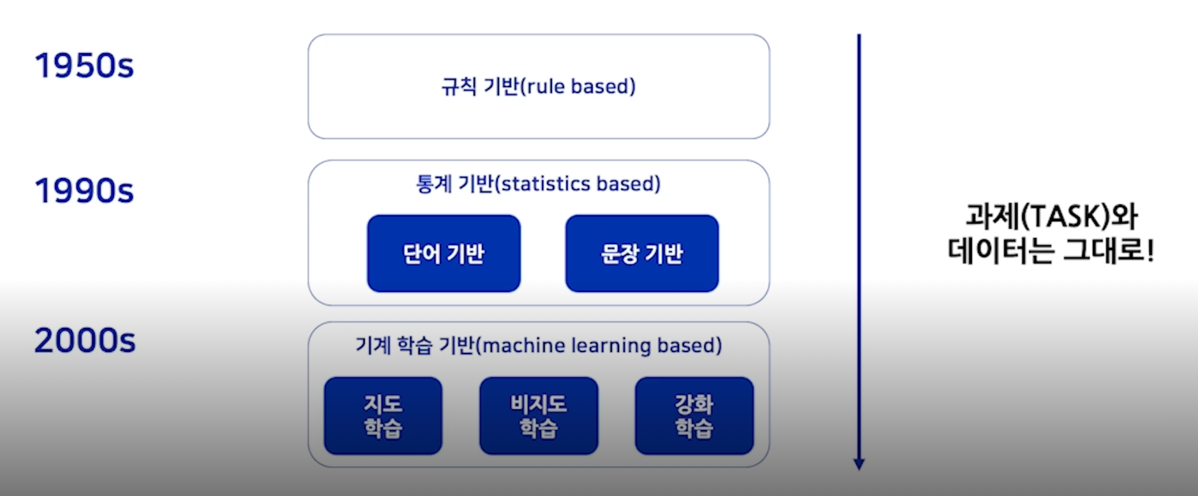
기술 자체는 변화했어도 궁극적인 풀고싶어하는 문제 대화시스템이라던지 기계번역이라던지 이런 것들은 유지되고 있음
언어 모델 평가를 위한 종합적인 벤치마크 등장
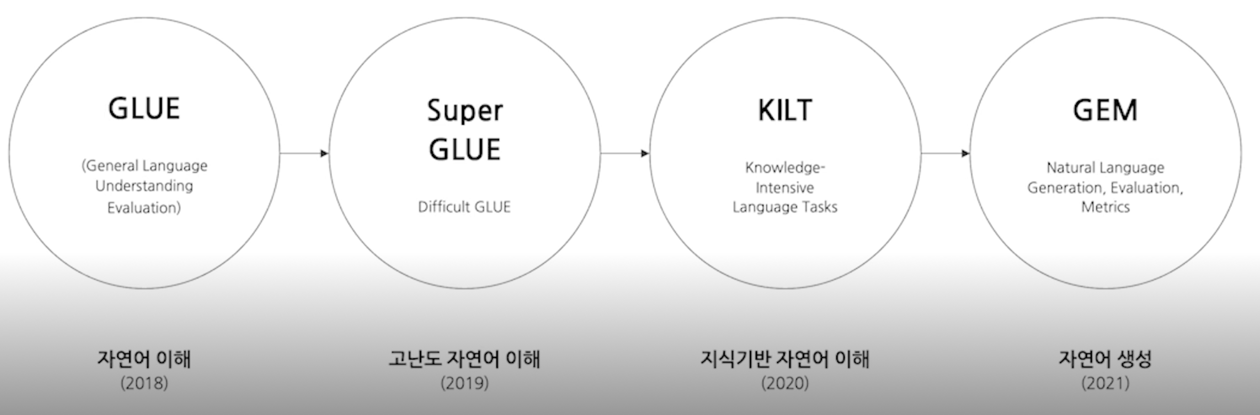
벤치마크의 구성

데이터 관련 용어 정리
텍스트 text
주석, 번역, 서문 및 부록 따위에 대한 본문이나 원문.
[언어] 문장보다 더 큰 문법 단위. 문장이 모여서 이루어진 한 덩어리의 글을 이룬다.
말뭉치 corpus, plural corpora
corpus 는 단수, corpora 는 복수
말뭉치(이상섭, 1988) : 어떤 기준으로든 한 덩어리로 볼 수 있는 말의 뭉치(한 저작자의 저작 전부, 특정분야 저작 전체)
텍스트 아카이브 text archive vs 말뭉치 corpus(seleted, structured, designed)
데이터 data
[정보 $\cdot$ 통신] 컴퓨터가 처리할 수 있는 문자, 숫자, 소리, 그림 따위의 형태로 된 정보.
말뭉치 데이터 corpus data : 말뭉치 자체
말뭉치의 데이터 data from corpus : 용례 색인 결과, 연어 추출 결과, 통계 분석 결과
주석
주석 : tag, label, annotation
주석하다 : tagging, labeling
분석하다 : analysis
형태소 분석기 vs 형태소 주석기
영어는 POS(Part of speech) tagger
- Segmentation
- Tagging
Why? 언어 사실을 분석하고자 하는 열망 반영
형태소의 주석을 다는 것은 분석을 하는것과 다른게 없다라고 생각
형태소 분석기의 기능은 실질적으로 2가지가 있을 수 있음
- 형태소 단위로 문장을 분리해주는 Segmentation 기능
- Segmentation 을 하고 난 뒤에 분할된 문자열에다가 형태소 tag NNG 라던지 VV 라던지 VA 이런 것을 붙여주는 작업을 하는 기능
언어학의 연구 분야

음성이나 음운은 자연어 text 에서 다루는 대상은 아님
단어나 구, 절, 문장, 텍스트 이런 것들이 앞으로 text 처리를 할 때 사용되는 개념들임
텍스트 데이터의 기본 단위
영어 말뭉치의 계량 단위 : 단어(=띄어쓰기 단위) / 문장 또는 발화
한국어 말뭉치의 계량 단위 : 어절(=띄어쓰기 단위) / 문장 또는 발화
한국어의 “단어” : 9품사로 분석됨(명사, 수사, 대명사, 동사, 형용사, 관형사, 부사, 조사, 감탄사)
이 중 “조사”는 체언(명사, 수사, 대명사)와 붙어서 사용되기 때문에 띄어쓰기 단위와 단어의 단위가 일치하지 않음! 또한, “어미”는 하나의 품사로 인정되지 않으며 형태 단위이므로 독립된 단어가 아님
품사 : 단어를 문법적 성질의 공통성에 따라 몇 갈래로 묶어 놓은 것
품사 분류의 기준 : 의미(뜻, meaning), 기능(구실, function), 형식(꼴, form)
품사중에서 동사와 형용사를 제외하고는 형태가 그대로 유지가 되고 동사와 형용사는 활용을하면서 형태가 바뀜
예를들면 달리다 먹다 마시다 이런것들이 동사고 예쁘다 하얗다 밝다 이런 것들이 형용사가 됨
타입 type & 토큰 token
토큰화 tokenization > 표제어 추출 lemmatization / 품사 주석 POS(part of speech) tagging
토큰 : 언어를 다루는 가장 작은 기본 단위, 단어 word, 형태소 morpheme, 서브워드 subword
타입 : 토큰의 대표 형태
한국어 예시
“이 사람은 내가 알던 사람이 아니다”
- 토큰화 : 이 사람 은 내 가 알 더 ㄴ 사람 이 아니 다
- 표제어 추출 : 이, 사람, 나, 알다, 아니다
- 품사 주석 : 이/MM 사람/NNG+은/JX 나/NP+가/JKS 알/VV+더/EP+ㄴ/ETM 사람/NNG+이/JKS 아니/VA+다/EF
- 토큰 수 : 12개, 타입 수 : 10개
영어 예시
“She is gone but she used to be mine”
- 토큰화 : She is gone but she used to be mine
- 표제어 추출 : She, be, go, but, use, to, mine
- 품사 주석 : she_PRP is_VBZ gone_VBN but_IN she_PRP used_VBD to_TO be_VB mine_JJ
- 토큰 수 : 9개, 타입 수 : 8개
N-gram
연속된 N개의 단위. 입력된 단위는 글자, 형태소, 단어, 어절 등으로 사용자가 지정할 수 있음
글자수 bi-gram
흔들리는 꽃들 속에서 네 샴푸향이 느껴진거야 : 흔+들, 들+리, 리+는, 는+꽃, 꽃+들, …
형태소 bi-gram
흔들리는 꽃들 속에서 네 샴푸향이 느껴진거야 : 흔들리+는, 는+꽃, 꽃+들, 들+속, 속+에서, …
어절 bi-gram
흔들리는 꽃들 속에서 네 샴푸향이 느껴진거야 : 흔들리는+꽃들, 꽃들+속에서, 속에서+네, …
표상 representation
대표로 삼을 만큼 상징적인 것.
표상-하다 [001] [동사] […을] 추상적이거나 드러나지 아니한 것을 구체적인 형상으로 드러내어 나타내다.
자연어처리 분야에서 표현으로 번역하기도 하나, 자연어를 컴퓨터가 이해할 수 있는 기법으로 표시한다는 차워에서 표상이 더 적합
표시를 통해 재현 과정을 통해 나타내는 작업
사전학습모델(PLM, pretrained language model), word2vec 등등
자연어처리 데이터 형식
HTML (Hypertext Markup Language)
우리가 보는 웹페이지가 어떻게 구조화되어 있는지 브라우저로 하여금 알 수 있도록 하는 마크업 언어
보통 웹페이지를 크롤링한 자료는 HTML 형식으로 되어 있음
파싱 라이브러리(beautifulsoup 등)을 통해 태그를 제외한 순수한 텍스트만 추출하여 사용
XML (Extensible Markup Language)
사람과 기계가 동시에 읽기 편한 구조
다른 특수한 목적을 갖는 마크업 언어를 만드는데 사용하도록 권장하는 다목적 마크업 언어
<> 안에 태그 정보를 부여
여는 태그 <> 와 다는 태그 </> 로 구성
**HTML 과의 차이 : HTML 은 태그가 지정되어 있으나 XML 은 사용자가 임의로 지정하여 사용할 수 있음
JSON (JavaScript Object Notation) 과 JSONL (JavaScript Object Notation Lines)
속상-값 쌍(attribute-valud pairs and array data types (or any other serializable value)) 또는 “키-값 쌍”으로 이루어진 데이터 오브젝트를 전달하기 위해 인간이 읽을 수 있는 텍스트를 사용하는 개방형 표준 포맷
기본 자료형 : 수, 문자열, 불린, 배열, 객체, null
JSONL 은 JSON 을 한 줄(Line)로 만든 것

CSV (comma-seperated values)
몇 가지 필드를 쉼표(,)로 구분한 텍스트 데이터 및 텍스트 파일
TSV (tab-seperated values)
몇 가지 필드를 탭(\t)로 구분한 텍스트 데이터 및 텍스트 파일
구분자(delimiter)의 차이
공개 데이터
경진대회 공개 데이터
국가 주도 공공 데이터
오픈소스 + benchmark
댓글남기기