Day_50 02. Closed-book QA with T5
작성일
Closed-book QA with T5
1. Closed-book Quesiton Answering
Current approaches of building QA system
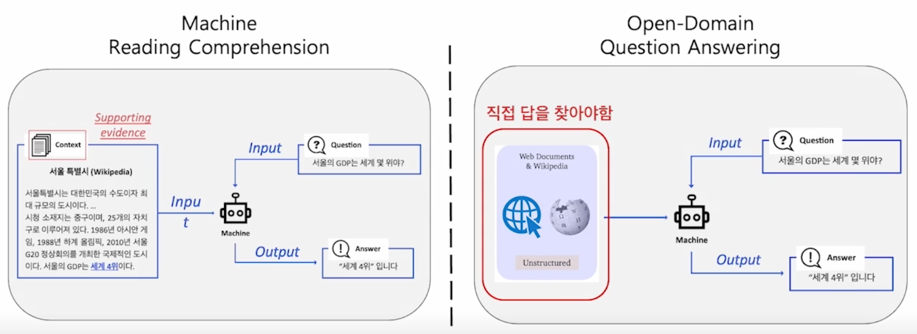
Open-Domain Question Answering system 을 접근하는 방식은 문서를 주거나 또는 문서가 주어지지 않았을때는 전체 웹 corpus 에서 해당되는 문서를 찾아서 머신러닝 모델한테 이 문서를 주어지고 그 다음에 모델들이 답을 찾는 방식으로 진행됨
보시다시피 왼쪽은 MRC Problem formulation(문서가 주어진 경우)이고 이 경우에 모델이 답을내는 방식임
오른쪽같은 경우는 문서가 없는 경우 어떤 문서를 봐야하는지 모르는 경우 web corpus 에서 해당 문서를 찾아서 retrieval 모델로 찾았고 답을 내주는 방식을 취함
이런 approach 들이 2018년 2019년까지 대부분이 이런 방식을 취했다고 한다면 2019년에 새로운 방식으로 이 문제를 접근했던 방법론이 있는데 이런 방법론을 흔히 Closed-book QA 형태라고 부름
Idea of Closed-book Quesation Answering
모델이 이미 사전학습으로 대량의 지식을 학습했다면, 사전학습 언어모델 자체가 이미 하나의 knowledge storage 라고 볼수 있지 않을까?
$\rightarrow$ 굳이 다른 곳에서 지식을 가져와야 할 필요가 없지 않을까?
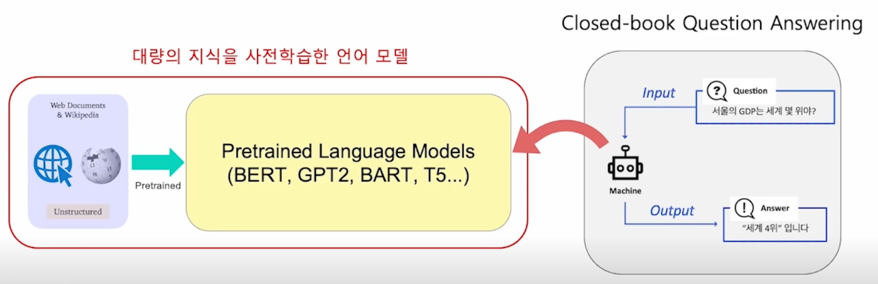
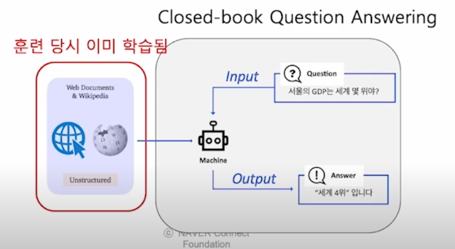
open-book 이냐 closed-book 이냐는 질문에 답하기 위해서 우리가 모델한테 책이라고 볼 수 있는 어떤 거대한 web corpus 를 access 할 수 있도록 주어질 것이냐 아니면 그렇지 않고 완전히 그런거 없이 모든 정보를 모델 내에서 어떻게든 답을 내는 방식으로 갈 것이냐의 차이임
그림을 보면 input 으로 question 만 있고 모델이 바로 답을 해야하는 경우임
이런 것들이 과거에는 상당히 어려웠지만 최근에 BERT 와 같은 large pretrained 된 모델을 활용하면서 이런 가능성이 있음을 알게되었음
모델이 사전학습으로 대량의 지식을 학습하였다면 사전학습 모델 자체가 이미 하나의 knowledge storage 로 볼 수 있음
이런 가정이 있다면 굳이 다른 곳에서 지식을 가져올 필요가 있는가에 대한 답변으로 꼭 그렇지 않다는 것을 보여준 사례라고 볼 수 있음
Zero-shot QA performance of GPT-2
사전학습 시 전혀 본적 없는 Natural Questions 데이터셋에도 어느 정도 대답이 가능함

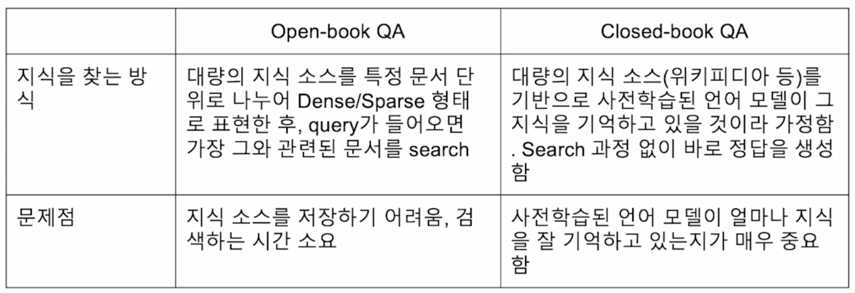
Open-book QA vs. Closed-book QA
2. Text-to-Text Format
Closed-book QA as Text-to-Text Format
Closed-book QA 에 사용되는 방법은 Generation-based MRC 와 유사함 (3강)
$\rightarrow$ 단, 입력에 지문(Context)가 없이 질문만 들어간다는 것이 차이점
$\rightarrow$ 사전학습된 언어 모델은 BART 와 같은 seq-to-seq 형태의 Transformer 모델을 사용함
$\rightarrow$ Text-to-Text format 에서는 각 입력값(질문)과 출력값(답변)에 대한 설명을 맨 앞에 추가함
모든 종류의 문제를 text 에서 text 로 맵핑되는 문제로 치환하는 것임
이 format 에서는 각 입력값과 출력값에 대한 설명을 맨 앞에 추가함으로써 모델이 어느정도 처음보는 task 라 하더라도 handle 할 수 있도록 함
Text-to-text problem : input 으로 text 를 받아서, output 으로 새로운 text 를 생성하는 문제
다양한 text processing problem $\rightarrow$ Text-to-text 문제로 변형
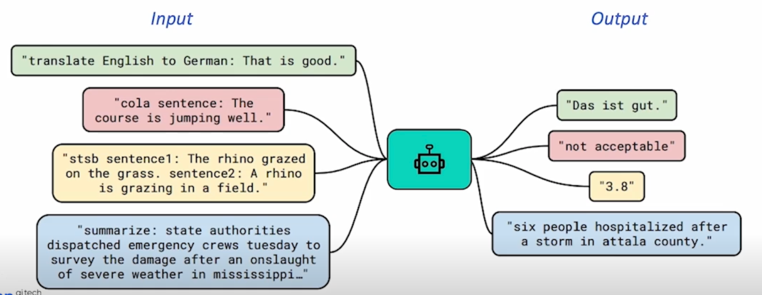
다양한 종류의 task-specific problem 을 language 관련된 problem 을 결국 설명이 첨가된 input 과 그에 대응되는 output 을 내보내는 방식으로 문제를 변형해서 결국 통일한 것임
이렇게 한다면 모든 다양한 문제를 한 모델에서 학습할 수 있고 또 새로운 문제를 유저가 임의로 앞에 설명을 통해서 정의를 하여 output 을 낼 수 있음
Text-to-Text Format Example
Task-specific prefix 를 추가 $\rightarrow$ 특정 task 에 알맞은 output text 를 생성하도록
Ex 1) Machine trasnlation: prefix = translate A to B (A: source language / B: target language)
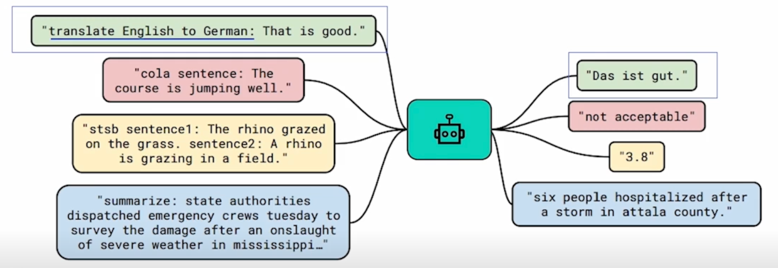
Ex 2) Text classification (MNLI)
MNLI: 두 개의 sentence (premise, hypothesis)가 주어지고, 이 둘의 관계를 예측하는 task (neural, contradiction, entailment)
Input: “mnli hypothesis: <sent 1> premise: <sent 2>”
Output: “neutral” or “contradiction” or “entailment”

이런 task 를 수행하기 위해서 예전에는 이런 task 를 수행하기 위한 모델을 delicate 된 모델을 따로 만들어야 했다면 이제는 앞에다가 task 이름을 붙여주고 “MNLI hypothesis: <sent 1> premise: <sent 2>” 이렇게 해줌으로써 최종 답변을 내보낼 수 있음을 보여줌
Model Overview
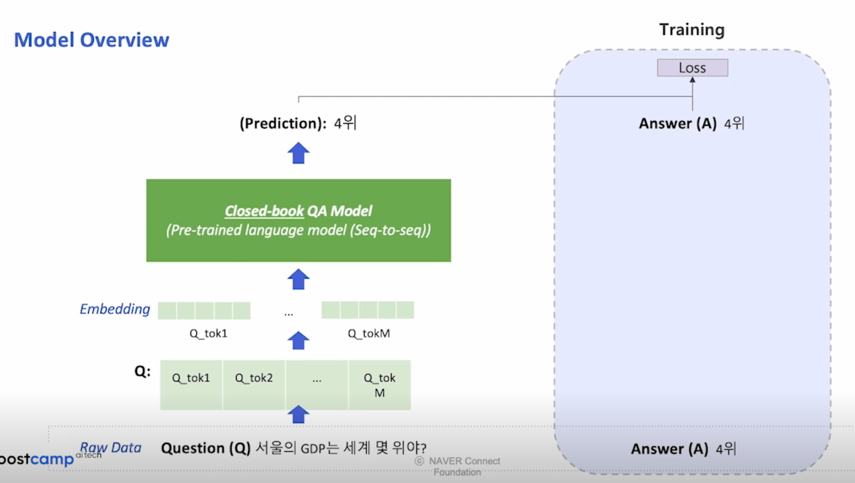
모델은 BART 와 상당히 유사하고 좀 더 엄밀하게 얘기하자면 BART 와 같은 모델의 상위호환된 방법이라고 보면 됨
BART 같은 generation 모델을 활용하여 Text-to-Text Format 으로 학습을 시킨다면 마찬가지로 성능이 잘 나올 수 있음
최종적으로는 input-to-text 지만 input 에 task 에 대한 설명이 들어가고 output 도 text 고 output 은 extraction-QA 처럼 특정 position 을 내보내는 것이 아니라 말 그대로 fully generate 된 text 를 내보내는 방식으로 하게 됨
T5
Text-to-Text format 이라는 형태로 데이터의 입출력을 만들어 거의 모든 자연어처리 문제를 해결하도록 학습된 seq-to-seq 형태의 Transformer 모델
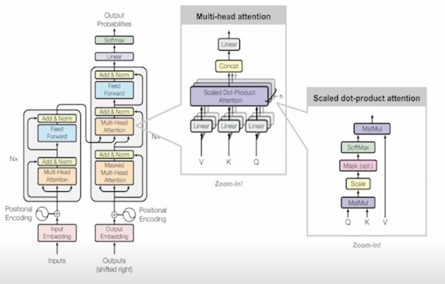
모델의 형태는 original Transformer 와 크게 다르지 않고 detail 은 좀 다름
Pre-training T5
다양한 모델 구조, 사전학습 목표, 사전학습용 데이터, Fine-tuning 방법 등을 체계적으로 실험함
가장 성능이 좋은 방식들을 선태갛여 방대한 규모의 모델을 학습시킴
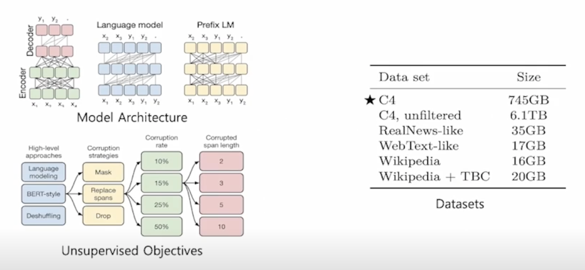
BERT 나 BART 와 마찬가지로 이런 모델은 아주 방대한 text 에 사전학습을 시키고 사전학습 한 다음에 fine-tuning 을 시킴으로써 성능이 잘 나오는 방식으로 모델을 튜닝할 수 있는것을 볼 수 있음
데이터사이즈가 위키피디아나 다른 데이터에 비해 상당히 큰것을 볼 수 있음

T5 라는 모델 내에 많은 정보를 담아야하기 때문에 그리고 Closed-book QA 를 수행하기 위해서 많은 지식을 담아야하기 때문에 T5 모델의 크기를 아주 키웠음
그래서 가장 큰 T5 모델 같은 경우는 parameter 의 개수가 11B 에 육박함
이는 BERT 나 GPT2 가 110M-340M 수준인 것을 가만하면 크기가 약 30배 이상 커진 어마어마한 크기라고 볼 수 있음
실제 T5-xlarge 같은 경우는 웬만한 GPU 개수로는 돌리기 쉽지 않아서 그것보다 작은 T5-base 나 T5-large 정도를 일반적으로 많이 씀
Using T5 for Closed-book QA
Fine-tuning T5:
- 미리 학습된 pre-trained T5 를 활용
- Fine-tuning: MRC 데이터셋 (TriviaQA, WebQuestions, Natural Qeustions) 의 QA pair 를 활용
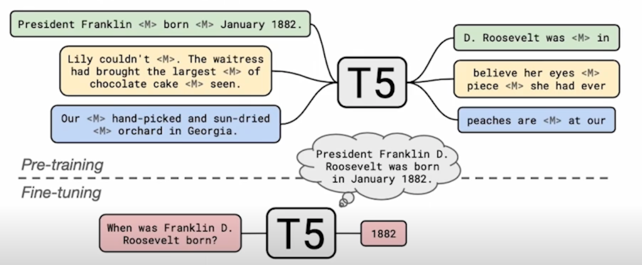
- MRC 데이터셋에 제공되는 supporting document 는 무시
- Input : Task-specific prefix 추가 $\rightarrow$ “trivia question: <question”
- Natural Questions 와 같이 답이 여러개인 경우 target $\rightarrow$ “answer: <answer 1> answer:
"

경우에 따라서는 answer 가 여러개가 나올 수 있음
3. Experiment Results & Analysis
Experiment Setting
Dataset
Open-domain QA 데이터셋 또는 MRC 데이터셋에서 지문을 제거하고 질문과 답변만 남긴 데이터셋을 활용
Salient Span Masking
고유 명사, 날짜 등 의미를 갖는 단위에 속하는 토큰 범위를 마스킹한 뒤 학습
일반적으로 BERT 같은 경우는 이렇게 하지 않고 random 하게 하다보니까 조사라던지 is, are 같은 의미가 없는 동사가 mask 되는 비효율성이 있었고 실제로 이런 단어들을 알아맞추는 것은 크게 문장의 의미와 관련이 없을 수 있기 때문에 상당히 쉬울 수 있음
그래서 Salient Span Masking 을 활용했다는 점이 좀 다름
Pre-trained 체크포인트에서 추가로 pre-training 함
Fine-tuning
Pre-trained T5 체크포인트를 Open-domain QA 학습 데이터셋으로 추가 학습
Experiment Examples
T5 를 이용한 Closed-book Question Answering 예시

마지막 질문을 보면 틀릴수는 있지만 어느정도 질문을 이해한다는 것을 알 수 있음
Quantative Examples
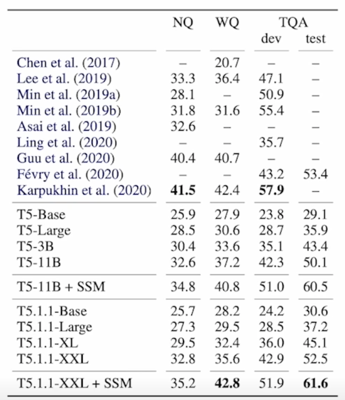
- 대부분의 Open-book 스타일 모델(문서 검색 후 기계독해)보다 뛰어난 성능을 보여줌
- 모델 크기가 커질수록 성능이 증가함
- Salient Span Masking 이 성능을 크게 끌어올림
False negatives
Exact match 기준으로 오답으로 채점된 결과를 사람이 평가한 결과 오답이 아닌 경우
- Phrasing Mismatch: 정답에 대한 표현이 다른 경우
- Incomplete Annotation: 정답이 여러개일수 있으나 하나만 정답으로 처리되는 경우
- Unanswerable: 질문을 한 시간이나 문맥에 따라서 정답이 달라지는 경우

Limitations
Closed-book QA 의 한계점 및 앞으로의 개선 방향
- 모델의 크기가 커서 계산량이 많고 속도가 느림 $\rightarrow$ 더 효율적인 모델 필요
- 모델이 어떤 데이터로 답을 내는지 알 수 없음 $\rightarrow$ 결과의 해석 가능성(interpretability)을 높이는 연구 필요
- 모델이 참조하는 지식을 추가하거나 제거하기 어려움
댓글남기기