Day_42 02. GPT 언어 모델 기반의 자연어 생성
작성일
GPT 언어 모델 기반의 자연어 생성
실습
텍스트 생성 방법 : Transformers 를 이용한 언어생성에 서로 다른 디코딩 방법 사용
이번 실습에서 사용할 모델은 Sk 에서 공개한 KoGPT-2 임
이번에는 KoGPT-2 모델을 직접 다운로드 받아서 사용하겠음
!curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bash
!apt-get install git-lfs
!git lfs install
!git clone https://huggingface.co/taeminlee/kogpt2
모델의 tokenizer 가 조금 다르게 설정이 되어있어서 기존의 BERT 에서 했던 것처럼 BertTokenizer 로 load 하면 Tokenizer 가 제대로 동작하지 않음
그래서 모델과 tokenizer 를 다운받고 수동으로 load 를 통해 사용하도록 하겠음
모델 다운로드 받고 나면 tokenizer 를 load 하겠음
import torch
from tokenizers import SentencePieceBPETokenizer
from transformers import GPT2Config, GPT2LMHeadModel
tokenizer = SentencePieceBPETokenizer("/content/kogpt2/vocab.json", "/content/kogpt2/merges.txt")
config = GPT2Config(vocab_size=50000)
config.pad_token_id = tokenizer.token_to_id('<pad>')
model = GPT2LMHeadModel(config)
model_dir = '/content/kogpt2/pytorch_model.bin'
model.load_state_dict(torch.load(model_dir, map_location='cuda'), strict=False)
model.to('cuda')
model.eval()
tokenizer.add_special_tokens(["<s>", "</s>"])

한국어 GPT2 를 만든 것 처럼 SentencePieceBPETtokenize 를 사용하겠음
다운로드 받았던 KoGPT-2 를 load 할 수 있음
이 모델 같은 경우에는 vocab_size 가 50000개로 되어있음
그래서 GPT2Config 를 load 할 때 반드시 vocab_size 를 맞춰줘야 함
그리고 명시적으로 token 의 pad 는 어떤것으로 되어있는지를 id 를 명시적으로 알려줌
그 다음에 모델도 directory 로 부터 load 해올 수 있음
모델 load 를 할 때 map_location='cuda' 로 설정해줘야지 GPU 로 올라가서 사용할 수 있음
첫번째로 설명할 방법은 Greedy Search 임
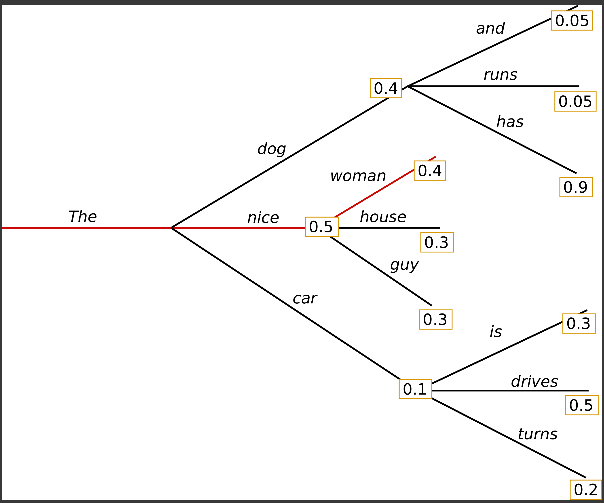
‘The’ 라는 첫번째 단어가 나왔을 때 ‘The’ 다음에 나올 수 있는 단어는 굉장히 많을 것임
이 경우에는 ‘dog’, ‘nice’, ‘car’ 이렇게 3가지 예시가 보여지고 있음
이 때, ‘dog’ 가 나올 수 있는 확률은 0.4로 40% 임
그리고 ‘nice’ 는 0.5 로 더 높은 확률임
Greedy Search 는 무조건 현재상태에서 가장 높은 확률로만 자연어를 생성하게됨
그러면 ‘The’ 다음에 ‘nice’ 가 되고 ‘nice’ 다음에 가장 높은 확률이 나올 수 있는 것은 ‘woman’ 임
그러면 모델은 ‘The’, ‘nice’, ‘woman’ 가장 최고의 확률로만 만들어지는 현재 상태에서 Greedy Search 를 통해 자연어를 만들어나가는 과정이 됨
이거를 GPT 모델에 적용해보자
# encode context the generation is conditioned on
def tokenizing(text):
return torch.tensor(tokenizer.encode('<s> '+text, add_special_tokens=False).ids).unsqueeze(0).to('cuda')
'''
I enjoy walking with my cute dog
'''
input_ids = tokenizing("이순신은 조선 중기의 무신이다.")
# generate text until the output length (which includes the context length) reaches 100
# 생성 모델은 generate 함수를 통해 다음 token을 생성해낼 수 있습니다.
greedy_output = model.generate(input_ids, max_length=100)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(greedy_output.tolist()[0], skip_special_tokens=True))
"""
Output:
----------------------------------------------------------------------------------------------------
I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with my dog. I'm not sure if I'll ever be able to walk with my dog.
I'm not sure if I'll
"""
우리가 테스트하고자 하는 단어는 “이순신은 조선 중기의 무신이다.” 이거임
이거 다음에 나올 단어를 예측하는데 model.generate() 에서 option 들을 다양하게 제공하고 있음
아무 옵션을 주지않고 그냥 input_ids 만 넣어주게 되면 그러면 자동으로 Greedy Search 를 시작하게 됨
그러면 결과를 한 번 보자

Greedy Search 입장에서는 항상 최고의 확률로만 단어를 만들어나가기 때문에 이렇게 똑같은 단어가 계속 반복됨
이건 좋지 않음
좀 더 자연스러운 단어가 만들어지길 바람
두번째로 제안된 방법이 Beam Search 라는 방법임
Beam Search 는 Greedy Search 처럼 가장 높은 확률로 나가는 것이 아니라 전체적으로 문장을 생성하고 봤을 때 그 문장의 확률이 최대가 되도록 문장을 생성해내게 됨
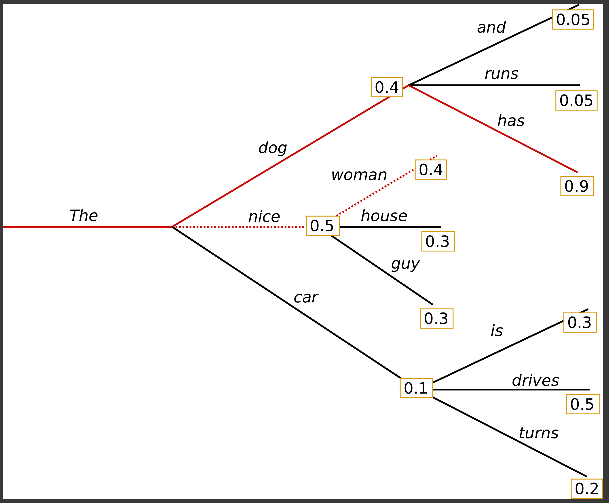
‘The’ 다음에 갈 수 있는 여러가지 길이 있는데 ‘nice’ 로가고 ‘woman’ 으로 가면 합이 0.5 * 0.4 의 확률을 가지게 됨
그런데 Beam Search 를 통해서 일단 문장을 생성해내고 그 문장의 최대확률로 가게 된다고 보게되면 빨간색 길로 가는게 전체 문장의 대한 확률은 더 높음
오히려 더 자연스러운 문장이고 문법적으로 맞는것이다 라는 것을 알 수 있음
Beam Search 를 사용하게되면 문장 자체에 문법적 확률이 더 높아지게 됨
대신 한편으로는 Beam Search 가 필요하기 때문에 inference 시간이 오히려 더 오래 걸림
왜냐면 다른 길도 파악하면서 모두 list up 을 해야되기 때문
Beam Search 를 사용하면 문장이 자연스럽게 나오느냐?
# activate beam search and early_stopping
beam_output = model.generate(
input_ids,
max_length=50,
num_beams=5,
early_stopping=True
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(beam_output.tolist()[0], skip_special_tokens=True))
"""
Output:
----------------------------------------------------------------------------------------------------
I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with him again.
I'm not sure if I'll ever be able to walk with him again. I'm not sure if I'll
"""

보이는 것처럼 반복되는 단어들이 나옴
이거를 해소하기 위한 방법으로는 n-gram 에 대한 penalty 가 있음
n-gram 은 음절단위로 자르는 거라고 말했는데 특정한 음절들이 계속해서 반복적으로 나온다면 그 쪽 길로 가지 않도록 penalty 를 줄 수 있
# set no_repeat_ngram_size to 2
beam_output = model.generate(
input_ids,
max_length=50,
num_beams=5,
no_repeat_ngram_size=2,
early_stopping=True
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(beam_output.tolist()[0], skip_special_tokens=True))
"""
Output:
----------------------------------------------------------------------------------------------------
I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with him again.
I'm not sure if I'll ever be able to walk with him again. I'm not sure if I'll
"""
예를 들어서 n-gram penalty 로 2개 (음절이 2개 이상 반복되지 않도록) 를 주게되면 조금 더 유연한 단어가 나올 수 있음

“이 목록은 대한민국의 작곡가 윤일상(尹一常)이 작사, 작곡한” 까지는 동일하게 나왔지만 그 다음에 n-gram penalty 에 의해서 다른 단어가 나옴
n-gram penalty 는 신중하게 사용되야함
예를 들어 고유명사들은 당연히 계속해서 나올 수 밖에 없음
그런데 n-gram penalty 를 주게되면 전체 text 에서 해당 단어가 한 번 밖에 나오지 않을 수 있음
그래서 penalty 는 줄 때 신중히 선택을 해야함
generate() 함수에서 제공하는 것 중에 하나가 num_return_sequences 인데 반환하고자 하는 sequence 가 몇개가 될 수 있는지 그런
개수를 지정해줄 수 있음
# set return_num_sequences > 1
beam_outputs = model.generate(
input_ids,
max_length=50,
num_beams=5,
no_repeat_ngram_size=2,
num_return_sequences=5,
early_stopping=True
)
# now we have 3 output sequences
print("Output:\n" + 100 * '-')
for i, beam_output in enumerate(beam_outputs):
print("{}: {}".format(i, tokenizer.decode(beam_output.tolist(), skip_special_tokens=True)))
"""
Output:
----------------------------------------------------------------------------------------------------
0: I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with him again.
I've been thinking about this for a while now, and I think it's time for me to take a break
1: I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with him again.
I've been thinking about this for a while now, and I think it's time for me to get back to
2: I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with her again.
I've been thinking about this for a while now, and I think it's time for me to take a break
3: I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with her again.
I've been thinking about this for a while now, and I think it's time for me to get back to
4: I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with him again.
I've been thinking about this for a while now, and I think it's time for me to take a step
"""
이 때 num_beams=5 로 설정했으니 5개의 가지만 바라보겠다는 뜻이고 num_return_sequence=5 그러면 최대로는 5개의 문장을
반환할 수 있음
사용자는 5개의 문장을 보고 최적의 문장을 선택할 수 있음

이 경우에 보면 전부다 생성되는게 동일하게 생성되는 것을 볼 수 있
이렇게 Beam Search 를 사용한다고 했을 때 약간 다르지 결국엔 비슷하게 나오게 됨
그러면 어떻게 유연한 결과를 만들어낼 수 있을까?
사람의 경우를 보자
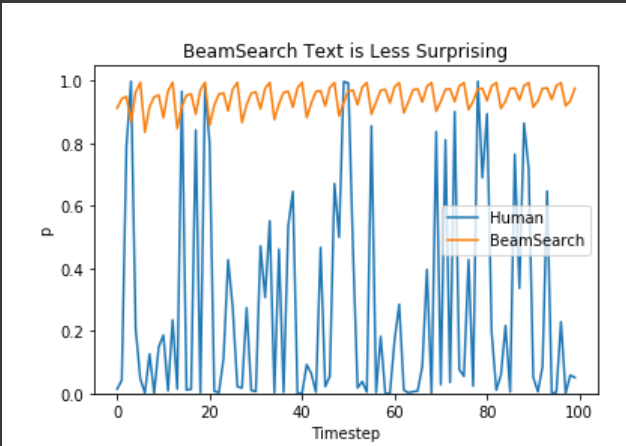
문장의 확률이 최대가 되도록 생성을 하면 어떤 문장이든 좋을거라고 가정이되는데 Beam Search 를 통해서 문장의 확률값을 볼 때 거의 100점 가까이 만들어내는 경우가 Beam Search 가 될 것이고 그런데 사람이 만들어내는 text 를 확률값으로 계산해봤더니 반드시 높은 수준으로만 유지가 되지 않음
낮은 수준의 확률값을 가지는 문장도 있었고 높은 확률을 가지는 문장과 또 낮은 확률 이런 것들이 굉장히 random 하게 왔다갔다 하는 것을 볼 수 있음
그리고 반드시 완벽한 문장만을 생성하게되면 똑같은 문장만 계속 생성이 됨
오히려 약간의 noise 를 섞거나 random 성을 추가해야지만 더 자연스러운 문장 더 dynamic 한 문장들이 나올 수 있음
그래서 적용한 방법이 Sampling 이라는 방법임
조건부확률에 따라서 단어를 무작위로 선택하는 것임
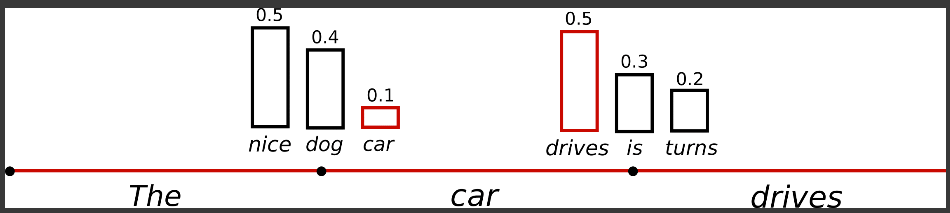
‘The’ 다음에 나올 수 있는 다양한 단어들이 있을텐데 이 중에 Random Sampling 으로 단어를 선택하게 됨
# activate sampling and deactivate top_k by setting top_k sampling to 0
sample_output = model.generate(
input_ids,
do_sample=True, # 완전 random sampling
max_length=50,
top_k=0 # w/o top_k 추출
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(sample_output.tolist()[0], skip_special_tokens=True))
"""
Output:
----------------------------------------------------------------------------------------------------
I enjoy walking with my cute dog. He just gave me a whole new hand sense."
But it seems that the dogs have learned a lot from teasing at the local batte harness once they take on the outside.
"I take
"""
generate() 함수의 옵션 중에 do_sample=True 로 두게되면 이 때부터 Random Sampling 이 시작하게 됨
그리고 top_k 라는게 뭐냐면 top_k 내에서 Random Sampling 을 하게되는데 이거를 0으로 두게되면 top_k 옵션을 끄게 됨
그러면 전체적으로 random 하게 만들어지게 됨

보면 “이순신은 조선 중기의 무신이다.” 나오고 뭔가 이상한 일관성 없는 이상한 문장이 나오게 됨
왜냐면 Random Sampling 때문
그러면 Random Sampling 에 다양한 옵션을 추가함으로써 이거를 일관성있는 문장으로 나올 수 있게 조절할 수 있음
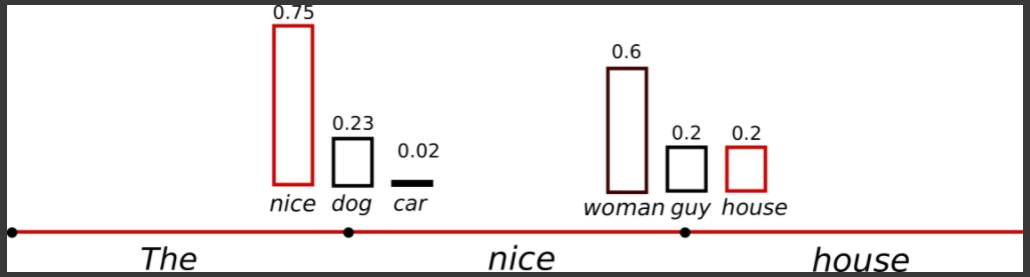
이걸 만들 수 있는 한가지 trick 이 softmax 이른바 temperature 를 조절할 수 있는데 이거는 높은 확률의 단어의 가능성은 점점 더 높아지게 만들고 낮은 확률은 더 적은 확률로 뽑히게 Sampling 을 해라 는 것을 명시적으로 지정해줄 수 있음
그러니까 Random Sampling 을 하되 높은 확률은 더 높은 확률로 선택을하고 낮은 확률에 있는건 더 낮은 확률로 선택해라 이런식으로 지정하게 됨
temperature=0.7 로 설정하고 어떻게 생성되는지 보자
# use temperature to decrease the sensitivity to low probability candidates
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_k=0,
temperature=0.7
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(sample_output.tolist()[0], skip_special_tokens=True))
"""
Output:
----------------------------------------------------------------------------------------------------
I enjoy walking with my cute dog, but I don't like to be at home too much. I also find it a bit weird when I'm out shopping. I am always away from my house a lot, but I do have a few friends
"""

좀 더 연관성이 어느정도 있을 것 같고 좀 더 문장처럼 만들어지는 것을 확인할 수 있음
그 다음에 여기에다가 top_k 옵션을 적용할 것임
Top-K Sampling 은 높은 확률을 가지는 K 개의 단어를 일단 선정해두고 거기서 Sampling 을 진행하게 됨
최종적으로 GPT-2 는 이 Top-K Sampling 방법을 채택했고 그렇기 때문에 좀 더 자연스러운 이야기를 생성해내는 결과를 얻을 수 있게됨
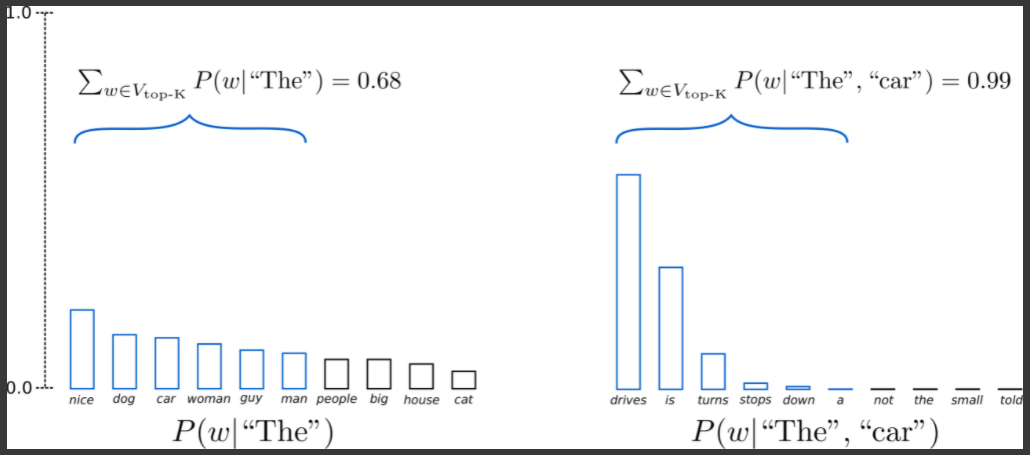
그러면 Top-K Sampling 을 적용한 결과를 보자
# set top_k to 50
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_k=50
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(sample_output.tolist()[0], skip_special_tokens=True))
"""
Output:
----------------------------------------------------------------------------------------------------
I enjoy walking with my cute dog. It's so good to have an environment where your dog is available to share with you and we'll be taking care of you.
We hope you'll find this story interesting!
I am from
"""
top_k=50 과 do_sample=True 를 설정

좀 더 유연하게 나온다는데 실제 결과는 관련없는 문장이 생성된 것 같은 느낌이다
여기서 더 추가할 수 있는 방법중에 하나가 Top-p Sampling 이 있음
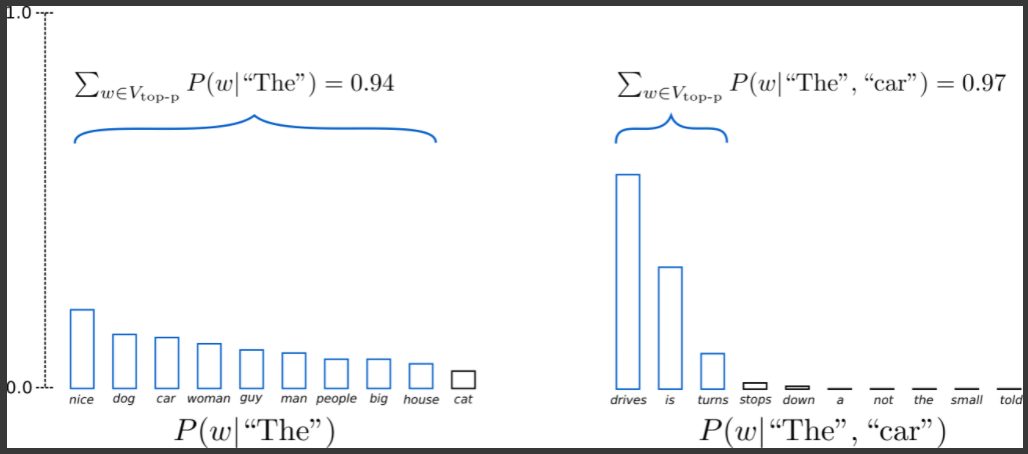
K 개만 바라보되 K 의 누적확률이 특정 확률 이상으로만 넘은 애들만 관찰하겠다라고 정의하게 됨
이 경우에는 ‘The’ 다음에 나올 수 있는게 다양하게 나올 수 있는데 얘네들의 합이 0.94 이상인 애들의 범위까지만 보고 그 다음에 Sampling 을 진행하게 됨
오른쪽 그림도 0.97 까지 왔으므로 0.9 이상으로 나왔으니 그 범위 안에서만 Sampling 을 진행을 하겠다라고 설정할 수 있음
# deactivate top_k sampling and sample only from 92% most likely words
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_p=0.92,
top_k=0
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(sample_output.tolist()[0], skip_special_tokens=True))
"""
Output:
----------------------------------------------------------------------------------------------------
I enjoy walking with my cute dog. He will never be the same. I watch him play.
Guys, my dog needs a name. Especially if he is found with wings.
What was that? I had a lot of
"""
top_p=0.92 로 적용해서 보자

앞서서 반복되는 단어와 달리 문장처럼 나오는 것을 볼 수 있음
이론적으로는 Top-p 가 Top-K 보다 성능이 좋아보이지만 실제로는 2개 다 잘 동작함
최종적으로 얻을 수 있는 문장들을 관찰해보자
# set top_k = 50 and set top_p = 0.95 and num_return_sequences = 3
sample_outputs = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_k=50,
top_p=0.95,
num_return_sequences=3
)
print("Output:\n" + 100 * '-')
for i, sample_output in enumerate(sample_outputs):
print("{}: {}".format(i, tokenizer.decode(sample_output.tolist(), skip_special_tokens=True)))
"""
Output:
----------------------------------------------------------------------------------------------------
0: I enjoy walking with my cute dog. It's so good to have the chance to walk with a dog. But I have this problem with the dog and how he's always looking at us and always trying to make me see that I can do something
1: I enjoy walking with my cute dog, she loves taking trips to different places on the planet, even in the desert! The world isn't big enough for us to travel by the bus with our beloved pup, but that's where I find my love
2: I enjoy walking with my cute dog and playing with our kids," said David J. Smith, director of the Humane Society of the US.
"So as a result, I've got more work in my time," he said.
"""

KoGPT-2 를 이용해서 다양한 문장을 생성해 낼 수 있음
생성모델을 이용해서 어떤 방법으로 생성하는지 규칙에 대해서 알아보았음
다음으로는 KoGPT-2 모델을 이용해서 Few-shot, Zero-shot learning task 를 진행해봐서 진짜로 GPT-2 가 적용이 가능한지
알아보도록 하자
실습
KoGPT-2를 활용한 Few-shot & Zero-shot 실습
!curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bash
!apt-get install git-lfs
!git lfs install
!git clone https://huggingface.co/taeminlee/kogpt2
모델 다운로드 받고
import torch
from tokenizers import SentencePieceBPETokenizer
from transformers import GPT2Config, GPT2LMHeadModel
tokenizer = SentencePieceBPETokenizer("/content/kogpt2/vocab.json", "/content/kogpt2/merges.txt")
config = GPT2Config(vocab_size=50000)
config.pad_token_id = tokenizer.token_to_id('<pad>')
model = GPT2LMHeadModel(config)
model_dir = '/content/kogpt2/pytorch_model.bin'
model.load_state_dict(torch.load(model_dir, map_location='cuda'), strict=False)
model.to('cuda')
모델 로드하고
tokenized_text = tokenizer.encode('이순신은 조선 중기의 무신이다.', add_special_tokens=True)
print(tokenized_text)
print(tokenized_text.tokens)
print(tokenized_text.ids)

토크나이징 테스트 해보고
원하는대로 토크나이징이 잘 되고 vocab_id 도 반환하는 것을 확인할 수 있음
tokenizer.add_special_tokens(["<s>", "</s>"])
명시적으로 문장의 시작과 끝에는 “", "” 기호가 들어가는 것을 tokenizer 에 지정해줌
import torch
torch.manual_seed(42)
input_ids = torch.tensor(tokenizer.encode("이순신은", add_special_tokens=True).ids).unsqueeze(0).to('cuda')
output_sequences = model.generate(input_ids=input_ids, do_sample=True, max_length=100, num_return_sequences=3)
for generated_sequence in output_sequences:
generated_sequence = generated_sequence.tolist()
print("GENERATED SEQUENCE : {0}".format(tokenizer.decode(generated_sequence, skip_special_tokens=True)))

생성도 테스트 해봄
자연스럽게 잘 생성되는 것을 볼 수 있음
전 실습에서 했던 다양한 생성방법들 다 넣어보자
def get_gpt_output(input_sent):
input_ids = torch.tensor(tokenizer.encode(input_sent, add_special_tokens=True).ids).unsqueeze(0).to('cuda')
sample_outputs = model.generate(
input_ids,
do_sample=True,
max_length=512,
top_k=50,
top_p=0.95,
num_return_sequences=1,
eos_token_id=tokenizer.token_to_id("</s>"),
no_repeat_ngram_size=2,
early_stopping=True
)
generated_sequence = sample_outputs[0].tolist()
return tokenizer.decode(generated_sequence, skip_special_tokens=True)
top_k, top_p, do_sample 이런 것들을 넣어줬음
generate 옵션에서 줄 수 있는게 eos_token_id 옵션이 있음
eos_token_id=tokenizer.token_to_id("</s>") 이렇게 지정해주면 나중에 문장을 생성하다가 내가 지정한 토큰이 등장하게되면
early_stopping 이 가능해지게 됨
그 이상 생성하지 않게 됨
get_gpt_output("<s>이순신은")
입력으로 “<s>이순신은” 이라는 문장을 주었더니

문장 마침 기호가 등장했기 때문에 더이상 생성하지 않고 early stopping 이 된 것임
이 방법을 이용해서 Zero-shot learning 을 해보자
get_gpt_output("<s>철수 : 영희야 안녕!</s><s>영희 : ")

대화체가 나오길 기대했는데 “….” 이 나옴
이번에는 Few-shot learning 을 해보자
get_gpt_output("<s>철수 : 영희야 안녕!</s><s>영희 : 어! 철수야! 오랜만이다!</s><s>철수 : 그러게~ 잘 지냈어?</s><s>영희 : ")

이상한 말 대잔치……
One-shot learning 으로 감정에 대한 분류를 해보자
get_gpt_output("<s>본문 : 아.. 기분 진짜 짜증나네ㅡㅡ</s><s>감정 : 분노</s><s>본문 : 와!! 진짜 너무 좋아!!</s><s>감정 : ")

“짱짱구!” 라니 ㅋㅋㅋㅋ 웃음만 나옴
이번에는 open domain question 을 해봄
Few-shot learning 으로 진행
get_gpt_output("<s>질문 : 코로나 바이러스에 걸리면 어떻게 되나요?</s>\
<s>답 : COVID-19 환자는 일반적으로 감염 후 평균 5 ~ 6 일 (평균 잠복기 5 ~ 6 일, 범위 1 ~ 14 일)에 경미한 호흡기 증상 및 발열을 포함한 징후와 증상을 나타냅니다. COVID-19 바이러스에 감염된 대부분의 사람들은 경미한 질병을 앓고 회복됩니다.</s>\
<s>질문 : 코로나 바이러스 질병의 첫 증상은 무엇입니까?</s>\
<s>답 : 이 바이러스는 경미한 질병에서 폐렴에 이르기까지 다양한 증상을 유발할 수 있습니다. 질병의 증상은 발열, 기침, 인후통 및 두통입니다. 심한 경우 호흡 곤란과 사망이 발생할 수 있습니다.</s>\
<s>질문 : 딸기 식물의 수명주기는 무엇입니까?</s>\
<s>답 : 딸기의 생애는 새로운 식물의 설립으로 시작하여 2 ~ 3 년 후 절정에 이르렀다가 절정에 이어 2 ~ 3 년에 노화와 죽음을 향해 진행됩니다. 이상적인 조건에서 딸기 식물은 5-6 년까지 살 수 있습니다.</s>\
<s>질문 : 파이썬 메서드의 self 매개 변수의 목적은 무엇입니까?</s>\
<s>답 : self 매개 변수는 클래스의 현재 인스턴스에 대한 참조이며 클래스에 속한 변수에 액세스하는 데 사용됩니다.</s>\
<s>질문 : 뇌의 어떤 부분이 말을 제어합니까?</s>\
<s>답 : 언어 우세 반구의 왼쪽 전두엽 (브로카 영역)에있는 뇌의 분리 된 부분에 대한 손상은 자발적 언어 및 운동 언어 제어 사용에 상당한 영향을 미치는 것으로 나타났습니다.</s>\
<s>질문 : 인공지능의 미래에 대해 어떻게 생각하십니까?</s>\
<s>답 : ")

get_gpt_output("<s>질문 : 코로나 바이러스에 걸리면 어떻게 되나요?</s>\
<s>답 : COVID-19 환자는 일반적으로 감염 후 평균 5 ~ 6 일 (평균 잠복기 5 ~ 6 일, 범위 1 ~ 14 일)에 경미한 호흡기 증상 및 발열을 포함한 징후와 증상을 나타냅니다. COVID-19 바이러스에 감염된 대부분의 사람들은 경미한 질병을 앓고 회복됩니다.</s>\
<s>질문 : 코로나 바이러스 질병의 첫 증상은 무엇입니까?</s>\
<s>답 : 이 바이러스는 경미한 질병에서 폐렴에 이르기까지 다양한 증상을 유발할 수 있습니다. 질병의 증상은 발열, 기침, 인후통 및 두통입니다. 심한 경우 호흡 곤란과 사망이 발생할 수 있습니다.</s>\
<s>질문 : 딸기 식물의 수명주기는 무엇입니까?</s>\
<s>답 : 딸기의 생애는 새로운 식물의 설립으로 시작하여 2 ~ 3 년 후 절정에 이르렀다가 절정에 이어 2 ~ 3 년에 노화와 죽음을 향해 진행됩니다. 이상적인 조건에서 딸기 식물은 5-6 년까지 살 수 있습니다.</s>\
<s>질문 : 파이썬 메서드의 self 매개 변수의 목적은 무엇입니까?</s>\
<s>답 : self 매개 변수는 클래스의 현재 인스턴스에 대한 참조이며 클래스에 속한 변수에 액세스하는 데 사용됩니다.</s>\
<s>질문 : 뇌의 어떤 부분이 말을 제어합니까?</s>\
<s>답 : 언어 우세 반구의 왼쪽 전두엽 (브로카 영역)에있는 뇌의 분리 된 부분에 대한 손상은 자발적 언어 및 운동 언어 제어 사용에 상당한 영향을 미치는 것으로 나타났습니다.</s>\
<s>질문 : 자연어처리에서 언어모델이란 무엇입니까?</s>\
<s>답 : ")

맞는말인지는 잘 모르겠지만 기존의 자연어를 생성하던 패턴이랑은 굉장히 다른 양상을 보임
get_gpt_output("<s>질문 : 코로나 바이러스에 걸리면 어떻게 되나요?</s>\
<s>답 : COVID-19 환자는 일반적으로 감염 후 평균 5 ~ 6 일 (평균 잠복기 5 ~ 6 일, 범위 1 ~ 14 일)에 경미한 호흡기 증상 및 발열을 포함한 징후와 증상을 나타냅니다. COVID-19 바이러스에 감염된 대부분의 사람들은 경미한 질병을 앓고 회복됩니다.</s>\
<s>질문 : 코로나 바이러스 질병의 첫 증상은 무엇입니까?</s>\
<s>답 : 이 바이러스는 경미한 질병에서 폐렴에 이르기까지 다양한 증상을 유발할 수 있습니다. 질병의 증상은 발열, 기침, 인후통 및 두통입니다. 심한 경우 호흡 곤란과 사망이 발생할 수 있습니다.</s>\
<s>질문 : 딸기 식물의 수명주기는 무엇입니까?</s>\
<s>답 : 딸기의 생애는 새로운 식물의 설립으로 시작하여 2 ~ 3 년 후 절정에 이르렀다가 절정에 이어 2 ~ 3 년에 노화와 죽음을 향해 진행됩니다. 이상적인 조건에서 딸기 식물은 5-6 년까지 살 수 있습니다.</s>\
<s>질문 : 파이썬 메서드의 self 매개 변수의 목적은 무엇입니까?</s>\
<s>답 : self 매개 변수는 클래스의 현재 인스턴스에 대한 참조이며 클래스에 속한 변수에 액세스하는 데 사용됩니다.</s>\
<s>질문 : 뇌의 어떤 부분이 말을 제어합니까?</s>\
<s>답 : 언어 우세 반구의 왼쪽 전두엽 (브로카 영역)에있는 뇌의 분리 된 부분에 대한 손상은 자발적 언어 및 운동 언어 제어 사용에 상당한 영향을 미치는 것으로 나타났습니다.</s>\
<s>질문 : 대한민국에서 최고의 인공지능 기술을 보유한 기업은 어디입니까?</s>\
<s>답 : ")

get_gpt_output("<s>질문 : 코로나 바이러스에 걸리면 어떻게 되나요?</s>\
<s>답 : COVID-19 환자는 일반적으로 감염 후 평균 5 ~ 6 일 (평균 잠복기 5 ~ 6 일, 범위 1 ~ 14 일)에 경미한 호흡기 증상 및 발열을 포함한 징후와 증상을 나타냅니다. COVID-19 바이러스에 감염된 대부분의 사람들은 경미한 질병을 앓고 회복됩니다.</s>\
<s>질문 : 코로나 바이러스 질병의 첫 증상은 무엇입니까?</s>\
<s>답 : 이 바이러스는 경미한 질병에서 폐렴에 이르기까지 다양한 증상을 유발할 수 있습니다. 질병의 증상은 발열, 기침, 인후통 및 두통입니다. 심한 경우 호흡 곤란과 사망이 발생할 수 있습니다.</s>\
<s>질문 : 딸기 식물의 수명주기는 무엇입니까?</s>\
<s>답 : 딸기의 생애는 새로운 식물의 설립으로 시작하여 2 ~ 3 년 후 절정에 이르렀다가 절정에 이어 2 ~ 3 년에 노화와 죽음을 향해 진행됩니다. 이상적인 조건에서 딸기 식물은 5-6 년까지 살 수 있습니다.</s>\
<s>질문 : 파이썬 메서드의 self 매개 변수의 목적은 무엇입니까?</s>\
<s>답 : self 매개 변수는 클래스의 현재 인스턴스에 대한 참조이며 클래스에 속한 변수에 액세스하는 데 사용됩니다.</s>\
<s>질문 : 뇌의 어떤 부분이 말을 제어합니까?</s>\
<s>답 : 언어 우세 반구의 왼쪽 전두엽 (브로카 영역)에있는 뇌의 분리 된 부분에 대한 손상은 자발적 언어 및 운동 언어 제어 사용에 상당한 영향을 미치는 것으로 나타났습니다.</s>\
<s>질문 : 이순신 장군이 전사한 전투는 무슨 전투입니까?</s>\
<s>답 : ")

강의에서와는 달리 정말 말도안되는 답변들이 나오고 있는데 학습이 안되서 그러는걸까??
번역에 대한 것도 테스트해보자
get_gpt_output("<s>한국어: 그 도로는 강과 평행으로 뻗어 있다.</s>\
<s>English: The road runs parallel to the river.</s>\
<s>한국어: 그 평행선들은 분기하는 것처럼 보인다.</s>\
<s>English: The parallel lines appear to diverge.</s>\
<s>한국어: 그 도로와 운하는 서로 평행하다.</s>\
<s>English: The road and the canal are parallel to each other.</s>\
<s>한국어: 평행한 은하계라는 개념은 이해하기가 힘들다.</s>\
<s>English: The idea of a parallel universe is hard to grasp.</s>\
<s>한국어: 이러한 전통은 우리 문화에서는 그에 상응하는 것이 없다.</s>\
<s>English: This tradition has no parallel in our culture.</s>\
<s>한국어: 이것은 현대에 들어서는 그 유례를 찾기 힘든 업적이다.</s>\
<s>English: This is an achievement without parallel in modern times.</s>\
<s>한국어: 그들의 경험과 우리 경험 사이에서 유사점을 찾는 것이 가능하다.</s>\
<s>English: It is possible to draw a parallel between their experience and ours.</s>\
<s>한국어: 그 새 학위 과정과 기존의 수료 과정이 동시에 운영될 수도 있을 것이다.</s>\
<s>English: The new degree and the existing certificate courses would run in parallel.</s>\
<s>한국어: 이순신은 조선 중기의 무신이다.</s>\
<s>Englisth: ")

번역에서 완전 쌩뚱맞은 얘기를 함
근데 이게 번역에서뿐만 아니라 앞에서도 계속 그랬음
get_gpt_output("<s>한국어: 그 도로는 강과 평행으로 뻗어 있다.</s>\
<s>English: The road runs parallel to the river.</s>\
<s>한국어: 그 평행선들은 분기하는 것처럼 보인다.</s>\
<s>English: The parallel lines appear to diverge.</s>\
<s>한국어: 그 도로와 운하는 서로 평행하다.</s>\
<s>English: The road and the canal are parallel to each other.</s>\
<s>한국어: 평행한 은하계라는 개념은 이해하기가 힘들다.</s>\
<s>English: The idea of a parallel universe is hard to grasp.</s>\
<s>한국어: 이러한 전통은 우리 문화에서는 그에 상응하는 것이 없다.</s>\
<s>English: This tradition has no parallel in our culture.</s>\
<s>한국어: 이것은 현대에 들어서는 그 유례를 찾기 힘든 업적이다.</s>\
<s>English: This is an achievement without parallel in modern times.</s>\
<s>한국어: 그들의 경험과 우리 경험 사이에서 유사점을 찾는 것이 가능하다.</s>\
<s>English: It is possible to draw a parallel between their experience and ours.</s>\
<s>한국어: 그 새 학위 과정과 기존의 수료 과정이 동시에 운영될 수도 있을 것이다.</s>\
<s>English: The new degree and the existing certificate courses would run in parallel.</s>\
<s>한국어: 100명은 서 있을 수 있을 것 같은 섬 하나가 넓은 하늘 위에 두둥실 떠 있다.</s>\
<s>Englisth: ")

KoGPT-2 를 활용해도 Zero-shot, One-shot, Few-shot leanring 을 할 수 있음을 알 수 있음
다음 실습에서는 원하는 답변을 내놓도록 GPT-2 를 fine-tuning 해보자
실습
한국어 언어모델 학습 및 다중 과제 튜닝
KoGPT-2 를 이용해서 내가 원하는 task 로 맞춰서 fine-tuning 을 하고 실제로 inference 날려서 어떻게 생성이되는지 확인하는 과정을 해보도록 하자
이번 실습에서는 자유대화가 가능한 챗봇을 만들어보자
!curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bash
!apt-get install git-lfs
!git lfs install
!git clone https://huggingface.co/taeminlee/kogpt2
모델 다운받고
import torch
from tokenizers import SentencePieceBPETokenizer
from transformers import GPT2Config, GPT2LMHeadModel
tokenizer = SentencePieceBPETokenizer("/content/kogpt2/vocab.json", "/content/kogpt2/merges.txt")
config = GPT2Config(vocab_size=50000)
model = GPT2LMHeadModel(config)
model_dir = '/content/kogpt2/pytorch_model.bin'
model.load_state_dict(torch.load(model_dir, map_location='cuda'), strict=False)
model.to('cuda')
모델 load 하고
tokenized_text = tokenizer.encode('이순신은 조선 중기의 무신이다.', add_special_tokens=True)
print(tokenized_text)
print(tokenized_text.tokens)
print(tokenized_text.ids)

토크나이저 테스트 해보고 잘 되는 것 확인
import torch
torch.manual_seed(42)
input_ids = torch.tensor(tokenizer.encode("이순신은", add_special_tokens=True).ids).unsqueeze(0).to('cuda')
output_sequences = model.generate(input_ids=input_ids, do_sample=True, max_length=100, num_return_sequences=3)
for generated_sequence in output_sequences:
generated_sequence = generated_sequence.tolist()
print("GENERATED SEQUENCE : {0}".format(tokenizer.decode(generated_sequence, skip_special_tokens=True)))

단어 생성도 잘되는 것 확인
그러면 데이터셋을 준비하자
심리상담을 위한 챗봇 데이터로 만들어보자
!git clone https://github.com/songys/Chatbot_data.git
import pandas as pd
data = pd.read_csv('/content/Chatbot_data/ChatbotData.csv')
data.head(10)
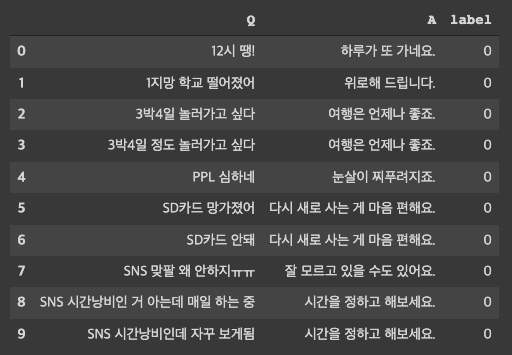
Qeustion 과 Answer 가 singleton 으로 연결되어 있는 데이터를 확인할 수 있음
added_special_token_num = tokenizer.add_special_tokens(['<s>', '</s>'])
print(added_special_token_num)

tokenizer 에게 명시적으로 문장의 시작과 끝을 알려줌
그리고 fine-tuning 을 하는 과정을 거칠 예정이기 때문에 나중에 special token 이 추가가 된다고 하면 반드시 모델도 resize 하는 과정이 필요함
지금 task 에서는 특별한 다른 token 이 추가되지 않겠지만 만약 본인이 원하는 special token 이 추가가 된다면 반드시 추가된 token 이 몇개인지 기억해두고 나중에 모델을 resize 하는 과정을 필수로 필요로 함
pad_id = tokenizer.token_to_id("<pad>")
print(pad_id)
tokenizer.enable_padding(pad_id=pad_id, pad_token="<pad>")
tokenizer.enable_truncation(max_length=128)
<pad> 토큰도 넣어주게
BertTokenizer 에서는 padding 이라는 옵션으로 padding 을 설정해줬다면 이 tokenizer 는 enable_padding 으로 설정할 수 있음
truncation 할 때도 enable_truncation 으로 max_length 가 몇개인지 명시적으로 알려줌으로써 truncation 과 padding 을 가능하게
만들어주게 됨
class ChatDataset(torch.utils.data.Dataset):
def __init__(self, tokenizer, file_path):
self.data = []
self.file_path = file_path
self.tokenizer = tokenizer
def load_data(self):
raw_data = pd.read_csv(self.file_path)
train_data = '<s>'+raw_data['Q']+'</s>'+'<s>'+raw_data['A']+'</s>'
#<s>안녕하세요</s><s> -> 네, 안녕하세요</s>
tokenized_train_data = tokenizer.encode_batch(train_data)
for single_data in tokenized_train_data:
self.data.append(torch.tensor(single_data.ids).unsqueeze(0))
def __len__(self):
return len(self.data)
def __getitem__(self, index):
item = self.data[index]
return item
학습을 위한 데이터를 만들어줘야 하는데 이 과정은 GPT-2 에서 pre-training 을 위해 데이터를 만들어줬던거랑 똑같음
load_data(), __get_item__() 함수를 구현함
load_data() 는 실제로 dataset 에서 데이터를 load 하고 우리가 원하는대로 전처리가 이루어지도록 데이터를 수정하는 과정을 말함
train_dataset = ChatDataset(tokenizer=tokenizer, file_path='/content/Chatbot_data/ChatbotData.csv')
train_dataset.load_data()
tokenizer 명시해주고 file_path 명시해 줌
load_data() 하게 되면 전체 데이터들이 self.data 안에 저장됨
from torch.utils.data import DataLoader
data_loader = DataLoader(train_dataset, batch_size=4, shuffle=True)
그 다음엔 떠먹여주는 data loader 를 만들어줌
train dataset 을 batch_size 4만큼 input 으로 넣어라 라고 만들어주게 됨
from transformers import AdamW
optimizer = AdamW(model.parameters(), lr=1e-4, correct_bias=True)
epochs = 3
avg_loss = (0.0, 0.0)
for epoch in range(epochs):
count=0
for data in data_loader:
optimizer.zero_grad()
data = data.transpose(1,0)
data = data.to('cuda')
model = model.to('cuda')
outputs = model(data, labels=data)
loss, logits = outputs[:2]
loss = loss.to('cuda')
loss.backward()
avg_loss = (avg_loss[0] * 0.99 + loss, avg_loss[1] * 0.99 + 1.0)
optimizer.step()
if count % 200 == 0:
print('epoch no.{0} train ({1}/{2}) loss = {3:.5f} avg_loss = {4:.5f}' . format(epoch, count, len(data_loader), loss, avg_loss[0] / avg_loss[1]))
count += 1
현재 예제는 torch 를 사용했음
pre-train 에서 사용한 예제를 사용해도 똑같이 동작함
모델에 data 를 넣고 label 이 data 자체가 됨
GPT-2 는 학습할 때 data input 을 한칸씩 넣어가면서 다음 토큰이 뭐가나오는지 그 확률이 최대가 되도록 학습이 됨
torch.save(model.state_dict(), 'chitchat_model.bin')
모델을 저장하면 우리가 만든 chatbot 모델이 저장됨
실제 inference 를 통해서 챗봇과 대화하는 task 를 해봐야 함
def encoding(text):
text = '<s>'+text+'</s><s>'
return torch.tensor(tokenizer.encode(text).ids).unsqueeze(0).to('cuda')
def decoding(ids):
return tokenizer.decode_batch(ids)
tokenizer.no_padding()
tokenizer.no_truncation()
e_s = tokenizer.token_to_id('</s>')
unk = tokenizer.token_to_id('<unk>')
encoding() 함수는 내가 입력한 text 에 대해 앞뒤로 bos, eos token 을 넣어주게 되고 그 다음에 생성을 해야하는 시점이 <s> 토큰으로 문장의
시작점을 알려준 것임
이 text 를 vocab_id 로 치환해주고 vocab_id 로 치환된 것이 모델의 input 으로 들어감
그럼 모델은 뒷부분에 생성된 단어들을 만들어낼거고 그걸 다시 decoding 함으로써 원래 정답을 알아낼 수 있음
def get_answer(input_sent):
input_ids = encoding(input_sent)
sample_outputs = model.generate(
input_ids,
num_return_sequences=5,
do_sample=True,
max_length=128,
top_k=50,
top_p=0.95,
eos_token_id=e_s,
early_stopping=True,
bad_words_ids=[[unk]]
)
decoded_result = decoding(sample_outputs.tolist())
for result in decoded_result:
print(result)
우리가 정의한 sentence 를 vocab_id 로 바꿔주고 그걸 모델의 입력으로 넣어주고 예제를 5개 보기 위해 설정하고
그리고 Sampling 도 넣고 top_k, top_p 두가지 옵션도 다 넣었고 max_length 까지 지정해줌
그 다음에 생성을 멈추도록 하는 eos_token_id 까지 입력해줌
여기에 추가로 bad_words_ids 라는 옵션이 추가로 나왔는데 가끔 <unk> 토큰을 생성할 수 있음
입력된 거의 대해서 적정한 Random Sampling 과 top_p, top_k 를 참고하다보니 <unk> 토큰이 등장할 수 있음
그 때 <unk> 토큰이 등장하게 되면 다른것을 선택해라라고 bad_words_ids 를 등록해줄 수 있음
여기에 배열형태로 넣게되면 그 token 들이 생성되지 않도록 피하는 과정이 generate 함수내에서 이뤄지게 됨
그래서 생성된 output(vocab_ids)을 이걸 decoding 을 하고 반환하게 되면 채팅결과가 나오는 것임
테스트를 해보자
get_answer('안녕?')

get_answer('만나서 반가워.')

get_answer('인공지능의 미래에 대해 어떻게 생각하세요?')

get_answer('여자친구 선물 추천해줘.')

get_answer('앞으로 인공지능이 어떻게 발전하게 될까요?')

get_answer('이제 그만 수업 끝내자.')

재밌는 답변들이 많이 나옴
이것으로 KoGPT-2 를 활용한 챗봇 실습을 마치도록 하겠음
작성자
* 김성현 (bananaband657@gmail.com) 1기 멘토 김바다 (qkek983@gmail.com) 박상희 (parksanghee0103@gmail.com) 이정우 (jungwoo.l2.rs@gmail.com) 2기 멘토 박상희 (parksanghee0103@gmail.com) 이정우 (jungwoo.l2.rs@gmail.com) 이녕우 (leenw2@gmail.com) 박채훈 (qkrcogns2222@gmail.com)
댓글남기기