Day_46 02. Extraction-based MRC
작성일
Extraction-based MRC
1. Extraction-based MRC
Extraction-based MRC 문제 정의
질문(question)의 답변(answer)이 항상 주어진 지문(context)내에 span 으로 존재
e.g. SQuAD, KorQuAD, NewsQA, Aatural Questions, etc.

질문에 대한 답이 지문에 항상 있다고 가정하면 텍스트를 생성하는 것이 아닌 텍스트의 위치만 파악하는 것으로 문제를 fomulate 할 수 있기때문에 상당히 여로모로 편리한 경우가 많음
Extraction-based MRC datasets in Hugging Face datasets (https://huggingface.co/datsets)
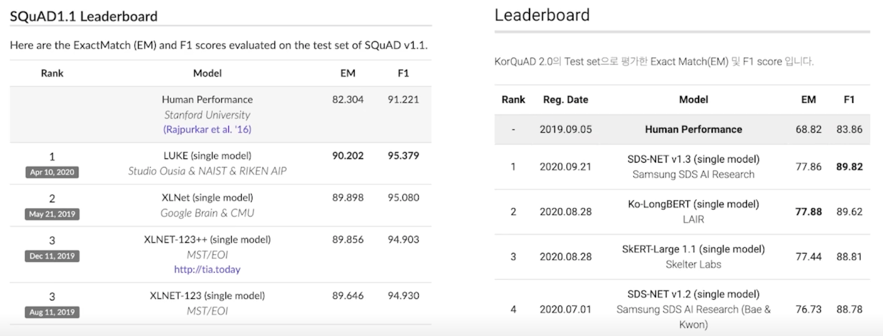
Extraction-based MRC 평가 방법
Exact Match (EM) Score
예측값과 정답이 캐릭터 단위로 완전히 똑같을 경우에만 1점 부여.
하나라도 다른 경우 0점.

F1 Score
예측값과 정답의 overlap 을 비율로 계산.
0점과 1점사이의 부분점수를 받을 수 있음.

계산해볼 수 있는 예제
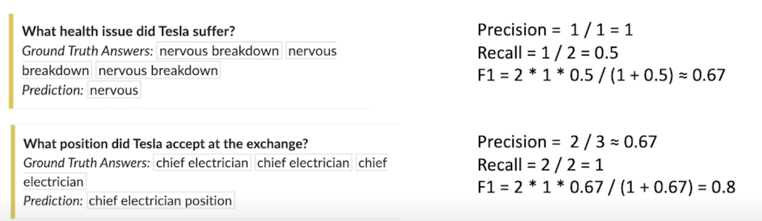
위의 예제는 Ground Truth 가 nervous breakdown 이고 prediction 은 nervous 였음
이 경우 첫번째 답 nervous breakdown 이 유일한 정답이라고 가정한다면 우리의 예측값같은 경우는 실제로 precision 은 1점임
왜냐면? Ground Truth 와 prediction 이 겹치는게 nervous 로 하나고 prediction 의 토큰 개수도 nervous 로 하나이니까
하지만 recall 값이 0.5가 되는데 겹치는 하나의 토큰 nervous 지만 정답값 같은 경우는 breakdown 이라는 단어가 추가적으로
하나더 있으므로 분모가 2가 되어 recall 값은 0.5가 됨
마지막으로는 F1 Score 는 이 두 숫자를 곱한다음에 2를 또 곱해주고 이 두개의 수치를 더한 값으로 나눠주는 최종 0.67이 나오는 것을 알 수 있음
물론 Ground Truth 가 하나만 있는것은 아니기 때문에 이런 방식으로 계산을 각각 Ground Truth answer 하나마다 계산을하여 실제 evaluation 은 그 중 가장 높은 숫자를 내보내는 방식으로 함
보시다시피 Ground Truth Answers 가 nervous breakdown nervous breakdown nervous breakdown 이렇게 밖에 없기 때문에 이 경우는 다 0.67로 계산이 될 것임 따라서 만약에 prediction 이 nervous 였다면 최종 F1 Score 도 0.67이 됨
물론 0.67이라는 숫자를 67로 편의상 표현하기도 함
Extraction-based MRC Overview
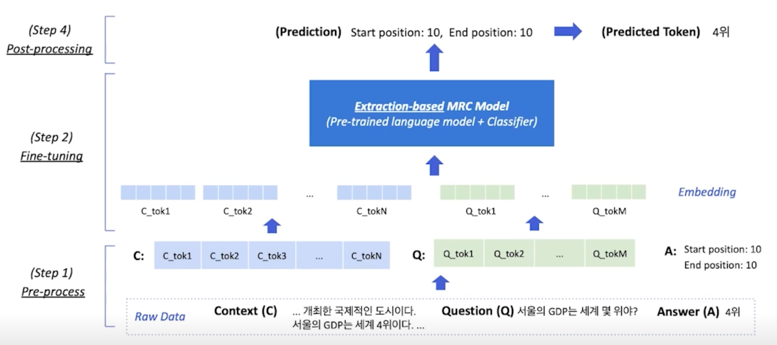
실제로 모델에서는 Context 와 Question 의 단어가 먼저 쪼개져서 나가게 됨 (1강에서 배웠던 Tokenization 을 활용해서)
그래서 Context 같은 경우는 C_tok1, C_tok2, …, C_tokN 까지 가게되고 Question 같은 경우는 Q_tok1, Q_tok2, …, Q_tokM까지 가게 됨
이거를 Word Embedding 이라는 concept 을 이용해서 벡터화를 시키고 이 벡터들이 파란색 모델안에 들어가게되서 최종적으로는 모델이 내보내는 값은 시작점과 끝점이 됨
여기서 시작쩜과 끝점을 내보낸다고 하는것은 숫자를 내보내는 것이 아니라 Context 와 Question 에 해당하는 각각 단어에 해당하는 Contextualize vector 가 나오게 됨
이 Contextualize vector 들을 각각 scaler value 로 내보내게 됨으로써 일종의 각 포지션이 시작 또는 끝 값이 될 수 있는 점수가 됨
그 점수중에 가장 높은 위치를 찾는 방식으로 start postion 과 end position 을 예측하게 됨
start 와 end 를 예측하고나서는 최종 예측값을 쉽게 구할 수 있음
말 그대로 시작과 끝 span 을 그대로 가져와서 답으로 내보내게 됨
2. Pre-processing
입력 예시

Tokenization
텍스트를 작은 단위(Token)로 나누는 것
- 띄어쓰기 기준, 형태로, subword 등 여러 단위 토큰 기준이 사용됨
- 최근엔 Out-Of-Vocatulary (OOV) 문제를 해결해주고 정보학적으로 이점을 가진 Byte Pair Encoding (BPE)을 주로 사용함
- 본강에선 BPE 방법론중 하나인 WordPiece Tokenizer 를 사용
WordPiece Tokenizer 사용 예시
“미국 군대 내 두번째로 높은 직위는 무엇인가?”
[‘미국’, ‘군대’, ‘내’, ‘두번째’, ‘##로’, 높은, ‘직’, ‘##위는’, ‘무엇인가’, ‘?’]
여기서 ‘##’ 이 의미하는 것은 바로 앞에 단어랑 space 가 없다는 뜻 즉 붙어있다는 뜻임
WordPiece 같은 경우 자주나오는 단어는 “미국”, “군대” 처럼 하나의 단어로 이루어지고 자주 나오지 않는 단어 같은 경우는 따로 나눠지는 것을 볼 수 있음
예를 들어 “직위는” 이라는 단어는 덜 나올테니 “직위는” 이 하나의 단어가 되지 못하고 “직” 과 “##위는” 이 나눠지는 것을 볼 수 있음
Special Tokens

special token 을 이용해서 question 과 context 를 구분하게 함
질문이 “미국 군대 내 두번째로 높은 직위는 무엇인가?” 이고 그 다음에 지문(context)가 나오는데 이 두개를 [SEP] 라는 토큰이 분리하는 것을
볼 수 있음
마찬가지로 [CLS] 토큰으로 시작하는 것을 볼 수 있는데 편의상 사용하고 있는 토큰이라고 보면 됨

이런 special token 들이 tokenize 된 이후에도 계속 존재하는 것을 볼 수 있음
이렇게 tokenize 된 형태로 모델에 들어간다고 보면 됨
Attention Mask
- 입력 시퀀스 중에서 attention 을 연산할 때 무시할 토큰을 표시
- 0은 무시, 1은 연산에 포함
- 보통
[PAD]와 같은 의미가 없는 특수토큰을 무시하기 위해 사용

Token Type IDs
입력이 2개 이상의 시퀀스일 때 (예: 질문 & 지문), 각각에게 ID 를 부여하여 모델이 구분해서 해석하도록 유도

모델 출력값
- 정답은 문서내 존재하는 연속된 단어토큰(span)이므로, span 의 시작과 끝 위치를 알면 정답을 맞출 수 있음
- Extraction-based 에선 답안을 생성하기 보다, 시작위치와 끝위치를 예측하도록 학습함
- 즉 Token Classification 문제로 치환

여기서 생길 수 있는 문제가 정답은 text 레벨에서 character 위치로 파악하고 있는데 토크나이징 한 다음에 학습할 때 학습할 때 시그널에 주는
방식은 이 토큰이 정답토큰이 어디있는가로 되기 때문에 약간의 processing 이 필요함
보시다시피 정답이 ‘미국’, ‘육군’, ‘부’, ‘##참모’, ‘총장’ 이라고 했을 때 원래 original text 에 해당하는 토큰들을 찾을 수 있어야하는데
찾는 방법은 여러가지가 있지만 가장 간단하게는 해당 text 를 그대로 포함하는 모든 단어를 가져와서 시작과 끝을 표시하는 방식이 있음
대부분의 경우는 문제가 없는데 가끔가다가 예를 들면 정답은 ‘미국 육군 부참모 총장’ 에서 ‘국 육군 부 참모 총장’ 이렇게 좀 부분적으로 나눠질 수
있음 이렇게되면 정확하게 일치하는 정답은 없기 때문에 애매할 수 있긴 한데 그렇다하더라도 최소한으로 포함하는 단어들을 전부 다 정답으로 포함하여
학습할 때 사용한다고 생각하면 됨
3. Fine-tuning
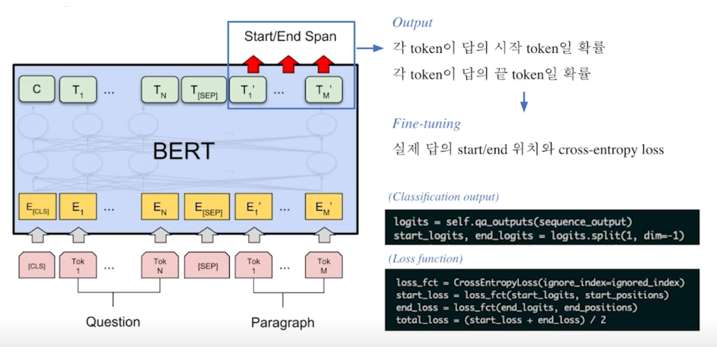
지문 내에서 정답에 해당되는 각 embedding 을 실제로 linear transformation 을 통해서 각 단어마다 하나의 숫자가 나올 수 있도록 바꿔주고 물론 이 linear transformation 도 학습할 대상임
그러면 각 지문 토큰마다 하나의 숫자가 output 으로 나오게 되고 그 숫자는 점수로 볼 수 있음
높을 수록 정답으로 볼 수 있는 점수들
그래서 시작포지션을 이런 방식으로 구하게되고 마찬가지로 엔드포지션도 이런방식으로 구하게되서 최종 답안을 내는 방식을 취함
실제로 학습할때는 이 수치를 softmax 로 apply 해서 거기에 negative log likelihood 로 학습하는 방식을 취함
4. Post-processing
불가능한 답 제거하기
다음과 같은 경우 candidate list 에서 제거
- End position 이 start position 보다 앞에 있는 경우 (e.g. start = 90, end = 80)
- 예측한 위치가 contexet 를 벗어난 경우 (e.g. question 위치쪽에 답이 나온 경우)
- 미리 설정한 max_answer_length 보다 길이가 더 긴 경우
최적의 답안 찾기
- Start/end position prediction 에서 score (logits)가 가장 높은 N 개를 각각 찾음
- 불가능한 start/end 조합을 제거
- 가능한 조합들을 score 의 합이 큰 순서대로 정렬
- Score 가 가장 큰 조합을 최종 예측으로 선정
- Top-k 가 필요한 경우 차례대로 내보냄
Further Reading
- SQuAD 데이터셋 둘러보기
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning)
- Huggingface datasets
실습
# To use utility functions defined in examples.
!git clone https://github.com/huggingface/transformers.git
import sys
sys.path.append('transformers/examples/pytorch/question-answering')
특정 폴더에 있는 파이썬 코드들을 전부다 현재 python environment 에 import 해올 수 있음
transforemrs 라는 라이브러리를 python package 로 다운받는게 아니라 github repository 로 다운받게 됨
거기에 대해서 파일들을 가져와서 전부 다 import 를 끝냄
from datasets import load_dataset
datasets = load_dataset('squad_kor_v1')

/root/.cache/~~ cache 폴더 안에 저장한 것을 알 수 있음
datasets

datasets 은 train 과 validation 으로 이루어져 있는데 각각이 하나의 table 이라고 보면 될 것 같음
각 table 의 header 가 있고 ‘id’, ‘title’, ‘context’, ‘question’, ‘answers’ 가 있음
그리고 개수가 밑에 적혀있음
datasets['train']

datasets['train'][0]

첫번째 example 을 볼 수 있음
from datasets import load_metric
metric = load_metric('squad')
metric 을 불러올 수 있음
from transformers import (
AutoConfig,
AutoModelForQuestionAnswering,
AutoTokenizer
)
클래스를 import 해줌
model_name = 'bert-base-multilingual-cased'
config = AutoConfig.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForQuestionAnswering.from_pretrained(model_name, config=config)
model_name 을 먼저 설정하고 config, tokenizer, model 을 전부 불러옴
max_seq_length = 384 # 질문과 컨텍스트, special token을 합한 문자열의 최대 길이
pad_to_max_length = True
doc_stride = 128 # 컨텍스트가 너무 길어서 나눴을 때 오버랩되는 시퀀스 길이
max_train_samples = 16
max_val_samples = 16
preprocessing_num_workers = 4
batch_size = 4
num_train_epochs = 2
n_best_size = 20
max_answer_length = 30
sequence_length 의 한계를 정하는게 중요함
일정 개수를 넘어가지 않는다는것을 알고있어야 그 개수내에서 모델을 만들고 여러가지 padding 같은 것을 작업할 수 있기때문에 max_seq_length 를 정의함
max_seq_length 에서 남는부분이 있다면 나머지 부분을 padding 으로 채워주게 됨 이거를 pad_to_max_length=True 라는 flag 로 처리해줌
문서가 너무 긴 경우는 doc_stride 라는 숫자로 일부 겹치게해서 나누는 방식을 채택
예를들어 문서 길이가 500이라고 하면 sequence length 384 내에 들어가지 않기때문에 문서를 2개로 쪼개고 그 문서 2개가 overlap 되는게 128개를
함으로써 두개로 나눠서 Question Answering system 을 진행할 수 있도록 하고 이런 경우는 문서가 하나라고 하더라도 각각 문서에서 답변을 구한다음에
답변을 취합하는 방식을 택함
첫번째 단어 500개짜리 문서가 있다고 했을 때 첫번째 384개 짜리 문서랑 두번째 나머지의 128개 겹치는 나머지의 문서에서 답변을 구하고 2개의 답변 중 더 확률이 높은 걸 가져가는 방식임
train_sample 의 max 를 정해줌
개수를 적당히 정해서 학습이 빨리 끝나도록 함 실제로는 이것보다 더 많은 개수를 학습해야 함
max_val_sample 도 정해줌
preprocessing_num_workers 같은 경우는 cpu 의 thread 를 몇개를 활용할 것이냐? process 를 몇개 활용할거냐 라고 보면 됨
많이쓸수록 더 빨라지기는 하는데 다만 보통 일반적으로는 컴퓨터가 갖고있는 hardware 에 dependent 하기도 하고 4 이상 필요가 없는 경우도 많음
그리고 batch_size 같은 경우는 학습할 때 쓰이는 mini-batch size akfgka
train_epoch 같은 경우는 학습 데이터를 총 몇번 재활용 할거냐라고 보면 됨
n_best_size 와 max_answer_length 가 있는데 max_answer_length 같은 경우는 답변의 최대 길이가 몇이냐 이고 답변길이를 제한함으로써 너무 긴 답변이 나오지 않을 수 있도록 미리 control 하는 거라고 볼 수 있음
def prepare_train_features(examples):
# 주어진 텍스트를 토크나이징 한다. 이 때 텍스트의 길이가 max_seq_length를 넘으면 stride만큼 슬라이딩하며 여러 개로 쪼갬.
# 즉, 하나의 example에서 일부분이 겹치는 여러 sequence(feature)가 생길 수 있음.
tokenized_examples = tokenizer(
examples["question"],
examples["context"],
truncation="only_second", # max_seq_length까지 truncate한다. pair의 두번째 파트(context)만 잘라냄.
max_length=max_seq_length,
stride=doc_stride,
return_overflowing_tokens=True, # 길이를 넘어가는 토큰들을 반환할 것인지
return_offsets_mapping=True, # 각 토큰에 대해 (char_start, char_end) 정보를 반환한 것인지
padding="max_length",
)
# example 하나가 여러 sequence에 대응하는 경우를 위해 매핑이 필요함.
overflow_to_sample_mapping = tokenized_examples.pop("overflow_to_sample_mapping")
# offset_mappings으로 토큰이 원본 context 내 몇번째 글자부터 몇번째 글자까지 해당하는지 알 수 있음.
offset_mapping = tokenized_examples.pop("offset_mapping")
# 정답지를 만들기 위한 리스트
tokenized_examples["start_positions"] = []
tokenized_examples["end_positions"] = []
for i, offsets in enumerate(offset_mapping):
input_ids = tokenized_examples["input_ids"][i]
cls_index = input_ids.index(tokenizer.cls_token_id)
# 해당 example에 해당하는 sequence를 찾음.
sequence_ids = tokenized_examples.sequence_ids(i)
# sequence가 속하는 example을 찾는다.
example_index = overflow_to_sample_mapping[i]
answers = examples["answers"][example_index]
# 텍스트에서 answer의 시작점, 끝점
answer_start_offset = answers["answer_start"][0]
answer_end_offset = answer_start_offset + len(answers["text"][0])
# 텍스트에서 현재 span의 시작 토큰 인덱스
token_start_index = 0
while sequence_ids[token_start_index] != 1:
token_start_index += 1
# 텍스트에서 현재 span 끝 토큰 인덱스
token_end_index = len(input_ids) - 1
while sequence_ids[token_end_index] != 1:
token_end_index -= 1
# answer가 현재 span을 벗어났는지 체크
if not (offsets[token_start_index][0] <= answer_start_offset and offsets[token_end_index][1] >= answer_end_offset):
tokenized_examples["start_positions"].append(cls_index)
tokenized_examples["end_positions"].append(cls_index)
else:
# token_start_index와 token_end_index를 answer의 시작점과 끝점으로 옮김
while token_start_index < len(offsets) and offsets[token_start_index][0] <= answer_start_offset:
token_start_index += 1
tokenized_examples["start_positions"].append(token_start_index - 1)
while offsets[token_end_index][1] >= answer_end_offset:
token_end_index -= 1
tokenized_examples["end_positions"].append(token_end_index + 1)
return tokenized_examples
이 function 의 역할은 example 들이 사실상 보여줬던 데이터셋들의 각각의 row 라고 보시면 되고 output 같은 경우는 bert 에 들어갈 수 있는 input 이라고 보면 될 것 같음
이런 저런 pre-procesisng 을 하는 거고 새로운 정보를 더하는 함수임
train_dataset = datasets['train']
print(train_dataset[0])

dictionary 형태로 첫번째 row 에 해당하는 학습 데이터를 볼 수 있음
이걸 부분적으로 고를거기 때문에
train_dataset = train_dataset.select(range(max_train_samples))
print(len(train_dataset))

개수가 원래는 60000개였는데 16개로 줄은 걸 볼 수 있음
이 형태는 bert 가 활용할 수 있는 형태가 아니기 때문에 이걸 변형을 시켜줄텐데 위에서 선언한 prepare_train_features function 을 활용함
column_names = datasets["train"].column_names
train_dataset = train_dataset.map(
prepare_train_features,
batched=True,
num_proc=preprocessing_num_workers,
remove_columns=column_names,
load_from_cache_file=True,
)
train_dataset 을 다시 정의했고 정의하는 방법은 train_dataset 에 mapping 을 하는데 prepare_train_features 아까 정의했던 function 을 활용하고 batched 라는걸 활용해서 dataset 을 들여다 볼 때는 하나씩 보는게 아니라 여러개가 합쳐진 방식으로 보게되고 preprocessing 을 파이파라인화 시킴으로써 processing 을 할 때 한번에 다 하는 방식보다 그때그때 필요할 때 on demand 를 하는 방식을 통해서 효율적으로 그 데이터를 다룰 수 있음
train_dataset[0]
이전에는 사람이 읽을 수 있는 형태로 보였는데 이렇게 적용한 다음에는 숫자밖에 안나옴
같은 형태의 정보를 담고있는 거지만 BERT 가 이해할 수 있는 형태로 바꿨다고 보시면 될 것 같음
train data 를 preprocessing 했다면 validation data 도 preprocessing 해야함
def prepare_validation_features(examples):
tokenized_examples = tokenizer(
examples['question'],
examples['context'],
truncation="only_second",
max_length=max_seq_length,
stride=doc_stride,
return_overflowing_tokens=True,
return_offsets_mapping=True,
padding="max_length",
)
sample_mapping = tokenized_examples.pop("overflow_to_sample_mapping")
tokenized_examples["example_id"] = []
for i in range(len(tokenized_examples["input_ids"])):
sequence_ids = tokenized_examples.sequence_ids(i)
context_index = 1
sample_index = sample_mapping[i]
tokenized_examples["example_id"].append(examples["id"][sample_index])
tokenized_examples["offset_mapping"][i] = [
(o if sequence_ids[k] == context_index else None)
for k, o in enumerate(tokenized_examples["offset_mapping"][i])
]
return tokenized_examples
하는 역할은 똑같음 다만 다른점은 학습데이터를 preprocess 하는 거였다면 validation data 를 preprocess 하는 것임
eval_examples = datasets["validation"]
eval_examples = eval_examples.select(range(max_val_samples))
eval_dataset = eval_examples.map(
prepare_validation_features,
batched=True,
num_proc=preprocessing_num_workers,
remove_columns=column_names,
load_from_cache_file=True,
)
모델이 이해할 수 있는 형태로 validation data 를 맵핑해줌
그러면 데이터를 가져왔고 모델도 가져왔고 데이터를 모델에 적합한 형태로 바꿔줬음
이제는 데이터를 모델에 적용시켜서 학습을 해야함
from transformers import default_data_collator, TrainingArguments, EvalPrediction
from trainer_qa import QuestionAnsweringTrainer
from utils_qa import postprocess_qa_predictions
default_data_collator : 학습을 할 때 여러개의 example 들을 collate 해주는 역할을 하게 됨 TrainingArguments : 학습할 때 주는 Configuration 들을 합쳐서 한번에 줄 수 있는 편리한 클래스임 EvalPrediction : eval prediction 을 쉽게 할 수 있도록 해주는 class
QuestionAnsweringTrainer 를 사용
이걸 쓰면 편하게 학습할 수 있음
def post_processing_function(examples, features, predictions):
# Post-processing: we match the start logits and end logits to answers in the original context.
predictions = postprocess_qa_predictions(
examples=examples,
features=features,
predictions=predictions,
version_2_with_negative=False,
n_best_size=n_best_size,
max_answer_length=max_answer_length,
null_score_diff_threshold=0.0,
output_dir=training_args.output_dir,
is_world_process_zero=trainer.is_world_process_zero(),
)
# Format the result to the format the metric expects.
formatted_predictions = [{"id": k, "prediction_text": v} for k, v in predictions.items()]
references = [{"id": ex["id"], "answers": ex["answers"]} for ex in datasets["validation"]]
return EvalPrediction(predictions=formatted_predictions, label_ids=references)
답이 나왔을 때 답을 우리가 원하는 형태로 맵핑을 해주는 거고 모델이 이해할 수 있는 형태에서 사람이 이해할 수 있는 형태로 맵핑을 해준다고 보면 됨
def compute_metrics(p: EvalPrediction):
return metric.compute(predictions=p.predictions, references=p.label_ids)
metric 을 정의해줌
metric 은 어떤 모델의 prediction 이 답변과 비교했을 때 얼만큼 좋은지를 보는 것
training_args = TrainingArguments(
output_dir="outputs",
do_train=True,
do_eval=True,
learning_rate=3e-5,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
num_train_epochs=num_train_epochs,
weight_decay=0.01,
)
aurgements 를 몇가지 정의해 주자
여러가지 정의한 arguments 들을 모아주는 일종의 convenient 한 class 라고 보면 됨
trainer = QuestionAnsweringTrainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
eval_examples=datasets["validation"],
tokenizer=tokenizer,
data_collator=default_data_collator,
post_process_function=post_processing_function,
compute_metrics=compute_metrics,
)
QuestionAnsweringTrainer 라는 class 가 받는 첫번째 argument 는 model 임
학습할 때 필요한 arguments 들을 args 로 넣어주게 되고
dataset 도 정의해줌
아까 정의할 때 학습 데이터셋을 original dataset 에서 preprocessing function 을 통해서 모델이 이해할 수 있는 형태로 바꿔줬음
그 새로운 dataset 이 들어가게 되는 거고 마찬가지로 eval dataset 도 사람이 이해할 수 있는 형태에서 모델이 이해할 수 있는 형태로 변경해줬고
그 다음엔 eval 에 쓰이는 dataset 을 넣어주게 됨
어떤 toknizer 를 쓸 지 정해주고
어떻게 데이터를 collate 할 지인데 이거 같은 경우는 왠만한 경우는 default_data_collator 를 쓰게 됨
어떻게 collate 즉 붙여줄지인데 거의 default 를 쓴다고 보면 됨
마지막으로 post_precess_function 답변이 나오게 되면 어떻게 다시 사람이 이해할 수 있는 형태로 해석할 지 위와 반대되는 function 임
여기서 정의해주게 됨
위에서는 train_dataset 을 input 으로 받았는데 post_process_function 같은 경우는 dataset 을 input 으로 받는게 아니라 function 을 input 으로 받음
이 function 을 input 으로 받고 내부에서 그때그때 on demand 로 나온 답변을 사람이 이해할 수 있는 형태로 바꿔준다고 보면 됨
마지막으로는 evaluation 을 진행하게 된다면 evaluation 을 어떻게 진행할지 어떤 점수를 낼지에 대한 function 을 마찬가지로 넣어주게 됨
train_result = trainer.train()
학습이 진행 됨
train_result

학습에서 tracking 하고 있는 여러가지 수치들이 나오게 됨
가장 중요한 것은 현재 step 이 몇번째냐 몇번째 batch 를 학습에 활용했냐 global_step 이고 12 개만 활용했기 때문에 12이고 현재 step 에서 loss 가 얼마인지 4.89 이렇게 나오는데 이 2개가 가장 중요하다고 보면 됨
이거는 학습에 대한 수치들이고 실제로 평가를 하려면 evaluation 을 해야 함
metrics = trainer.evaluate()
metrics

현재 모델에서 eval_dataset 을 활용해서 성능이 얼마나 잘나오는지를 볼 수 있음
중요하게 생각하는 2개의 metric 을 볼 수 있음
exact_match 와 f1 인데 학습을 어마 안했기 때문에 exact_match 는 0점이고 f1 도 0점임
2개의 epoch 를 돌았기 때문에 epoch 도 같이 나옴
댓글남기기