Day_48 01. Passage Retrieval - Dense Embedding
작성일
Passage Retrieval - Dense Embedding
1. Introduction to Dense Embedding
Passage Embedding
구절(Passage)을 벡터로 변환하는 것

지난 post 에서는 Passage Embedding 방법 중에서 Sparse Embedding 에 대해서 설명했음
Sparse Embedding
TF-IDF 벡터는 Sparse 함
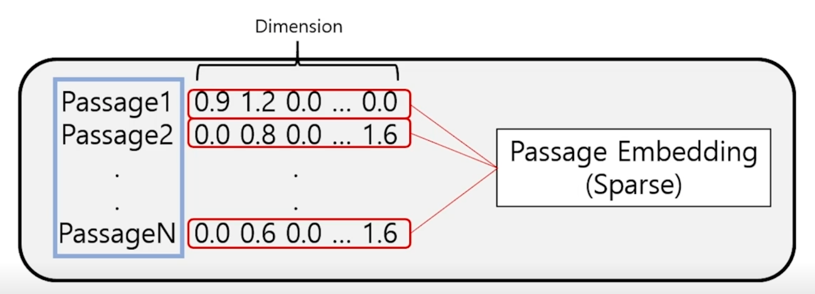
벡터의 크기는 아주 크지만 벡터 크기내에서 실제로 0이 아닌 숫자는 상당히 적게 있음
특히 TF-IDF BoW 방법론을 택하고 있기 때문에 특정 단어가 있는 경우에만 해당 vocab vector 의 dimension 이 non-zero 가 됨으로써 사실상 90% 이상의 dimension 들이 보통은 0이되는 경우가 발생
Limitations of sparse embedding
- 차원의 수가 매우 크다 $\rightarrow$ compressed format 으로 극복 가능
- 유사성을 고려하지 못함
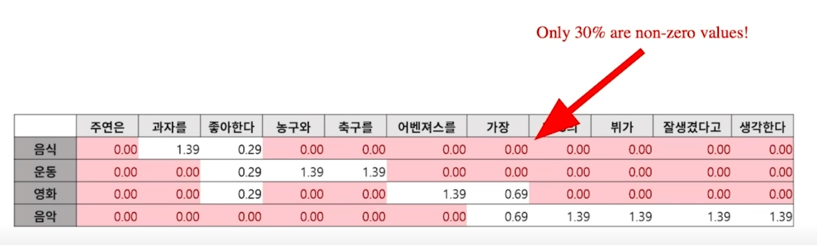
대표적인 방법으로는 non-zero 인 값과 위치만 저장해서 벡터 전체를 저장하지 않는다고 하더라도 상당히 efficient 하게 저장하는 것은 가능
하지만 sparse embedding 의 가장 큰 문제점은 유사성을 쉽게 고려하지 못한다는 것!!
어떤 두 단어가 있을 떄 두 단어가 비슷한 의미를 가진 단어라고 하더라도 sparse embedding 형태로 다른 단어일 때 두 단어는 vector space 에서 완전히 다른 dimension 을 차지하는 그리고 그 vector space 상에서는 전혀 두개의 유사성을 고려할 수 없는 형태가 됨
이런 단점을 극복하기 위해서 최근에는 Dense Embedding 이 많이 쓰이고 있음
Dense Embedding 이란?
Complementary to sparse representations by design
- 더 작은 차원의 고밀도 벡터 (length = 50-1000)
- 각 차원이 특정 term 에 대응되지 않음
- 대부분의 요소가 non-zero 값

Sparse Embedding 의 단점의 많은 부분을 보완한다고 보면 됨
Sparse 같은 경우는 vocab size 와 똑같은 혹은 n-gram 을 고려했을때는 vocab size 이상의 훨씬 더 큰 vector size 로 mapping 되는 반면에 Dense 같은 경우는 훨씬 더 작은 차원의 고밀도 vector 가 됨
Retrieval: Sparse vs Dense

Sparse 같은 경우는 단어의 존재 유무 이런 것들을 Retrieval 할 때 유용하지만 논리적으로 해석하기 쉽지 않고 따라서 Dense 처럼 의미가 같다하더라도 다른 단어로 표현되는 경우를 detect 할 수 있는 방법론을 쓰곤 함
그리고 Sparse 같은 경우는 항상 dimension 이 Dense 에 비해 크기때문에 결국에는 활용할 수 있는 알고리즘에 한계가 있는 반면에 Dense 같은 경우는 dimension 이 작기 때문에 훨씬 더 많은 종류의 알고리즘을 활용할 수 있음
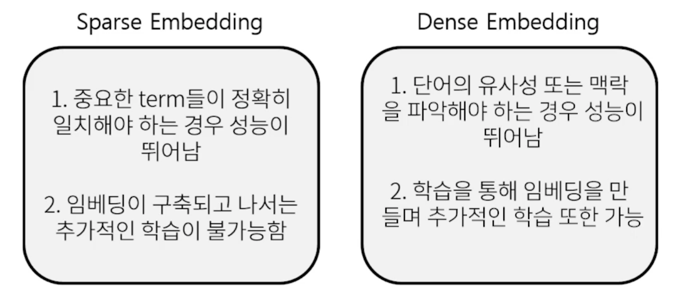
$\rightarrow$ 최근 사전학습 모델의 등장, 검색 기술의 발전 등으로 인해 Dense Embedding 을 활발히 이용
현업에서 Sparse Embedding 도 많이 쓰입니다만 Sparse 혼자만으로 많은 것을 하기는 쉽지 않음
그래서 일반적으로는 Sparse Embedding 을 쓰면서 동시에 Dense Embedding 을 쓰거나 또는 Dense Embedding 만으로 retrieval 을 구축하는 것을 추천함
Overview of Passage Retrieval with Dense Embedding
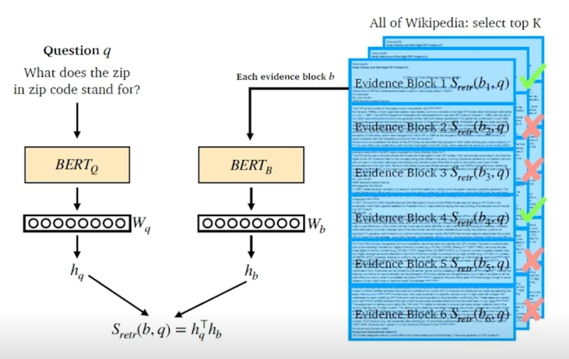
왼쪽에는 question 에 대응되는 encoder 가 있음 sentence 를 encoding 해서 [CLS] 토큰에 해당되는 vector 를 보고 그 embedding 을
$h_q$ 라는 vector 로 지칭되는 vector 를 내보내게 됨
마찬가지로 passage 쪽도 동일한 방법으로 다만 다른 형태의 다른 파라미터를 활용한 BERT 를 활용해서 passage 를 똑같이 [CLS] 토큰을 활용해서
$h_b$ 라는 vector 를 내보내게 됨
여기서 중요한 것 중 하나는 이 두개의 vector 가 같은 size 여야 함
같은 size 의 경우 두개의 유사도를 계산할 수 있음
가장 일반적으로 많이 쓰는 유사도 계산하는 방법은 두개를 dot-product 하는 것임
그래서 $S_{retr}(b, q) = h_q^Th_b$ 에서 보이는 것처럼 $h_q^T$ 와 $h_b$ 를 multiply 해줌으로써 scalar value 를 구할 수 있도록 함
물론 이 숫자는 현재 question 과 특정 passage 의 유사도를 계산한 것이고 모든 passage 에 대해서 유사도를 계산하고 싶다면 passage 를 하나씩 하나씩 넣어서 점수를 다 구한다음에 가장 높은 점수를 가진 passage 를 MRC 모델에 활용하면 됨
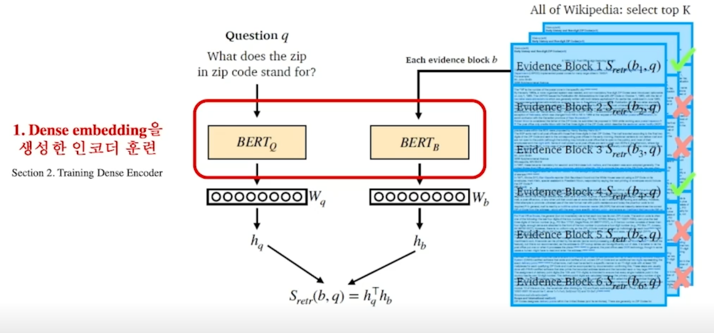
실제로 훈련을 해야하는 대상은 BERT 부분임
question 과 passage 를 다른 encoder 를 쓰는데 같은 encoder 를 쓰는 경우도 있고 다만 architecture 는 두개가 동일함
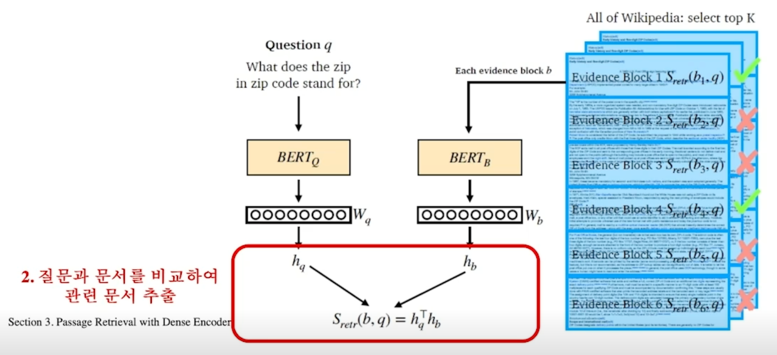
결국 이 두개의 output 을 score 를 내서 두개의 output 을 비교해서 score 를 내는 방법으로 가장 유사한 문서를 찾는 방법을 활용함
2. Training Dense Encoder
What can be Dense Encoder?
BERT 와 같은 Pre-trained language model (PLM) 이 자주 사용
그 외 다양한 neural network 구조도 가능
BERT 만이 option 이 아니고 다양한 pre-trained Language Model (PLM) 이라고 불리는 모델을 활용해서 fine-tuning 해가지고 활용할 수 있음
여기서 BERT 를 사용하는 방법은 MRC 와 상당히 유사한데 다만 좀 다른점은 MRC 같은 경우는 passage 와 question 을 둘다 input 으로 넣어주는 반면에 이번의 경우는 각각 passage 와 question 을 넣어주고 각각의 embedding 을 구하고 싶기 때문에 독립적으로 넣어주게 됨
BERT as dense encoder $\rightarrow$ [CLS] token 의 output 사용
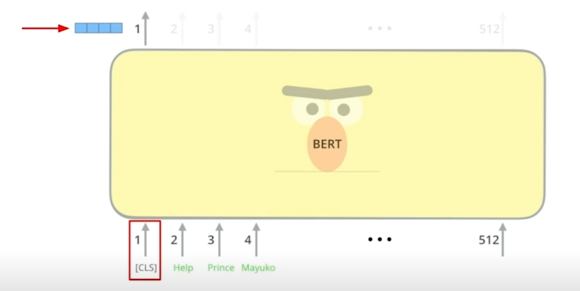
또 다른점은 기존의 passage 내의 답변이 어디있을지 예측하기 위해서 일종의 각 token 별로 score 를 내는것이 목적이었다면 이번엔 embedding 을
output 하는게 목적이기 때문에 [CLS] 토큰 쪽을 보면서 [CLS] 토큰의 최종 embedding 이 뭔지를 output 함으로써 passage 를 encoding
하게 됨
passage 뿐만 아니라 question 도 똑같은 방식으로 encoding 을 하고 다만 같은 파라미터를 쓸지 별개의 파라미터를 쓸지는 좀 더 design choice 로 보면 되고 경우에 따라서 하나가 다른 것보다 더 잘 될 수 있음
Dense Encoder 구조
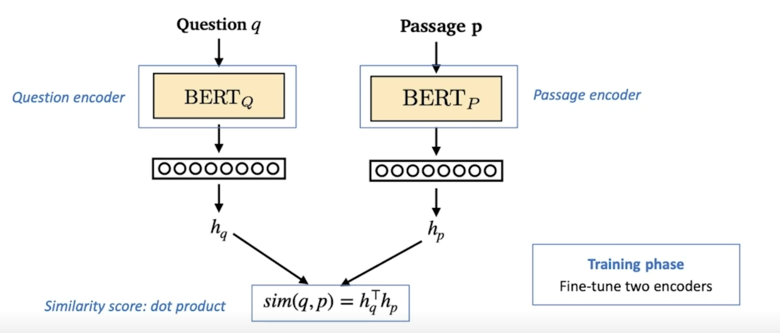
question 이랑 passage 를 BERT 를 활용해서 vector 를 내보내게되고 이 vector 두개를 유사도를 측정함으로써 최종 유사점수를 낼 수 있음
학습시에는 여기서 BERT 를 fine-tuning 해가지고 실제 정답인 passage 같은 경우는 유사도 점수가 더 높도록 학습하고 정답이 아닌 passage 인 경우는 유사도 점수가 최대한 - 쪽으로 갈 수 있도록 학습해서 최종적으로 모델을 완성함
Dense Encoder 학습 목표와 학습 데이터
학습목표 : 연관된 question 과 passage dense embedding 간의 거리를 좁히는 것 (또는 inner product 를 높이는 것). 즉 higher similarity Challenge : 연관된 question / passage 를 어떻게 찾을 것인가? $\rightarrow$ 기존 MRC 데이터셋을 활용
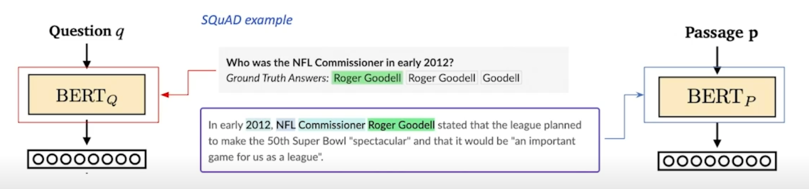
MRC 데이터셋에 있는 pair 는 정답셋이라고 볼 수 있고 이 passage 는 해당 질문에 해당되는 passage 라고 볼 수 있음
그 외의 passage 들은 관련이 없는 passage 라고 볼 수 있음
Dense Encoder 학습 목표와 학습 데이터 - Negative Sampling
1) 연관된 question 과 passage 간의 dense embedding 거리를 좁히는 것 (higher similarity) $\rightarrow$ Positive 2) 연관 되지 않은 question 과 passage 간의 embedding 거리는 멀어야 함 $\rightarrow$ Negative
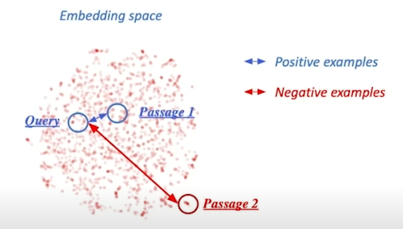
따라서 관련이 없는 passage 를 sample 하기 위해서는 기본적으로 random 하게 sample 해오고 관련이 있는 passage 같은 경우는 question 이 속해있던 passage 를 사용해서 한쪽은 거리를 좁히고 한쪽은 거리를 멀리하는 방식으로 학습을 진행함
Choosing negative examples
- Corpus 내에서 랜덤하게 뽑기
- 좀 더 헷갈리는 negative 샘플들 뽑기 (ex. 높은 TF-IDF 스코어를 가지지만 답을 포함하지 않는 샘플)
최근에 2번 방법론을 선택해서 성능을 올린 방법이 많이 있음
Objective function
Positive passage 에 대한 negative log likelihood (NLL) loss 사용
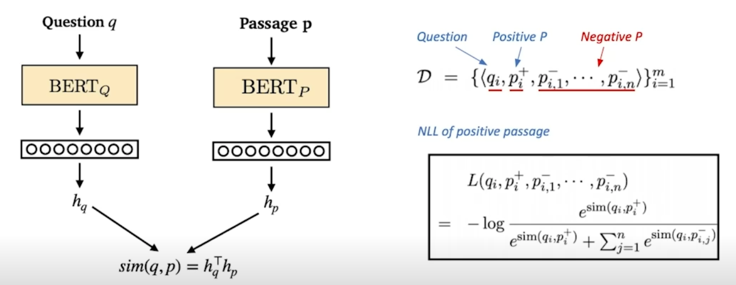
positive passage score 를 확률화 하기 위해서 positive passage 와 question 간의 실수인 similarity score 이 점수랑 negative sample 에 대한 점수를 가져와서 softmax 를 하여 그 softmax 한 값의 확률값을 negative log likelihood 에 적용해서 학습하는 방법을 택함
Evaluation Metric for Dense Encoder
Top-k retrieval accuracy : retrieve 된 passage 중에 답을 포함하는 passage 의 비율
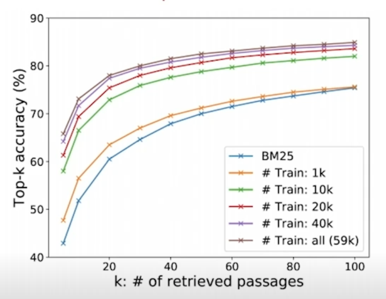
여기서 말하는 답은 최종 MRC 답변임
3. Passage Retrieval with Dense Encoder
From dense encoding to retrieval
Inference : Passage 와 query 를 각각 embedding 한 후, query 로부터 가까운 순서대로 passage 의 순위를 매김
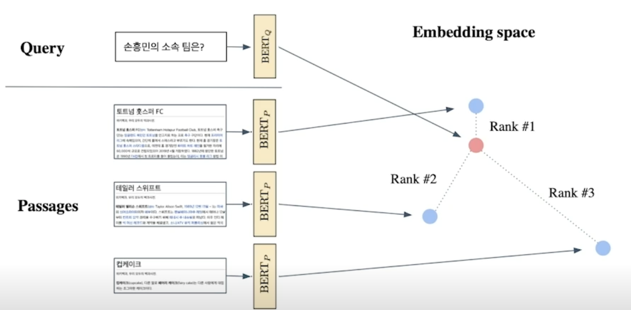
From retrieval to open-domain question answering
Retriever 를 통해 찾아낸 Passage 을 활용, MRC (Machine Reading COmprehension) 모델로 답을 찾음
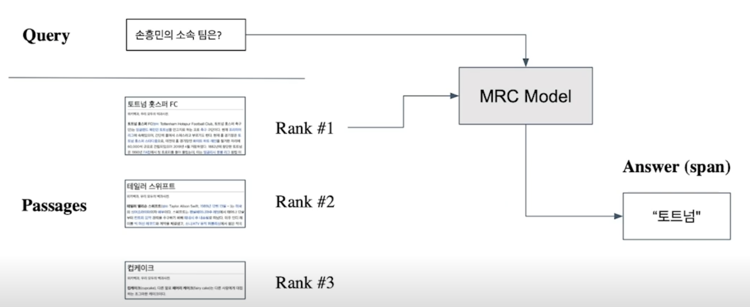
How to make better dense encoding
- 학습 방법 개선 (e.g. DPR)
- 인코더 모델 개선 (BERT 보다 큰, 정확한 Pretrained 모델)
- 데이터 개선 (더 많은 데이터, 전처리, 등)
Further Reading
실습
BERT를 활용한 Dense Passage Retrieval 실습
library 설치
!pip install datasets
!pip install transformers
korquad 데이터 다운로드
from datasets import load_dataset
dataset = load_dataset('squad_kor_v1')
corpus = list(set([example['context'] for example in dataset['train']]))
len(corpus)
 문장을 가지고 있음
문장을 가지고 있음
bert-multilingual 모델을 사용하겠음
from transformers import AutoTokenizer
import numpy as np
model_checkpoint = 'bert-base-multilingual-cased'
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
tokenizer

tokenizer 가 잘 불려온것을 확인할 수 있음
tokenizer 를 사용해서 input 을 tokenizing 해보자
print(corpus[0])
tokenized_input = tokenizer(corpus[0], padding='max_length', truncation=True)
tokenizer.decode(tokenized_input['input_ids'])

실제 text 를 print 하고 실제 text 가 tokenize 됐다가 다시 decode 되서 원래 text 로 돌아온 것을 볼 수 있고 다만 special token 들이 남아있는 것을 볼 수 있음
Dense Encoder 를 학습할 때는 기본적으로 BERT 를 활용해서 할텐데 몇개 중요한 package 들을 import 하자
from tqdm import tqdm, trange
import argparse
import random
import torch
import torch.nn.functional as F
from transformers import BertModel, BertPreTrainedModel, AdamW, TrainingArguments, get_linear_schedule_with_warmup
torch.manual_seed(2021)
torch.cuda.manual_seed(2021)
np.random.seed(2021)
random.seed(2021)
학습데이터를 정의할텐데 실습에서는 모든 데이터를 쓰지않을 것임
sample_idx = np.random.choice(range(len(dataset['train'])), 128)
training_dataset = dataset['train'][sample_idx]
print(len(dataset['train']), len(training_dataset))
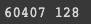
원래는 60407 개였는데 128개로 줄음
간단하게 tokenization 을 하자
from torch.utils.data import (DataLoader, RandomSampler, TensorDataset)
q_seqs = tokenizer(training_dataset['question'], padding='max_length', truncation=True, return_tensors='pt')
p_seqs = tokenizer(training_dataset['context'], padding='max_length', truncation=True, return_tensors='pt')
tokenization 을 완료했음
이 다음엔 dataset 을 학습하기 위해서 tensor dataset 으로 변경해줌
train_dataset = TensorDataset(p_seqs['input_ids'], p_seqs['attention_mask'], p_seqs['token_type_ids'],
q_seqs['input_ids'], q_seqs['attention_mask'], q_seqs['token_type_ids'])
6개의 input 값들을 학습할 때 편리하게 access 할 수 있도록 해줌
model 을 정의하자
class BertEncoder(BertPreTrainedModel):
def __init__(selfself, config):
super(BertEncoder, self).__init__(config)
self.bert = BertModel(config)
self.init_weights()
def forward(self, input_ids, attention_mask=None, token_type_ids=None):
outputs = self.bert(input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids)
pooled_output = outputs[1]
return pooled_output
모델을 정의했음
이제는 모델 초기화를 해주자
p_encoder = BertEncoder.from_pretrained(model_checkpoint)
q_encoder = BertEncoder.from_pretrained(model_checkpoint)
if torch.cuda.is_available():
p_encoder.cuda()
q_encoder.cuda()
print('GPU enabled')
학습루틴을 정의하자
def train(args, dataset, p_model, q_model):
# Dataloader
train_sampler = RandomSampler(dataset)
train_dataloader = DataLoader(dataset, sampler=train_sampler, batch_size=args.per_device_train_batch_size)
# Optimizer
no_decay = ['bias', 'LayerNorm.seight']
optimizer_grouped_parameters = [
{'params': [p for n, p in p_model.named_parameters() if not any(nd in n for nd in no_decay)], 'weight_decay': args.weight_decay},
{'params': [p for n, p in p_model.named_parameters() if any(nd in n for nd in no_decay)], 'weight_decay': 0.0},
{'params': [p for n, p in q_model.named_parameters() if not any(nd in n for nd in no_decay)], 'weight_decay': args.weight_decay},
{'params': [p for n, p in q_model.named_parameters() if any(nd in n for nd in no_decay)], 'weight_decay': 0.0},
]
optimizer = AdamW(optimizer_grouped_parameters, lr=args.learning_rate, eps=args.adam_epsilon)
t_total = len(train_dataloader) // args.gradient_accumulation_steps * args.num_train_epochs
scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=args.warmup_steps, num_training_steps=t_total)
# Start training!
global_step = 0
p_model.zero_grad()
q_model.zero_grad()
torch.cuda.empty_cache()
train_iterator = trange(int(args.num_train_epochs), desc='Epoch')
for _ in train_iterator:
epoch_iterator = tqdm(train_dataloader, desc='Iteration')
for step, batch in enumerate(epoch_iterator):
q_encoder.train()
q_encoder.train()
if torch.cuda.is_available():
batch = tuple(t.cuda() for t in batch)
p_inputs = {'input_ids': batch[0],
'attention_mask': batch[1],
'token_type_ids': batch[2],
}
q_inputs = {'input_ids': batch[3],
'attention_mask': batch[4],
'token_type_ids': batch[5],
}
p_outputs = p_model(**p_inputs) # (batch_size, emb_dim)
q_outputs = q_model(**q_inputs) # (batch_size, emb_dim)
# Calculate similarity score & loss
sim_scroes = torch.matmul(q_outputs, torch.transpose(p_outputs, 0, 1)) # (batch_size, emb_dim) x (emb_dim, batch_size) = (batch_size, batch_size)
# target: position of positive samples = diagonal element
targets = torch.arange(0, args.per_device_train_batch_size).long()
if torch.cuda.is_available():
targets = targets.to('cuda')
sim_scroes = F.log_softmax(sim_scroes, dim=1)
loss = F.nll_loss(sim_scroes, targets)
print(loss)
loss.backward()
optimizer.step()
scheduler.step()
q_model.zero_grad()
p_model.zero_grad()
global_step += 1
torch.cuda.empty_cache()
return p_model, q_model
이 train 루틴이 trainer 의 역할과 비슷함
trainer 와 유사한 function 을 만들면서 실습을 진행하고 있음
이 다음엔 TrainingArguments 를 정의하자
args = TrainingArguments(
output_dir='dense_retrieval',
evaluation_strategy='epoch',
learning_rate=2e-5,
per_device_train_batch_size=4,
per_device_eval_batch_size=4,
num_train_epochs=2,
weight_decay=0.01,
)
이제 학습을 진행하자
p_encoder, q_encoder = train(args, train_dataset, p_encoder, q_encoder)
학습이 끝났으니 학습된 모델을 활용해서 retrieval 을 해보자
valid_corpus = list(set([example['context'] for example in dataset['validation']]))[:10]
sample_idx = random.choice(range(len(dataset['validation'])))
query = dataset['validation'][sample_idx]['question']
ground_truth = dataset['validation'][sample_idx]['context']
print(query, ground_truth)

이게 실제로 corpus 에 있는지 없는지를 확인해봐야 함
if not ground_truth in valid_corpus:
valid_corpus.append(ground_truth)
def to_cuda(batch):
return tuple(t.cuda() for t in batch)
각각의 passage 에 대한 embedding 을 확보하자
with torch.no_grad():
p_encoder.eval()
q_encoder.eval()
q_seqs_val = tokenizer([query], padding='max_length', truncation=True, return_tensors='pt').to('duca')
q_emb = q_encoder(**q_seqs_val).to('cpu')
p_embs = []
for p in valid_corpus:
p = tokenizer(p, padding='max_length', truncation=True, return_tensors='pt').to('cuda')
p_emb = p_encoder(**p).to('cpu').numpy()
p_embs.append(p_emb)
p_embs = torch.Tensor(p_embs).squeeze()
print(p_embs.size(), q_emb.size())

11이 의미하는 바는 passage 의 개수이고 10개였다가 정답으로 쓸 passage 가 없어서 더해져가지고 11개가 됨
768 같은 경우는 embedding size 임
question 쪽도 embedding size 는 768 이고 question 은 하나만 있으니까 앞에 사이즈는 1임
question 과 passage 의 embedding 을 구했으면 양쪽의 similarity 를 구해야 함
dot_product score 를 계산하기 위해서 matmul 을 해줌
dot_prod_scores = torch.matmul(q_emb, torch.transpose(p_embs, 0, 1))
print(dot_prod_scores.size())

예산한대로 (1, 11) 이 나오고 11개의 문서에대한 해당 쿼리의 유사도 점수라고 보면 됨
이제 가장 높은걸 찾으면 됨
rank = torch.argsort(dot_prod_scores, dim=1, descending=True).squeeze()
print(dot_prod_scores)
print(rank)

6번째 문서가 rank 가 0으로 가장 유사도가 높음
k = 11
print('[Search query]\n', query, '\n')
print('[Ground truth passage]')
print(ground_truth, '\n')
for i in range(k):
print('Top-%d passage with score %.4f' % (i + 1, dot_prod_scores.squeeze()[rank[i]]))
print(valid_corpus[rank[i]])

학습을 오래하지 않아서 top-1 에 나오진 않았고 top-7 에 나왔음
학습을 많이하게되면 top-7 에 나왔던 ranking 이 좀 더 올라가는 걸 볼 수 있음
댓글남기기