Day_43 01. 최신 자연어처리 연구
작성일
최신 자연어처리 연구
1. BERT 이후의 LM
1.1 XLNet
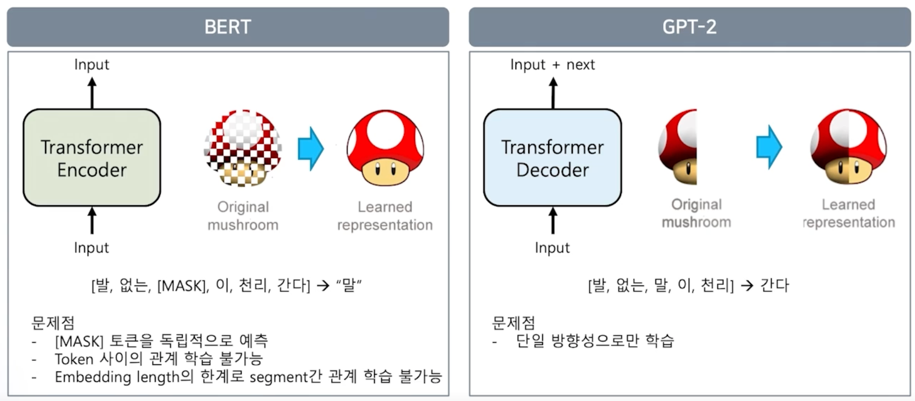
BERT 같은 경우는 MASK 를 통해서 그 MASK 된 문장을 다시 원본으로 복원하는 과정으로 학습이 이루어짐
그렇기 때문에 문제점이 발생할 수 있음
BERT 는 MASK 토큰을 독립적으로 예측을 하게 됨
예측의 대상이 그저 MASK 토큰일 뿐 임
그렇기 때문에 토큰 사이의 관계를 학습하는것이 불가능 함
그리고 embedding_length 의 한계로 512 토크을 벗어나는 새로운 segment 의 대해서는 segment 와 segment 의 관계를 학습하는 것이 불가능 함
그리고 GPT-2 는 앞의 나온 단어를 바탕으로 다음 토큰이 어떤것이 나올지 예측하는 방법으로 학습이 됨
이 문제는 단일 방향성으로만 학습한다는 문제점이 있음
그래서 이 두가지 문제점을 보완해서 나온 아이디어가 바로 XLNet 이라는 Language Model 임
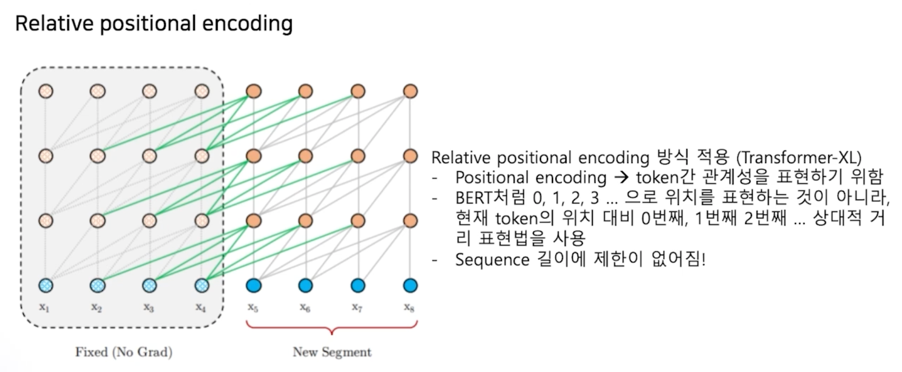
XLNet 은 512 토큰의 한계점을 벗어나기 위해 positional encoding 을 Relative positional encoding 방식을 사용함
BERT 같은 경우에는 512 토큰 내에서 절대값을 기준으로 positional encoding 을 한다면 XLNet 같은 경우에는 현재 토큰의 위치대비 0번째, 1번째, 2번째 이런 상대적 거리 표현법을 바탕으로 positional encoding 을 함
이렇게 되기 때문에 sequence 의 대한 길이 제한이 없어짇나는 장점이 있음
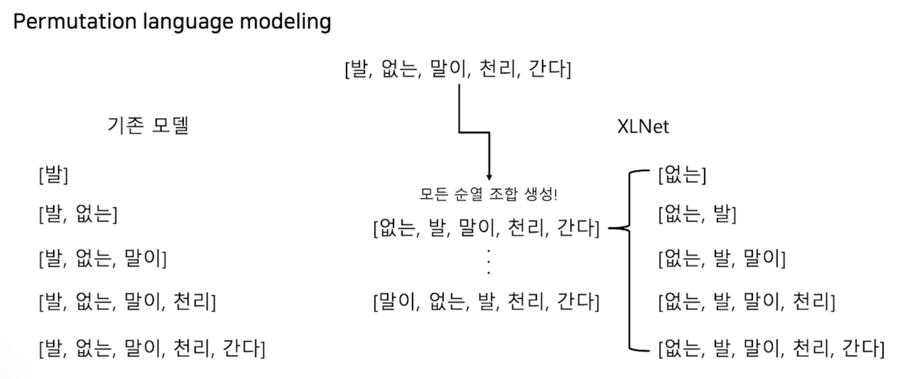
두번째로는 MASK 토큰을 없앴음
Permutation language modeling 이라는 방법으로 학습이 진행됨
왼쪽에 보이듯이 기존 모델은 “발” 다음에 “없는” 이 나오고 그 다음에 “말이” 가 나오듯이 이렇게 단어를 순차적으로 예측하는 방식으로 학습이 이루어짐
하지만 XLNet 은 순열 조합을 통해서 문장을 학습하게 됨
예를 들어서 “발 없는 말이 천리간다” 라는 sequence 가 있을 때 이 sequence 내에 존재하는 모든 토큰들을 순열 조합을 통해서 순서를 모두 섞어버림
그리고 그 섞인 순서의 sequence 가 학습의 대상이 됨
예를 들어서 “발 없는 말이 천리간다” 가 “없는 발 말이 천리 간다” 라는 문장으로 순열이 섞였다고 예시로 들어보자
이 때 XLNet 은 이 문장이 정답으로 여기고 “없는”, “발”, “말이” 이렇게 순서를 섞어가지고 학습을 하게 됨
이렇게 섞었기 때문에 한 방향으로만 학습하게 되는 것을 방지할 수 있음
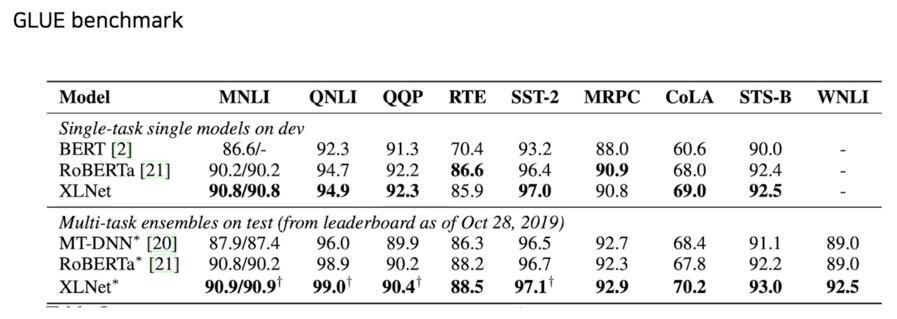
XLNet 이 나왔을 때 바로 기존 모델들의 성능을 한참 뛰어넘게 됨
BERT 랑 RoBERTa 라는 모델이 있는데 이 XLNet 이 가장 SOTA 성능을 보여주게 됨
그리고 기존 BERT 모델의 한계점을 보완하기 위해 제안된 또 다른 모델인 RoBERTa 모델이 있음
1.2 RoBERTa
BERT 구조에서 학습 방법을 고민!
- Model 학습 시간 증가 + Batch size 증가 + Train data 증가
- Next Sentence Prediction 제거 $\rightarrow$ Fine-tuning 과 관련 없음 + 너무 쉬운 문제라 오히려 성능 하락
- Longer sentence 추가
- Daynamic masking $\rightarrow$ 똑같은 텍스트 데이터에 대해 masking 을 10번 다르게 적용하여 학습
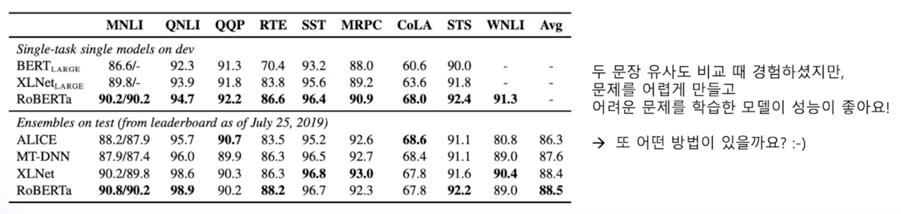
이 방법을 통해서 기존의 BERT 보다 성능이 더 높게 나온 결과를 얻음
XLNet 과 RoBERTa 혹은 BERT 얘네 모델들 모두 다 어떻게 Text 를 이쁘게 encoding 하느냐의 문제였는데 BERT 도 성능 좋고 GPT 도 성능이 좋으니 이거 두개를 하나로 합칠 수 있지 않을까? 하는 아이디어로 BART 라는 모델이 나옴
1.3 BART
Transformer Encoder-Decoder 통합 LM
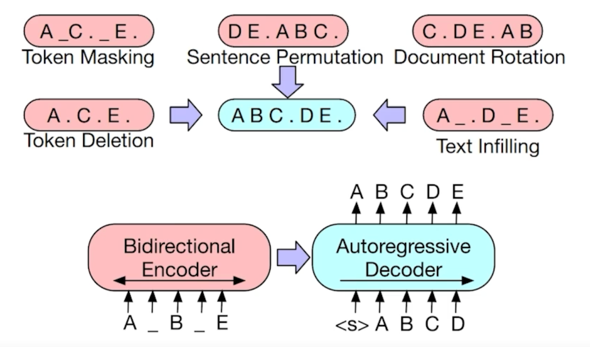
학습 방법은 다양한 방법을 선택함
기존의 GPT 같은 경우에는 Next Token 을 예측하게 되어있고 BERT 는 Mask 된 토큰을 예측하도록 되어있음
이 모델은 여러가지 방법을 다 섞었음
Token Masking 한 것을 올바르게 예측하는 것도 만들었고 Sentence 를 Permutation 한 다음에 올바른 순열을 만들도록 예측하는 것도 학습함
그리고 문서 자체에 token 을 ratation 해서 ratation 한 것을 올바르게 맞추는 것도 진행했고 이런 복잡한 다양한 task 들을 학습하도록 만들었음
기존의 MASK 를 예측하는 것만 만들었던게 BERT 라면 BART 라는 모델은 온갖 어려운 task 들을 한꺼번에 예측할 수 있게 만들어놓은 것이고 이렇기 때문에 언어를 좀 더 정확하게 학습할 수 있었다고 함
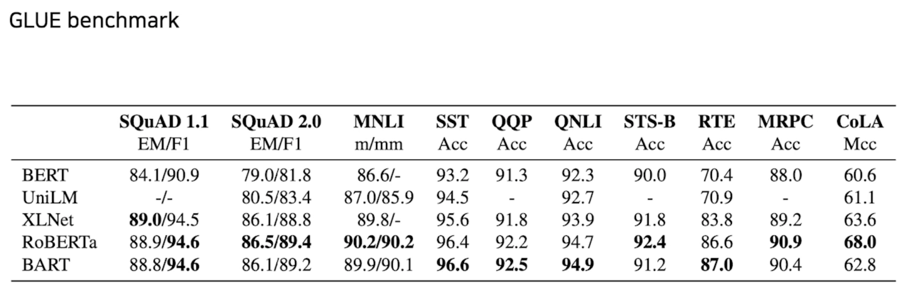
그래서 BART 가 나왔을 때 XLNet 이나 RoBERTa 성능을 더 뛰어넘는 그런 결과를 보여줌
이렇게 정형화 된 모든 사람이 인정한 자연어 task 데이터 셋이 존재하고 이런 Benchmark 가 있어야 우리가 언어모델에 대한 정량적 비교가 가능해짐
다음으로 소개해드릴 모델 역시 Transformer Encoder-Decoder 를 사용한 모델임
이 모델은 T-5 라는 모델임
1.4 T-5
Transformer Encoder-Decoder 통합 LM $\rightarrow$ 현재까지의 끝판왕!
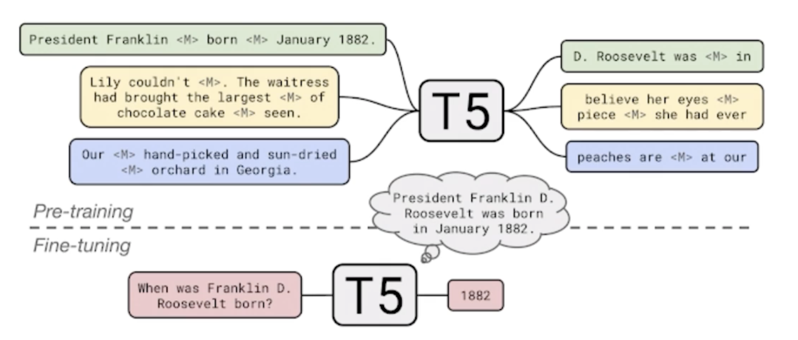
현재 가장 SOTA 모델임
T-5 모델은 Pre-training 과정에서 온갖 task 들을 다양하게 학습할 수 있음
SQuAD 데이터를 통해서 학습하고 GLUE 데이터셋을 이용해 학습하기도 함
T-5 는 학습을 할 때 비슷하게 Masking 기법을 사용함
하지만 Masking 이 하나의 토큰만을 의미하는게 아니고 의미를 가진 여러 어절들을 동시에 Masking 을 하고 그 Mask 도 한번에 학습할 때 여러개의 Multi Mask 를 다시 복원하는 과정으로 학습을 하게 됨
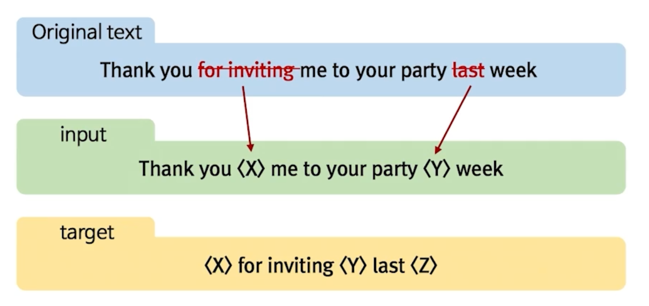
Original text 가 있을 때 여러개의 어절을 하나의 Mask token 으로 치환해버림
그러면 input 자체가 두개의 어절이
그러니까 훨씬 더 어려운 문제를 학습하게 되는 것임
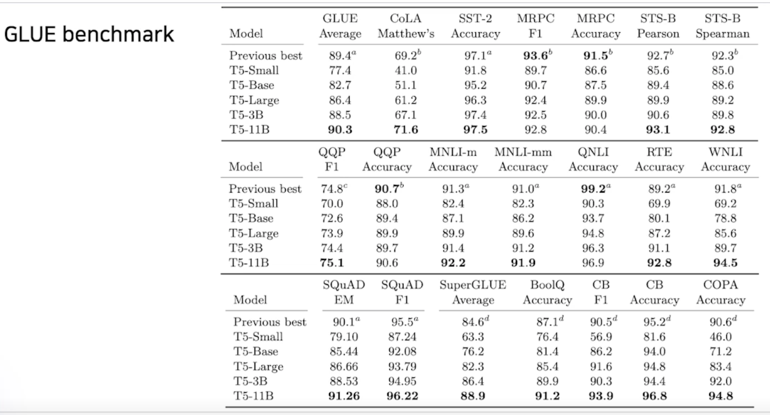
이렇게 했을 때 T-5 같은 경우는 11B 개의 parameter 를 가지게 되는데 이 모델이 나왔을 때 기존의 GLUE 데이터셋에서 가장 SOTA 모델이 되게 됨
그래서 T-5 모델이 NLU task (자연어처리 task) 에 대해서는 가장 높은 성능을 보여주는 language model 로 여겨지고 있음
T-5 도 마찬가지로 transformers 에 업로드가 되어있고 불러와서 사용할 수 있음
대신 한국어 T-5 는 없지만 MT-5 라고 Multi-lingual T-5 모델을 공개했음
그 안에 한국어도 담겨있고 실제로 T-5 를 통해서 다양한 fine-tuning 을 진행하면 높은 성능의 결과를 보여줄 수 있음
1.5 Meena
다음으로 소개해드릴 모델은 대화만을 위한 Language Model 임
대화 모델을 위한 LM

이 모델은 Transformer 의 Encoder Block 한 layer 와 나머지 Decoder Block 을 잔뜩 합쳐서 만들게 됨
소셜 미디어의 대화 데이터 총 341GB 의 대화 데이터를 사용했고 이 모델 자체의 사이즈는 26억개의 파라미터를 가지고 있는 end-to-end multi-turn 챗봇이라고 함
모델이 되게 다양한 답변을 해줄 수 있음
위 그림의 왼쪽 예시를 보면 유저가 “나 뭔가 보려고 결정하려고 한다” 라고 하니까 Meena 가 “너 어떤 쇼를 제일 좋아하냐?” 라고 얘기하고 유저는 “watch” 라는 단어를 사용했는데 Meena 는 여기서 “Show” 어떤 재밌는(선호하는) Show 가 있는지 dynamic 한 답변을 만들어낼 수 있음
그리고 유저가 “Good Place” 라는 걸 좋아한다고 하니까 Meena 가 이렇게 얘기함 “난 그걸 본적이 없다. 내가 좋아하는 쇼는 Supernatural 그리고 Star Trek 그리고 TNG 다” 라고 얘기함
이 말은 Good Place 는 TV show 에 관련된 거고 현재 대화 맥락자체가 TV Show 에 관련된 대화를 하고있다라는 것이고 Meena 는 TV Show 에 관련된 예제를 이미 Language Model 안에 학습을 해놓았다는 것임
그래서 “What is TNG?” 라고 물어보니까 “The Next Generation” 이라고 완벽하게 QA 까지 가능한 성능 좋은 모델임
이 모델은 대화성능 자체도 굉장히 좋은 편이었고 그리고 새로운 평가 챗봇의 평가를 위한 새로운 metric 인 SSA 라는 것을 제시해줘서 많은 contribution 을 가져감
이 SSA 는 Sensibleness 와 Specificity 를 말하고 있음
Sensibleness 는 현재까지 진행중인 대화에 가장 적절한 답변을 했는지 안했는지를 결정하는 점수임
만약에 현재 대화 맥락과 어울리는 답변을 했다면 이 Sensibleness 점수가 높게되는 것임
그리고 Specificity 는 얼마나 구체적으로 답변을 했는지를 의미
예를 들어서 유저가 “나 뭐 볼려고 그래” 라고 하면 Meena 가 가장 적절한 답변중에 “그렇구나”, “그래”, “아 정말?” 이런 것들도 굉장히 어울리는 답변이 될 수도 있는데 “어떤 쇼를 좋아해?” 라고 했을 때 “잘 모르곘어” 아니면 “나 아는 쇼 없어” 이런식으로만 얘기를 해도 분명히 적절한 답변이 될 수 있을 것임
하지만 구체적인 답변은 아니라는 점!
그래서 챗봇 평가를 할 때 좀 더 구체적이고 명확하고 예제를 들어서 설명한다면 이런 Specificity 점수가 높게 되게 됨
Meena 같은 경우는 이 두가지를 사람이 평가하게해서 SSA 를 평가하도록 했음
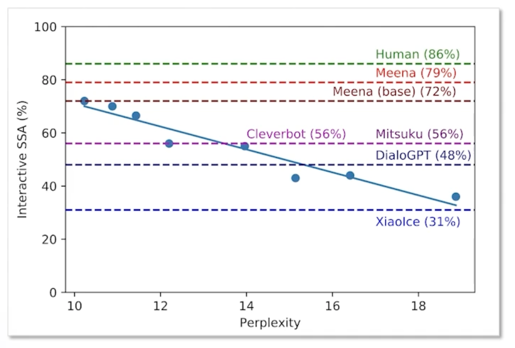
결과론적으로는 Meena 가 사람은 86% 정도의 점수를 얻었다면 Meena 는 사람과 굉장히 근접한 799 점의 점수를 얻었다고 함
Meena 아래에 있는 Mitsuku 라는 챗봇이 보이는데 Mitsuku 라는 챗봇이 어떤 챗봇이냐면 외국에는 Turing-test 와 같은 대회가 있음
그 대회에서 3년인가 4년 계속해서 연승을 하던 챗봇이었음
그래서 사람과 가장 자연스럽고 자유롭게 대화한다고 알려진 Mitsuku 가 SSA 점수는 56점 밖에 안됨
Meena 는 한참 뛰어넘는 점수가 나온 모델임
이런 end-to-end generation 챗봇들은 정말 말만 잘하면 다 되는걸까?
그렇게 생각하지 않음!
인공지능 챗봇이 가장 인간다워지려면 인간과 같은 윤리성을 당연히 가지고 있어야 한다고 생각함
하지만 이런 Generation 모델은 분명히 모델의 확률론적인 것에 생성을 맡기기 때문에 이런 윤리성을 control 할 방안이 없을 것임
이런 control 을 할 수 있게 연구가 되는 부분이 바로 Controllable Language Modeling 알고리즘 들임
1.6 Controllable LM
Plug and Play Language Model (PPLM)
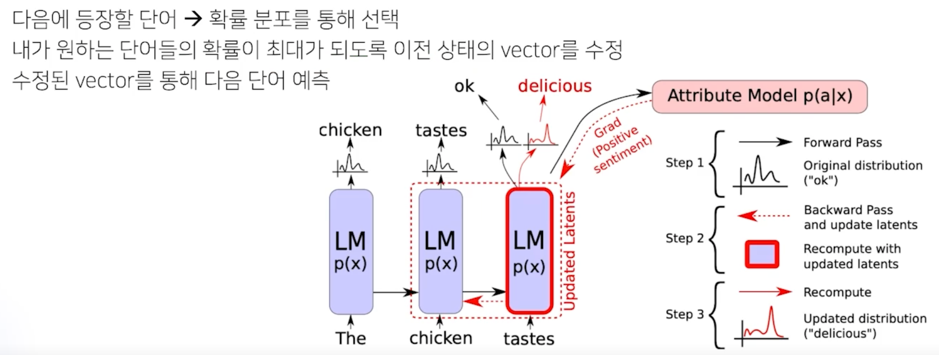
대표적으로 Plug and Play Language Model 이 있음
일반적으로 Language Model 이 다음 답변을 생성을 할 때는 단순히 다음에 등장할 단어에 대해서 확률 분포를 통해서 선택하게 되어 있음
물론 그 안에서는 sampling 이나 다양한 방법들이 있겠지만 어쨌든 그게 확률성을 반영해서 선택을 하게 됨
이 Plug and Play 모델은 어떤것을 제안하냐면?
다음에 나오기에 적절한 단어들을 bag of words 에 저장하고 있음
그래서 예를 들어서 긍정의 답변을 원한다 그러면 긍정적인 답변의 예시들을 저장을 해놓는 것임
“좋아”, “그래”, “그렇게 하는게 좋을 것 같아” 이런 예제들을 미리 bag of words 에 저장해놓음
그러면 PPLM 이 제안하는 방법은 이렇게 내가 원하는 bag of words 의 단어들이 최대 확률로 되도록 이전 상태의 vector 를 수정하는 방법을 제안하고 있음
단계적으로 설명해보자
여기 Language Model 이 “The chicken” 을 생성했다고 가정해보자
그러면 “The chicken” 다음에 Languae Model 이 결정한 것은 “taste” 라고 결정을 했고 “taste” 다음에 나올 수 있는 확률분포를 봤을 때 “ok” 라는 단어가 최대 확률분포인 것을 확인했음
그러면 “ok” 가 나올 수 있어야 하는데 우리는 “delicious” 라는게 더 높은 확률로 나오길 바라는 상황임
나의 bag of words 에는 “delicious” 가 저장되어 있는 상황임
그러면 이 모델은 어떤식으로 동작을 하냐면 먼저 “delicious” 의 확률분포도 확인을 함
그러면 이 모델은 이런식으로 동작하게 됨
내가 가지고 있는 bag of words 의 모든 확률 데이터를 현재 상태에 맞춰서 확인을 함
그러면 “ok” 가 가지고 있는 왼쪽의 그래프보다 나의 확률분포가 더 낮게 나올 것임
이렇게 됐을 때 내가 가진 bag of words 가 최대 확률로 유지될 수 있도록 backpropagation 을 통해서 “chicken” 쪽에서 만들어진 vector 그 vector 정보를 다시 수정을 하게 됨
실제로 gradient 가 업데이트 되는 것이 아니고 이전의 만들어진 vector 값을 수정함으로써 내가 가진 bag of words 의 단어들이 최대 확률로 되도록 수정을 하게 되는 것임
그래서 최종적으로는 “The chicken tastes” 다음에 “ok” 가 아니라 “delicious” 가 선택될 수 있도록 의도적인 유도를 만들어냄
이 모델의 가장 큰 장점은 실제로 gradient update 를 필요로 하지 않기 때문에 기존의 학습한 모델을 바탕으로 내가 원하는 단어로 생성하도록 유도할 수 있다는 것임
- 확률 분포를 사용하는 것이기 때문에, bag of words 의 중첩도 가능 (기쁨 + 놀람 + 게임)
- 특정 카테고리에 대한 감정을 컨트롤해서 생성 가능
- 정치적, 종교적, 성적, 인종적 키워드에 대해서는 중성적인 단어를 선택해서 생성
- 범죄 사건에 대해서는 부정적인 단어를 선택해서 생성
- 확률 분포 조절을 통해 그라데이션 분노 가능
- 초반에는 분노1 level1 정도로 분노를 하다가 그 level 에 있는 bag of words 를 점점 더 심한말로 바꿔주게 되면 예제에서 보이는 것처럼 그라데이션 분노도 만들 수 있음

여기서 추가로 드리고 싶은 말씀은 정치적, 종교적 이런 편향성 데이터를 애초에 학습데이터에 안넣으면 그런 편향성있는 대사가 나오지 않는것 아니냐 라고 생각하실수도 있을 것 같음
실험했던 것중에 인공지능 다람이 프로젝트를 한적이 있음
이 프로젝트가 뭐냐면?
하나의 GPT 모델은 전문가들이 선별한 3세 이하의 올바른 대화표현을 가지고 모델을 학습시켰음
여기에는 Disney 만화라던가 학습만화 정말로 문법적으로 올바르고 좋은 표현들만 가득한 그런 데이터로 학습을 했고
하나의 데이터로는 유튜브의 댓글이라던가 혹은 유튜브의 전사데이터 욕설도 섞여있음
이런 나쁜 데이터만 가지고 학습을 해서 두 모델이 어떤 식으로 언어를 표현하는가 이것을 연구했던 모델임
실제로 착하게 학습한 모델은 정말 착한말만 뱉을 것 같은데 이 모델한테 예를 들어서 “나 마약 너무 좋아” 이런식으로 얘기하면 이 모델은 마약이라는 것을 정확이 모름
내가 좋다니까 얘도 같이 좋아함 “응 맞아 나도 마약 되게 좋아해” 이런식으로 답변이 나올 수 밖에 없음
이거는 기존의 Language Model 이 가지는 한계점임
그래서 편향성이 제거된 데이터만 가지고 학습을 하면 편향성이 제거된 output 이 나온다? 이거는 틀린 얘기임
반드시 언어모델 자체는 언어를 잘 하는 법을 배우는 거라고 생각을 함
그래서 Language Model 의 역할은 정말로 자연스럽게 풍부한 대화를 하기 위해 학습이 되어있다면 이 풍부한 대화 다음에 윤리성에 대한 어떤 모델이 혹은 모듈이 필요하다고 생각함
그래서 최신 연구들은 PPLM 처럼 Language Model 의 생성자체를 후단에서 control 한다던가 혹은 만들어진 모델의 출력 결과에 대해서 챗봇에서 유사도 비교를 통해서 output 을 필터링 한 것 처럼 뭔가 윤리성 평가 장치를 둬서 필터링 할 수 있도록 그런식으로 대화모델이 발전되고 있음
그리고 직접 PPLM 을 테스트를 한국어에서 진행해봤음
한국어 BoW 실험

역시 KoGPT-2 를 활용했음
그리고 Music BoW 라는 단어장을 만들어봤음 여기에는 우리가 알고 있는 음악 장르에 대해서 넣어봤음
그리고 BoW 와 PPLM 을 적용했을 때와 적용하지 않았을 때를 비교분석해 보겠음
KoGPT-2 에 “스마일 게이트” 라는 input 만 넣어봤음

BoW 가 적용되지 않았을 때는 텐센트와 합병한다, 모바일게임과 관련된 얘기하고 새로운 뉴스가 나옴
이거는 KoGPT-2 가 뉴스데이터에 많이 편향되어 있음 그래서 뉴스폼으로 생성된 것을 볼 수 있음
여기에 PPLM 을 적용했을 때 나오는 결과를 확인해보자

마찬가지로 스마일게이트에 관련된 얘기와 게임에 관련된 얘기가 나오고 그 다음 뉴스 자체가 “엠카운트다운” 이라는 음악과 관련된 뉴스기사가 생성되고 있음
그래서 “씨스타”, “포미닛” 처럼 여자 연예인들 그런 댄스팀들과 관련된 기사가 생성된 것을 확인할 수 있었음
다음으로는 음악과 관련이 없을 것 같은 “문재인 대통령이” 라는 input 을 넣어봤음

그러자 문재인 대통령이 국민의례를 하고있다 그리고 박근혜 대통령은 사과해야한다 이런 키워드들이 나오는 것을 확인할 수 있음
여기에 PPLM 을 적용해보니

보면 문재인 대통령이 노래 가사를 불렀다 라고 음악과 연결되어 있는 문장이 생성되는 것을 확인할 수 있음
그 뒤로는 갈라쇼, 리듬체조 스타들, 공연을 펼치게 된다 그리고 레이디 가가 처럼 음악과 관련된 단어들이 생성되는 것을 볼 수 있음
이것처럼 모든 생성을 언어모델에게 맡기는 것 뿐만 아니라 내가 원하는 방향으로 control 을 하는 conrollable LM 에 관한 연구도 최신 연구로 계속 지속되어오고 있음
그러면 궁금한 사항이 생기게 되는데?
과연 자연어 to 자연어로 충분할까요??
우리가 언어를 배울 때, written language 인 책만 보고 학습하나요?
태어나서 첫 마디를 뗄 때까지, 우리는 spoken language 를 통해 학습합니다.
또한 인간은 시각, 청각, 후각, 촉각, 미각 등의 모든 감각을 통해 세상을 학습합니다.
그렇다면 인공지능을 구현하기 위해 자연어 to 자연어로 충분할까요?
그렇게 생각하지 않음!!
최신에는 multi-model 연구가 활발하게 이뤄지고 있음
2. Multi-modal Language Model
Multi-modal 이 어떤 것이냐?
뇌과학적 접근으로 한가지 예시를 들어 설명하겠음
2.1 할머니세포 (Grandmother cell)
할머니세포에 대해서 들어본적 있나요?
이 세포의 이야기는 Philip Roth (1969)의 소설 Portnoy’s Complaint 에서 시작되었음
이 소설이 어떤 내용을 품고 있냐면?
어떤 환자가 한명 있었음. 이 환자는 어머니의 대한 기억으로부터 굉장히 많은 고통을 받고 있었음. 그래서 천재 신경외과의사인 아카키 아카키비치라는 사람한테 요청을 하게됨. 나한테 어머니의 대한 기억을 지워달라고
이 의사가 얼마나 천재였냐면? 우리의 뇌속에 들어있는 뉴런들의 각각의 역할을 모두 알고 있었다고 함
그래서 이 환자를 위해서 환자의 머리를 열고 어머니를 의미하는 몇천개의 뉴런을 하나씩 제거를 했다고 함
그러고 나니까 환자는 깨어났을 때 어머니의 대한 모든 기억이 사라져있게 되었다고 함
이거는 1969년도에 제안된 소설인데 그러니까 어머니를 representation 하는 concept 뉴런들을 제거했더니 해당 concept 의 대한 기억이 사라졌다는 것임
이 소설을 통해서 한 신경외과 과학자가 할머니 세포라는 개념을 제시하게 됨
이 세포는 한개의 단일 세포가 어떤 concept 에 대해 반응한다는 것임
할머니가 될 수도 있고 어머니가 될 수도 있을 것임
이렇게 concept 의 대한 개념을 저장하는 뇌세포가 실제로 발견이 되었음
어떻게 발견이 되었냐면 다음과 같이 실험을 했음
**electrophysiological recording - Microelectrode arrays (MEAs)
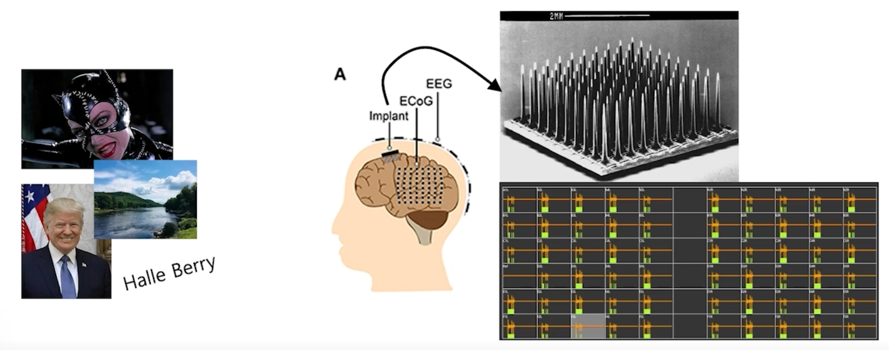
실험 방법이 환자가 누워있는 상태에서 머리 뚜껑을 열고 뇌 위에다가 뇌의 전기적 신호를 측정할 수 있는 장치를 부착을 함
부착을 하고 환자의 눈앞에 다양한 concept 에 대한 이미지를 보여줌
트럼프의 이미지를 보여주기도 하고 자연의 이미지를 보여주기도 함
이런 다양한 이미지들을 보여줬을 때 환자의 뇌세포가 활성이 어떻게 변화되는지를 관찰했다고 함
이 때 굉장히 재밌는 뉴런이 하나 발견이 되게 되는데
이 뉴런은 Halle Berry Neuron 이라고 함
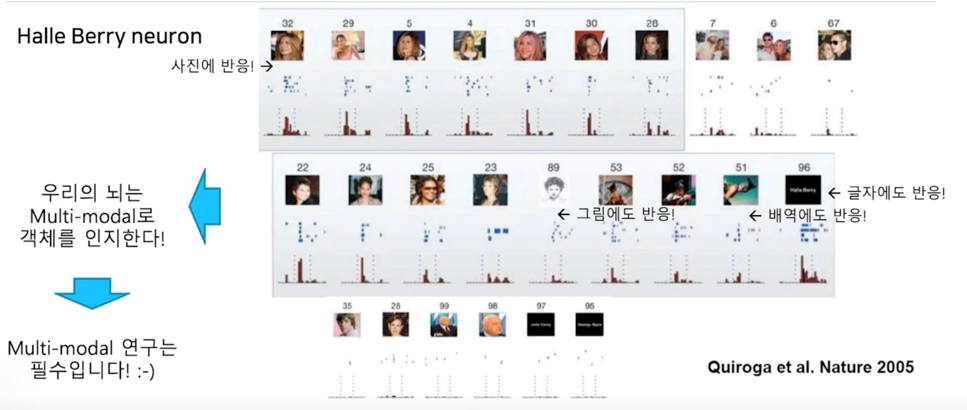
어떤 뉴련이냐면?
수 많은 이미지를 많이 보여줬는데 유독 Halle Berry 라고 하는 여배우의 모습만 나타나면 그 뇌세포가 반응하기 시작
재밌는 것은 얼굴 이미지만 가지고 반응을 하는 것이 아니라 Halle Berry 라는 글자(오른쪽의 96번) 이렇게 글자에도 반응을 하고 이 사람이 연기했던 배역에도 반응을 하게 됨
그리고 초상화의 모습 그림에서도 반응이 됨
그러니까 우리의 뇌가 하나의 객체를 인지할 때 다양한 Multi-modal 정보를 바탕으로 그 객체를 인지하게 됨
우리는 언어를 배우거나 어떤 세상을 이해를 할 때 단순히 text 만 가지고 이해를 한다는 것이 아니라는 것임
온갖 다양한 modality 를 가지고 이해를 하게 됨
그렇기 때문에 Multi-modal 을 이용한 연구는 필수적으로 필요하고 앞으로 계속해서 발전해 나갈 것임
이런 관점에서 봤을 때 이미지, 자연어 등의 배운 내용을 모두 활용한다면 훨씬 좋은 Multi-model 연구자가 될 수 있을 것이라고 생각함
그러면 Multi-modal LM 을 소개하겠음
2.2 LXMERT
Cross-modal reasoning language model (Learning Cross-Modality Encoder Representations from Transformers)
이미지와 자연어를 동시에 학습!
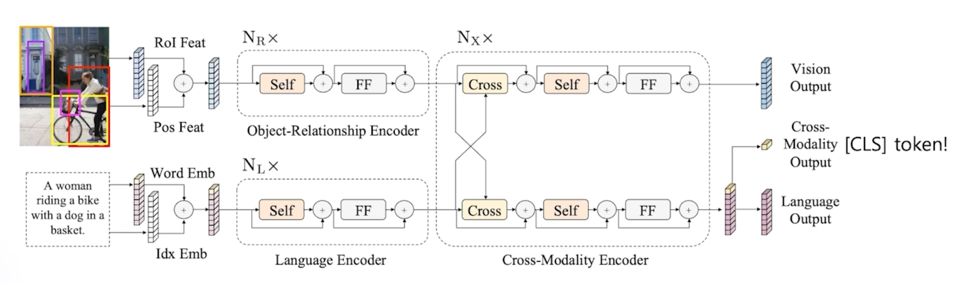
동시에 학습된 정보를 하나의 모델로 합침으로써 이미지와 자연어를 하나로 연결할 수 있음
그림에서 가장 오른쪽에 Cross-Modality Output 이라고 첫번째 토큰을 가져오게 됨
이 토큰이 생성되기 위해서는 자연어의 embedding 된 정보와 이미지가 embedding 된 정보가 서로 cross 가 되어서 하나로 합쳐져서 만들어지게 됨
이 Cross-Modality Output 가 우리가 BERT 에서 가져온 것과 마찬가지로 [CLS] 토큰이 되는 것임
그래서 이 모델을 이용해서 분류 task 를 하되 자연어가 섞여있는 분류 task 를 시도했더니 성능이 가장 좋게 나왔다고 함
이미지 feature - 자연어 feature 가 하나의 모델에 반영됨
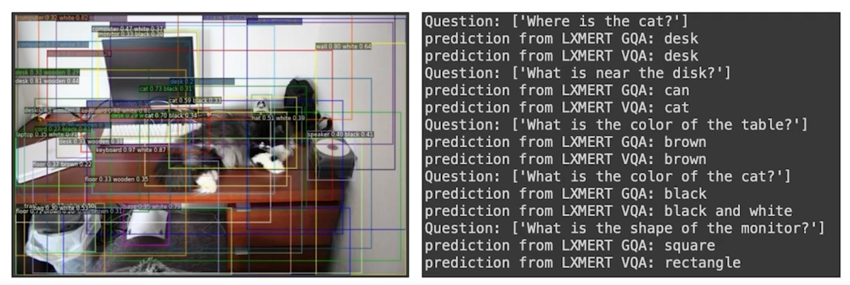
옆에 이미지가 보이고 이 때 이미지의 관련된 질문을 자연어로 줌
“Where is the cat?” 이라고 했을 때 답변으로 “desk” 라고 나옴
이것은 질문에 대한 자연어도 이해하고있고 “cat” 이라고 하는 자연어와 “desk” 라는 자연어의 관계와 그 이미지에 어떻게 맵핑되는지 이런 것들이 모두 하나의 모델에 반영이 되어있기 때문에 이런 좋은 답변을 만들어 낼 수 있음
2.3 ViLBERT
비슷한 예로 BERT for vision-and-language 모델이 있음
이 모델은 BERT 와 구조가 똑같음
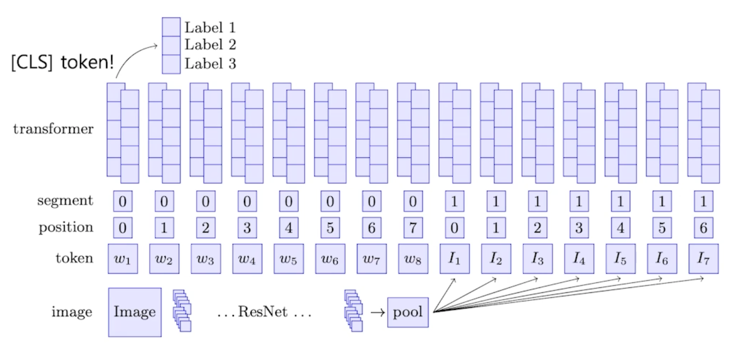
그런데 앞에 토큰에는 BERT 는 일반적으로 문장 1번과 [SEP] 토큰과 문장 2번을 넣었는데 이 모델은 앞에 토큰은 Image 에 대한 embedding vector
를 넣고 그 다음에 [SEP] 토큰 다음에는 자연어에 대한 vector 를 넣음
그러면 BERT 입장에서는 Image 에 대한 토큰과 자연어에 대한 토큰을 하나로 합쳐서 [CLS] 토큰을 만들어내게 됨
그러면 만들어진 [CLS] 토큰 위에 classification layer 만 부착하면 자연어와 이미지가 합쳐져있는 정보를 통해서 분류를 하게되는 그런 task 를
수행할 수 있음

MM-IMDB 라는 데이터셋에는 이미지와 text 데이터가 있음
그래서 이 정보를 통해서 주어진 정보가 어떤 장르의 영화인가를 분류할 수 있는 모델임
실제로 이미지만 보고 분류했을 때와 text 만 보고 분류했을 때 그리고 이미지와 text 를 하나로 합쳐서 분류했을 때 세가지의 task 의 성능을 비교해보면 이미지와 text 를 하나로 합쳐서 분류했을 때 성능이 가장 좋았다고 함
2.4 Dall-e
그리고 Multi-model LM 중에 지금 현재 가장 sensation 하게 우리에게 충격을 주었던 모델을 소개하도록 하자
자연어로부터 이미지를 생성해내는 모델

이 모델은 Dall-e 라고 하는 모델임
GPT 시리즈를 개발했던 Open-AI 에서 개발했음
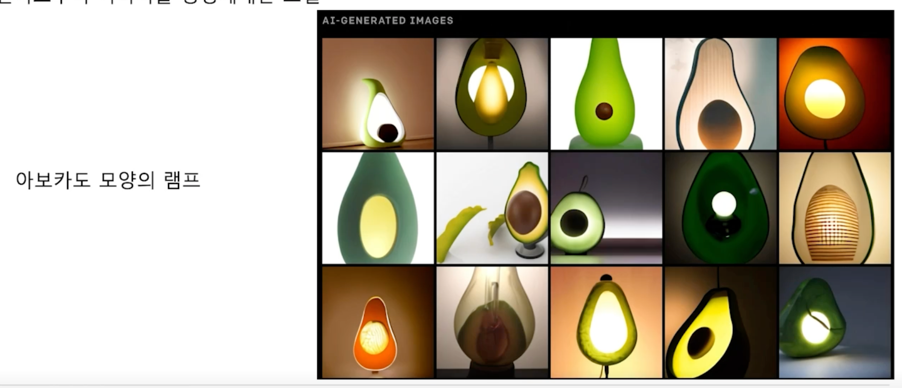
자연어로 “아보카도 모양의 안락 의자” 라고 input 을 주면 아보카도 모양의 이미지를 생성해냄
세상에 존재할 것 같지 않은데 인공지능이 이런 다양한 이미지를 만들어냈다고 함
또 다른 예시로
어떤 식으로 동작하냐면?
-
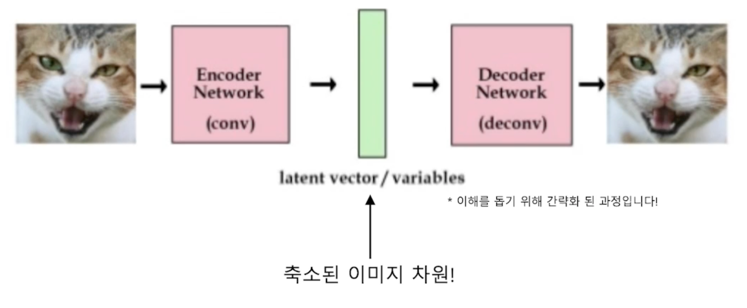
VQ-VAE 를 통해 이미지의 차원 축소 학습
이미지를 생성하기 위해서는 이미지 토큰을 학습해야 하는데 이미지 같은 경우에 256 x 256 이미지만 해도 사이즈가 엄청 커짐
거기에 이미지가 3차원 벡터로 되어있음 그래서 256 x 256 x 3 의 data size 를 가지게 됨
그런데 BERT 만 하더라도 512 토큰으로 되어있고 그거 이상으로 가면 모델사이즈가 어마어마하게 커지게 됨
그러면 기존에 있던 LM 이 256 x 256 x 3 의 엄청난 사이즈를 수용하기 힘들것임
그래서 이 이미지를 차원축소하는 방법으로 조금 작은 사이즈로 만들게 됨
차원 축소 방법은 그림에서처럼 이미지에 대해 Encoder layer 를 태우고 중간에 나오는 latent vector 를 이미지 vector 로 환산을 하게 됨
이해를 돕기 위해 엄청나게 간략화한 과정이고 내부적으로는 더 복잡한 방법을 통해서 latent vector 를 만들어내는 것이 Dall-e 알고리즘이고 VQ-VAE 라는 이름으로 개발되어 있음
이렇게 큰 이미지에 대해 먼저 차원축소를 했고 그 다음은 GPT-2 의 과정과 똑같음
-
Autoregressive 형태로 다음 토큰 예측 학습
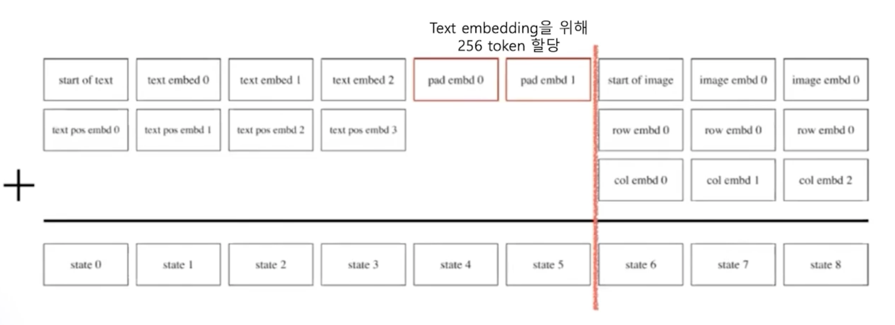
앞 부분에 뭐가 들어가냐면 text 에 대한 encoding 을 진행함
text 토큰이 앞에 들어가고 이 text 를 위해서는 256 토큰을 할당했다고 함
그래서 256 토큰 동안은 반드시 text 가 들어가고 만약에 이걸 못채우면 padding 이 들어감
그 다음은 이미지 vector 를 생성하도록 한 것임
그래서 GPT 와 마찬가지로 text 토큰이 입력으로 들어갔을 때 다음에 이미지 토큰을 생성해내는 방법으로 이미지를 만들어내도록 학습이 됨
이렇게만 학습을 했는데도 자연어로 입력을 했을 때 굉장히 그럴듯한 이미지들을 생성해내는 결과를 볼 수 있었음
그래서 Dall-e 모델도 한국어 모델로 적용해서 실험을 해봤음
한국어 Dall-e 모델 실험
학습 데이터: MSCOCO-2014 (13GB) 모델 사이즈: Dall-e 대비 1/120

COCO 데이터는 이미지에 대해서 서술형으로 이미지에 대한 설명이 적혀있음
“한 남자가 자전거를 타고 내리막길을 내려가고 있다” 이런식으로 서술형의 스크립트가 같이 되어있어서 앞에서 보여드린 과정을 똑같이 Transforemr 를 이용해서 학습을 해본 것임
대신 모델사이즈가 Dall-e 같은 경우는 괴장히 큼 GPT-3 와 맞먹을 만큼
그정도 사이즈로 학습하긴 힘들어서 1/120 으로 사이즈를 줄여서 학습했음
인공지능의 중심, 자연어처리!
이렇듯 최신 인공지능 기술들은 Cross-Modality 를 반영할 수 있는 Multi-modal 기술로 발전되고 있음
이런 발전들은 이제 우리 모두가 꿈꾸는 범용 인공지능의 발전으로 점점 가까이 다가가고 있음
이런 발전의 중심이 자연어처리에 있다고 생각함
댓글남기기