Day_42 01. GPT 언어 모델
작성일
GPT 언어 모델
1. 두 문장 관계 분류 task 소개
1.1 GPT 모델 소개
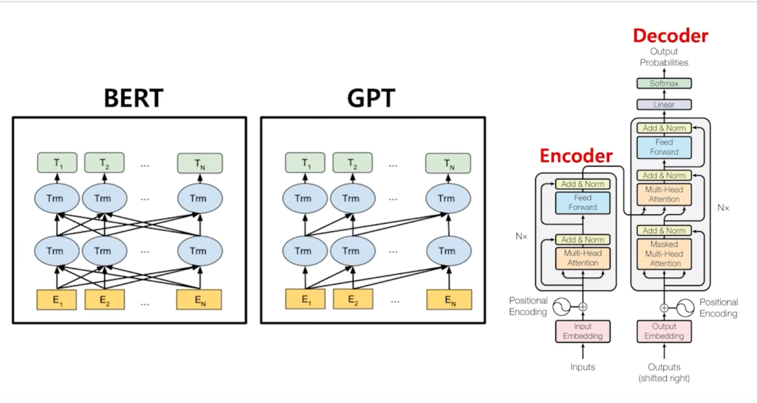
BERT 는 Transformer 의 Encoder 를 사용했고 GPT 는 Transformer 의 Decoder 를 사용한 모델임
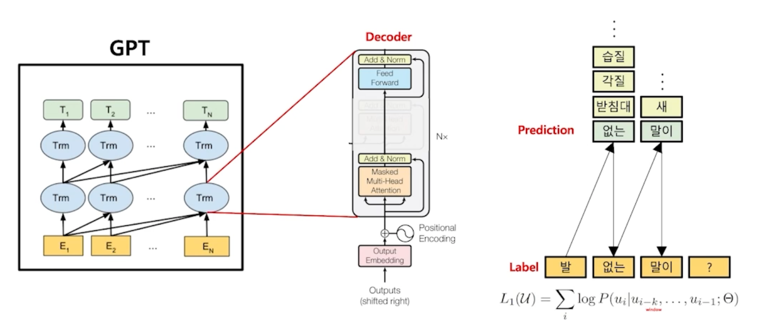
GPT 가 어떻게 언어를 학습을 하냐면?
“발 없는 말이 천리간다” 라는 문장을 학습한다고 가정하자
이 때, “발”이라는 단어가 나왔을 때 이 모델은 다음에 나오기에 가장 적절한 단어가 무엇인지? 어떤 토큰이 가장 적절한지? 를 학습할 수 있음
예를 들어서 “없는” 이 가장 적절한 단어라고 학습하게 되면 “발 없는” 이 나오게 되고 그 다음엔 “발 없는” 다음에 나오기에 가장 적절한 토큰이
어떤 것인지 예측을 하고 그 예측한 것을 통해서 계속해서 자연어를 지속적으로 생성하게 됨
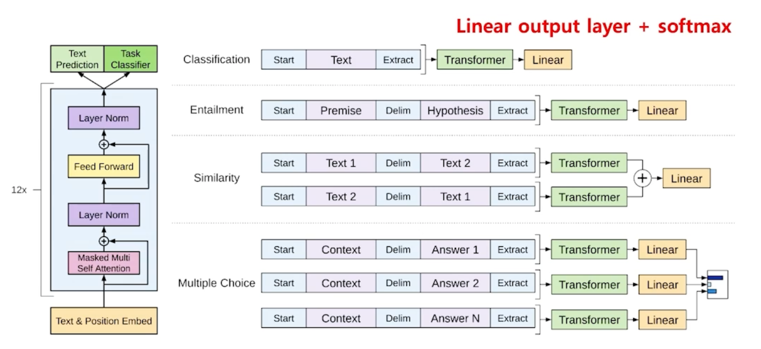
GPT1 모델은 시기적으로 BERT 보다 먼저 나옴
GPT1 모델의 목적은 RNN 과 마찬가지로 기존의 문장이 입력으로 들어갔을 때 그 입력된 것의 context vector 를 출력하고 그 context vector 뒤에
linear layer 를 붙임으로써 분류 task 에 적용하기 위해 설계되었던 모델임
그래서 GPT1 모델의 경우 classification or similarity 를 계산하는 모델이었음
- [자연어 문장 $\rightarrow$ 분류] 성능이 아주 좋은 디코더인 GPT
- 덕분에 적은 양의 데이터에서도 높은 분류 성능을 나타냄
- 다양한 자연어 task 에서 SOTA 달성
- Pre-train 언어 모델의 새 지평을 열었음 $\rightarrow$ BERT 로 발전의 밑거름
- 하지만 여전히, 지도 학습을 필요로 하며, labeld data 가 필수임
- 특정 task 를 위해 fine-tuning 된 모델은 다른 task 에서 사용 불가능
$\rightarrow$ “언어“의 특성 상, 지도학습의 목적 함수는 비지도 학습의 목적함수와 같다! $\rightarrow$ fine-tuning? 필요 없다!!!!!
그런데 GPT 를 개발한 연구진들은 이러한 한계점을 고민을 하다가 이렇게 생각을 하게됨
언어의 특성상 언어의 특성상 우리가 만들고자하는 지도학습의 목적함수가 비지도학습의 목적함수와 같음
그러니까 fine-tuning 에서 만들어지는 목적함수와 pre-trained 모델을 만드는 비지도학습의 목적함수가 같음
무슨말이냐면, 결국에는 fine-tuning 에서 사용되는 label 자체도 그게 하나의 언어라는 것!
예를 들어 감정분석을 보자.
“기쁨”, “슬픔”, “분노” 등이 나올 수 있는데 이 “기쁨”이라는 단어자체가 언어인 것!
“슬픔”이라는 단어 자체도 언어가 됨
그니까 이것을 굳이 fine-tuning 할 필요가 없다라고 여겨지게 됨

엄청 큰 데이터셋을 사용하면 자연어 task 를 자연스럽게 학습!
이 text 에는 영어가 있고 French: 하고 그 영어가 프랑스어로 번역된 예제가 있음
이게 무엇을 의미하냐면?
엄청나게 큰 데이터셋을 사용하면 번역 task 와 같이 자연어 task 들은 자연스럽게 학습할 수 있음

“그는 놀란 마음으로 다음과 같이 말했다.” 라는 sentence 가 제시됨
그러면 “로스트아크에서는 투명 모자가 공짜라고??” 라는 sentence 는 “놀람” 이라는 의미다라는 것을 명확하게 제시하지 않더라도
엄청큰 데이터셋을 통해서 감정에 대한 것까지 자연스럽게 학습할 수 있음
굳이 비지도학습의 과정에서 이루어지는 목점함수랑 fine-tuning 에서 이뤄지는 과정을 구분할 필요가 없다는 것임!
즉, fine-tuning 과정 자체가 필요 없을수도 있음을 가정으로 두게됨
이렇게 GPT1 을 개발한 연구진들은 이 가정을 통해서 다음 모델들을 고안해내게 됨

GPT 를 개발한 연구진들은 다음과 같은 문제점을 제시함
사람은 새로운 task 를 학습하기 위해 수많은 데이터를 필요로 하지 않음
우리가 감정에 대한 것을 분류한다고 가정했을 때 우리가 어떤 데이터 corpus 를 보면서 corpus 의 이 문장은 “놀람”이다라고 tagging 하고
이건 “기쁨”이다라고 tagging 함으로써 배우지 않음
또 다른 문제점으로 pre-trained 모델을 fine-tuning 함으로써 한 모델을 하나의 task 만으로 활용한다는건 이 행동자체가 바보 같다는 것을 제시하게 됨
pre-trained 모델을 만들어내기 위해서는 엄청나게 많은 resource 가 필요함
엄청나게 많은 GPU 도 필요하고 엄청나게 많은 데이터도 필요함
그렇게 만들어진 pre-trained 모델을 fine-tuning 함으로써 한가지의 task 에만 적용할 수 있는 모델을 새롭게 만들고 그걸로 배포를 한다? 라는
행위자체가 자원의 낭비가 될 수 있다라는 것임
그래서 제안한 방법이 바로 Zero-shot, One-shot, Few-shot 방법임
먼저 Fine-tuning 을 살펴보자.
기존의 언어모델은 pre-trained 된 모델이있고 그 다음에 데이터셋을 하나씩 넣어가면서 gradient 를 업데이트 함으로써 한 가지 task 에 점점
fine-tuning 하게 됨
그래서 한국어로는 미세조정이라고 얘기함
large corpus 로 학습한 pre-trained 모델을 점점 미세조정을 하면서 나의 task 에 맞춰가는 과정으로 만들어가게 됨
하지만 GPT 의 연구진들이 제안한 방법은 바로 Zero-shot, One-shot, Few-shot Learning 임
이 각각의 learning 들은 gradient 가 존재하지 않음
각각의 learning 의 차이점은 어떤 inference 를 날릴 때 내가 원하는 task 에 대한 source(힌트) 를 하나만 주느냐, 아예 안주느냐, 혹은 여러개
주느냐의 차이에 있음
그래서 Zero-shot learning 같은 경우에는 내가 만약 번역 task 를 원한다 그러면 “Translate English to French:” 하고 그 다음에
cheese 라고 입력하게되면 다음에 나올 가장 적절한 단어를 GPT 모델이 예측하게 됨
이 경우에 기존의 번역 모델은 이렇게 번역하는 과정을 학습하기 위해서 fine-tuning 하는 과정을 거쳤어야 함
하지만 저자의 생각은 이미 엄청나게 큰 corpus 내에서 이런 식으로 “English to French:” 에서 번역하는 과정을 학습했기 때문에 cheese 다음에
나올 수 있기에 가장 적절한 토큰들을 예측하는 것을 보면 아마도 French 로 번역된 단어가 나올 것이라고 예측할 수 있음
그래서 Zero-shot learning 같은 경우에는 힌트없이 task 를 수행하는 것임
One-shot learning 은 한가지 예시를 주게 됨
그리고 Few-shot 은 여러가지 예시를 주고서 task 를 수행하게 됨
그래서 저자들은 이 아이디어를 바탕으로 GPT2 모델을 개발하게 됨

기존의 GPT 모델은 파라미터수가 117M 개로 되어있었는데 GPT2 의 경우에는 기존의 11GB 의 text 데이터를 40GB 로 늘리고 그리고 학습가능한 파라미터의 개수도 10배로 늘려서 GPT2 를 개발하게 됨
그리고 실제로 GPT2 를 개발하고나서 Zero-shot, One-shot, Few-shot Learning 이 성공적으로 이루어지는 것을 증명하게 됨
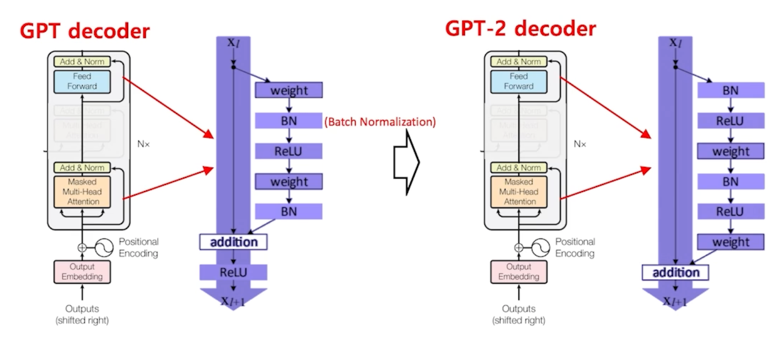
GPT2 는 GPT1 의 Decoder 에서 Decoder 구조만 어느정도 다르게 구성이 되어있음
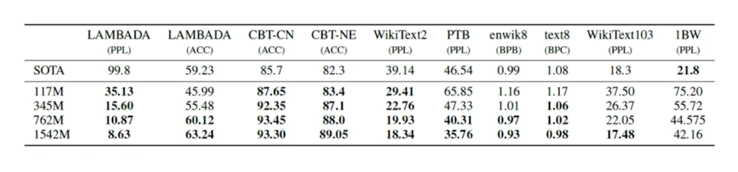
실제로 GPT2 를 이용했을 때
다음 단어 예측 방식에서는 SOTA 성능
기계독해, 요약, 번역 등의 자연어 task 에서는 일반 신경망 수준 $\rightarrow$ 하지만! Zero, One, Few-shot learning 의 새 지평을 제시!

그리고 여기서 연구진들은 멈추지 않았음
GPT3 라는 모델을 만들게 됨
GPT3 는 기존의 파라미터수를 100배 정도로 늘리는 엄청나게 큰 모델을 만들게 됨
사이즈도 늘리고 학습데이터도 기존의 40GB 였던 학습데이터를 570GB 에 달하는 text 데이터를 이용해 학습을 하게됨
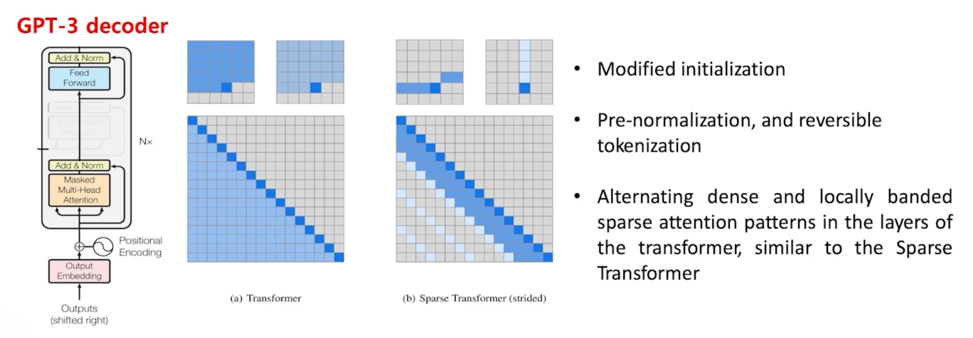
GPT3 역시 Transformer 의 Decoder layer 를 사용했음
하지만 GPT2 랑 같은 Decoder 를 사용한 것은 아니고 약간 다른 구조와 initialize 를 조금 고친 그런 모델로 되어있으나 전체적인 구조자체는 Transformer 의 Decoder 를 사용한 것이 동일함
그래서 모델사이즈를 키우고 학습데이터를 키운 그런 차이점이 있음
이렇게 만든 GPT3 를 이용해서 뉴스 기사를 생성하도록 시켰음

이 때 사람 평가자가 사람이 쓴 뉴스랑 GPT3 가 쓴 뉴스를 구분하는 실험을 해봤는데
Control 는 실제 사람이 쓴 뉴스기사이고 100건의 뉴스기사에 대해 88번의 뉴스기사가 사람같이 썼다고 평가자가 평가했고
GPT3 같은 경우는 100건의 뉴스기사중에 52% 에 달하는 뉴스기사를 직접 사람이 쓴거다라고 평가를 내리게 됨

그리고 GPT3 를 활용해서 Zero-shot, One-shot, Few-shot learning 의 대한 실험도 해봤음
수학적 계산에 대한 실험을 해봄
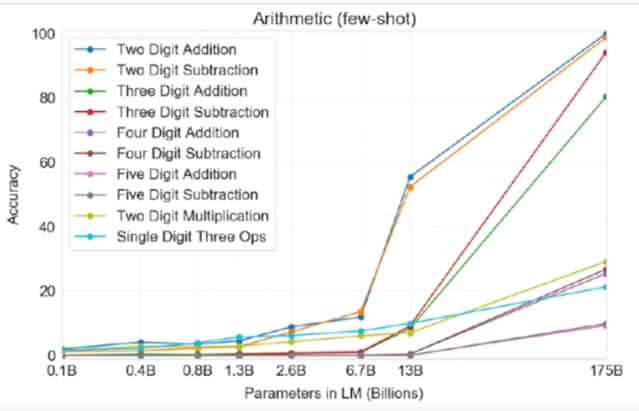
그림에서와 같이 GPT3 가 두개의 숫자를 덧셈하는거에 대해서는 100% 가까운 accuracy 가 나왔다고 함
다음으로 실험한 것은 open domain QA test 를 해봄
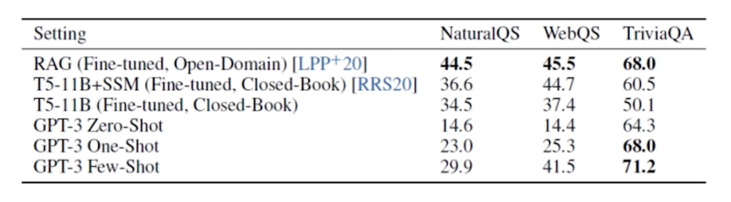
기계독해와 같은 경우에는 정답과 관련된 context 가 input 으로 함께 주어지게 됨
하지만 open domain QA 은 어떤식으로 동작하냐면 그런 문서조차 주어지지 않고 질문을 하게 됨
예를 들어 질문이 “물의 끓는점은 몇도인가?” 이런게 질문으로 들어가게 되면 답변으로 “100도” 이런 답변이 나와야 함
그래서 이런 task 는 모델이 하기에 굉장히 어려운 task 임
이걸 수행하기 위해서는 모델 자체가 상식적인 것과 어려운 지식들 이런게 모두 모델에 녹아있어야지만 답변이 가능함
GPT3 의 Few-shot learning 을 사용했을 때 다른 모델 대비 SOTA 성능이 나옴
1.2 GPT 의 응용



이렇게만 보면 GPT3 가 모든 과제를 다 해결할 수 있을것처럼 보이는데 GPT3 는 한계점이 없을까?
GPT3 역시 다음단어를 예측하는 방식으로 학습한 언어모델임
이렇게 학습하는 것으로 정말 모든 문제가 다 해결이 될까?
GPT3 의 문제는 Weight update 가 없다는 것이 문제가 될 수 있음
그렇다는 것은 새로운 지식에 대한 학습이 없다는 것임
그래서 GPT3 를 학습할 때 사용한 large corpus 내에서만 GPT3 가 답변할 수 있음
그리고 시기에 따라 달라지는 문제에도 대응할 수 없음
예를 들어 GPT3 한테 “한국의 대통령이 누구야?” 라고 질문하게되면 “이명박 대통령” 이라고 답변이 나오는 것을 확인할 수 있었음
하지만 대통령이라는 존재는 시기에따라서 달라짐
그 말은 GPT3 같은 언어모델도 새로운 데이터에 대한 updqte 가 반드시 필요하다는 것임
또 한편으로는 모델 사이즈와 학습데이터만 계속해서 키우면 모든 문제가 해결될까?
정답은 알 수 없지만 그렇게 생각하지는 않음
뭔가 다른 방향의 연구도 필요하다고 생각함
또한 GPT3 는 글로만 세상을 배우게 됨
하지만 우리가 세상을 인지할 때는 우리의 감각기관을 모두 사용해서 인지를 하게됨
그래서 반드시 언어모델은 단순히 witten language(text 로 된 데이터)만 학습하는 것이 아니라 멀티 모달 에 대한 정보도 학습이 필요할 것이라고 생각함

실습
GPT-2 학습해보기
한국어 코퍼스를 활용해 한국어 GPT-2 모델을 만들 예정
학습데이터는 wiki 데이터를 이용해서 실습하도록 하겠음
path = "/content/my_data/wiki_20190620_small.txt"
기존에는 BERT 를 학습할 땐 BertWordPieceTokenizer 를 사용했음
이번에는 SentencePieceBPETokenizer 를 사용하도록 하겠음
내부적인 알고리즘은 BPE 로 동일하고 tokenizer 의 경우에는 띄어쓰기 부분에 ‘_’ 기호를 추가하는 과정만 다르다고 생각하면 됨
from tokenizers import SentencePieceBPETokenizer
from tokenizers.normalizers import BertNormalizer
tokenizer = SentencePieceBPETokenizer()
tokenizer._tokenizer.normalizer = BertNormalizer(clean_text=True,
handle_chinese_chars=False,
lowercase=False)
tokenizer.train(
path,
vocab_size=10000,
special_tokens=[
"<s>",
"<pad>",
"</s>",
"<unk>",
],
)
마찬가지로 tokenizer 학습을 해줌
학습데이터와 vocab_size 를 지정해줄 수 있음
BERT 와 다른점이 하나 있는데 BERT 는 학습할 때 앞에 [CLS] 토큰과 뒤에 [SEP] 토큰을 부착하게 되어있었음
그렇기 때문에 special token 에 [PAD], [CLS] [SEP], [UNK] 들이 의무적으로 들어갔었음
하지만 GPT2 가 학습하는 과정을 상상해보면 앞에 토큰이 나왔을 때 계속해서 다음 토큰을 예측하는 방식으로 이루어지고 있음
그래서 [CLS] 토큰이나 [SEP] 토큰이 필요하지 않음
하지만 이 경우에 fasttext 도 상상해보면 음절의 시작과 긑을 표시해주는 “<”, “>” 기호 넣은것이 생각나나요?
역시 GPT2 도 문장의 끝과 시작을 표시해주는 special token 을 부착해줄 수 있음
그래서 나중에 생성할 때 문장단위로 생성하도록 control 할 수 있음
special token 에 문장의 시작을 의미하는 <s> 와 문장의 끝을 의미하는 </s> 를 추가해줄 수 있음
tokenizer 를 학습했으니 test 를 해보자.
print(tokenizer.encode("이순신은 조선 중기의 무신이다."))
print(tokenizer.encode("이순신은 조선 중기의 무신이다.").ids)
print(tokenizer.encode("이순신은 조선 중기의 무신이다.").tokens)
print(tokenizer.decode(tokenizer.encode("<s>이순신은 조선 중기의 무신이다.</s>").ids, skip_special_tokens=True))
# SentencePiece를 사용하면, 나중에 decoding 과정에서 '_' 만 ' '로 replace해주면 띄어쓰기 복원이 가능해집니다.

문장에서 띄어쓰기가 들어가는 부분 즉, 어절의 시작부분에는 ‘_’ 기호가 부착이됨
이 문장을 복원하라고 하면 올바르게 복원이 됨
tokniezr 를 저장할 땐 아래 명령어를 사용함
tokenizer.save_model(".")

나만의 tokenizer 가 만들어졌음
tokenizer = SentencePieceBPETokenizer.from_file(vocab_filename="vocab.json", merges_filename="merges.txt")
from_file() 함수를 사용하면 내가 학습한 모델을 그대로 불러와서 tokenizer 로서 사용할 수 있음
print(tokenizer.encode("이순신은 조선 중기의 무신이다."))
print(tokenizer.encode("이순신은 조선 중기의 무신이다.").ids)
print(tokenizer.encode("이순신은 조선 중기의 무신이다.").tokens)
print(tokenizer.encode("<s>이순신은 조선 중기의 무신이다.</s>").tokens)
print(tokenizer.decode(tokenizer.encode("<s>이순신은 조선 중기의 무신이다.</s>").ids, skip_special_tokens=True))

불러와서 test 해보면 동일한 결과를 확인할 수 있음
우리가 원하는 것은 문장의 시작과 끝에 <s>, </s> 를 부착함으로써 문장을 구분해내는 것을 원하고 있음

그런데 이렇게 다 분리되서 나옴
이 이유는 special token 으로 지정이 되어있지 않음
의도적으로 tokenizer 에 add_special_tokens 를 통해 명시적으로 알려줘야 함
tokenizer.add_special_tokens(["<s>", "</s>", "<unk>", "<pad>", "<shkim>"])
tokenizer.pad_token_id = tokenizer.token_to_id("<pad>")
tokenizer.unk_token_id = tokenizer.token_to_id("<unk>")
tokenizer.bos_token_id = tokenizer.token_to_id("<bos>")
tokenizer.eos_token_id = tokenizer.token_to_id("<eos>")
print(tokenizer.encode("<s>이순신은 조선 중기의 무신이다.</s>").ids)
print(tokenizer.encode("<s>이순신은 조선 중기의 무신이다.</s>").tokens)
print(tokenizer.decode(tokenizer.encode("<s>이순신은 조선 중기의 무신이다.</s>").ids, skip_special_tokens=True))

이렇게 등록하고 나면 문장내에 스페셜 토큰을 부착하게 되더라도 올바르게 tokenizing 된 것은 확인할 수 있음
이제 본격적으로 GPT2 를 학습해야 함
from transformers import GPT2Config, GPT2LMHeadModel
# creating the configurations from which the model can be made
config = GPT2Config(
vocab_size=tokenizer.get_vocab_size(),
bos_token_id=tokenizer.token_to_id("<s>"),
eos_token_id=tokenizer.token_to_id("</s>"),
)
# creating the model
model = GPT2LMHeadModel(config)
transformers 에서 BERT 와 마찬가지로 GPT2 에 대해서도 학습을 제공해줌
GPT2 에 대한 껍데기 모델을 만들어야 함
항상 vocab_size 를 우리가 만든 tokenizer 의 vocab_size 로 명확하게 지정해줘야 함
bos_token(문장의 시작을 알려주는 토큰) 과 eos_token(문장의 끝을 알려주는 토큰)을 어떤 것으로 정의했는지 명확하게 저장할 수 있음
다양한 옵션들이 많아서 layer size 를 줄일 수도 있고 내부의 embedding size 도 줄일 수 있고 다양한 설정을 할 수 있음
model.num_parameters()
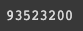
파라미터 개수도 알 수 있음
GPT2 에 넣어줄 데이터셋도 만들어야 함
import json
import os
import pickle
import random
import time
import warnings
from typing import Dict, List, Optional
import torch
from torch.utils.data.dataset import Dataset
from filelock import FileLock
from transformers.tokenization_utils import PreTrainedTokenizer
from transformers.utils import logging
logger = logging.get_logger(__name__)
class TextDataset(Dataset):
"""
This will be superseded by a framework-agnostic approach soon.
"""
def __init__(
self,
tokenizer: PreTrainedTokenizer,
file_path: str,
block_size: int,
overwrite_cache=False,
cache_dir: Optional[str] = None,
):
assert os.path.isfile(file_path), f"Input file path {file_path} not found"
block_size = block_size - tokenizer.num_special_tokens_to_add(is_pair=False)
directory, filename = os.path.split(file_path)
cached_features_file = os.path.join(
cache_dir if cache_dir is not None else directory,
"cached_lm_{}_{}_{}".format(
tokenizer.__class__.__name__,
str(block_size),
filename,
),
)
# Make sure only the first process in distributed training processes the dataset,
# and the others will use the cache.
lock_path = cached_features_file + ".lock"
with FileLock(lock_path):
if os.path.exists(cached_features_file) and not overwrite_cache:
start = time.time()
with open(cached_features_file, "rb") as handle:
self.examples = pickle.load(handle)
logger.info(
f"Loading features from cached file {cached_features_file} [took %.3f s]", time.time() - start
)
else:
logger.info(f"Creating features from dataset file at {directory}")
# 여기서부터 본격적으로 데이터셋을 만들기 시작합니다.
self.examples = []
text = ""
with open(file_path, encoding="utf-8") as f:
lines = f.readlines()
for line in lines:
line = line.strip()
line = "<s>"+line+"</s>" # 학습 데이터 앞 뒤에 문장 구분 기호를 추가해줍니다.
text += line # 'text' 객체에 모든 학습 데이터를 다 합쳐버립니다 :-)
tokenized_text = tokenizer.encode(text).ids
# 모델의 최대 sequence length만큼 데이터를 잘라서 저장합니다.
for i in range(0, len(tokenized_text) - block_size + 1, block_size): # Truncate in block of block_size
self.examples.append(
tokenized_text[i : i + block_size]
)
# Note that we are losing the last truncated example here for the sake of simplicity (no padding)
# If your dataset is small, first you should look for a bigger one :-) and second you
# can change this behavior by adding (model specific) padding.
start = time.time()
with open(cached_features_file, "wb") as handle:
pickle.dump(self.examples, handle, protocol=pickle.HIGHEST_PROTOCOL)
logger.info(
"Saving features into cached file %s [took %.3f s]", cached_features_file, time.time() - start
)
def __len__(self):
return len(self.examples)
def __getitem__(self, i) -> torch.Tensor:
return torch.tensor(self.examples[i], dtype=torch.long)
GPT2 모델은 BERT 학습보다 훨씬 간단함
mask 의 대한 개념도 없었고 Next Sentence Prediction 도 필요하지 않음
그냥 우리가 학습해야하는 sentence 를 통채로 주면 GPT 모델이 이 토큰 다음에 나올 수 있는 토큰은 이거다 다음은 이거다 라는 것을 순차적으로 자동으로 학습하게됨
그래서 sentence 만 만들어줘서 GPT 모델에 넘겨주면 됨
캐싱 관련된 부분을 지나서 file_path(wiki small 데이터) 를 한줄씩 읽어서 strip() 해주고 의도적으로 line 앞뒤에 <s>, </s> 를
넣어주게 됨 그리고 text 라는 하나의 변수에 모든 학습데이터를 통채로 넣게 됨
text 안에 기존의 wiki 데이터와 동일하지만 모든 문장마다 <s>, </s> 이 부착된 형태로 text 가 만들어짐
그 만들어진 것을 tokenizing 하면 tokenizer 에 따라서 vocab_id 로 변환된 데이터가 tokenized_text 로 입력으로 들어가게 됨
그러면 내가 가진 모델의 sequence length 가 있을 건데 BERT 는 512 토큰이 있었고 GPT2 도 그런 block_size 를 가질텐데
tokenized_text 데이터는 전체 wiki 의 데이터를 다가지고 있으니 이거를 block_size 만큼으로 쪼개게 됨
toknized_text[i : i + bolck_size] 로 쪼개서 exmaples 에 넣게 됨
다 넣게되면 우리가 원하는 학습데이터가 완성됨
dataset = TextDataset(
tokenizer=tokenizer,
file_path=path,
block_size=128,
)
from transformers import DataCollatorForLanguageModeling
data_collator = DataCollatorForLanguageModeling( # GPT는 생성모델이기 때문에 [MASK] 가 필요 없습니다 :-)
tokenizer=tokenizer, mlm=False,
)
TextDataset 에 tokenizer, file_path, block_size 넣고 만들어 줌
실습을 위해 block_size 를 128 로 줬지만 원래 사이즈는 1024 로 알고 있음
이렇게 데이터셋인 밥이 만들어지면 떠먹여주는 데이터로더가 필요함
transformers 에서 DataCollatorForLanguageModeling 이라는 함수를 제공해주고 있음
이전에는 data_collator 를 mask 를 지원해주는 기능을 넣었었는데 이번에는 mask 가 필요없음
그래서 LanguageModeling 을 위한 함수를 불러왔음
이 함수를 call 할 때 mlm 은 mask 를 의미하는 건데 GPT2 는 mask 가 필요없으므로 False 로 두고 데이터셋을 만들면
print(dataset[0])
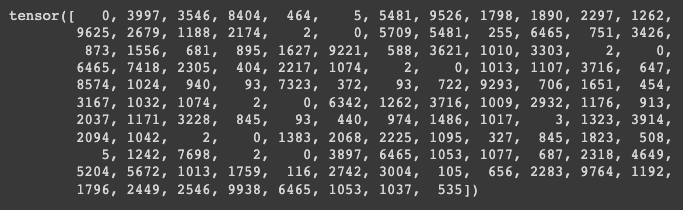
학습을 위한 데이터셋이 만들어지게 됨
동일하게 TrainArgument 에 우리가 원하는 argument 를 채워주게 됨
from transformers import Trainer, TrainingArguments
training_args = TrainingArguments(
output_dir='model_output',
overwrite_output_dir=True,
num_train_epochs=50,
per_device_train_batch_size=64, # 512:32 # 128:64
save_steps=1000,
save_total_limit=2,
logging_steps=100
)
trainer = Trainer(
model=model,
args=training_args,
data_collator=data_collator,
train_dataset=dataset
)
trainer.train()
BERT 와 마찬가지로 굉장히 쉽게 GPT2 도 학습할 수 있음
trainer.save_model()
모델 저장도 같은 방법으로 할 수 있음
학습을 했으니 test 를 해야죠?
USE_GPU = 1
# Device configuration
device = torch.device('cuda' if (torch.cuda.is_available() and USE_GPU) else 'cpu')
import torch
torch.manual_seed(42)
input_ids = torch.tensor(tokenizer.encode("<s>이순신", add_special_tokens=True).ids).unsqueeze(0).to('cuda')
output_sequences = model.generate(input_ids=input_ids, do_sample=True, max_length=100, num_return_sequences=3)
for generated_sequence in output_sequences:
generated_sequence = generated_sequence.tolist()
print("GENERATED SEQUENCE : {0}".format(tokenizer.decode(generated_sequence, skip_special_tokens=True)))
테스트를 할 때는 GPT2 모델 같은 경우에 generate 라는 특별한 함수를 제공해주고 있음
다음 실습에서는 generate 함수에 대한 분석을 보여주겠음
간단히 설명하자면 입력값이 들어가고 GPT2 가 단어를 생성하기에 앞서서 앞에 무슨 단어를 시작으로 할 것이냐를 input_ids 로 넣게 됨
input_ids 이기 때문에 당연히 tokenize 된 vocab_id 가 들어가게 됨
뒷부분에 대해서는 다음 포스팅에서 설명하겠음
do_sample=True 면 sample 을 몇개 반환하라는 의미

작성자
* 김성현 (bananaband657@gmail.com) 1기 멘토 김바다 (qkek983@gmail.com) 박상희 (parksanghee0103@gmail.com) 이정우 (jungwoo.l2.rs@gmail.com) 2기 멘토 박상희 (parksanghee0103@gmail.com) 이정우 (jungwoo.l2.rs@gmail.com) 이녕우 (leenw2@gmail.com) 박채훈 (qkrcogns2222@gmail.com)
댓글남기기