Day_50 03. QA with Phrase Retrieval
작성일
QA with Phrase Retrieval
1. Phrase Retrieval in Open-Domain Question Answering
Current limitation of Retrieval-Reader approach
- Error Propagation : 5-10개의 문서만 reader 에게 전달 됨
- Query-dependent encoding: query 에 따라 정답이 되는 answer span 에 대한 encoding 이 달라짐

Error Propagation 이 항상 따라 다닐 수 밖에 없음
이게 어떤 의미냐면?
5-10개 정도의 문서만 찾아서 Reader 에게 전달하게 됨
근데 이 문서들이 사실 올바른 문서라는 보장이 없음
즉 Retrieval 이 잘 못하면 아무리 Reading Model 이 잘 한다고 하더라도 성능이 잘 안나오는 issue 가 있음
이런 문제를 해결하는 것이 굉장히 중요한 부분임
How does Document Search work?
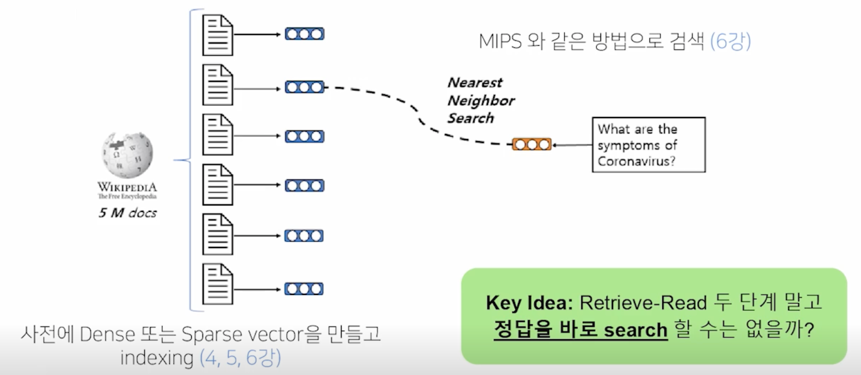
phrase search 는 document search 와 상당히 비슷함
document search 같은 경우는 실제로 문서를 가져오려고 할 때 이 문서에 대한 vector Dense or Sparse vector 를 만들고 indexing 을 한 다음에 새로운 question 이 들어오면 관련 있는 문서를 찾는 방법론으로 Nearest Neighbor Search 나 MIPS 를 활용하여 문서를 찾았음
이런 방법으로 문서를 찾듯이 문서검색을 하듯이 정답 즉 phrase 를 바로 검색할 수 없을까? 라는 아이디어에서 출발한 접근법임
One solution: Phrase Indexing

이런 문서가 있다고 치면 이 문서에 존재하는 모든 phrase 를 enumerate 시킴

이것들을 일종의 memory values 라고 볼 수 있음
모든 존재하는 phrase 들을 enumerate 시킨 다음에 이 각각에 대한 phrase 에 대한 embedding 을 오른쪽에 맵핑해줌
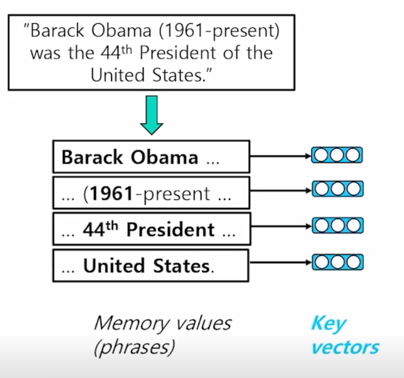
이 벡터들을 key vecotr 라고 볼 수 있고 이렇게 해놓으면 질문이 들어왔을 때 질문에 해당되는 vector 와 가장 가까운 key vector 를 찾는 방식으로 문제를 치환할 수 있음
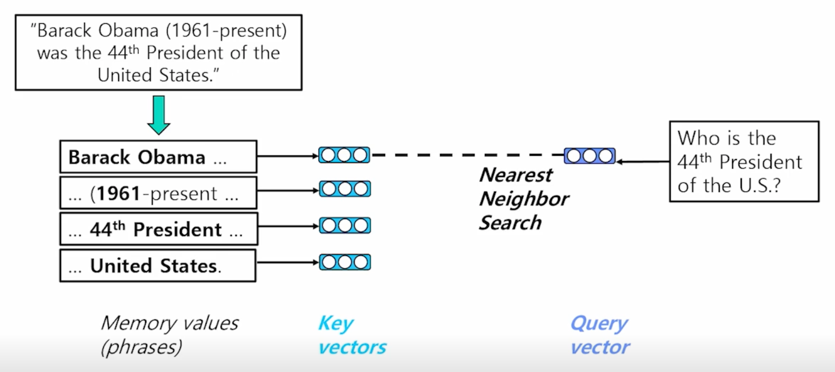
이렇게 되면 새로운 지문이 들어온다 하더라도 key vector 들은 update 가 필요 없이 새로운 question 에 대한 vector 만 계산을 해서 key vector 에 연결해주는 방법을 취할 수 있음
Query-Agnostic Decomposition

실제로 이렇게 접근하게되면 기존의 MRC 모델 같은 경우 F 라는 scoring function 을 구하는 문제라 볼 수 있음
이 scoring function 을 가능한 모든 candidate 과 그리고 질문과 문서가 input 으로 들어오게되고 이 3개를 모델에 넣어줌으로써 답변이 scoring 해주는 구조임
이 모든 가능한 triplet 중에서 가장 점수가 높은 triplet 을 골라주는 구조임
이런 모델을 정의하고 난 다음에 학습을 한 후에는 실제로 inference time 때는 어떤 a 를 저기에 넣어줘야 가장 높은 score 가 나오는지를 구하는 방식이라고 볼 수 있음
이런 방법론의 큰 문제는 새로운 질문이 들어왔을 때 a 랑 d 는 똑같다고 하더라도 왜냐하면 a 는 fix 된 corpus 내에 있는 phrase 들이니까
새로운 질문이 들어올때마다 F 라는 function 을 다시한번 계산해줘야 하는 불편함이 있음
이런 불편함을 phrase retrieval 방법으로 접근하게되면 G 와 H 라는 encoder function 을 정의하는 것이고 여기서 G 는 question 을 encoding 해서 vector space 에 mapping 해주고 H 같은 경우는 각 answer candidate 와 문서를 vector space 에 mapping 해줘서 Inner product 가장 높은 or Nearest Neighbor distance 가 가장 가까운 a 를 찾는 방식으로 문제를 치환할 수 있음
이렇게 문제를 치환해주는게 phrase retrieval 로 치환하는것과 똑같은 방법인건데 이렇게 해주게되면 장점은 명확함
H 쪽에 문서들을 다시한번 encoding 할 필요가 없음
질문이 들어올때마다 G 만 돌리고 H 는 그대로 두면 됨
그렇기때문에 효율적이고 Inner product 또는 Nearest Neighbor Search 는 상당히 효율적으로 큰 개수의 d 와 a 에서 찾을 수 있기때문에 상당히 빠름
하지만 가장 큰 단점은 중요한 assumption 이 있다는 건데 F 라는 function 이 정의되었을 때 F 가 G 와 H 로 나눠질 수 있다는 가정자체가 틀릴 수 있기 때문임
F 가 G 와 H 로 나눠질 수 있다는 보장이 없음
여기서 말하는 F 라는 function 은 간단한 function 이 아니고 상당히 복잡한 function 임
이 복잡한 function 이 decompose 된다는 보장은 없음
따라서 실질적으로는 exact 하게 decompose 하기 보다는 G 랑 H 를 학습을 하되 최대한 F 를 미닉하는 approximate 하는 방식으로 갈 수 밖에 없음

이랬을 때 key challenge 라고 볼 수 있는 부분은 어떻게 phrase 를 G 나 H 를 모델링하여 vector space 상에 잘 mapping 할 수 있을까? 라고 볼 수 있고 그 중 하나의 solution 은 Dense 와 Sparse 둘 다 사용해보는 방법이 있음
2. Dense-sparse Representation for Phrases
Dense vectors vs Sparse vectors
- Dense vectors: 통사적, 의미적 정보를 담는데 효과적
- Sparse vectors: 어휘적 정보를 담는데 효과적
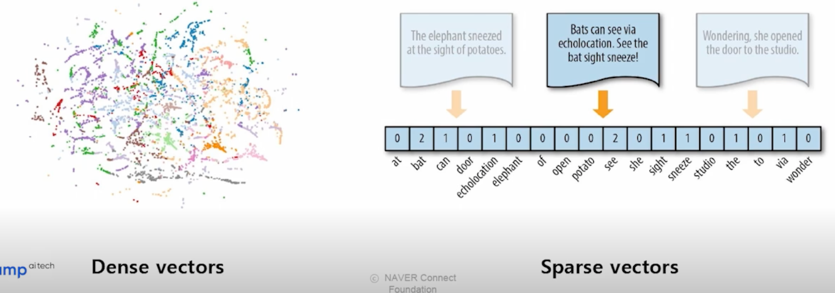
Phrase and Question Embedding
Dense vector 와 sparse vector 를 모두 사용하여 phrase (and question) embedding
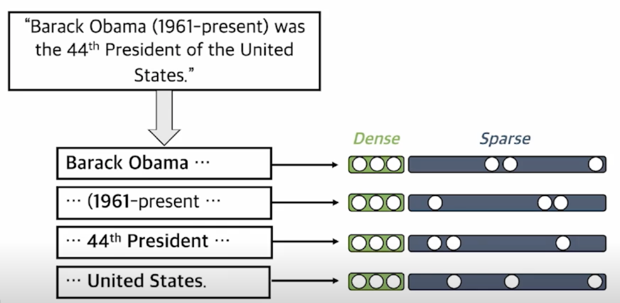
둘을 모두 활용하는 방법은 간단함
각각의 phrase embedding 을 구할 때 Dense 만 쓰는 것이 아니라 sparse 까지 계산한 후에 두 가지의 vector 를 합쳐줘서 하나의 vector 로 고려하고 Inner product 나 nearest neighbor sesarch 를 진행함
그러면 Dense 나 Sparse vector 를 어떻게 계산해야 할까?
Dense representation
Dense vector 를 만드는 방법
- Pre-trained LM(e.g. BERT)를 이용
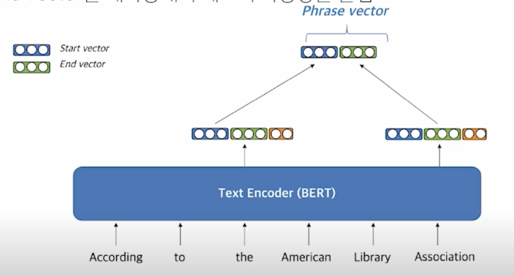
- Start vector 와 end vector 를 재사용해서 메모리 사용량을 줄임
시작점의 vector 와 끝점의 vector 를 합쳐줘서 phrase vector 를 정의함
예를 들면 아래와 같이 “the American Library Association” 에 해당하는 phrase vector 를 구하고 싶다고 한다면 “the” 에 해당하는 vector 일부분과 “Association” 에 해당하는 vector 일부분을 가져와서 두개의 vector 를 붙이고
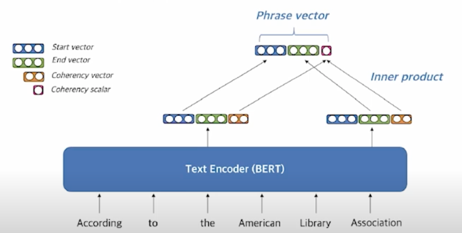
맨 마지막에 간단하게 하나의 숫자를 더해줌으로써 phrase 가 좋은 phrase 인지 아닌지를 표시하고 정답일 것 같지 않은 phrase 들을 걸러내기 위한 용도로 쓰임
Coherency vector
- phrase 가 한 단위의 문장 구성 요소에 해당하는지를 나타냄
- 구를 형성하지 않는 phrase 를 걸러내기 위해 사용함
- Start vector 와 end vector 를 이용하여 계산
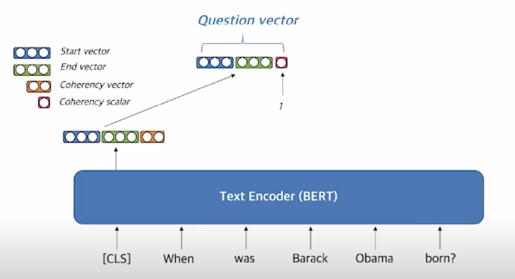
Question embedding
- Question 을 임베딩할때는 [CLS] 토큰 (BERT) 을 활용
Sparse representation
Sparse vector 를 만드는 방법
- 문맥화된 임베딩(contextualized embedding)을 활용하여 가장 관련성이 높은 n-gram 으로 sparse vector 구성
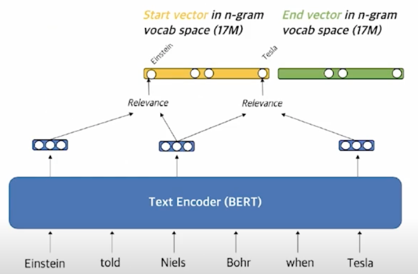
target 으로 하고 있는 phrase 에 들어있는 단어들과 유사성을 계산해서 그 유사성을 각 단어에 해당하는 sparse vector 상의 dimension 에 넣어줌으로써 일종의 TF-IDF 와 비슷하지만 TF-IDF 와 다르게 각 phrase 마다 weight 가 dynamic 하게 변하는 형태의 vector 로 만들어 줄 수 있음
uni-gram 뿐만 아니라 n-gram 을 활용하여 겹치는 부분까지 어느 정도 정보를 활용할 수 있음
Scalability Challenge
In Wikipedia: 60 billion 개의 phrase 가 존재 $\rightarrow$ Storage, indexing, search 의 scalability 가 고려되어야 함
- Storage Pointer, filter, scalar quantization 활용 (240T storage $\rightarrow$ 1.4T storage)
- Search: FAISS 를 활용해 dense vector 에 대한 search 를 먼저 수행 후 sparse vector 로 reranking
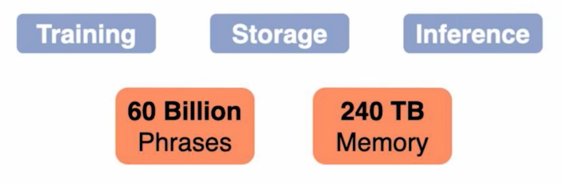
실제로 이렇게 했을 때 가장 큰 issue 중 하나는 wikipedia 에는 600억개의 phrase 가 존재하고 이런 것들을 다 저장하고 indexing 을 한다음에 검색을 하기 위해서는 정말 scalability(확장성)가 고려되어야 함
저장공간도 엄청 필요하고 이거를 여러가지 trick 으로 1.4T 까지 줄일 수는 있음
그리고 검색을 할 때도 검색할 대상이 워낙 크다보니까 수십억 단위다 보니까 FAISS 를 활용해 마찬가지로 빠르게 검색을 하려고 하는데 FIASS 같은 경우에는 dense vector 에 대한 검색만 가능하고 sparse 에 대한 검색을 할 수 없기 때문에 dense part 를 먼저 검색하고 그 다음에 sparse part 를 score 를 계산해서 reranking 하는 방식을 취함
3. Experiment Results & Analysis
Experiment Results - SQuAD-open
SQuAD-open (Open-domain QA)
- s/Q : seconds per query on CPU
#D/Q: number of documents visited per query- DrQA (Retriever-reader) 보다 +3.6% 성능 / 68x 빠른 inference speed (less than 1s)
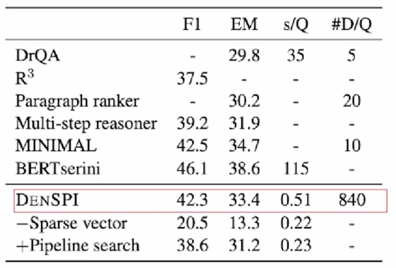
phrase 를 retrieval 할 때 연산량이 워낙 적다보니까 가질 수 있는 이점임
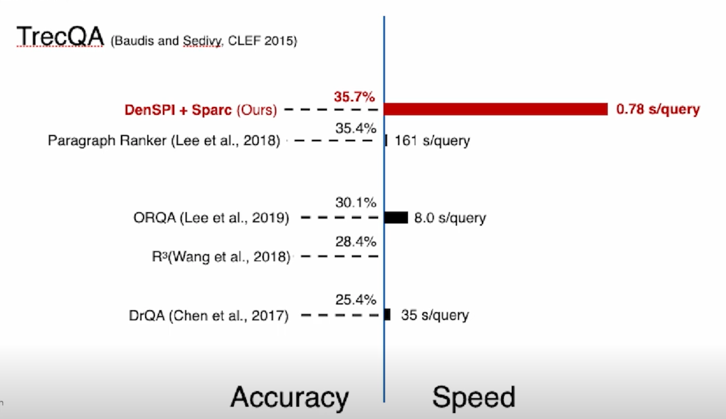
accuracy 도 높고 speed 도 빠른걸 알 수 있음
Limitation in Phrase Retrieval Approach
- Large storage required : 2TB SSD for phrases
- 최신 Retriever-reader 모델들 대비 낮은 성능
- SQuAD-open 결과: (EM) 38.6 (BERT serini) - Retriever-reader vs. 33.4 (DenSPI) - Phrase retrieval
- Natural Questions (NQ) 에서 낮은 성능
$\rightarrow$ Decomposability gap 이 하나의 원인

단점으로는 CPU 가 적어도 4코어 가 필요하고 RAM 도 적어도 30GB 필요하고 저장공간도 1.5TB 이상의 공간이 필요함
하지만 GPU 는 필요없음
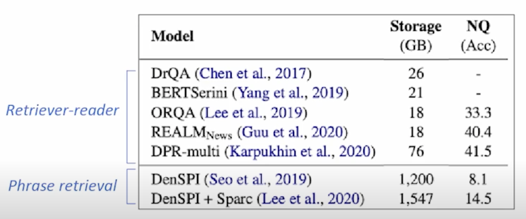
당시에는 비교적 성능이 잘 나왔지만 이후에 나온 모델과 비교해서는 낮은 성능임
- Decomposability gap
- (기존) Question, passage, answer 가 모두 함께 encoding
$\rightarrow$ (Phrase retrieval) Question 과 passage/answer 이 각각 encoding $\rightarrow$ Question 과 phrase 사이 attention 정보 x
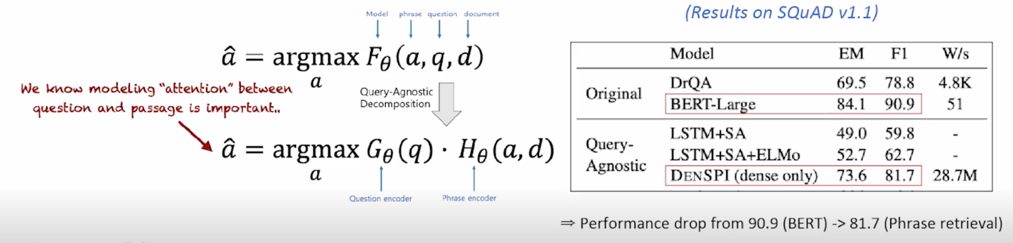
실제로 MRC 데이터에 똑같은 환경으로 실험을 해봤을때도 Decomposability gap 이 9% 정도 나는 것을 오른쪽에서 볼 수 있음
댓글남기기