Day_49 01. Linking MRC and Retrieval
작성일
Linking MRC and Retrieval
1. Introduction to ODQA
Linking MRC and Retrieval: Open-domain Question Answering (ODQA)
MRC : 지문이 주어진 상황에서 질의응답
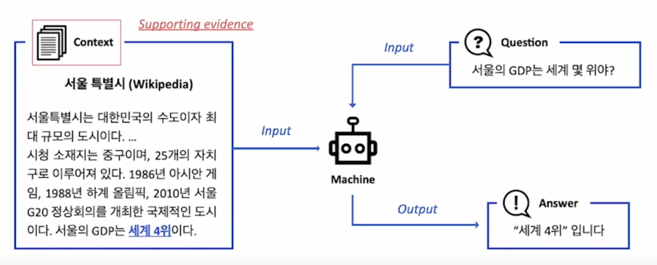
ODQA : 지문이 따로 주어지지 않음. 방대한 World Knowledge 에 기반해서 질의응답
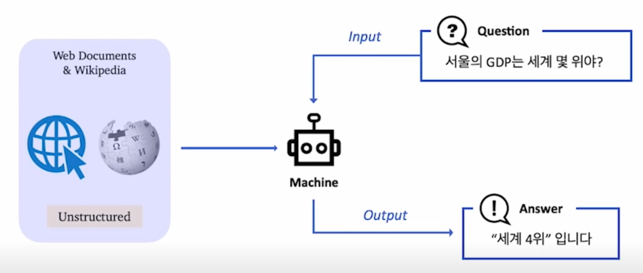
MRC 와 다르게 ODQA 은 비슷한 형태지만 조금 달라짐
바로 Supporting evidence 즉, 지문 부분이 주어지는 것이 아니라 좀 더 넓은 의미로 wikipedia 또는 web 전체가 주어지게 됨
이렇기 때문에 똑같은 형태로 질문을 한다 하더라도 우리가 봐야하는 문서의 크기는 하나가 아닌 위키피디아와 같은 경우 예를들어 영어 위키피디아 같은 경우 약 300만개의 문서가 있는데 이와 같이 문제자체가 스케일이 커지게 됨
하지만 다른건 똑같다고 볼 수 있음
input 상태도 비슷하고 input 도 마찬가지로 질문이고 output 도 마찬가지로 간결한 답변이 됨
Ex) Modern search engines : 연관문서 뿐만 아니라 질문의 답을 같이 제공
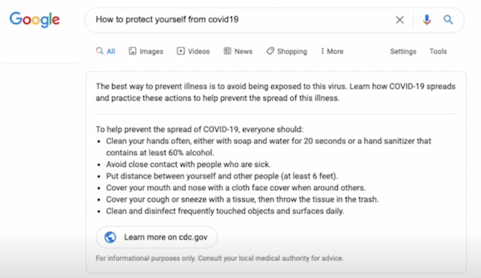
실제로 ODQA 를 이용해서 서비스를 하고 있는 회사들이 많은데 가장 대표적인 예는 구글이 될 것 같음
구글에서 검색을 하면 초기에는 구글에서 검색을 했을 때 문서들만 나왔지만 최신 Modern search engine 으로 넘어오게 되면서 구글이나 다른 회사도 포함해서 연관문서뿐만 아니라 질문에 대한 답도 같이 제공을 하게 되었음
ODQA 라는 문제는 사실 어제오늘 최근 몇년에 관심을 가졌던 문제는 아니고 꽤 예전부터 다뤘던 문제임
History of ODQA
Text retrieval conference (TREC) - QA Tracks (1999-2007): 연관문서만 반환하는 information retrieval (IR)에서 더 나아가서, short answer with support 형태가 목표
1) Question processing + 2) Passage retrieval + 3) Answer processing
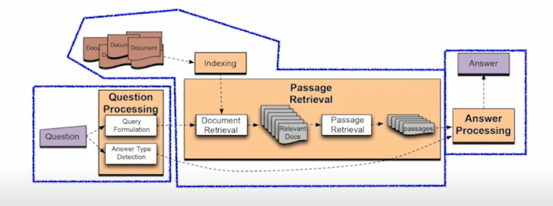
근본적으로는 최근의 approach 와 크게 다르지 않다고 볼 수 있음
1) Question processing
Query formulation : 질문으로부터 키워드를 선택 / Answer type selection (ex. LOCATION: coutnry)
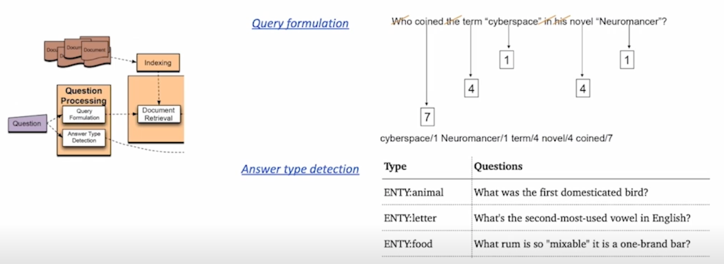
어떻게하면 우리가 질문을 잘 이해할 수 있을까에대한 고민인데 물론 당시에는 딥러닝이나 advanced 된 모델이 존재하지 않았기 때문에 지문으로부터 키워드를 선택해서 answer type 을 select 하는 방식이 거의 유일했음
예를들면 이 질문은 답변의 형태가 장소여야한다 또는 장소중에서도 나라여야한다 이런 것들을 분류를 미리 해준 것임
그 당시에는 이런 것들을 키워드나 룰베이스의 방법론으로 정의를 하도록 했음
2) Passage retrieval : 기존의 IR 방법을 활용해서 연관된 document 를 뽑고, passage 단위로 자른 후 선별 (Named entity / Passage 내 question 단어의 개수 등과 같은 hand-crafted features 활용)
이건 현재 방법론과 많이 다르지 않음
현재도 TF-IDF 나 BM25 같은 것을 많이 쓰고있고 이런 것들은 그 당시에도 존재했던 방법이기 때문에 꽤 오랫동안 가용되고 있는 방법론이라 볼 수 있음
3) Answer processing
Hand-crafted features 와 heuristic 을 활용한 classifier
주어진 question 과 선별된 passage 들 내에서 답을 선택
이 부분은 요즘과 좀 다름
최근에는 MRC 라 함은 단순하게 passage 를 선별하는 것 뿐만이 아니라 passage 내에 어떤 span 이 답변이 되는지를 맞추는 것으로 진화한 것을 보면 좀 많이 다르다 볼 수 있음
당시에는 span level 에서 답을 낼 수 있을 정도의 기술력이 없었기 때문에 이런 정도까지 가지 못했던 것이기도 하고 또한 기술이 발전하면서 passage 전체를 읽는 것보다 부분적으로 읽는 것들에 대한 customer 들의 needs 를 좀 더 파악했다고 볼 수 있음
이런 차별점이 존재하지만 말하고 싶었던 부분은 ODQA 라는 domain 은 생각보다 오래된 domain 임
IBM Watson (2011)
- The DeepQA Project
- Jeopardy! (TV quiz show) 우승

2011년도에는 많은 분들이 아시는 큰 뉴스가 있었음
DQA Project 라고 불렸던 IBM 에서 만들었던 Watson 이라는 AI 가 Jeopardy 라는 TV quiz show 에서 우승을 했었음
Jeopardy TV show 는 사람들이 참가하는 건 아니었고 따로 AI 랑 대결하는 TV show 를 만들었던 건데 원래 Jeopardy 라는 TV show 는 사람들끼리 competition 하는 것이긴 함
거기서 AI 엔진이 참여할 수 있도록 따로 기회를 만들었던 것임
당시에 Jeopardy 챔피언들과 붙어서 Watson 이라는 AI 가 우승했음
2011년도에 꽤 오랜시간이 지나서 이런 project 가 진행된 것은 맞지만 실제로 pipeline 을 들여다보면 방금봤었던 TrackQA 나 예전에 했던 방법론들과 많이 다르지 않음
당시에도 아직까지 딥러닝이 활용되기 전이었고 여러가지 feature 들과 이 feature 들 위에 쌓아올린 SVM 같은 초기 머신러닝 모델들을 활용해서 답변들을 추출할 수 있었다는 것을 알 수가 있음
그 후론 정말 많은 발전들이 있었음
2012~2013년 딥러닝의 발전으로 인해서 컴퓨터비전 쪽이 완전히 패러다임이 바뀌게되고 2014~2015년도를 통해서 NLP 쪽도 마찬가지로 완전한 패러다임의 쉬프트가 일어남
Recent ODQA Research
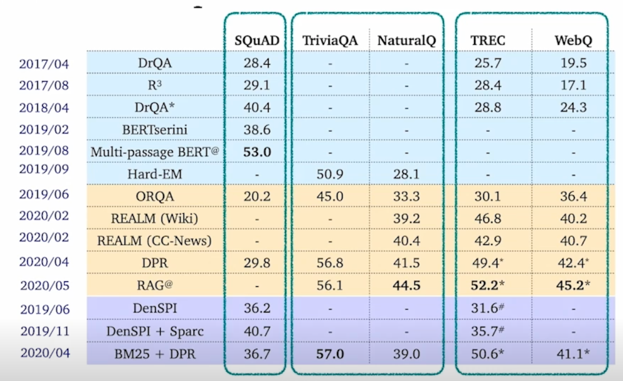
그에 힘입어서 2016~2017년 부터는 정말 많은 종류의 Question Answering 그리고 ODQA 모델들이 많이 나오기 시작했음
보시다시피 2017년을 기점으로 삼는다고 하면 3년 사이에 많은 모델들이 나왔고 성능향상도 아주 높은걸 알 수 있음
맨 왼쪽에 있는 SQuAD 같은 경우도 28.4점에서 시작해서 53점까지 올라가는 것을 볼 수 있음
맨 오른쪽에 있는 WebQ 라는 데이터셋도 17점에서 시작해서 나중에 45점까지 올라가는 걸 볼 수 있음
보시다시피 많은 발전이있었고 이런 발전들을 average 하는 것이 대회의 final project 의 가장 중요한 목표임
이런 여러가지 방법론이 있지만 일반적인 방법론을 알아보려함
2. Retriever-Reader Approach
가장 일반적인 방법론이라 불릴 수 있는 Retriever-Reader Approach 임
Retriever-Reader 접근 방식
- Retriever : 데이터베이스에서 관련있는 문서를 검색(search)함
- Reader : 검색된 문서에서 질문에 해당하는 답을 찾아냄

Reader 와 Retriever 를 연결해서 만들 수 있는 모델임
Retriever 를 통해서 문서를 찾고 찾은 문서를 통해서 MRC 엔진에 이용하여 최종 답안을 내는 것이 접근방식임
Retriever
- 입력
- 문서셋 (Document corpus)
- 질문 (query)
- 출력
- 관련성 높은 문서 (document)
Reader
- 입력
- Retrieved 된 문서 (document)
- 질문 (query)
- 출력
- 답변 (answer)
학습 단계
Retriever
- TF-IDF, BM25 $\rightarrow$ 학습 없음
- Dense $\rightarrow$ 학습 있음
Reader
- SQuAD 와 같은 MRC 데이터셋으로 학습
- 학습 데이터를 추가하기 위해서 Distant supervision 활용
Distant supervision
질문-답변만 있는 데이터셋 (CuratedTREC, WebQuestions, WikiMovies)에서 MRC 학습 데이터 만들기. Supporting document 가 필요함
- 위키피디아에서 Retriever 를 이용해 관련성 높은 문서를 검색
- 너무 짧거나 긴 문서, 질문의 고유명사를 포함하지 않는 등 부적합한 문서 제거
- answer 가 exact match 로 들어있지 않은 문서 제거
- 남은 문서 중에 질문과 (사용 단어 기준) 연관성이 가장 높은 단락을 supporting evidence 로 사용함
일반적으로 질문과 답은 있지만 그 답이 어느 지문에 있는지는 알지 못할때가 있음
답변이 어디에 존재하는지가 주어지지 않기 때문에 직접 찾아야함
그게 Distant supervision 의 의미임
각 데이터셋 별 distant supervision 을 적용한 예시

Inference
- Retriever 가 질문과 가장 관련성 높은 5개 문서 출력
- Reader 는 5개 문서를 읽고 답변 예측
- Reader 가 예측한 답변 중 가장 score 가 높은 것을 최종 답으로 사용함
3. Issues & Recent Approaches
Different granularities of text at indexing time
위키피디아에서 각 Passage 의 단위를 문서, 단락, 또는 문장으로 정의할지 정해야 함
- Article: 5.08 million
- Paragraph: 29.5 million
- Sentence: 75.9 million
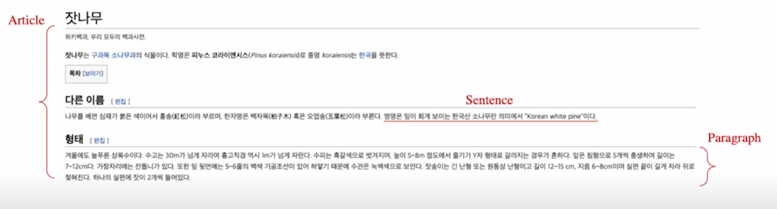
MRC 에 건내주는 단위를 항상 지문이나 passage 로 지칭했지만 passage 라는 단위가 위키피디아 상에서는 엄밀하게 정의가 되어있지 않음
여러가지 방법이 있을 수 있음 passage 단위를 크게보면 문서단위(Article)로 볼 수 있고 조금 더 작게 보면 paragraph 로 볼 수도 있고 더 작게보면 Sentence 로 볼 수 있는데 이렇게 했을 때 당연히 위키피디아 같은 경우도 개수가 많이 다름
Retriever 단계에서 몇개 (top-k) 의 문서를 넘길지 정해야 함
Granularity 에 따라 k 가 다를 수 밖에 없음
(e.g. article $\rightarrow$ k=5, paragraph $\rightarrow$ k=29, sentence $\rightarrow$ k=78)
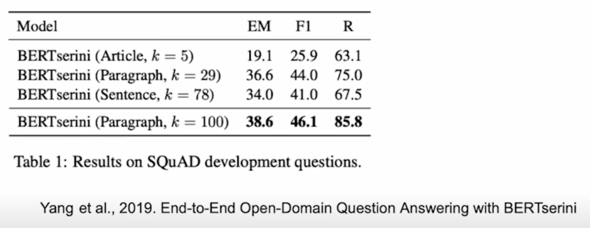
그리고 이런 granularity 에 따라서 retriever 단계에서 몇개의 문서 몇개의 passage 를 넘길지를 정해야 함
article 의 경우는 5개로 충분할 수 있지만 paragraph 는 조금 더 많이 필요함 예를들면 29개 sentence 같은 경우는 좀 더 많이 78개 이런 비율대로 갈 수 있음 꼭 비율대로 갈 필요는 없겠지만 일반적으로 이렇게 많이 함
성능의 차이가 있긴 하지만 R 기준으로는 어느정도 비슷한 것을 볼 수 있음
물론 k 를 늘리면 늘릴수록 성능이 올라가는 경우도 있고 항상 그렇지도 않음
그래서 이런 것들을 challenge 를 하실 때 잘 튜닝을 해야 할 문제일 수 있음
Single-passage training vs Multi-passage training
(Single-passage) : 현재 우리는 k 개의 passages 들을 reader 이 각각 확인하고 특정 answer span 에 대한 예측 점수를 나타냄. 그리고 이 중 가장 높은 점수를 가진 answer span 을 고르도록 함
$\rightarrow$ 이 경우 각 retrieved passages 들에 대한 직접적인 비교라고 볼 수 없음
$\rightarrow$ 따로 reader 모델이 보는 게 아니라 전체를 한번에 보면 어떨까?
(Multi-passage) : retrieved passages 전체를 하나의 passage 로 취급하고, reader 모델이 그 안에서 answer span 하나를 찾도록 함
Cons: 문서가 너무 길어지므로 GPU 에 더 많은 메모리를 할당해야 함 & 처리해야하는 연산량이 많아짐
Importance of each passage
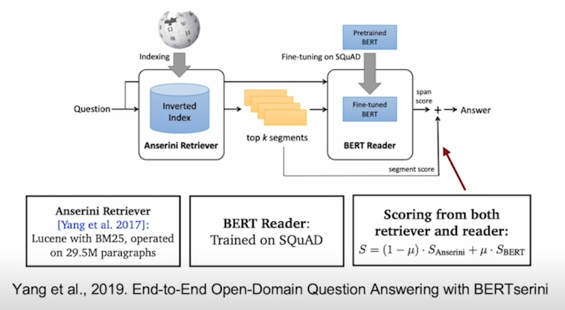
Retriever 모델에서 추출된 top-k passage 들의 retrieval score 를 reader 모델에 전달
댓글남기기