Day_45 [P-Stage level 2] KLUE Relation Extraction 개인 회고
작성일
[P-Stage level 2] KLUE Relation Extraction 개인 회고
- 2021.10.08 (금)
네이버 부스트캠프 P-Stage level 2 KLUE Relation Extraction 대회 마무리 회고 글입니다.
1. 시도했던 방법 들
1.1. Hierarchical approach
EDA 를 하면서 가장 처음에 발견한 것은 class 의 imbalance 였다.
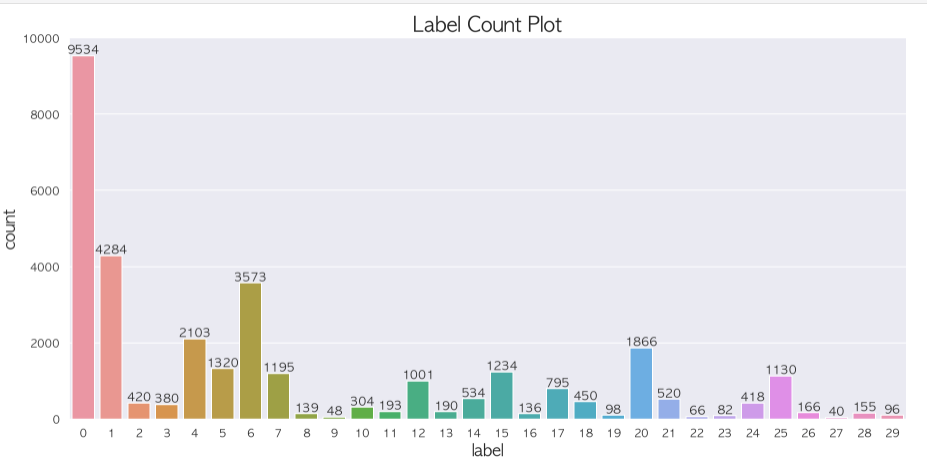
이런 imbalance 를 잡아 볼 방법으로 저번 이미지대회에서 마지막에 사용했었던 mask, age, gender 를 모두 따로따로 구분해서 예측하는 모델을 만들었던 것처럼 계층적으로 분류하는 모델을 만들어보자 생각했다.
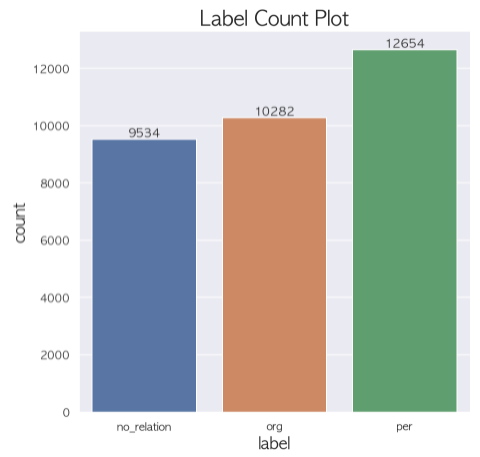
label 에서 no_relation vs org vs per 을 가지는 3개의 큰 분류가 보였다.
먼저 이렇게 분류하고 나면 org 로 분류된 애들 중에 org 의 세세한 분류를 할 수 있을거라고 생각했고 per 도 마찬가지라고 생각했다.
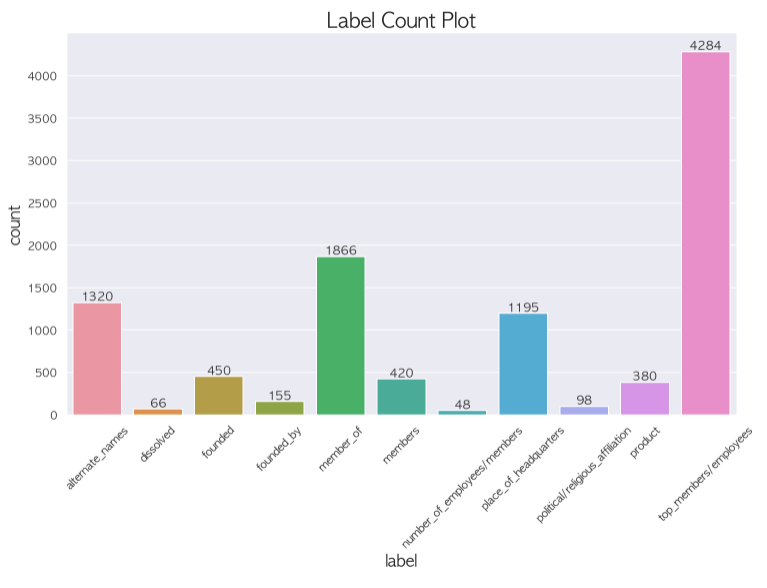
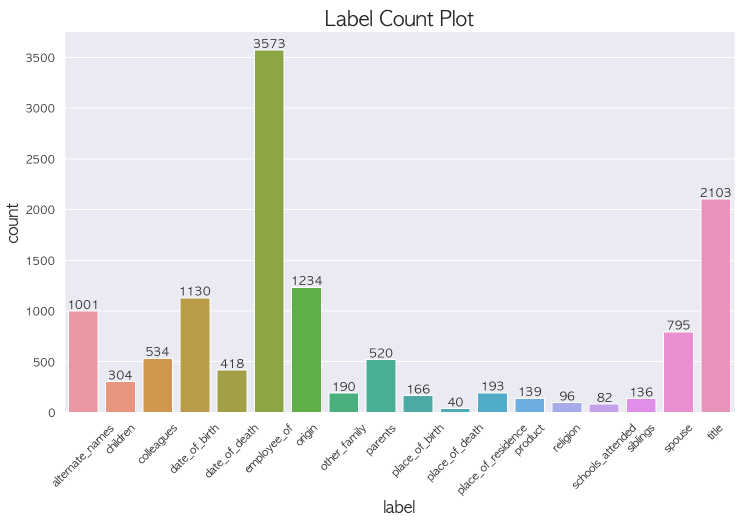
가설 : no_relation vs org vs per 의 분류는 imbalance 가 많이 줄어들었기 때문에 성능이 괜찮을 것이고 org 로 분류된 애들 중에서
또 분류를 진행하고 per 로 분류된 애들 중에서 분류를 진행해서 최종 예측을 만들면 성능이 오를것이다.
결과 : 베이스라인으로 주어지는 모델과 같은 조건하에 비교했을 때, 성능이 떨어졌음 LB 기준으로 58점 정도나옴
이 시도는 내가 생각했을때는 좋은 접근이라고 생각했지만 auprc 같은 경우는 어떻게 해야할지 감도 못잡았었고 f1-score 조차도 낮게 나와서
폐기처리했음
그런데 스페셜 피어세션때 들어보니 다른 팀들은 no_relation vs org vs per 로 나누는 것이 아니라 no_relation vs relation 을 먼저 분류하고 나머지 29개 class 를 분류했다고 한다. 그리고 성적도 더 올랐다고한다.
저렇게도 분류할 수 있다는 생각을 해보지 못한점이 좀 아쉽다.
1.2. typed entity marker (punct)
An Improved Baseline for Sentence-level Relation Extraction 에서 소개된 방법으로 RE task 에서 RoBERTa-large 모델에서
큰 성능향상을 가져온 방법이다.

가설 : 이 논문을 구현한 코드에서는 @, # 이 두개의 output vector 만 사용했지만 RBERT 의 방법도 접목해서 @ 사이의 모든
output vector 와 # 사이의 모든 output vector 를 사용하면 성능이 오를 것이다.
결과 : baseline 으로 주어진 모델과 같은 조건하에 비교했을 때, 성능이 확실히 올라감 LB 기준으로 72점 까지 상승했다.
논문을 토대로 구현하기 위해 2일정도 고민했고 구현을 성공했을 때 굉장한 뿌듯함을 느꼈고 성능이 올라서 더욱 만족스러웠다.
물론… 다른 분들의 점수가 훨씬 높아서 이 다음엔 어떻게해야하지? 하고 많은 고민을 했지만 그래도 나름의 성과였다고 생각한다.
1.3. Data Augmentation
오피스아워 시간에 듣게된 AEDA 라는 방법이 단순하게 적용하기 너무 쉬워 보여서 바로 적용하려는 시도를 거쳤다.
논문 상에서는 AEDA 를 사용했을 때 성능이 눈에띄게 상승했었기 때문에 바로 적용하려고 했다.
가설 : 주어진 문장에 AEDA 를 통해서 문장수를 늘리고 subject word 와 object word 는 건드리지 않았고 label 도 건드리지 않은 상태로
데이터만 늘려주었을 때 RoBERTa 는 데이터가 많아질수록 성능이 좋아진다고 했으니 성능이 오를것이다.
결과 : valid score 가 올라서 LB 점수의 상승을 기대했지만 valid data 에 비슷한 문장이 추가되서 valid score 가 오른 것이라는 결론이
나왔고 실제 LB 상에서는 점수가 오히려 더 떨어지는 결과를 보게 되었다.
나의 실험은 전제가 잘 못 되어있었지만 같은 조의 다른 캠퍼는 valid 에는 train data 에 들어있는 문장으로 augmentation 한 문장이 들어있지 않도록 구현했고 실험했지만 LB 상에서의 점수가 오히려 떨어졌다는 결론을 듣고서는 시도하지 않게되었다.
그러나 스페셜 피어세션때 듣기로는 augmentation 을 해서 성능이 올라간 조도 있었기에 어떻게 하느냐에 따라서 성능이 올라갈수도 있으므로 내가 또는 우리조의 캠퍼분이 좀 더 파고들었어야 하는거 아닌가 싶기도 하다.
1.4. loss 함수를 label smoothing 으로 변경
가설 : 모델이 데이터의 과반수를 차지하는 라벨에 overconfident 해지는 현상이 생길 것을 막아주고 성능이 오를것이다.
결과 : 기본 baseline 에서 label smoothing 으로의 변경이 이뤄지진 않았기 때문에 성능향상이 얼마나 일어났는지는 정확히 실험하지 못했다.
아쉬운 부분이라고 생각하고있고 그렇지만 label smoothing 을 적용했을 때 더 좋은 성능이 나오는 것을 확인할 수 있었다.
1.5 Cross Validation
가설 : valid set 을 만들어서 사용해서 모델의 성능을 평가해야 하는데 그만큼 학습데이터의 부족으로 연결되므로 K-fold 를 사용해서 모든 데이터를
사용해서 평균값을 구할 수 있으면 성능이 향상할 것이다
결과 : 단일 모델을 학습시켰을 때보다 LB 상으로 거의 4점가까이 차이가 나는 것을 볼 수 있었다.
이 방법은 StratifiedKFold 를 적용해서 label 의 imbalance 를 train 과 valid 에서 비율을 맞춰줬고 그로 인해 좀 더 LB 와 가까운 점수를 얻지 않았나 싶다.
물론 LB 와는 큰 점수차이(12점 정도)가 났고 다른 팀들도 마찬가지였다고 한다.
2. 학습과정에서의 교훈
2.1. 실험 관리 정리
transformers 의 Trainer 클래스에서 wandb 를 함께 접목시킬 수 있어서 간단하게 적용할 수 있었다.
wandb 를 통해서 나온 결과들을 눈으로 보면서 실험해보는 결과들에 대해서 쉽게 비교할 수 있었다.
저번 level1 P-stage 보다는 실험관리를 잘 했다고 생각이 들지만 대회 종료일이 다가올수록 조급해져서 실험관리가 엉망이 된 것 같다.
좀 더 잘 관리할 수 있도록 wandb 뿐만이 아니라 시도해보는 과정마다의 기록이 따로 필요한 것 같다.
2.2. 데이터의 중요성!
이번 대회에서는 데이터에 대해서 크게 건드리지 못했다. 그런데 1등 조의 솔루션을 들어보니 데이터에 대해서 굉장히 많은 작업을 거치신 것 같다.
labeling 이 잘못된 데이터라던가 subject entity 의 type, object entity 의 type 이 잘 못 적혀있다던가 하는 오류가 있는데 그런 부분까지 하나하나 발견해서 고치시는 부분이 이런 세세한 작업 하나하나가 큰 성능차이를 일으킨다고 생각했다.
다시 한번 느끼지만 데이터의 중요성을 잊지 말아야겠다.
2.3. 아쉬운 공유문화 참여도
이번에도 대회기간에는 공유를 한번도 하지 못한점이 너무 아쉽습니다.
같은 팀원들에게는 나의 실험을 공유하고 방법들에 대해서 잘 나누지만 대회 게시판에 좋은 정보를 남기는 그런 과정을 경험하지 못해봐서 아쉽습니다.
아직까진 어떤 것을 올려야 좋을지 모르겠는 마음과 이런걸 올려도 되나 싶은 마음과 대회에 집중하기 버거운 그런게 있는 것 같습니다.
다음 대회에서는 꼭 하나라도 남기도록 해보겠습니다.
3. 마주한 한계와 도전 숙제
3.1. 아쉬운 점
2등팀이 대회 마지막 3분전까지만 해도 계속 1등이었는데 2등조의 결과물에서 마지막단 layer 의 차이와 ensemble 의 차이만 빼면 방법에 대해서는 그렇게 큰 차이가 있었다고 생각되지 않는데 왜 나는 시도해보지 않았을까라는 아쉬움이 큽니다.
스페셜 피어세션때 다른 조들의 경험을 들어보니 우리조에서는 생각하지도 못했던 방향으로의 접근들이 있었어서 더 다양한 아이디어를 생각하지 못한점이 너무 아쉽습니다.
대회를 진행하면서 이방법 좋더라 하면 이방법 을 사용해보고 오 성능올랐네? 좋다 하면서 진행하는 이런 상황을 없애겠다고 다짐했으면서도
대회 마지막 시간이 다가올수록 같은 실수를 반복하고 내가 어떤 실험을 했었는지에 대해서도 정확하게 파악하지 못하고 score 에만 집중하는 모습이
너무 아쉽습니다.
3.2. 한계/교훈을 바탕으로 다음 스테이지에서 새롭게 시도해볼 것
이번 대회를 통해서 또 한번 느끼지만 문제정의 $\rightarrow$ 가설 설정 $\rightarrow$ 실험 $\rightarrow$ 결과 의 흐름을
놓지지 않아야겠다.
다음 대회에서는 SOTA 모델을 찾아보고 그 논문을 구현해보는 과정을 거쳐야겠다고 생각했다. 구현하는 과정속에서 수정했으면 하는 부분을 찾아보고 정확하게 비교를 할 수 있도록 관리하면서 실험해야겠다.
댓글남기기