Day_43 [오피스아워] Chatbot with NLP
작성일
[오피스아워] Chatbot with NLP - 이녕우
1. NLP, NLU, 그리고 NLG
1.1.1 NLP, Natural Language Processing
- NLP(자연어 처리)는 컴퓨터가 인간의 자연어를
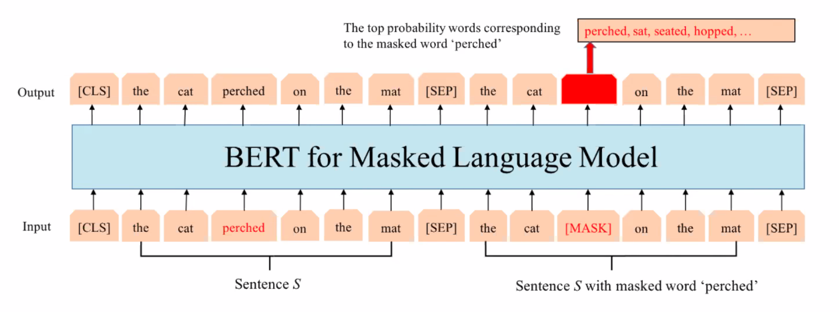
1.1.2 NLU, Natural Language Understanding
1.1.3 NLG, Natural Language Generation
1.1.4 NLP = NLU + NLG + … = Chatbot
2. What’s Chatbot?

3. Types of Chatbots

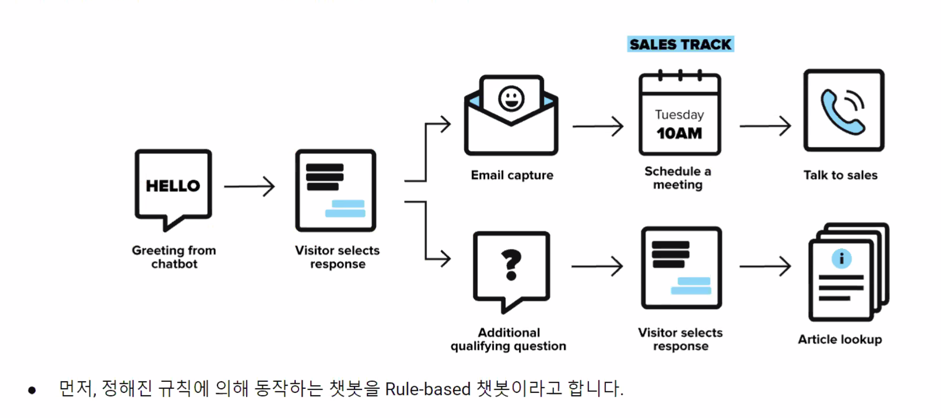
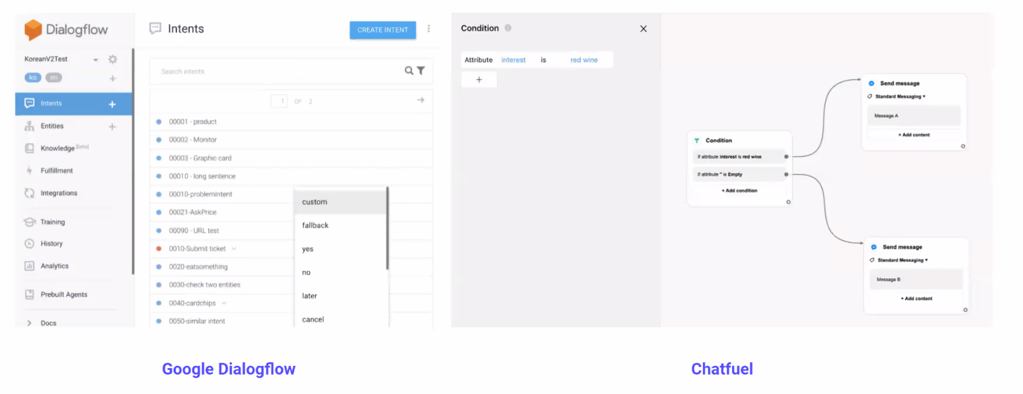
3.1.2 Rule-based chatbots: The Old School
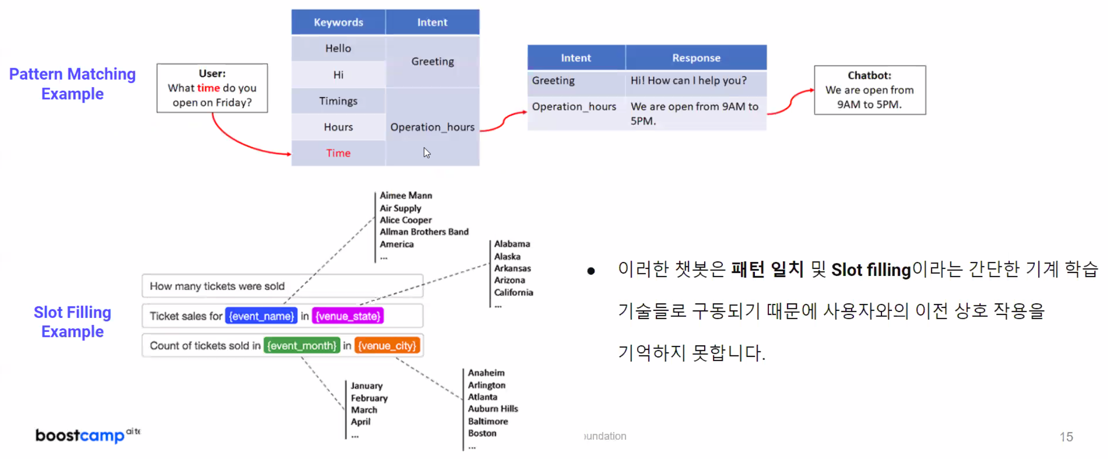
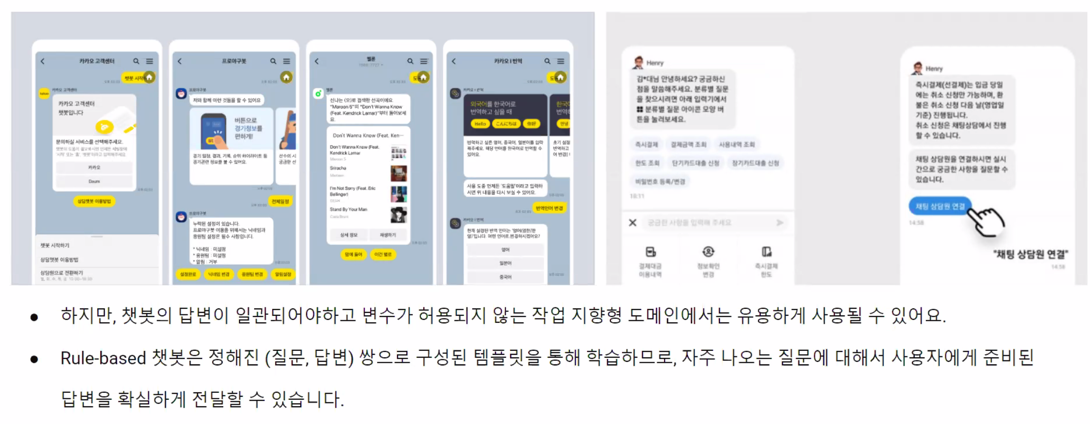


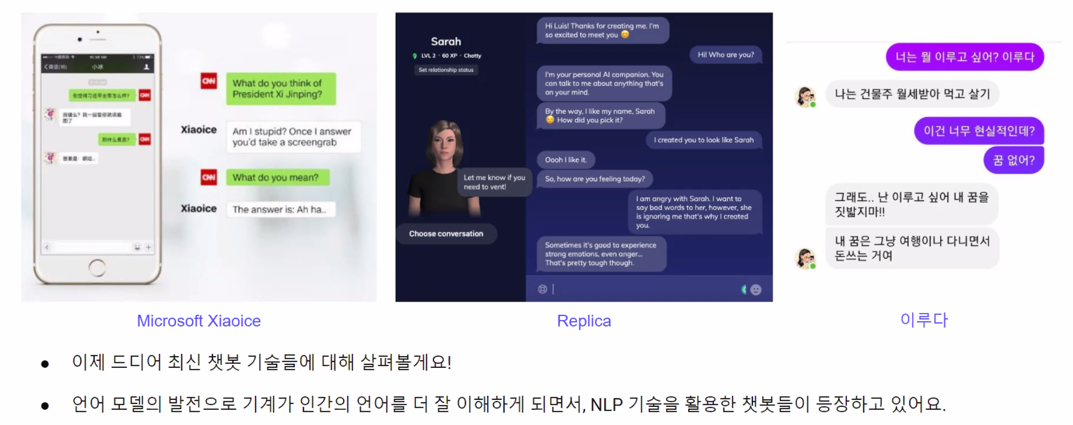
3.1.3 NLP powered chatbots: The Next Generation

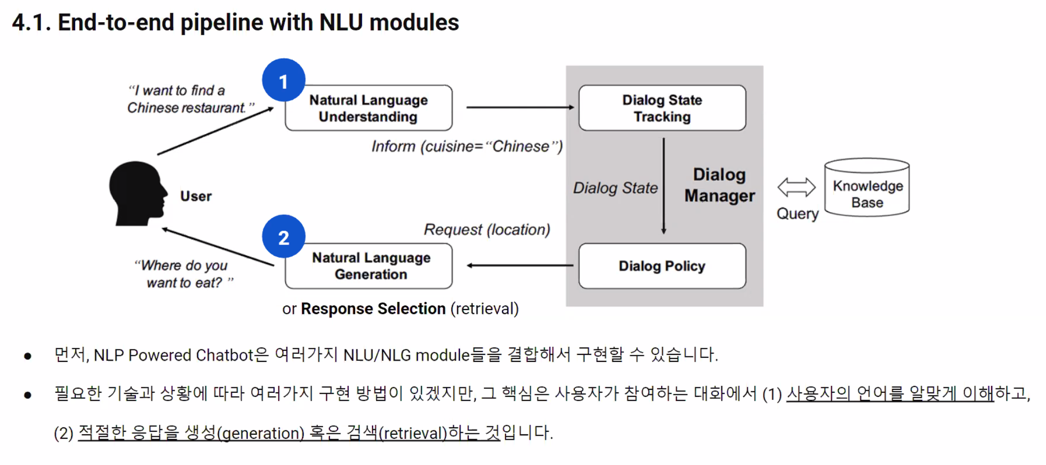
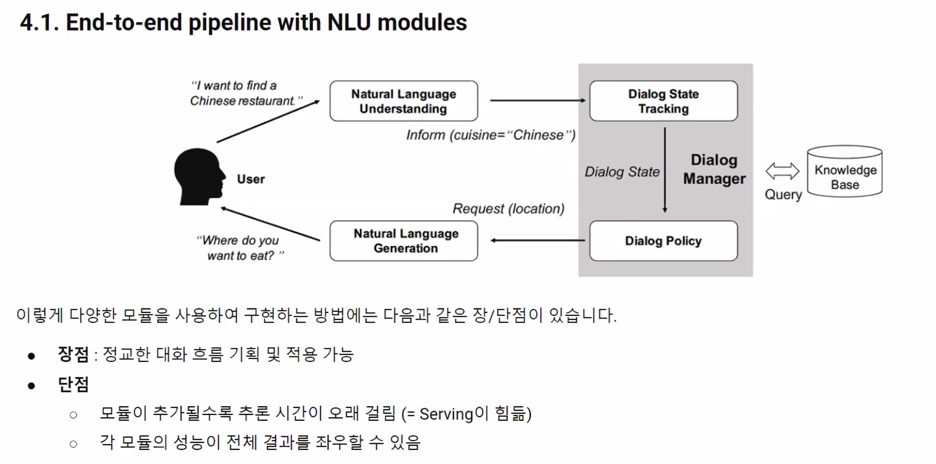
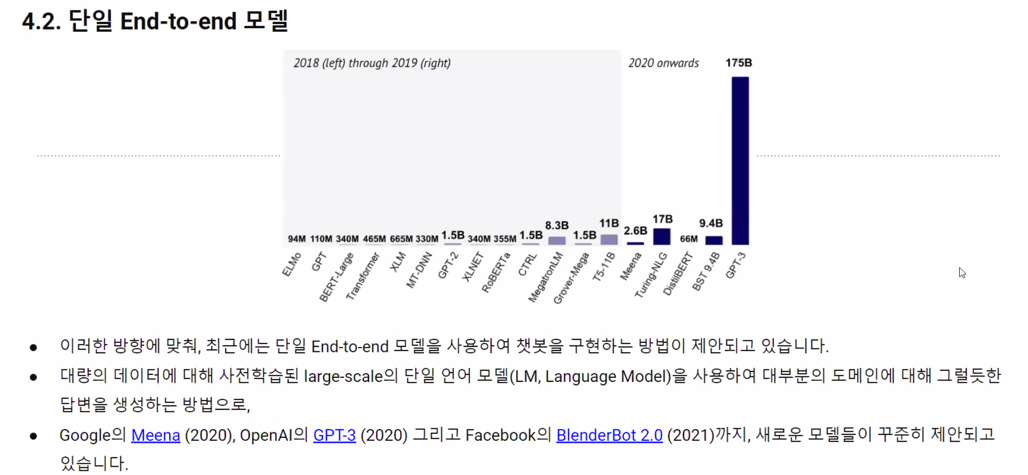
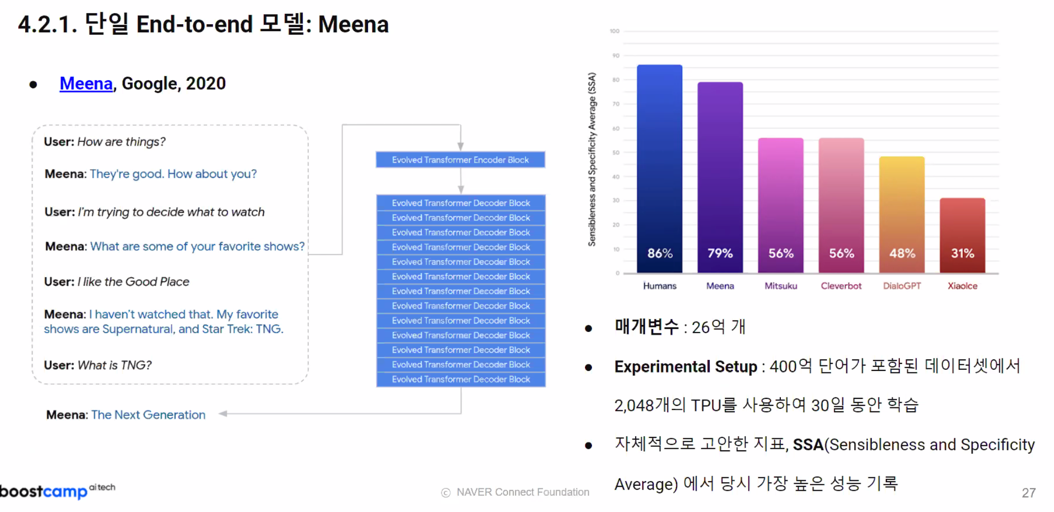
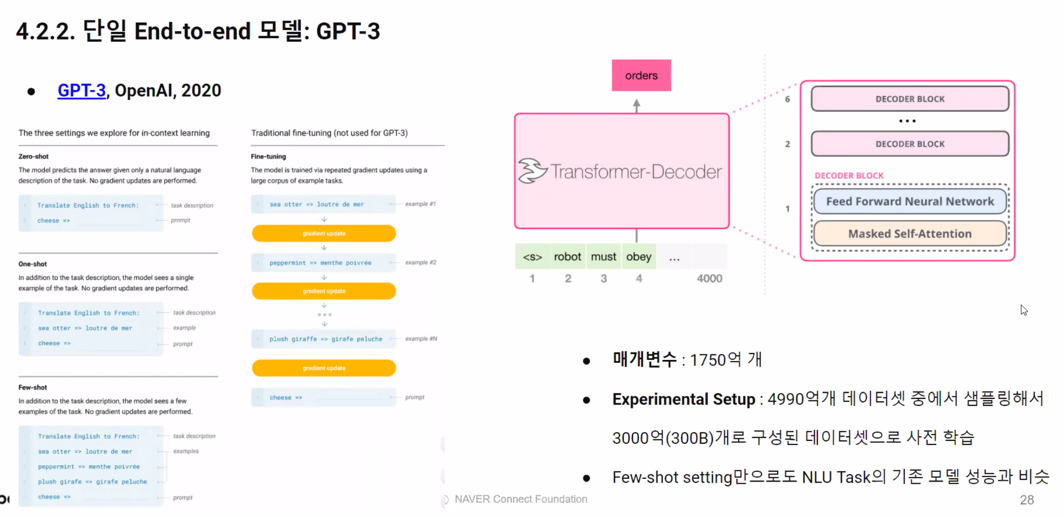
4. NLP Powered Chatbot Implementation
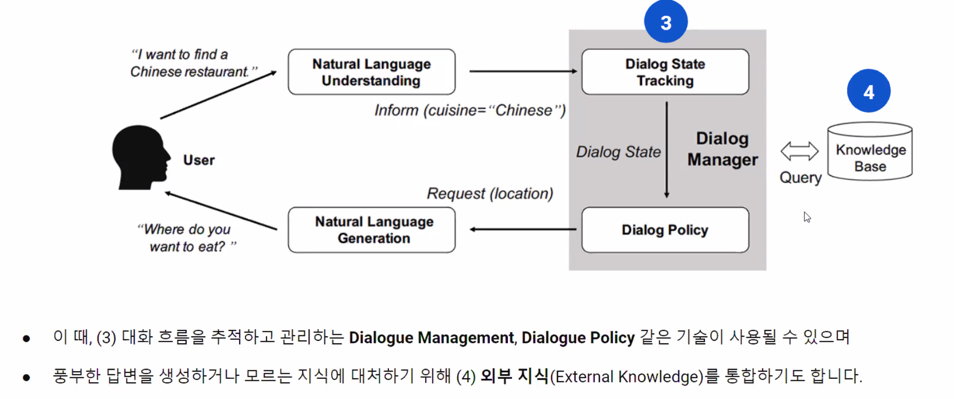






5. Further Works




사전 질문

아까 GPT 같은 LM경우는 진정한 의미의 언어 학습이 아니라는 말이 많은데 진정한 의미로써의 언어 학습을 하는 연구는 어떤게 있을까요?
단어 단위의 학습을 하고있기는 하지만 문장단위로 하고있다고 할 수 있음
언어를 배울 때 보면 다양한 상황들 언어들을 써보면서 이 상황엔 이게 안되는걸 배우면서 (통계적으로) 아는걸 잘 조합해서 답변 생성에 반영할 수 있지만 기본은 통계적으로 배우는데 GPT 같은 학습방법도 크게 다르진 않다고 봄
외부지식 통합을 하든 다른 모듈들을 사용해서 답변 생성에 통합하는 방법이 있을
어느정도의 수준이 되어야 할까요?
문제를 좀 스스로 파악하고 푸는 방법들을 배웠던 것과 결합해서 있는 코드를 내 생각에 맞게 변환해서 반영한다는 정도가 되면 충분히 잘하고 있다고 생각
자연어만 보자면 klue 데이터셋의 task 보시고 각 task별로 어떻게 구현 가능할지 감이 오시면 충분히 학습하셨다 생각합니다~ 현실 세계의 문제들은 수 많은 task들의 combination으로 해결하게 되거든요
현업에서 모델을 만드는 부분은 일부에 해당하고 이외에도 필요한 작업이 많다고 들었는데, 모델을 만드는 작업은 보통 요구되는 기간이 어느정도나 주어지는 편인가요 ??
연구랑 다르게 지금 있는 모델을 잘 쓰는게 목적일 수 있어서 모델 구현자체의 시간은 길어봤자 2주정도 잡는것 같고 모델 만드는 것은 일부에 해당하고 이후에 데이터 전처리 이루다 사건처럼 챗봇들이 만들어내는 답변들의 편향적인 유해한 것들을 필터링하는 그런 사용자의 경험을 끌어올리기 위한곳에 많은 시간을 쏟게 되는 것 같음
모델 자체를 만드는 시간은 굉장히 짧고 실제로 모델 코딩하고 학습하는건 오래 안걸림
자료조사하고 문제정의를 명확하게하고 기존 모델들은 어떤 한계점이 있는지 분석하고 한계점을 분석하는 아이디어나 회의를 오래함
문제 정의하고 해결방법 도출하는게 한달가까이 하는게 많았음
실제로는 기업에서 패스트 프로토타이핑 하는 작업을 많이 함
베이스 라인 모델로 한달 이내에 껍데기를 만들어놓고 테스트하면서 문제점을 파악하고 2주 단위로 고치고 테스트해서 문제점 찾고 (반복)
짧은 단위로 이루어지게 됨
회의를 하면서 동시에 기존에 갖고있던 baseline이 있다면 그것을 백그라운드에서 돌리면서 그것을 기준으로 잡진않나요?
기본 모델들도 문제들이 많음
전혀 아무것도 없이 연구를 시작하기에는 맨땅에 해딩이라 베이스라인을 찾은 다음에 문제점을 찾아가면서 해결함
huggingface tutorial 을 보면 전부 영어라서 어떤 방식으로 접근하면 좀 더 쉽게 공부할 수 있을까요?
처음 논문을 읽는데 1주일이 걸림 한참이 걸렸고 이 논문으로 발표를 하는데 한달이 걸렸음 교수님이 계속 빠꾸하셔서
영어를 하려면 훈련을 해야함
논문 하나를 읽고 나서 다음 논문을 읽을 때는 점점 줄어듦
나중 되면 논문 하나 읽는데 한시간 이내에 다 본다던가 능력이 누적이 됨
반드시 노력을 해야할 것 같음
영어를 피할 수 없고 모든 자료는 영어로 되어있고 영어로 읽어야 오해가 없음
같은 페이지를 영어버전으로 다시 읽게 됨
한국어로 나온 자료랑 영어로 나온 자료가 의미가 다르고 사용법도 정확하게 이해가 안갈때가 많음
영어를 논문 하나를 일주일동안 읽겠다라는 생각으로 노력해야 한다고 생각하고 봐야 함
볼수록 느는 것 같고 논문 하나 볼 때 오래걸렸는데 영어 실력과 별개로 보는 노하우가 쌓여서 더 잘 볼 수 있게 됨
하는 만큼 느는 것 같다
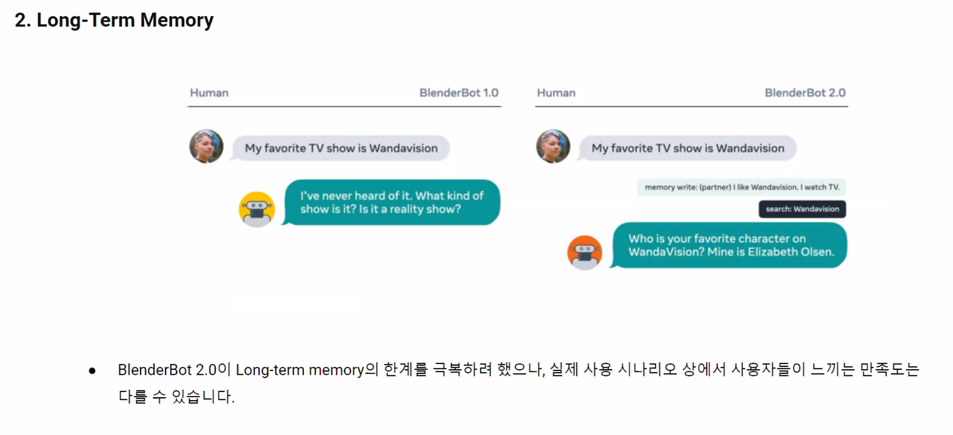
룰베이스 기반 챗봇이 아닌 챗봇에 특정지식을 넣어줄수 있는 방법이 있나요? 챗봇이 pretrain할때 배우는거 이외에 하는 방법이 있는지 궁금합니다. 아까 챗봇이 인간의 상식을 못알아 듯던데 특정 지식을 주입하는게 가능한가 싶습니다.
gpt-3 시연에서 알려줌
MRC 도 본문에 대한 지식을 넣었을 때 지식을 찾아내는 것이므로 넣어주는 형태는 다양하게 해줄 수 있음
KLUE 라인으로 진행을 하고 있는데 점점 알아야 하는 내용도 방대해지고 모든 걸 소화하지 못한다면 이것만은 알고갔으면 좋겠다? 하는 부분은?
허깅페이스 사용법만 알아도 됨
딥러닝이라고 하는 네트워크가 함수의 개념이고 input output 을 맞춰주고 학습하면 된다 gradient descent, learning_rate 이런 개념을 완전히 품고 가야 될 것 같음
이것만 품고가면 어느 task 를 맞닥뜨리더라도 할 수 있음
멘토님,마스터님 개인 github주소가 궁금합니다.
왜 궁금해하시는 거죠?
김성현 마스터님 저는 개인 플젝보다는 아카이브용으로 사용하고있어요~
이정우 멘토님
이녕우 멘토님
이번 프로젝트를 통해서 협업이라는 것을 조금이나마 경험해봤던 것 같습니다. 이 과정에서 팀원들과 의견의 다를 수도 있다고 생각을 합니다. 모델을 한 번 돌리게 되면 시간이 오래 걸리고, 주어진 제한 시간이 있어 모든 의견을 실험해 볼 수는 없었던 것 같습니다. 이 때 어떠한 방법으로 해결을 하셨는지에 대해 궁금합니다 !
리소스의 부족으로 나타나는 현상이고 회사가면 이런일은 없음
당연히 갈등은 생길 수 밖에 없는데 해결방법은 설득이 가장 좋다고 생각함
설득 못 시킨다면 본인의 주장에 논리가 부족하다고 생각하고 본인의 논리가 부족하다면 받아들이는 연습도 해야 함
협업할 때 동일한 목적을 향해 나아가는거지 싸우면 안됨
당연히 뻔한 얘기지만 시도하려는 것중에 우선순위를 추려야하는데 당연히 토의가 있을 것이고 자기의 생각이 맞다고 생각할 수밖에 없음
그런 과정중에 어떻게 남들에게 더 잘 설득하느냐? 더 좋은 의견이 들어왔을 때 잘 받아들이는게 중요하지 않을까 싶음
자기의 의견이 맞다고 해도 설득을 못시키는 분들이 있음 그래서 근거를 잘 생각하는 걸 연습하면 좋을 듯
기억에 남는 재밌는 프로젝트 있으신가요!?
김성현 멘토님

인공지능 가람이라고 만든게 있는데 실제로 실험해보니 이런 결과가 나왔음 챗봇 분야의 한계점이나 편향 되는거 나왔는데 편향이 되지 않은 데이터만 사용하면 해결이되느냐? 그것이 해결방법이 아니다
챗봇에서 진짜로 넘어야 할 허들이 이런거라고 생각함
음성은 TTS 음성이고 마이크를 통해 질문하면 TTS 합성해서 나가는건데 영상은 규칙을 만들어서 만들어진 영상임
이정우 멘토님
강화학습을 주로 하는데 벌처 컨트롤하는 task 가 있었는데 오로지 강화학습으로만! 최종적으로 본인만 성공해서 재밌었음
그게 학습된 이후에 승률이 100% 가 나와서 가능성도 봤음
페이스북 RL Korea 에서 운영진으로 활동하고 있는데 강화학습에 관심있고 상금도 타보고 싶다면
https://github.com/reinforcement-learning-kr/2021_RLKR_Drone_Delivery_Challenge_with_Unity
참여해보시는것을 추천합니다.
무슬림 데이터만 모아서 챗봇을 만들면 챗봇이 이슬람으로 개종되겠군요…?
페르소나 챗의 개념으로 가서 이슬람의 사람들만 모아서 학습하면 그렇게 될 수 있을 듯
이녕우 멘토님
AI 를 잘 모를 때 했던 프로젝트인데 룰베이스 챗봇을 만들어서 사람들로 하여금 자신의 감정을 대화하면서 기록할 수 있게 어플리케이션을 저장할 수 있게 만들었는데 사람들이 그래도 얘기를 잘 하더라
사람들의 만족도나 반응이 좋아서 가능성 있을 수 있겠다라고 느꼈던 프로젝트였다고 생각했음
현업에서 (서비스 관점에서) 소스 구현을 하실 때, 허깅페이스, TF, PyTorch 등을 모두 골고루 조합해서 하시는지 하나를 정해서 하시는지 궁금합니다!
일단은 다 하고 섞어서 하는 이유는 두가지가 있는데 오픈소스를 가져다 쓸 때는 뭐로 구현되어 있느냐에 따라서 쓰게됨
TPU 를 쓰느냐 GPU 를 쓰느냐에 따라 달라질 수 있음
TPU 를 쓴다고 하면 Tensorflow 를 쓰는게 정신건강에 좋음
PyTorch 를 주로 쓰는것 같음
현업에서도 Keras 나 Tensorflow 비율보다는 PyTorch 비율이 80% 정도 되지 않나 싶음
자연어 할 때는 허깅페이스가 기본중의 기본임
골고루 조합하고 하나의 프로덕트를 만들 때 그 안에서도 허깅페이스도 있고 PyTorch 도 있고 Tensorflow 도 있을 수 있음
댓글남기기