Day_46 01. MRC Intro & Python Bascis
작성일
MRC Intro & Python Bascis
Course Objective
사용자의 질문을 답할 수 있는 Question Answering 모델을 밑바닥부터 개발
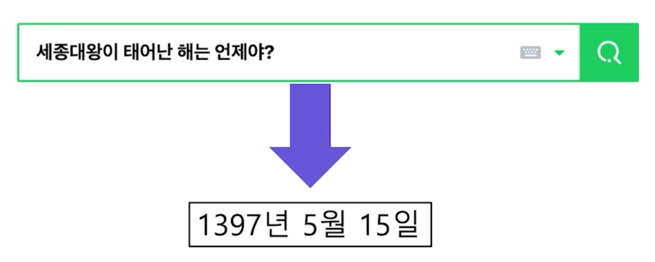
1. Introduction to MRC
Machine reading comprehension (MRC) 개념
- 기계 독해 (Machine Reading Comprehension)
- 주어진 지문 (Context) 를 이해하고, 주어진 질의 (Qeury/Question) 의 답변을 추론하는 문제
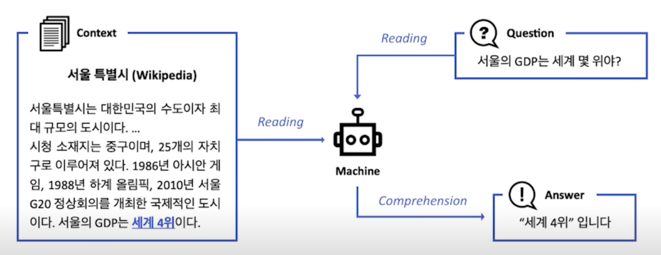
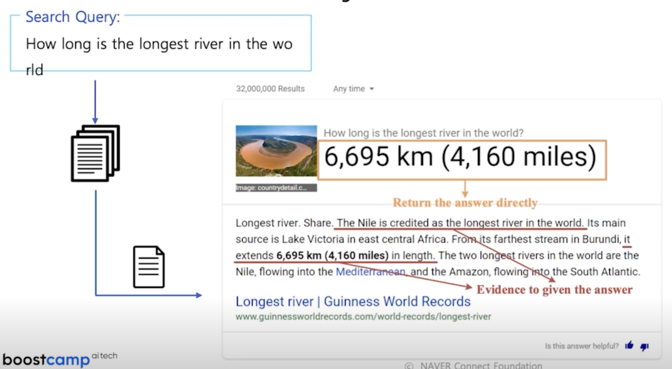
Search engine with MRC
Dialog system with MRC
MRC 의 종류
- 1) Extractive Answer Datasets
- 질의 (question) 에 대한 답이 항상 주어진 지문 (context) 의 segment (or span) 으로 존재

중간에 어떤 단어를 빼고 그걸 맞추는 형태로 게임이 진행되는데 이런걸 cross test 라고 하고 엄밀하게는 Question & Answering 은 아님
QA 같은 경우는 아주 비슷하지만 질문이 더 이상은 빠진 단어를 맞추는 것이 아니라 실제로 지문형태로 들어오게 됨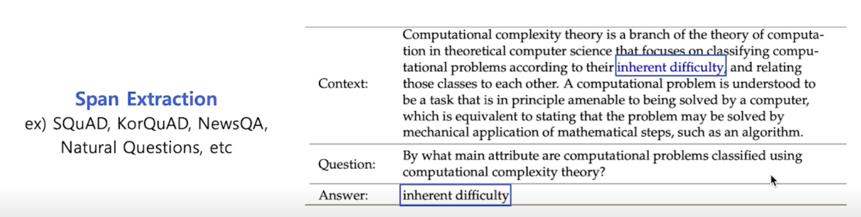
질문에 대한 답변이 context(지문) 안에 존재한다는 가정으로 문제를 진행하게 됨
- 2) Descriptive/Narrative Answer Datasets
- 답이 지문 내에서 추출한 span 이 아니라, 질의를 보고 생성 된 sentence (or free-form) 의 형태
ex) MS MARCO, Narrative QAMS MARCO(Bajaj et al., 2016)

지문내에는 없는 답변을 생성해내는 task 로 진행됨
- 3) Multiple-choice Datasets
- 질의에 대한 답을 여러 개의 answer candidates 중 하나로 고르는 형태
ex) MCTest, RACE, ARC, etc.MCTest(Richardson et al., 2013)


MRC Datasets
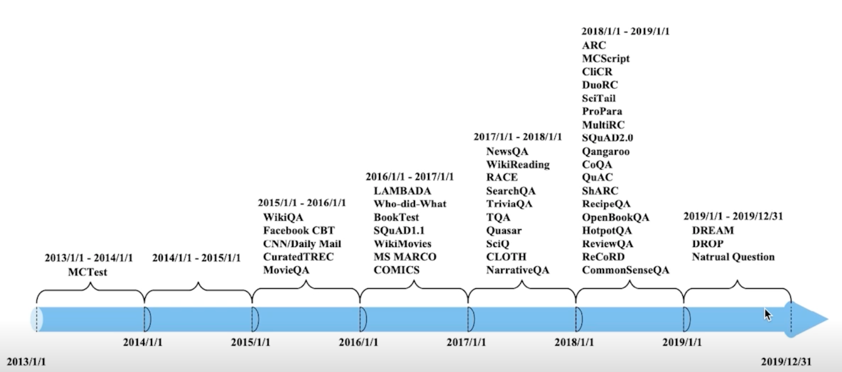
MRC 라는 task 는 주어진 지문에서 질문에 대한 답변을 하는 방식이지만 이걸 응용하게되면 지문이 주어져있지 않은 상태에서 질문이 들어와도 질문과 관련이있는 지문을 웹상에서 찾아가지고 답변을 줄 수 있는 형태로 즉 Question Answering system 을 만들 수 있기 때문에 상당히 유용해서 커뮤니티나 산업계에서도 아주 많이 애용되고있고 상당히 많은 분들이 연구하는 분야임
2013년 MCTest 데이터셋을 시작으로 2018년쯤부터는 아주 많은 수의 MRC 데이터셋들이 공개되는 걸 볼 수 있음
Challenges in MRC
-
- 단어들의 구성이 유사하지는 않지만 동일한 의미의 문장을 이해
- 같은 의미의 문장이지만 다른 단어로 이루어진 문장
Dataset example: DuoRC (paraphrased paragraph)
-
대명사가 무엇을 지칭하는지 이해
Dataset example: QuoRef (coreference resolution)
-
- Unanswerable questions
- 지문내에 답변이 존재하지 않음
- Question with ‘No Answer’
- ex. SQuAD 2.0
- Example
-
little opposition (paragraph) vs. significant opposition (question) $\rightarrow$ 주어진 지문에서는 질문에 대한 답을 찾을 수 없음

-
-
- Multi-hop reasoning
- 질문에 대한 답을 하기 위해서 여러개의 문서를 조합해야 하는 경우
- 여러 개의 document 에서 질의에 대한 supporting fact 를 찾아야지만 답을 찾을 수 있음
- ex. HotpotQA, QAngaroo


MRC 의 평가방법
1) Exact Match / F1 Score: For extractive answer and multiple-choice answer datasets
Exact Match (EM) or Accuracy
예측한 답과 ground-truth 이 정확히 일치하는 샘플의 비율
(Number of correct samples) / (Number of whole samples)
F1 Score
예측한 답과 ground-truth 사이의 token overlap 을 F1 으로 계산
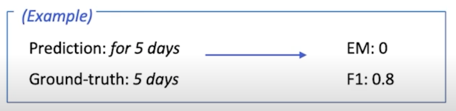
free-form 형태의 answer 는 이 방법을 쓰기 힘듦
EM 같은 경우에는 같지 않기 때문에 0점이지만 F1 Score 같은 경우에는 겹치는 음절에 대해 partial score 를 부여해 0.8점임
2) ROUGE-L / BLEU: For descriptive answer datasets
$\rightarrow$ Ground-truth 와 예측한 답 사이의 overlap 을 계산
ROUGE-L Score
예측한 값과 ground-truth 사이의 overlap recall
(ROUGE-L $\rightarrow$ LCS (Longest common subsequence) 기반)
BLEU (Bilingual Evaluation Understudy)
예측한 답과 ground-truth 사이의 precision
(BLEU-n $\rightarrow$ uniform n-gram weight)
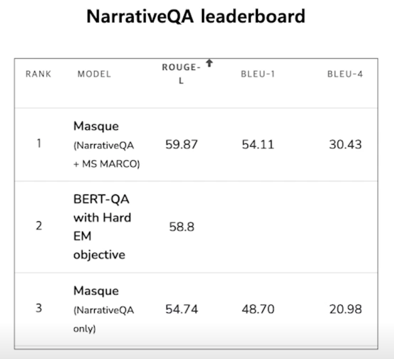
descriptive answer 의 경우는 완벽하게 일치하는 답변을 찾기 쉽지 않고 그러기 때문에 대부분의 답이 0점일 수 있음
그러면 F1 Score 를 쓸 수 있지 않냐고 할 수 있는데 F1 Score 도 쓸 수 있지만 조금 더 많이 쓰이는게 F1 Score 같은 경우 단어의 overlap 만 보다보니까 답변 자체의 언어적인 부분에서 변화를 보기 힘든 부분이 있어서 실제로는 BLEU 나 ROUGE-L 을 많이 씀
ROUGE-L 같은 경우 overlap 을 보긴 하지만 단어마다 보는 거 뿐만 아니라 스코어의 정의에 따라서 여러개의 단어가 겹치는지 안겹치는지를 Logest common subsequence 라는 개념으로 찾게 됨
BLEU 도 비슷한데 n 이라는 숫자르 정의해서 n-gram 을 실제로 비교해서 n-gram 끼리 겹치는 비율을 계산하게 됨
2. Unicode & Tokenization
Unicode 란?
전 세계의 모든 문자를 일관되게 표현하고 다룰 수 있도록 만들어진 문자셋
각 문자마다 숫자 하나에 매핑한다.

인코딩 & UTF-8
인코딩이란?
문자를 컴퓨터에서 저장 및 처리할 수 있게 이진수로 바꾸는 것
UTF-8 (Unicode Transformation Format)
UTF-8 는 현재 가장 많이 쓰이는 인코딩 방식
문자 타입에 따라 다른 길이의 바이트를 할당함
- 1 byte: Standard ASCII
- 2 bytes: Arabic, Hebrew, most European scripts
- 3 bytes: BMP(Basic Multilingual Plane) - 대부분의 현대 글자 (한글 포함)
- 4 bytes: All Unicode characters - 이모지 등

왜 좋냐면?
영어를 쓰게되면 영어는 ASCII 내에서 보통 해결이 됨
ASCII 의 경우 character 의 개수가 256개로 제한하고 있기 때문에 byte 1개 $2^8$ 개수만 필요함
그래서 문자를 1byte 로 모두 나타낼 수 있습니다만 문제는 다른 언어들을 쓰기 시작하면 더 많은 byte 가 필요하게 됨
그래서 그때그때 필요할 때마다 byte 를 추가 할당하는 방식으로 효율적인 문자 인코딩을 하게 됨
Pythone 에서 Unicode 다루기
Python3 부터 string 타입은 유니코드 표준을 사용
ord
문자를 유티코드 code point 로 변환
chr
Code point 를 문자로 변환

Unicode 와 한국어
한국어는 한자 다음으로 유니코드에서 많은 코드를 차지하고 있음
완성형
현대 한국어의 자모 조합으로 나타낼 수 있는 모든 완성형 한글 11,172자(가, 각, …, 힢, 힣)
(U + AC00 ~ U + D7A3)
조합형
조합하여 글자를 만들 수 있는 초 $\cdot$ 중 $\cdot$ 종성
(U + 1100 ~ U + 11FF, U + A960 ~ U + A97F, U + D7B0 ~ U + D7FF)

토크나이징
텍스트를 토큰 단위로 나누는 것
단어(띄어쓰기 기준), 형태소, subword 등 여러 토큰 기준이 사용됨
Subword 토크나이징
자주 쓰이는 글자 조합은 한 단위로 취급하고, 자주 쓰이지 않는 조합은 subword 로 쪼갬
“##” 은 디코딩 (토크나이징의 반대 과정) 을 할 때 해당 토큰을 앞 토큰에 띄어쓰기 없이 붙인다는 것을 뜻함

토크나이저 방법론은 모델의 일부라고 보는게 좋음
BPE (Byte-Pair Encoding)
데이터 압축용으로 제안된 알고리즘
NLP 에서 토크나이징용으로 활발하게 사용되고 있음
- 가장 자주 나오는 글자 단위 Bigram (or Byte pair) 를 다른 글자로 치환
- 치환된 글자를 저장
- 1 ~ 2 번을 반복
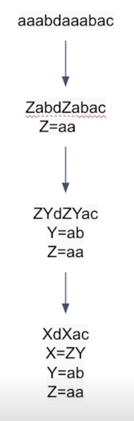
예전에는 re 같은 사람이 직접 고안한 룰을 활용해서 단어를 토크나이징 했음
그런데 이런 방식은 사람이 직접 룰을 짜기때문에 한계가 있다고 일반적으로 동의를 하고 있음
BPE 같은 데이터 조인 방법론으로 접근하는게 일반적이게 되었음
3. Looking into the Dataset
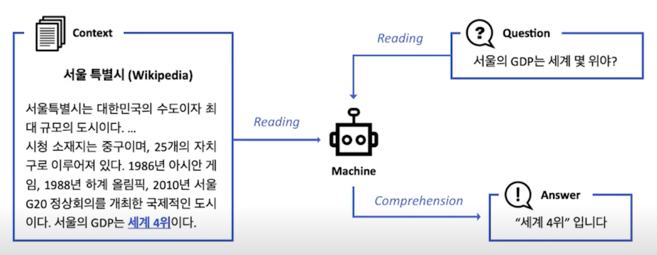
KorQuAD란?
LG CNS 가 AI 언어지능 연구를 위해 공개한 질의응답/기계독해 한국어 데이터셋
- 인공지능이 한국어 질문에 대한 답변을 하도록 필요한 학습 데이터셋
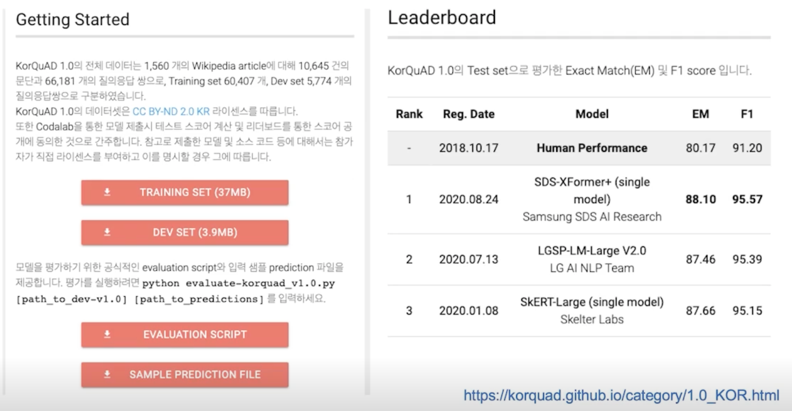
- 1,550개의 위키피디아 문서에 대해서 10,649건의 하위 문서들과 크라우드 소싱을 통해 제작한 63,952개의 질의응답 쌍으로 구성되어 있음 (TRAIN 60,407 / DEV 5,774 / TEST 3,898)
- 누구나 데이터를 내려받고, 학습한 모델을 제출하고 공개된 리더보드에 평가를 받을 수 있음 $\rightarrow$ 객관적인 기준을 가진 연구 결과 공유가 가능해짐
- 현재 v1.0, v2.0 공개: 2.0은 보다 긴 분량의 문서가 포함되어 있으며, 단순 자연어 문장 뿐 아니라 복잡한 표와 리스트 등을 포함하는 HTML 형태로 표현되어 있어 문서 전체 구조에 대한 이해가 필요
KorQuAD 데이터 수집 과정
- SQuAD v1.0 의 데이터 수집 방식을 벤치마크하여 표준성을 확보함

HuggingFace datasets 라이브러리 소개
- HuggingFace 에서 만든 datasets 는 자연어처리에 사용되는 대부분의 데이터셋과 평가 지표를 접근하고 공유할 수 있게끔 만든 라이브러리
- Numpy, Pandas, PyTorch, Tensorflow2 와 호환
- 접근가능한 모든 데이터셋이 memory-mapped, cached 되어있어 데이터를 로드하면서 생기는 메모리 공간 부족이나 전처리 과정 반복의 번거로움 등을 피할 수 있음
- KorQuAD 데이터셋의 경우 squad_kor_v1, squad_kor_v2 로 불러올 수 있음

KorQuAD 예시

title, context 에 해당하는 질문이 여러개 들어있음
질문은 text 로 들어있고 답변은 정확한 word 와 answer_start 가 들어있음
의미가 무엇이냐면?
“미국 육군 부참모 총장” 이라는 답이 지문내에서 몇번째 character 에서 시작하는지 알려줌
이게 중요할 수 있는 이유가 저 답변이 한번만 나온다면 사실 문제가 아닐것임 하지만 경우에 따라서는 답변이 지문내에서 여러개가 나올 수 있음
근데 그 답변을 유추할 수 있었던 문장이 하나만일수도 있음
한 문장에서는 답변으로 활용될 수 있는 문자이었고 다른 text 같은 경우는 실제고 그게 나오긴 했지만 답변을 유추할 수 없는 문장일 수 있음
이런 것들은 학습할 때 상당히 중요한데 학습을 할 때 supervision 을 정확히 주기 위해서는 Extract QA 데이터셋 같은 경우 중요할 수 있기때문에
SQuAD 나 KorQuAD 같은 경우 answer_start 라는 숫자를 주어지게 됨
물론 숫자가 주어지지 않아도 모델 학습은 가능하고 숫자가 주어지는 경우를 strong supervision 이라고 보면 되고 숫자가 주어지지 않은 경우를
좀 더 distant 한 supervision 이라고 보면 됨
실제 데이터 출력 형태

answers 의 answer_start 와 text 가 리스트로 되어있는데 답변이 여러개가 존재할 수 있어서 리스트로 되어 있음
하지만 많은 경우에 답변이 하나고 실제로 학습할 때도 답변을 하나만 볼 것이기 때문에 train data 에서는 answer_start 나 text 의
list 의 length 는 1개이고 다만 validation 이나 test dataset 에서는 교향곡만이 답변이 아니라고 한다면 다른것도 답변으로 인정을
해줘야하니 저 list 가 length 가 1개가 아니라 2개 혹은 3개이상의 답변을 포함하는 list 일 수 있음
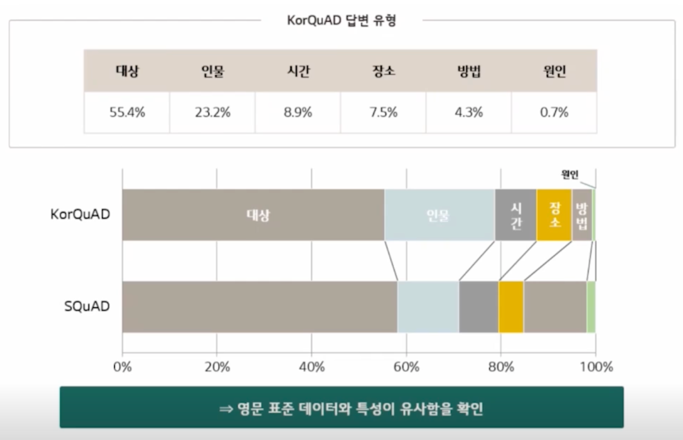
KorQuAD 통계치
-
질문 유형

-
답변 유형
댓글남기기