Day_46 03. Generation-based MRC
작성일
Generation-based MRC
1. Generation-based MRC
Generation-based MRC 문제 정의
MRC 문제를 푸는 방법
1) Extraction-based mrc: 지문(context) 내 답의 위치를 예측 $\rightarrow$ 분류 문제(classification) 2) Generation-based mrc: 주어진 지문과 질의(question)를 보고, 답변을 생성 $\rightarrow$ 생성 문제(generation)
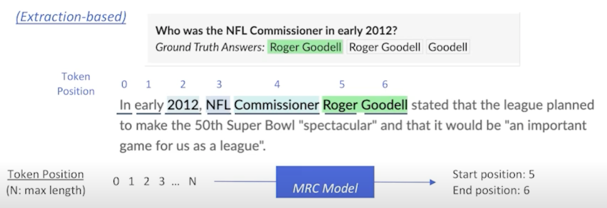
정답이 지문내에 있을수도 있고 없을 수도 있지만 기본적으로 생성해내는 것으로 답변을 하겠다는 방식
따라서 Extraction-based 문제는 Generation-based 문제로 치환할 수 있음
실제로 정답이 존재한다고 하더라도 생성을 하면 되니까
반대로 생성문제같은 경우는 Extraction-based mrc 로 치환하기 힘들 수 있음
특히 정답이 문장내에 있지 않으면 불가능함
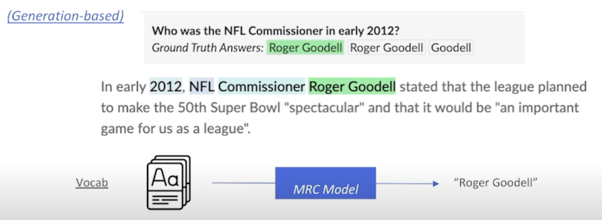
설사 정답이 지문내에 존재한다고 하더라도 그 정답의 위치를 파악하는 것이 아니라 모델이 해당 정답을 생성할 수 있도록 유도하고 실제로 생성한 값을 예측값으로 쓰게 됨
Generation-based MRC 평가 방법
동일한 extractive answer datasets $\rightarrow$ Extraction-based MRC 와 동일한 평가 방법을 사용 (recap)
1) Exact Match (EM) Score
EM = 1 when
\((Characters of the prediction) == (Characters of ground-truth)\)
Otherwise, EM = 0
2) F1 Score
예측한 답과 ground-truth 사이의 token overlap 을 F1 으로 계산
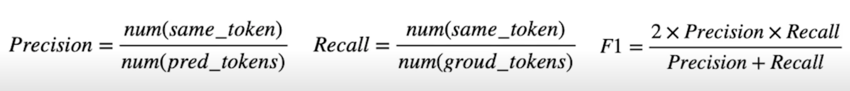
좀 더 생성문제와 일반적으로 비슷하게 접근하려고 한다면 ROUGE-L 이나 BLEU Score 같은 metric 을 사용하기도 함
Generation-based MRC Overview
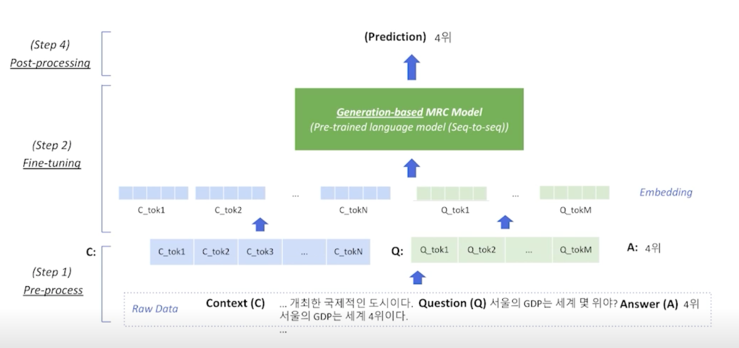
Extration-based MRC 와 크게 다르지 않음
input 쪽은 동일하다고 보면 될 것 같고 Contexet 와 Question 을 tokenize 한 다음에 embedding 으로 넘겨서 GreenBox 에 넣게되고 다만 이번에 다른점은 Extraction-based MRC 같은 경우는 output 으로 나오는 encoder embedding 을 활용해서 그걸 score 로 바꿔서 start 나 end 를 예측했다고 한다면 Generation-based MRC 같은 경우는 조금 더 편리하다고 볼 수 있음
GreenBox 가 정답까지 생성해주는 그런 Box 라고 보면 됨
바로 “4위” 라는 정답이 생성되어서 나오게 됨
일종의 seq2seq 모델이라고 보면됨
물론 pre-trained Language Model 이 seq2seq 을 할 수 있는것은 아님
예를 들어 BERT 같은 경우는 encoding 단계만 있고 decoder 가 없기 때문에 Generation-based MRC 에 활용할 수 없음
여기서는 간단하게 어떤 모델들을 활용할 수 있는지도 알아보도록 하자
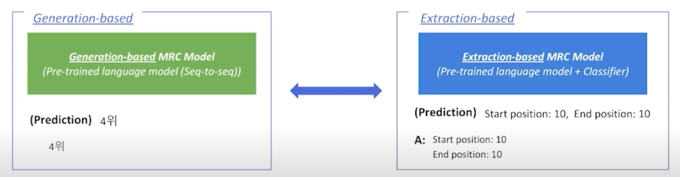
Generation-based MRC & Extraction-based MRC 비교
1) MRC 모델 구조 Seq-to-seq PLM 구조 (generation) vs. PLM + Classifier 구조 (extraction) 2) Loss 계산을 위한 답의 형태 / Prediction 의 형태 Free-form text 형태 (generation) vs. 지문 내 답의 위치 (extraction) $\rightarrow$ Extraction-based MRC: F1 계산을 위해 text 로의 별도 변환 과정이 필요
2. Pre-processing
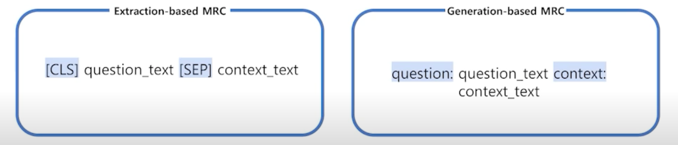
입력 표현 - 데이터 예시

Extraction-based MRC 의 경우 해당 정답의 위치를 정확하게 특정해야 했는데 Generation-based MRC 같은 경우는 필요가 없음
그냥 정답 그대로 넘겨주면 됨
입력 표현 - 토큰화
Tokenization(토큰화) : 텍스트를 의미를 가진 작은 단위로 나눈 것 (형태소)
- Extraction-based MRC 와 같이 WordPiece Tokenizer 를 사용함
- WordPiece Tokenizer 사전학습 단계에서 먼저 학습에 사용한 전체 데이터 집합(코퍼스)에 대해서 구축되어 있어야 함
- 구축 과정에서 미리 각 단어 토큰들에 대해 순서대로 번호(인덱스)를 부여해둠
- Tokenizer 은 입력 텍스트를 토큰화한 뒤, 각 토큰을 미리 만들어둔 단어 사전에 따라 인덱스로 변환함
WordPiece Tokenizer 사용 예시
- 질문: “미국 군대 내 두번째로 높은 직위는 무엇인가?”
- 토큰화된 질문 : [‘미국’, ‘군대’, ‘내’, ‘두번째’, ‘##로’, ‘높은’, ‘직’, ‘##위는’, ‘무엇인가’, ‘?’]
- 인덱스로 바뀐 질문 : [101, 23545, 8910, 14423, 8996, 9102, 48506, 11261, 55600, 9707, 19855, 11018, 9294, 119137, 12030, 11287, 136, 102]
$\rightarrow$ 인덱스로 바뀐 질문을 보통 input_idx(또는 input_token_idx)로 부름 $\rightarrow$ 모델의 기본 입력은 input_ids 만 필요하나, 그 외 추가적인 정보가 필요함
입력 표현 - Special Token
학습 시에만 사용되며 단어 자체의 의미는 가지지 않는 특별한 토큰
- SOS(Start Of Sentence), EOS(End Of Sentence), CLS, SEP, PAD, UNK, .. 등등
- $\rightarrow$ Extraction-based MRC 에선 CLS, SEP, PAD 토큰을 사용
- $\rightarrow$ Generation-based MRC 에서도 PAD 토큰은 사용됨. CLS, SEP 토큰 또한 사용할 수 있으나, 대신 자연어를 이용하여 정해진 텍스트 포맷(format) 으로 데이터를 생성
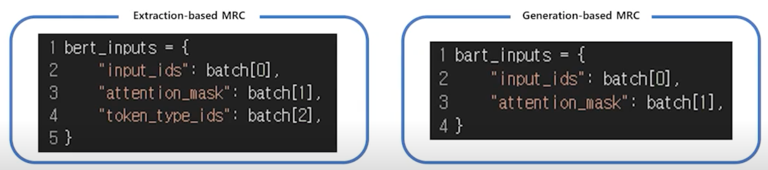
입력 표현 - additional information
Attention mask
- Extraction-based MRC 와 똑같이 어텐션 연산을 수행할 지 결정하는 어텐션 마스크 존재
Token type ids
- BERT 와 달리 BART 에서는 입력시퀀스에 대한 구분이 없어 token_type_ids 가 존재하지 않음
- 따라서 Extraction-based MRC 와 달리 token_type_ids 가 들어가지 않음
[SEP] 토큰들이 있으면 사실 token_type_ids 는 직접적으로 제공되지 않아도 어느정도 모델이 구분할 수 있고 초창기에는 그것을 직접적으로
구분해주려 했지만 나중에는 크게 중요하지 않다고 판단이되어 지운 모델들이 있는 것으로 보임
출력 표현 - 정답 출력
Sequence of token ids
- Extraction-based MRC 에선 텍스트를 생성해내는 대신 시작/끝 토큰의 위치를 출력하는 것이 모델의 최종 목표였음
- Generation-based MRC 는 그보다 조금 더 어려운 실제 텍스트를 생성하는 과제를 수행
- 전체 시퀀스의 각 위치마다 모델이 아는 모든 단어들 중 하나의 단어를 맞추는 classification 문제
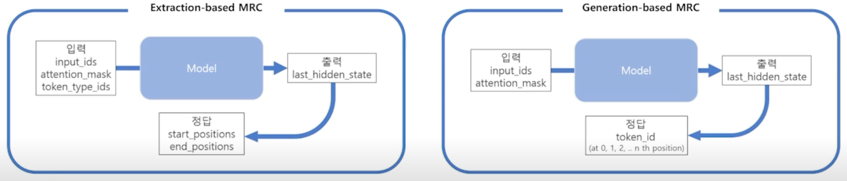
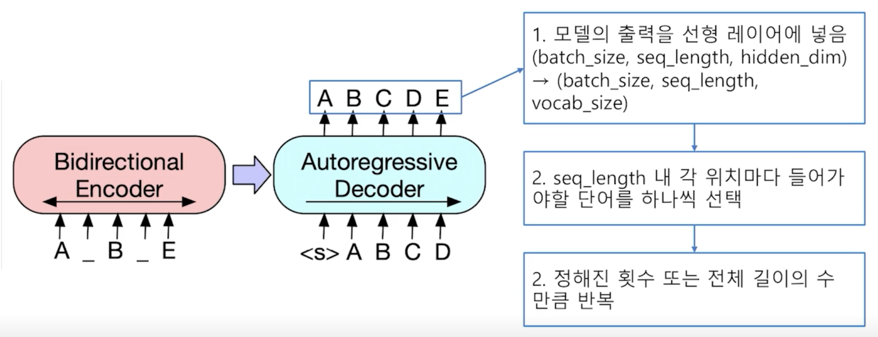
보시다시피 정답을 출력할때는 모델 출력값을 선형 layer 에 넣어서 각 sequence_length 내에 각 위치마다 들어가야할 단어를 선택하는 방식을 취하고 정해진 횟수 또는 정해진 길이의 수만큼 반복을 하여 단어를 하나씩 생성해서 끝까지 간다음에 하나씩 생성한 단어들을 다 붙여서 최종 답안으로 예측하는 방식을 취함
일반적인 decoding 방법론이라고 생각할 수 있음
3. Model
BART
기계 독해, 기계 번역, 요약, 대화 등 sequence to sequence 문제의 pre-training 을 위한 denoising autoencoder
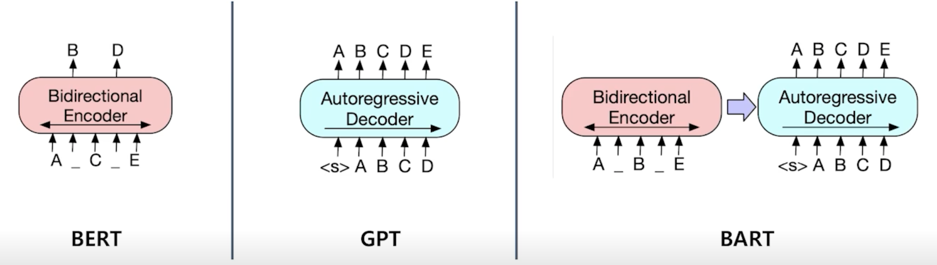
BERT 같은 경우 encoder 만 존재하고 그렇기 때문에 encoder 의 output feature 각 단어의 embedding 에 해당하는 것들을 가져와서 embedding 을 수치화시켜서 시작과 끝에 위치를 알아맞추는 방식으로 진행되는데 BART 같은 경우는 실제로 text 를 내보내는 방식으로 하게 됨
학습할 때가 좀 다름
BERT 같은 경우는 pre-training 할 때 단어를 Masking 한 다음에 단어를 알아맞추는 방식을 취한다고 하면 BART 같은 경우는 기존 문장을 비슷한 방식으로 Mask 를 하지만 Mask 를 알아맞추는 방식이 아니라 정답을 생성하는 방식으로 하게 됨
GPT 같은 Language Model 같은 경우는 심플하게 다음 단어를 알아맞추는 방식으로 pre-training 을 진행하게 됨
이런 방식을 일반적으로는 noising 을 injection 을 하고 그 다음에 noise 가 없었던 원래 버전을 reconstruct 하는 문제라고 보기 때문에 denoising autoencoder 라는 표현도 많이씀
BART Encoder & Decoder
- BART 의 인코더는 BERT 처럼 bi-directional
- BART 의 디코더는 GPT 처럼 uni-directional(autoregressive)
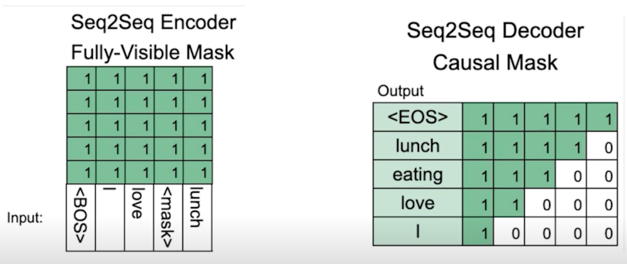
Pre-training BART
BART 는 텍스트에 노이즈를 주고 원래 텍스트를 복구하는 문제를 푸는 것으로 pre-training 함
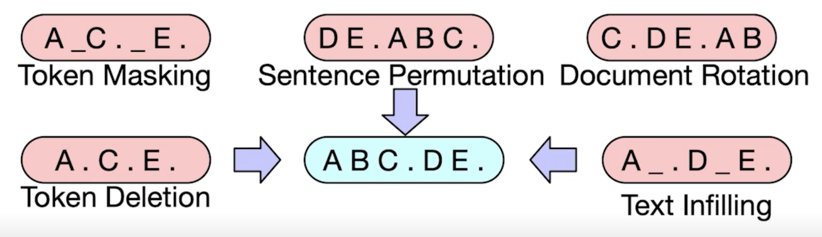
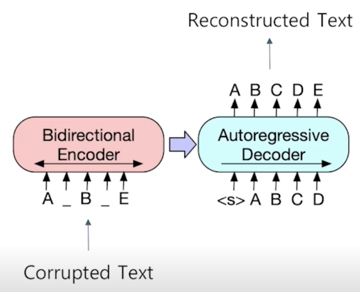
시작하는 text 가 A, B, E 밖에 없고 여기서 두 개의 단어를 없애고 text 를 Corrupt 한 거라고 볼 수 있음
그 다음에 원래 text 를 복원하는 쪽으로 모델을 학습하도록 함
4. Post-processing
Searching
Decoding 을 하는 방식으로 text 를 생성하기 때문에 이전 step 에서 나온 출력을 다음 step 의 입력으로 들어가는 방식을 채택함
보통 맨처음의 입력은 그 전에 나왔던 토큰이 없기 때문에 문장의 시작을 뜻하는 special token 을 활용하여 decoder 가 시작할 수 있도록 유도함
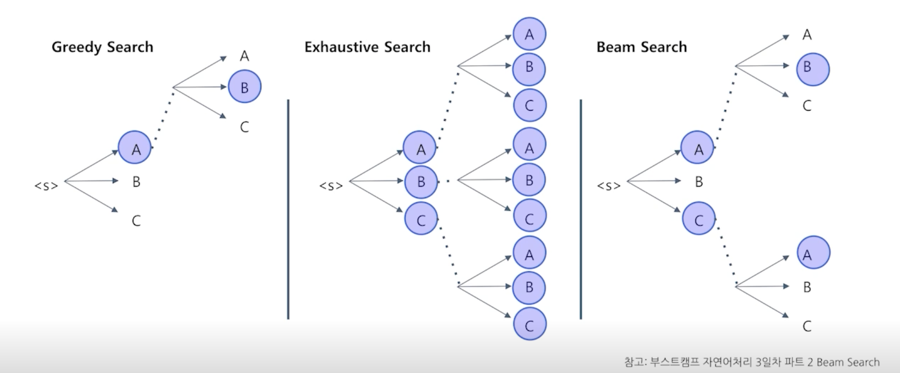
디코딩 방법론에는 여러가지가 있는데 가장 심플한 방법론은 Greedy Search 라고 하는데 시작하는 <s> 에서 가장 likely 한 그 다음 단어 A 를 맞추고
그 다음에 또 B 를 맞추는 방식으로 아주 효율적으로 빠르게 문장을 생성하는 방법이 있음
이런 경우는 생성자체는 상당히 빠르지만 가장 큰 문제는 실제로 처음에 골랐던 단어 A 가 어쩌면 나중에 가서는 잘못된 선택일 수 있기 때문에 상당히 안좋은 output 을 낼 수 있음
decision making 을 early stage 에서 하게되서 나중에 나쁜 결과가 나오는 방식임
그에 반해서 Exhaustive Search 같은 경우는 모든 가능성을 다 봄
다만 이 경우는 가능한 가짓수가 time step 에 비례해서 exponential 하게 늘어나기 때문에 문장의 길이가 조금만 길어져도 사실 불가능한 방법론임
또한 vocabulary 사이즈가 조금만 커져도 불가능한 방법론임
그래서 실제로는 일반적으로 모든 모델에 채택하는 방법은 Beam Search 와 유사한 방법인데 Exhaustive Search 를 하긴 하되 각 time step 마다 가장 점수가 높은 top-k 만 유지하는 방식을 취함
항상 가지고 있는 candidate list 는 100 혹은 1000개가 되는데 거기서 branch out 을 해서 거기서 그 다음으로 좋은 score 를 찾는 방식을 취함
그렇게 해서 각 time step 마다 1000개를 유지하기 위해 다시 re ranking 을 하고 ranking 이 내려간 candidate 같은 경우에는 버리게 됨
Further Reading
- Introducing BART
- BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
- Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer (T5)
실습
필요한 패키지 몇개를 설치
!pip install datasets==1.4.1
!pip install transformers==4.4.1
!pip install sentencepiece==0.1.95
!pip install nltk
nltk 를 가져오도록 하자
nltk 를 설치하긴 했지만 몇가지 download 를 해야 함
import nltk
nltk.download('punkt')
데이터셋을 불러오자
from datsets import load_dataset
datasets = load_dataset('squad_kor_v1')
metric 도 가져오자
from datasets import load_metric
metric = load_metric('squad')
다음으로는 pre-trained 된 모델과 tokenizer 를 불러오자
from transformers import (
AutoConfig,
AutoModelForSeq2SeqLM,
AutoTokenizer
)
model_name = 'google/mt5-small'
model_name 은 T5 모델을 사용할건데 mt5 라고 하는 이유는 multilingual 모델을 의미
config = AutoConfig.from_pretrained(
model_name,
cache_dir=None,
)
tokenizer = AutoTokenizer.from_pretrained(
model_name,
cache_dir=None,
use_fast=True,
)
model = AutoModelForSeq2SeqLM.from_pretrained(
model_name,
config=config,
cache_dir=None,
)
mt5 같은 경우에는 1.2G 의 큰 용량을 차지하는데 이게 사실 모델의 parameter 의 개수 중에서 많이 차지하는 비중은 여러 언어를 담아야하다 보니까 vocabulary size 가 아주 크고 각 단어에 해당하는 embedding 을 저장하느라고 저장공간이 커졌다고 볼 수 있음
언어에 특화된 pre-trained Language Model 을 활용하게 된다면 이점이라고 볼 수 있는 부분은 해당하는 국가의 언어만 활용하니까 용량이 좀 줄어들게 됨
max_source_length = 1024
max_target_length = 128
padding = False
preprocessing_num_workers=12
num_beams = 2
max_train_samples = 16
max_val_samples = 16
num_train_epochs = 3
이전 포스트에서와 달라진 점은 max_target_length 가 있는데 이게 존재하는 이유는 seq2seq 이 되었기 때문에 더이상 BERT 처럼 encoding 만 하는 것이 아니라 decoding 을 해야하고 decoding 하는 단계에서는 target_lenght 의 max 값을 정해줘야 함
이거 이상 길어지지 않도록하는 일종의 보호장치임
def preprocess_function(examples):
inputs = [f'question: {q} context: {c} </s>' for q, c in zip(examples['question'], examples['context'])]
targets = [f'{a["text"][0]} </s>' for a in examples['answers']]
model_inputs = tokenizer(inputs, max_length=max_source_length, padding=padding, truncation=True)
# Setup the tokenizer for targets
with tokenizer.as_target_tokenizer():
labels = tokenizer(targets, max_length=max_target_length, padding=padding, truncation=True)
model_inputs["labels"] = labels["input_ids"]
model_inputs["example_id"] = []
for i in range(len(model_inputs["labels"])):
model_inputs["example_id"].append(examples["id"][i])
return model_inputs
preprocess function 은 Extraction-based MRC 에 비해 간단함
input 과 target 을 가져온 다음에 그 다음에 tokenize 를 함
tokenize 한 값들을 모델 input 에 해당하는 key 로 지정해주는게 끝임
이렇게 심플해진 이유가 결국에는 text generation 문제로 풀게되면 모델에 넣어야하는 값들은 input 도 text 고 학습할 때 쓸 answer 도 text 임
extraction-based MRC 같은 경우 위치를 줘야하다 보니까 위치를 특정하는 로직이 많이 들어가게 됐다고 생각하면 됨
그래서 preprocess function 이 간단해지는 이점이 있음
column_names = datasets['train'].column_names
간단하게 column_names 을 정의해줌
그 다음엔 상당히 비슷한 방식응로 학습데이터셋을 정의함
train_dataset = datasets["train"]
train_dataset = train_dataset.select(range(max_train_samples))
train_dataset = train_dataset.map(
preprocess_function,
batched=True,
num_proc=preprocessing_num_workers,
remove_columns=column_names,
load_from_cache_file=False,
)
datasets 을 가져오고 ‘train’ 데이터만 활용한다음에 실습을 위해 16개의 example 만 보게 되고 preprocess_function 을 lambda 함수에 넣어줌으로써 실제로 필요한 process 를 효율적으로 진행하게 됨
map 을 활용하는 이유는 따로 처리하는 것보다 map 을 활용함으로써 예를 들면 여러가지 num_worker 를 활용해서 분산처리를 하던지
효율성을 높일 수 있어서 하는것이고 사실 꼭 map 을 활용할 필요는 없고 효율성이 중요하지 않다고 한다면 직접 preprocess function 을
apply 하는 것도 방법임
eval_dataset = datasets["validation"]
eval_dataset = eval_dataset.select(range(max_val_samples))
eval_dataset = eval_dataset.map(
preprocess_function,
batched=True,
num_proc=preprocessing_num_workers,
remove_columns=column_names,
load_from_cache_file=False,
)
똑같은 과정을 validation dataset 에도 해줌
이제 fine-tuning 단계임
from transformers import (
DataCollatorForSeq2Seq,
Seq2SeqTrainer,
Seq2SeqTrainingArguments
)
구체적인 모델을 불러옴
DataCollatorForSeq2Seq 는 다른 seq_length 를 가지는 input 들을 합쳐줘서 GPU 에서 parallel computing 을 하기 쉽게 만들어줌
label_pad_token_id = tokenizer.pad_token_id
data_collator = DataCollatorForSeq2Seq(
tokenizer,
model=model,
label_pad_token_id=label_pad_token_id,
pad_to_multiple_of=None,
)
이런방식으로 사용하게 되는데 중요한 것중에 하나는 label_pad_token_id 를 정의해주고 [PAD] 가 어떤 id 를 가지고 있는지 [PAD] 를 무시하도록
할 것이기 때문에 DataCollatorForSeq2Seq 를 활용하는데 여기서 label_pad_token_id 를 지정해주고 마지막으로 pad_to_multiple_of=None 으로
해주게 됨
def postprocess_text(preds, labels):
preds = [pred.strip() for pred in preds]
labels = [label.strip() for label in labels]
preds = ["\n".join(nltk.sent_tokenize(pred)) for pred in preds]
labels = ["\n".join(nltk.sent_tokenize(label)) for label in labels]
return preds, labels
다음은 간단한 postprocess 과정을 정의해줌
prediction 과 label 이 나오게 되었을 때 prediction 같은 경우는 예측값과 정답값을 postprocessing 해주는 것임
보시다시피 예측값 같은 경우도 양쪽에 space 를 다 걷어낸 다음에 그대로 가져오는 심플한 postprocessing 이고 label 도 마찬가지임
양 prediction 과 label 이 space 가 시작과 끝에 있는 경우는 없애주는 과정이라고 보면 되고 그 다음에 nltk 를 활용해서 해당 문장을
토크나이징을 하고 그 다음에 여러개의 prediction 을 \n 으로 join 해서 하나의 text 로 만들게 됨
metric 도 비교적 심플함
def compute_metrics(eval_preds):
preds, labels = eval_preds
if isinstance(preds, tuple):
preds = preds[0]
decoded_preds = tokenizer.batch_decode(preds, skip_special_tokens=True)
# decoded_labels is for rouge metric, not used for f1/em metric
decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
# Some simple post-processing
decoded_preds, decoded_labels = postprocess_text(decoded_preds, decoded_labels)
formatted_predictions = [{"id": ex['id'], "prediction_text": decoded_preds[i]} for i, ex in enumerate(datasets["validation"].select(range(max_val_samples)))]
references = [{"id": ex["id"], "answers": ex["answers"]} for ex in datasets["validation"].select(range(max_val_samples))]
result = metric.compute(predictions=formatted_predictions, references=references)
return result
metric 같은 경우는 decoding 된 prediction 과 label 이 있다고 했을 때 이 두개를 가져와서 처음에 불러왔던 metric 을 활용해서 수치를 구하게 됨
args = Seq2SeqTrainingArguments(
output_dir='outputs',
do_train=True,
do_eval=True,
predict_with_generate=True,
num_train_epochs=num_train_epochs
)
arguments 들을 정의해줌
trainer = Seq2SeqTrainer(
model=model,
args=args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics,
)
Trainer 를 정의해줌
train_result = trainer.train(resume_from_checkpoint=None)
마지막으로 학습을 진행
학습을 하고 나면 비슷하게 train_result 에서 어떻게 학습이 됐는지 볼 수 있음
train_result

가장 중요한 수치들은 step 이 몇번째 step 이었는지 그리고 loss 가 얼마인지 정도임
마지막으로 평가를 하게 됨
metrics = trainer.evaluate(
max_length=max_target_length, num_beams=num_beams, metric_key_prefix="eval"
)
똑같은 방식으로 진행되는데 max_length 를 추가적으로 넣어줘야 하고 beam search 를 사용하기 때문에 beam 의 크기도 정의해줌
metrics
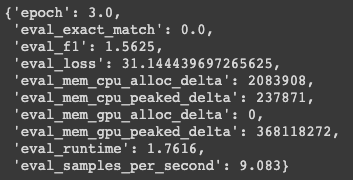
em 과 f1 으로 score 를 재는걸 알 수 있고 f1 같은 경우 완전 0점이 나오진 않았지만 em 같은 경우는 matching 을 하지 않았기 때문에 0점이 나왔음
그리고 추가적인 수치를 볼 수 있음
학습하고 난 다음엔 활용하는 방법은 간단함
pydocument = "세종대왕은 언제 태어났어?"
input_ids = tokenizer(document, return_tensors='pt').input_ids
outputs = model.generate(input_ids)
tokenizer.decode(outputs[0], skip_special_tokens=True)
input 으로 document 를 주게되고 toknizer 에 넣은 다음에 input_ids 를 가져오게 되고 그 다음에 model 에다가 input 으로 넣은 다음 generate 라는 function 을 활용함
output 값은 최종 답안이 되는 값의 id 로 이루어져 있음
id 로 이루어져 있기 때문에 다시 text 로 바꿔줘야 함
그걸 tokenizer.decode() 를 활용해서 변형하도록하면 정답이 나옴
댓글남기기