Day_65 01. 데이터 제작의 A to Z
작성일
데이터 제작의 A to Z
데이터 제작의 P;ㅠ (피, 땀, 눈물)
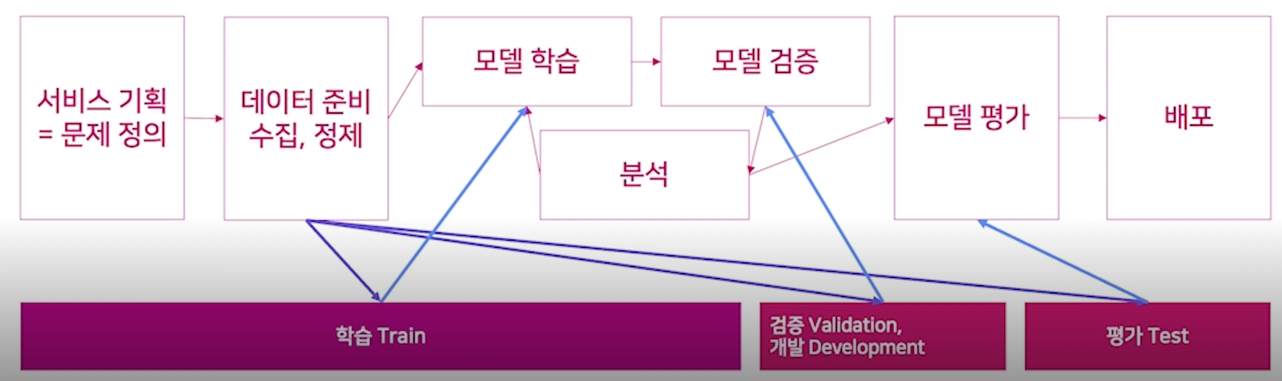
인공지능 서비스 개발 과정과 데이터
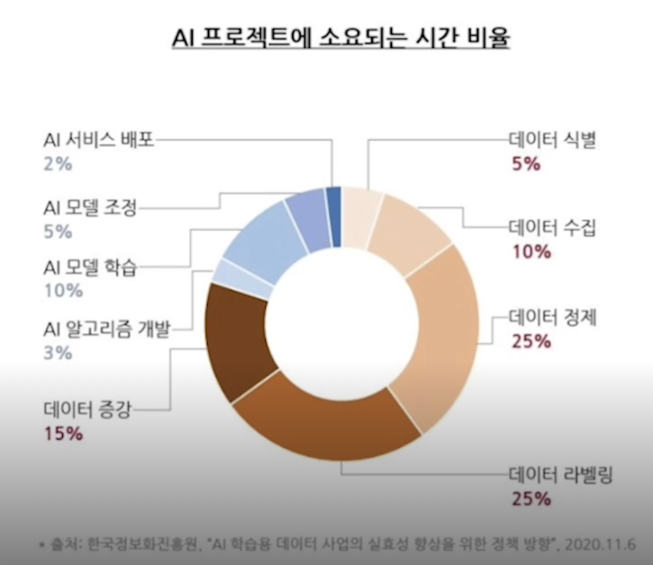
전체 프로젝트에서 데이터 관련 작업에 소요되는 시간비율 80%
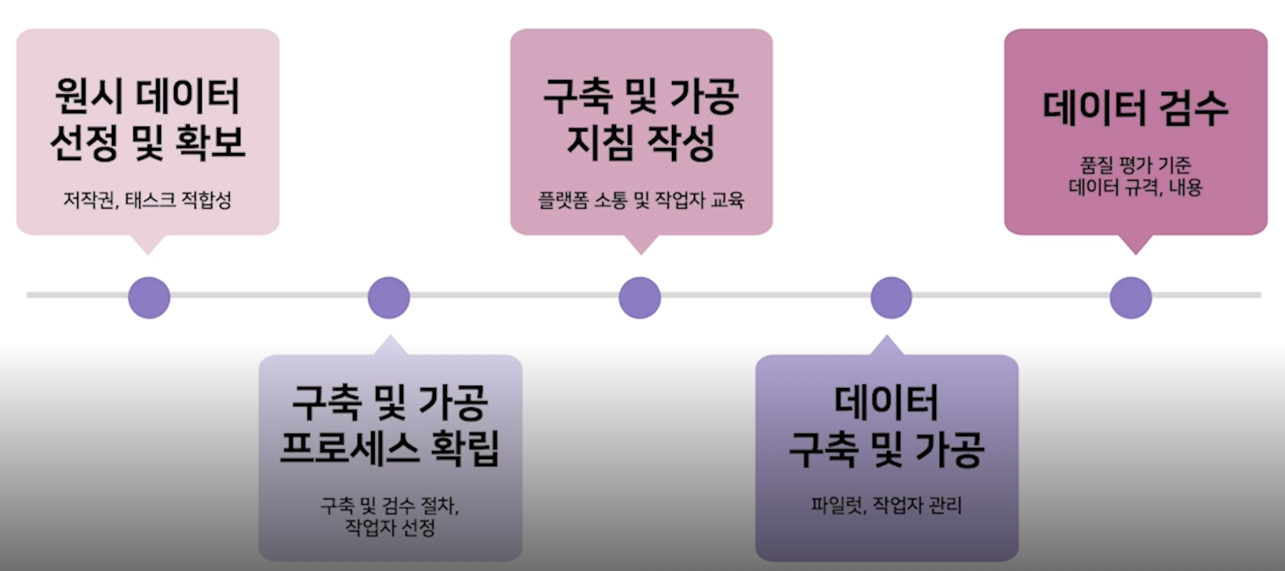
데이터 구축 과정
AI 데이터 설계의 구성 요소

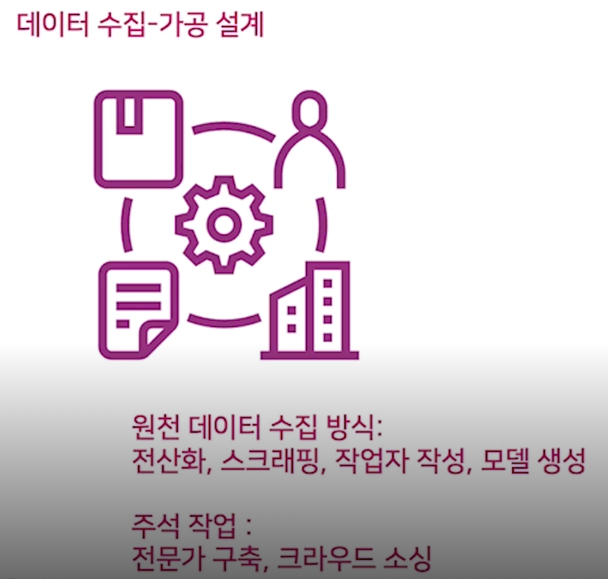
원천 데이터와 원시 데이터는 같은 말이라고 생각하면 좋음
데이터 설계
-
데이터의 유형
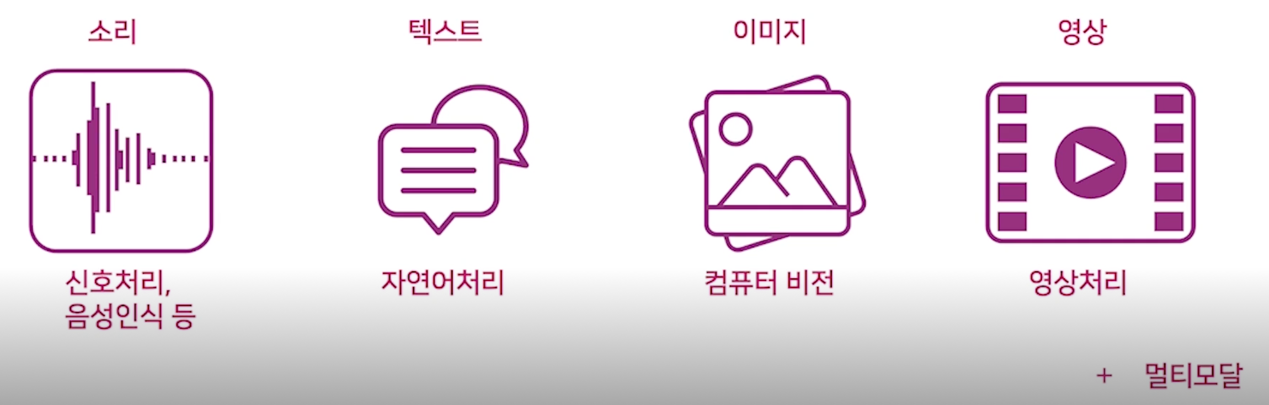
-
데이터의 In/Out 형식
HTML, XML, CSV, TSV, TXT, JSON, JSONL
JPG, Jpeg, PDF, png, ocr
.wav, .mp3, .pcm, .script어떤 것이 작업을 하는데 가장 효율적인지 신경써야함
특히 주석하는 작업을 거치게되면 언제든지 데이터의 형식이 바뀌게 되는데 어떻게 효율적으로 관리할것인가 하는 방법들을 고민해야함
-
데이터(train/dev(validation)/test)별 규모와 구분(split) 방식

규모 선정에 필요한 정보 : 확보 가능한 원시데이터의 규모, 주석 작업 시간
구분 방식 : 데이터별 비율과 기준 정하기
랜덤 vs 특정 조건 -
데이터의 주석(annotation) 유형
자연어처리
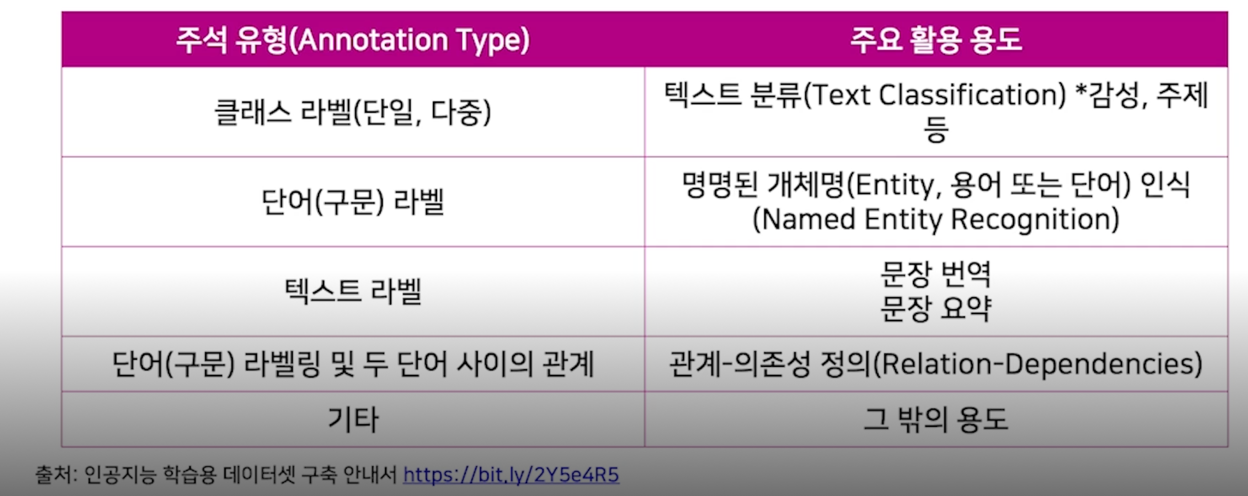
데이터 수집-가공 설계
-
원시 데이터 선정
전산화, 스크래핑, 작업자 작성, 모델 생성 : 적합한 데이터란 뭇엇인지 기준 세우기
-
작업자 선정
주석 작업의 난이도와 구축 규모에 맞는 작업자 선정 및 작업 관리

-
구축 및 검수 방법 설계
구축 작업의 난이도와 구축 규모, 태스크 특성에 맞는 구축 및 검수 방식(전문가, IAA) 설계
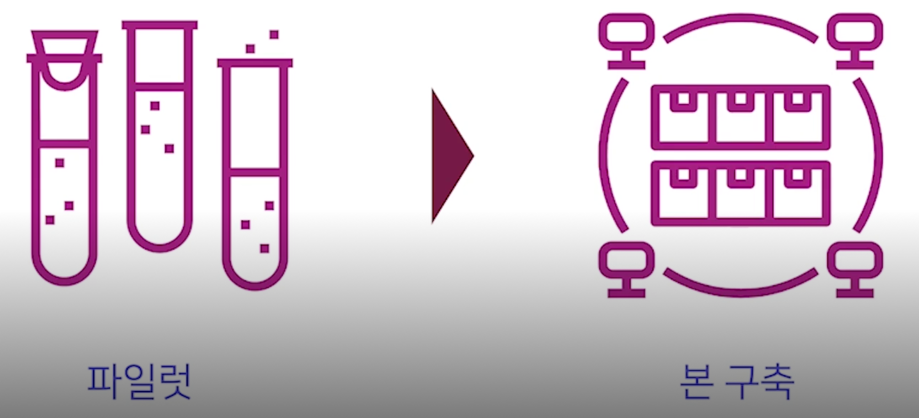
파일럿 작업의 경우 적게는 100개부터 많게는 1000~2000개 정도의 작업을 추천
일반적으로 머신러닝이나 딥러닝을 할 때의 최소수량이 10000개 단위로 생각하는데 문장을 기준으로 한다면 보통 30000문장 정도가 최수량으로 확보가 되어야하기 때문에 10% 정도를 파일럿으로 해본다고 생각하면 됨
전체 작업자들에게 하는 파일럿은 10% 정도라고 생각하면 되고 그거에 앞서서 가이드라인을 작성하고 이런 단계에서는 최소 100개정도의 샘플은 직접 해보면서 작업을 하는것을 추천 -
가이드라인 작성

본 구축을 할 때 끊임없이 일반 검수를 해나가면서 데이터의 품질을 관리하는것이 중요
그래서 본 구축을 1차, 2차, 3차로 나눠서 하는것이 일반적 -
데이터 검수 및 분석
평가 지표 설정

이때의 전문가는 실제 이 프로젝트를 설계한 사람 또는 의뢰한 레이블 agency 의 담당 PM 그리고 숙련된 작업자가 될 것임
자연어처리 데이터
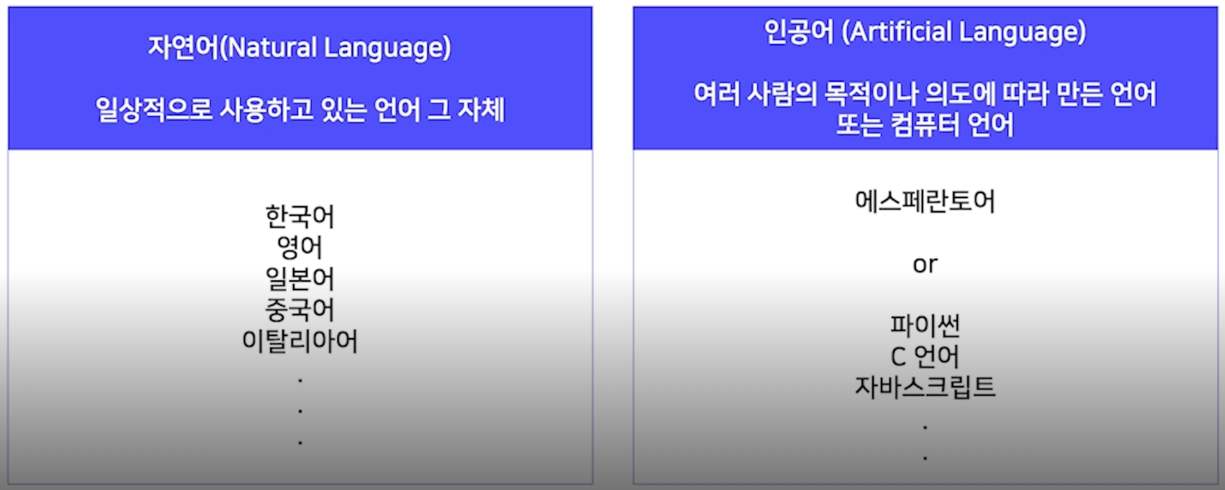
자연어란?
자연어처리(NLP, natural language processing)란?
인공지능의 한분야, 사람의 언어를 컴퓨터가 알아듣도록 처리하는 인터페이스 역할
자연어 이해 (NLU, natural language understanding)와 자연어 생성(NLG, natural language generation)으로 구성
자연어 처리의 최종 목표 : 컴퓨터가 사람의 언어를 이해하고 여러 가지 문제를 수행할 수 있도록 하는 것
자연어처리와 관련 연구 분야
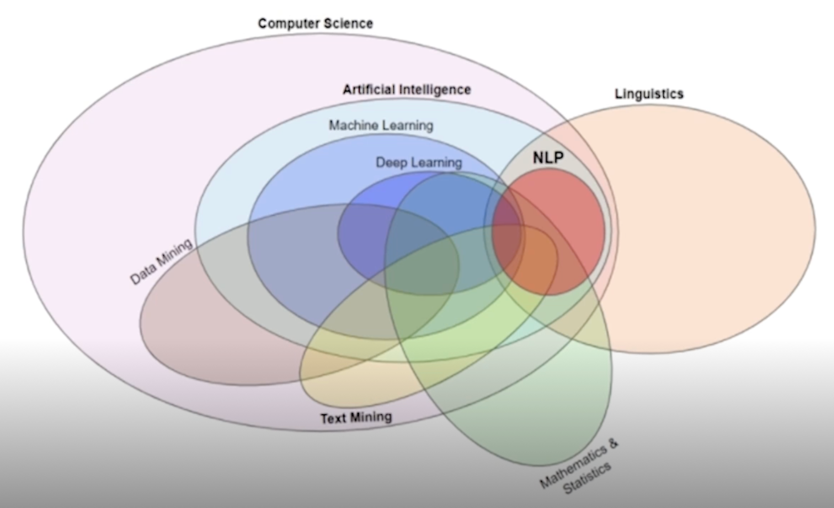
https://gritmind.blog/2020/10/09/nlp_overview/
언어학과 컴퓨터과학의 교점에 NLP 가 자리잡고 있고 NLP 라는 것은 크게보면 인공지능의 하위 한 분야이기도 함
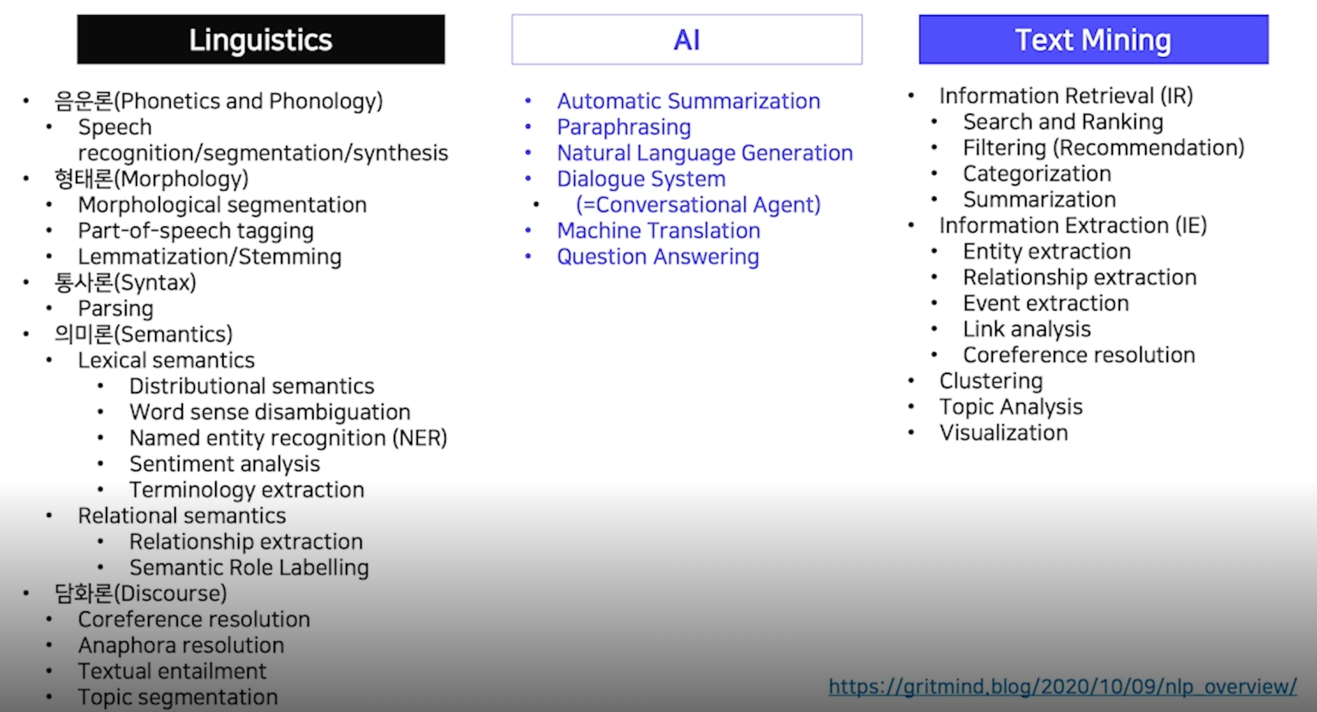
데이터 분류 방식
원천 데이터 장르(도메인) : 문어(뉴스, 도서 등), 구어(대화 등), 웹(메신저 대화, 게시판 등)
과제의 유형 :
- 자연어 이해(형태 분석, 구문 분석, 문장 유사도 평가 등)
- 자연어 생성(기계 번역, 추상 요약 등)
- 혼합(챗봇 등)
+ 자연어처리 데이터를 만들 때는 복잡한 과제도 단순화하여 단계별로 구축
댓글남기기