Day_50 [오피스아워] Elastic Search
작성일
[오피스아워] Elastic Search - 서중원 멘토
1. Retrieval 소개
IR(Information retrieval)의 관점으로 대표적으로는 Google Search
1.1 Boolean Retrieval
Boolean Retrieval 란?
쿼리 연산에 대해서 두가지 중 하나의 결과를 보여줌
- True or False
- Exact-match
일반적으로 Query 는 Bool 연산을 이용해 제공됨
- AND, OR, NOT
기본 가정은, “검색된 모든 결과는 동일하게 관련된 내용이다”
아직도 많은 검색 시스템은 Bool 연산을 활용
- 이메일, 인스타그램
일부 도메인에 대해서는 매우 효과적인
- 특허 검색
- 법률 검색
Boolean View
쿼리 실행
- 검색어로 들어온 Term 을 고르고
- Boolean 연산을 적용
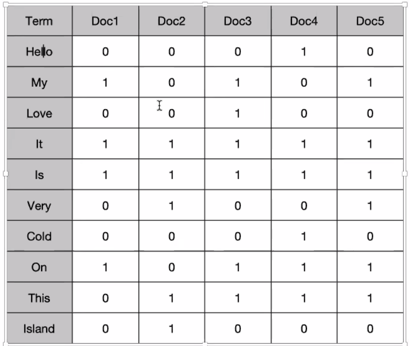
Boolean 검색 예제
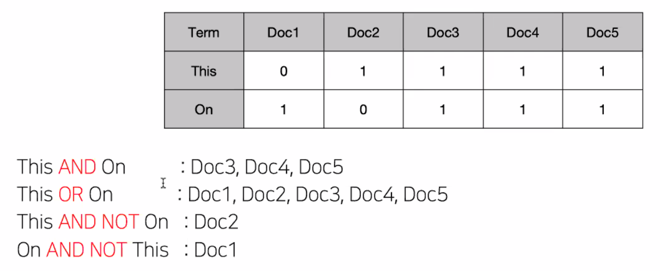
Google 에서 Boolean 검색 예제
Boolean 검색 장/단점
장점
- 검색 결과에 대한 설명이 쉬움(포함/미포함)
- 다양한 요소들이 검색에 함께 포함될 수 있음(이미지의 포함여부 등)
- 효율적인 연산(시작과 동시에 많은 문서들이 제외 될 것이기 때문에)
- 관련된 문서를 절대 놓치지 않음
단점
- 검색 결과의 퀄리티는 사용자의 쿼리 작성에 의해 달려있음
- 문서간 누가 더 유사한지의 랭킹이 X
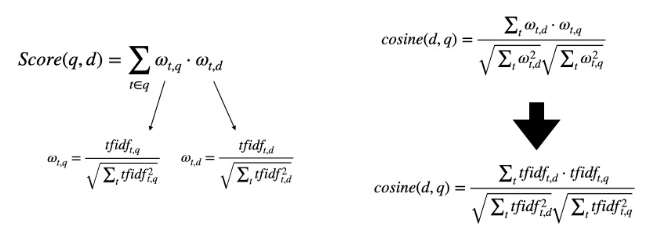
1.2 Rank Retrieval
Rank Retrieval 란?
score(d, q)
- 주어진 쿼리 q 에 대해서 각각의 문서의 점수를 계산
- Query = “Hello world”
How?
- $w_{t, d}$ : 문서(d)와 Term(t) 과의 가중치 계산
- $w_{t, q}$ : 쿼리(q)와 Term(t) 과의 가중치 계산
- 그리고 그 둘의 내적을 통한 유사도 계산
- 각각의 문서에 대한 점수 반환
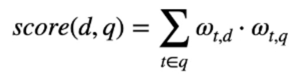
Scoring Example 1 - Term Frequency Weighting
$f_{t, d}$ : 문서 d 에서 term t 가 등장한 횟수 $f_{t, q}$ : 쿼리 q 에서 term t 가 등장한 횟수
Example
- Query : Hello, Hello world
- Term : Hello
- Document : “Hello, Hello, Hello world, programming is very fun”
- $f_{t, d}$ : 3
- $f_{t, q}$ : 2
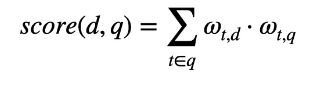
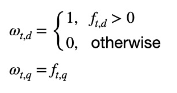
Scoring Example 2 - Log Frequency Weighting
문서에서 단어 횟수를 적절히 반영하기 위해서는?
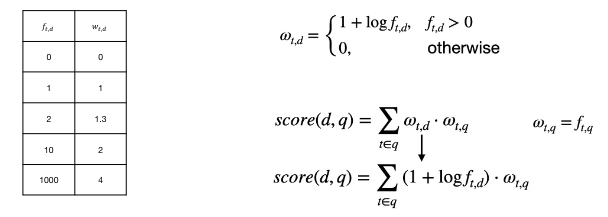
Vector Space Model (VSM)을 활용한 Rank Retrieval
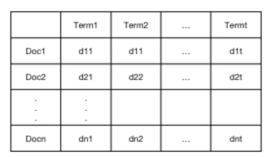
문서와 쿼리는 term 의 weight 들의 벡터로 표현됨
- 쉽게 표현하면, 문서와 쿼리는 단어들이 중요도에 대한 벡터임
Term 과 Document 의 매트릭스로 표현
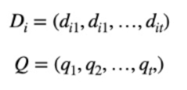
코사인 유사도
이전 슬라이드에서, 쿼리와 다큐먼트 둘 다 벡터로 표현을 했으므로, 문제를 재정의 가능
- 두 벡터 간의 유사도는 어떻게 구할 수 있을까?
Cosine 유사도
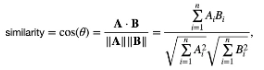
- 𝜃가 작을 수록 1에 가까워 진다.
단어가중치계산:어떤단어가얼마나중요한가?

너무 흔하지도 않지만, 너무 희귀하지도 않음

TF-IDF 를 활용한 랭킹함수
BM25: 우리는 1절만 하지 않지..

BM25 에서 직접 변경 가능한 파라미터

2. Elasticsearch
비정형 데이터 검색에 최적화된 데이터베이스
2.1 Elasticsearch Overview
Elasticsearch 는 어떻게 시작되었나?


이 이야기의 교훈은?
Elasticsearch 와 관련된 용어들

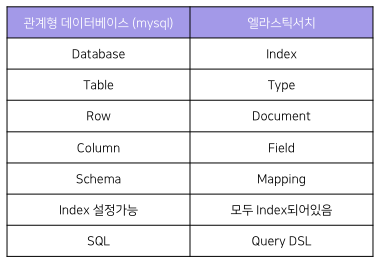
RDB vss Elasticsearch
2.2 Index
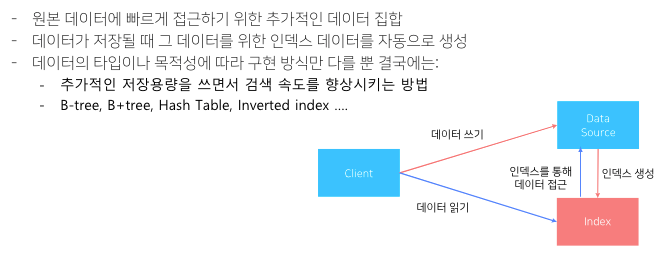
Index 란?
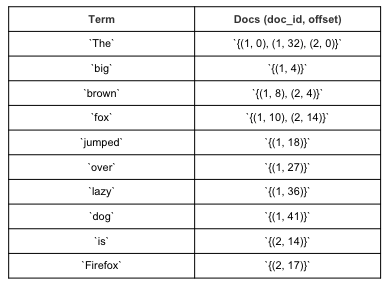
Big 이라는 단어를 포함하는 문서들을 찾는데 걸리는 시간 복잡도는?
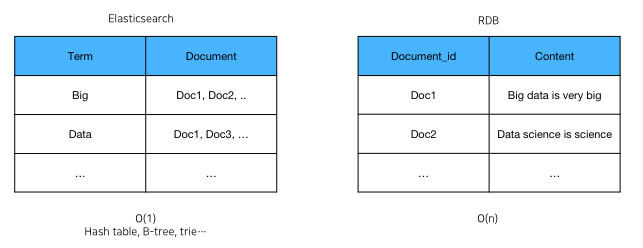
Inverted Index

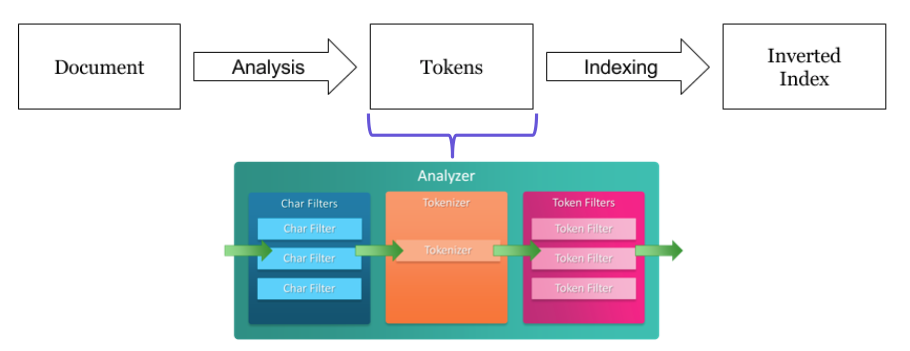
2.3 Elasticsearch setting
어떻게 Term 을 추출해야 좋을까?

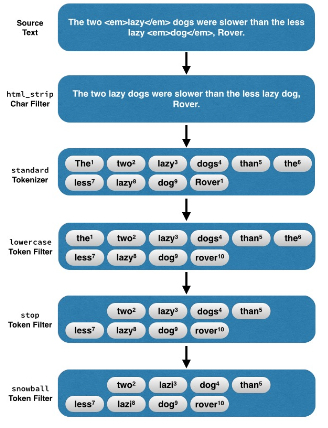
Analyzer
Tokenizer : 어떤 기준으로 단어를 자를 것인가?

참고사이트 : https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-tokenizers.html
Filter: 어떤 단어를 어떻게 바꿀 것인가?

Scoring: 쿼리와 문서간의 점수계산

참고사이트 : https://www.elastic.co/guide/en/elasticsearch/reference/current/index-modules-similarity.html
Mappings
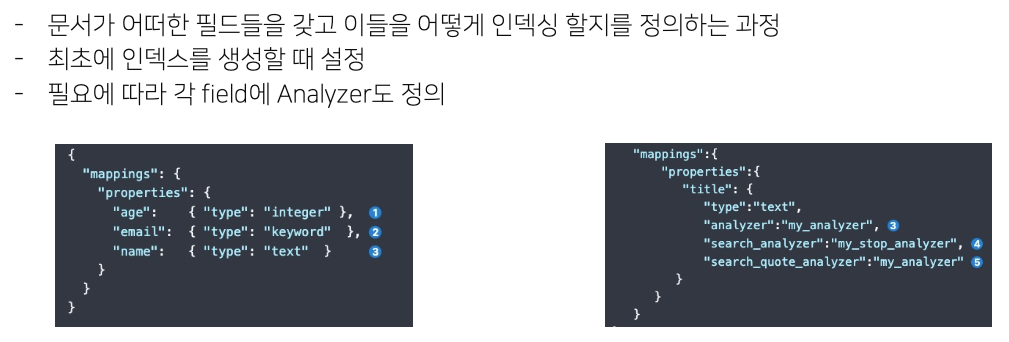
Settings


REST API

TMI: Elastic Stack

3. Practice
Retrieval 에서 Elastic search 를 활용하는 것도 좋을 듯
댓글남기기