Day_45 01. Huggingface hub 에 모델 공유하기
작성일
Huggingface hub 에 모델 공유하기
1. 사전준비
1.1 Huggingface huv 란?

대규모 오픈소스 커뮤니티로써 사용자들 사이에 손쉽게 NLP 모델을 공유할 수 있음
1.2 설치 및 파일 준비
설치 및 파일 준비
- 설치
pip install transformers==4.1.1
sudo apt-get install git-lfs
- 파일 준비
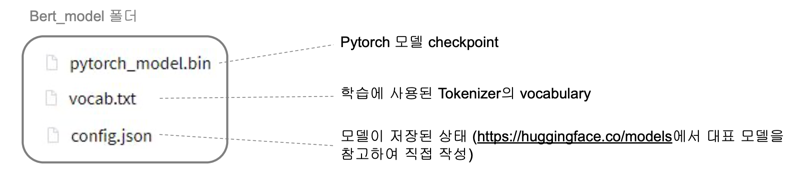
1.3 로그인
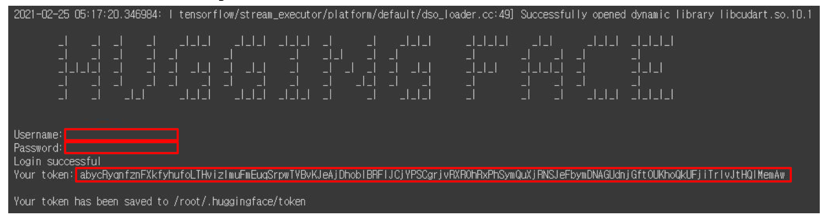
로그인
- Huggingface 회원가입
- https://huggingface.co/
- 커맨드라인에 username 과 password 입력하여 로그인 (token 은 저장소 clone 과정에서 필요)
transformers-cli login
2. 모델 공유하기
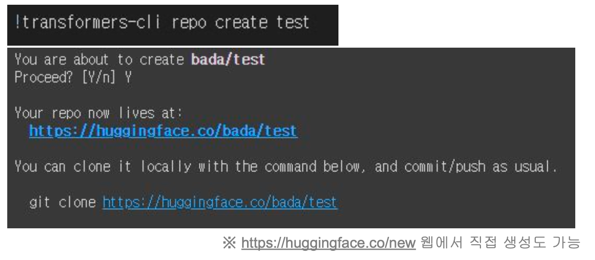
2.1 저장소 생성
Huggingface hub 저장소 생성
- 저장소 생성 명령어 입력
transformers-cli repo create (모델명)
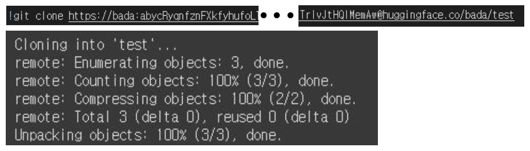
2.2 저장소 Clone
저장소 Clone
- Clone 명령어 입력 (토큰은 로그인 단계에서 생성된 값 이용)
git clone https://사용자이름:토큰@huggingface.co/사용자이름/모델명
- Git user.email 과 user.name 입력
git config --global user.email "huggingface 이메일"git config --global user.name "사용자이름"
2.3 구글드라이브 연동(Colab 사용할 경우)
구글드라이브 연동
- 구글 드라이브 연동 코드 입력
from google.colab import drive
drive.mount('./MyDrive')
-
URL 에서 제시된 인증 코드 입력

-
현재 경로는 내 구글 드라이브경로로 이동
cd MyDrive/My Drive
2.4 공유할 파일 $\rightarrow$ Clone 폴더로 이동
파일 이동
-
Huggingface 공유에 필요한 파일을 Clone 폴더로 이동
mv 공유할 파일 클론폴더경로/

cd 클론폴더경로로 이동

-
파일 확인
ls

2.5 모델 Push
모델 push
- Push 명령어 입력
git lfs install
git add --all
git commit -m "My test model upload"
git push
3. 업로드 모델 확인
3.1 업로드 모델 확인
BERT 모델 확인
- Feature-extraction 파이프라인 inference 확인
from transformers import AutoModel, AutoTokenizer, pipeline
import numpy as np
model = AutoModel.from_pretrained('bada/test')
tokenizer = AutoTokenizer.from_pretrained('bada/test')
feature = pipeline('feature-extraction',
model=model.to('cpu'), tokenizer=tokenizer)
f = np.squeeze(feature('안녕 반가워'))
print(f.shape)

3.2 업로드 모델 확인
GPT 모델 확인
- 해당 예제 GPT 모델은 오픈소스 Tokenizer 사용
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script
.deb.sh | sudo bash
git clone https://huggingface.co/teaminlee/kogpt2
- Feature-extraction 파이프라인 inference 확인
from transformers import AutoModel, AutoTokenizer, pipeline
model = AutoModel.from_pretrained('bada/test_gpt')
tokenizer = AutoTokenizer.from_pretrained('teaminlee/kogpt2')
feature = pipeline('feature-extraction',
model=model.to('cpu'), tokenizer=toknizer)
print(feature)

댓글남기기