Day_45 [마스터클래스] 김성현 마스터
작성일
[마스터클래스] 김성현 마스터
리더보드 1등 솔루션
Kiyoung2 조
어떤 실험에 어떤 데이터를 썼는지를 관리
데이터 노이즈가 많아서 보정해주는 과정을 거쳤음
- word 의 type 이 잘 못되어있는 걸 수정하는 작업
- [MASK] 토큰을 활용하는 방안도 고민
xlm-roberta 모델을 사용
ENtity Embedding + TAPT 적용
TACREAD SOTA 인 RECENT 적용
다양한 head 를 둬서 per vs per 끼리 예측하고 per vs loc 끼리 예측하고 이걸 통해서 성능향상을 거둠
협업 + 소통 + 버전관리
리더보드 2등 솔루션
쿼터백 조
Input Format 에 대해 고민이 많았음
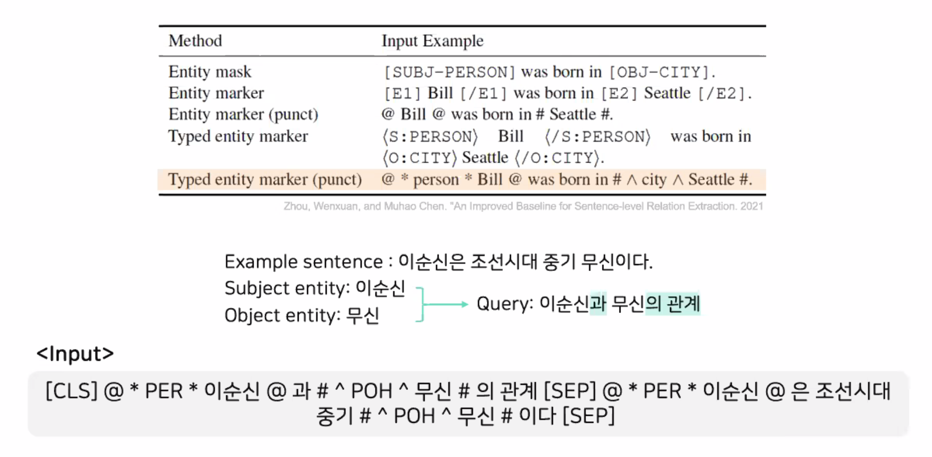
augmentation 적용
- Random Masking
- AEDA
- Entity Swap
- Random Delete
성능이 오히려 떨어지는 결과
BiLSTM 을 2층 추가함
hgtk.josa() 라이브러리를 사용하면 josa 를 자동으로 붙일 수 있음
자원해서 발표하는 조
Happyface 조
RBERT + Improved Baseline
entity type 을 영어가 아닌 한글로 넣는게 더 효과적이지 않나 싶어 진행함
마스터 피드백 & 리뷰
RE 데이터 자체가 텍스트를 먼저 모으고 개체명인식기를 돌렸음
나온 개체명들을 entity 후보로 두고 그걸 combination 해서 label 을 구축했음
RE 데이터자체가 어떻게 만들어졌는지를 추측할 정도로 데이터분석해서 대단했던것 같음
협업과 회의와 관련한 발표를 봤을 때 이런 협업과 회의에 대한 규칙을 정해놓고 merge 규칙도 정하고 그런 내용들을 정해서 맞추려고 하고 일일 목표를 scrum 이라고 해서 매일 아침마다 회의를 진행
진짜 프로같은 접근방식이라 인상깊었음
huggingface datasets 을 쓴것이 인상깊었음
당연히 벽이 있었을텐데 허들을 넘겨서 사용하는게 인상깊음
커리큘럼 러닝을 했을 때 성능향상이 큼
그때도 적용할 수 있으면 하는게 좋음
정말 단순하게 모델을 3개로 나눴음 짧은문장(한줄짜리), 토큰의 절반정도 되는 모델, 긴거 이렇게 나눠도 좋은 성능을 냈어서 좋은 아이디어임
punctuation 을 활용해서 학습을했는데 이게 인상깊었음
큰 사이즈를 학습하다보니 special token 이 학습이 잘 안되는 경향이 있음
새로운게 끼어들면 학습이 잘 안됨
special token 이 학습이 잘 안됨
special token 을 자연어 형태로 바꿔서 적용하고 있는데 punctuation 을 활용할 생각은 못했는데 연구하는거에 추가해보고 싶은 생각이 들었음
짧은 기간에도 많은 내용을 알차게 시도하고 실험도 많이하셔서 굉장히 좋았던 것 같음
GPT-3 Copilot 시연
copilot
API 콜만 가능
깃헙에 올라가있는 모든 코드들을 GPT 형태로 학습했음
코딩을 할 때 자동으로 추천해줌
codex
순수하게 자연어를 넣어서 code 가 만들어짐
codex 와 copilot 의 한계점은 보안 이슈가 생길때가 있음
아마존 database 에 접근할 수 있는 코드가 copilot 을 통해 획득이 되었다고 함
그래서 외국계기업에서는 작업할 때 copilot 을 활성화하지 말라고 공문이 내려왔다고 함
GPT-3 만 가지고 제품을 만들지 않고 앞뒤에 모듈을 잔뜩 붙여서 원하는 답이 나오도록 학습
copilot 과 codex 는 무료이지만 api 를 신청해야 사용할 수 있음
사전질문

절대로 혼자는 불가능하고 혼자 공부하는건 어렵고 함께 열정이 가득한 사람을 만나야함
같이 하는걸 추천
계속 강조를 했지만 지식은 공유할수록 확장이되고 누군가에게 설명할 때 더 많이 배움
그래서 누군가와 같이 하는게 굉장히 좋다고 생각함
딥러닝 커뮤니티라던가 같이 교육을 수강하시는분들 아니면 모두의연구소 같은 공부하는 스터디를 활용하면
좋을듯
공부와 일하는것을 분리하면 안됨
회사에서 일을 할 때도 공부는 집에가서 해야지 하는 생각은 말이안되고 어떤 목적을 뒀으면 목적을 이루기위해서
공부도 병행하면서 가는 것이니까 분리되면 안됨
여기서 일은 회사업무뿐만이 아니고 리더보드에서의 1등을 목적으로 뒀으면 목적을 달성하기 위해서 다양한 노력을
할건데 논문을 읽거나 모델링을 하거나 이런 것들이 분리될 수 없음
어떤 목적을 위해서 공부를 해야한다고 생각함
딥러닝을 공부할 때 처음에 블로그에 정리했음 그러면 블로그에 정리를 더 하기 위해 공부를 더 열심히 했음
학습정리 열심히 하는게 도움이 많이 될 듯

2001년도에 AI 라는 영화가 개봉이 됐는데 그 영화에 어린아이 로봇이 있는데 그 시대가 로봇을 혐오하는 시기였음
이 어린아이가 말을 인간같이 너무 잘해서 다른 사람들이 이 로봇을 감싸는 연출이 나옴
이때 인간과 로봇이랑 어떤 차이가 있기 때문에 차이를 느끼고 어떤 차이가 없어서 동질감을 느끼는지 그런 부분에
관심이 생겨서 어떻게 interaction 이 이루어져야지 사람과 인공지능의 차이를 줄일 수 있는지가 궁금했음
그래서 뇌공학과에 진학해서 배웠고 그 지식을 인공지능에 적용해보자라는 마음으로 시작했음
목표는 인간과 인공지능과 구분되지 않는 챗봇을 만드려고 노력하고 있음

논문을 보면 자세히 나와있음
하이퍼클로바가 GPT-3 임 크게 다르지 않고 구조적으로는 다른게 없고 하이퍼클로바가 좀 더 작음
한국어 데이터를 좀 더 많이 사용한거고 토크나이저에 대한 연구도 진행했고 차이점이고 한가지 더 연구적으로
추가한것은 모델 사이즈별로 성능을 측정했음
논문에 보면 fewshot learning 할 때도 70개정도 예제를 넣었음
성능적으로 하이퍼클로바가 GPT-3 에 대해서 더 나은지 써보지 못해서 알 수 없음
논문을 자세히 보면 알 수 있음

문제가 굉장히 많을 것 같은데 가장 영향을 준것 같은것은 데이터 증강에서 사용한 labeling 규칙과 KLUE labeling
한 규칙이 다를 수 있음
작업자분들을 훈련도 많이 시켰어야 했음
훈련 받은 분들이 한 labeling 기준과 데이터 증강기법으로 만들어진 데이터의 labeling 기준이 다를 수 있음
두 생성된 데이터의 의도가 다를 수 있음
증강기법에 따라 성능이 증가한 경우도 있었음

mecab 자체는 알고리즘이라고 생각하면 됨
crf 기반으로 학습이 되어있고 데이터는 다국어 형태소 분석기를 사용했음
동일한 알고리즘으로 다국어에 대해 학습된 여러 모델이 있음
mecab 은 기계학습 기반으로 적용이 된것이고 사전은 형태소분석이나 개체명분석에는 사전을 적용하는 것이 불가능
성능이 너무 안좋음
토큰을 분류하는 것은 사전기반이 성능이 낮을 수 밖에 없음

아무 이유 없고 글자가 귀여워서 정했음
노란색을 좋아함

RAG 라는 모델이 있는데 읽어보는 것을 추천함
논문을 보면 reference 가 다양하게 있는데 https://jeonsworld.github.io/NLP/rag/
핫한 이슈중에 답이 들어있는 문서에서 어떻게 retrieval 하는가가 굉장히 중요
RAG 논문 하나 읽고 컨셉에 대해서 이해하고 가는게 중요하다고 생각함
Blender 2.0 에 대해서도 배웠었는데 이것도 아직 핫한 기술이므로 document retrieval 로 찾아보면 많이 나올 것임
MRC 강의에도 설명이 있어서 도움이 많이 될 듯

하나는 AI 분야쪽 사람들과 대화를 통해서 얻음
또 하나는 facebook 에서 많이 얻고 있음 tensorflowKR, PyTorchKR, Montrial AI page 이런 곳을
보면 매일매일 새로운 논문소개와 이런 것들이 많이 나옴
세번째는 arxiv 에 keyword 로 검색한 다음에 논문들이 나옴
최신 논문들이 나오기 때문에 그걸 보면서 많이 update 하고 있음

입사지원서를 받았다고 가정해서 말해보겠음
캐글대회를 참여해서 몇등했는지는 관심 없음
등수가 중요한것이 아니라 문제정의를 어떻게했고 해결방법에 어떤식으로 접근했고 최종적으로 어떻게 해결했는지
관심있지 등수에 관심 별로 없음
수상경력을 적으라고 했을 때 상 못타고 참가만 해도 괜찮은 것 같음
RE 대회를 할 때도 RE 대회 나갔을 때 느꼈던 부분과 문제점이 정확히 정의가 되고 문제점을 해결하기 위해서
가설을 설정하고 실제로 테스트해봤을 때 어떤 결과가 있는지 이런 부분을 잘 정리하는 것이 중요
연구하는 과정을 보여주는 것이 훨씬 좋은 포트폴리오가 되는 것 같음

대기업이 커리큘럼과 트레이닝이 잘되어 있다는 생각은 편견임
아마 잘 되어 있는 곳은 없을 것
대기업에 있다면 여러 장점이 있음
일을 하는게 단순히 어떤일을 하는것도 중요하지만 복지나 연봉도 중요하니 원천징수로 받는 금액이 차이가 남
대기업에가면 나이에 비해서 훨씬 높은 연봉을 버는 경우가 있기 때문에 무시하기 힘듦
대기업에 경우 노동자의 힘이 더 쎄고 야근을해도 야근수당이 나온다던가 회사에 불합리한 상황이 벌어졌을 때
더 강력하게 어필이 가능하다던가 이런 좋은 복지가 있는 반면에 하고 싶은일이나 기회같은게 적을 수는 있음
반복적인 업무를 맡을 수 있음 물론 기업상황마다 다를 수 있음
스타트업은 내 의견이 피력되는게 목소리가 커질 수 있음
대기업은 직급에 대한 체계가 잘 되어있음
스타트업은 굳이 체계를 나누지 않는 편이 많음 팀장과 팀원이 회의를 하는 경우 팀원의 목소리가 좀 더
영향을 주는 경우도 있음
내가 하고 싶은 것을 어필할 수 있음
단점은 회사가 어느 순간 길이 바뀌는 경우가 있음
연구하는 쪽으로 많이 갔다가 돈이 부족해지다 보니 B2B 사업이나 SI 쪽으로 눈을 돌리면서 AI 프로덕트를 팔 때
연구적인 측면보다는 쌩 노가다를 하면서 구르게 되는…
이전 회사는 어느순간 BERT 모델을 돌려막기만 하고 있었음
그렇게 되는 케이스가 있음
실력향상 측면에서는 스타트업이 더 좋은 것 같음
개인적으로는 가능하면 대기업가는게 좋은 것 같음
케이스바이케이스 아닐까 싶음
대기업으로 가게되면 task 의 폭이 넓은 것 같음
스타트업 같은 경우는 회사의 조직 전체가 한 가지 목표의 task 를 혹은 하나의 분야를 타겟팅하는 경우가 많아서
포커싱되는 경우가 많음
대기업은 협력하는 협력사나 우리팀이 아닌 외부조직의 니즈도 충족할 필요가 있어서 좀 더 다양한 task 를 하는 것 같음
정확하게 가고자 하는 회사가 있으면 회사에 다니고 있는 분들에게 개별적으로 양해를 구하고 정보를 얻어보는 것도 정확한 정보일 것 같음

스톡옵션을 선택
상장안하고 이제 막 스타트업인데 발전가능성이 무궁무진하다 이러면 스톡옵션이 몇백배로 뛰니까 인생역전도 가능
심지어 창업멤버이면 무조건 스톡옵션을 선택할 거임
만약에 스타트업이 어느정도 자리를 잡고 있고 상장을 안하고 드라마틱한 발전이 안생긴다면 스톡을 받아도
영향이 적은 경우가 있음
그런데 한 주당 8000원 받았던 주식이 상장할 때는 30000원으로 뛰었음
많이 받은 분들은 굉장히 많이 벌었을 것
이직을 염두해둔다면 연봉수자체를 높이는 것도 중요함
다음 직장은 이전 직장을 기준으로 보고 연봉을 줌
요즘은 스타트업도 연봉을 높게 쳐줘서 스톡 받는게 더 좋은 것 같음
실제 KLUE 리더보드가 있으니 klue/roberta-large 를 꺾어주시길
이렇게 하면 포트폴리오가 될 것
자료의 링크들이 있는데 이걸 보면 좋을 것 같음
여러분들 공부하신 내용들이 대학원 1년치 공부를 한 것 같아서 많이 하셨으니 너무 걱정하지 마시고 자존감 떨어뜨리지 마시고 자신감있게 어떤일이든 해나갔음 좋겠고 꼭 지금이 아니더라도 궁금한거나 조언이나 포트폴리오 라던가 잔소리하는거 좋아하니까 필요하면 연락주시면 도움드릴 수 있을 것 같음
댓글남기기