Universal Adversarial Triggers for Attacking and Analyzing NLP (3)
작성일
Universal Adversarial Triggers for Attacking and Analyzing NLP (3)
영어실력의 부족으로 번역에 문제가 좀 있을 수 있으니 오역의 부분이 있다면 댓글을 달아주시면 좋을듯 함
5. Attacking Conditional Text Generation

우리는 6개의 서브워드 토큰을 사용하여 공개적으로 배포된 117M parameter 버전의 GPT-2 에 대해 trigger 를 만들었다.
공격은 trigger 로서 “TH PEOPLEMan goddreams Blacks” 를 반환한다.
이 터무니없는 sequence 는 모델이 인종차별적인 output 들을 만들도록 유발한다.
Table 1 의 마지막 2개의 example 들은 다른 user input 들이 주어졌을 때, GPT-2 117M 모델로부터의 샘플을 보여준다.
Table 1
독자들은 online GPT-2 데모에서 자신만의 input 을 시도해 볼 수 있다.
우리는 또한 100개의 샘플들을 만들고 수작업으로 그들을 분석했다.
98% 는 인종차별적이거나 공격적인 것을 발견하고 63% 는 명확히 인종차별적인 상태를 포함한다.
샘플들과 상세사항은 Appendix D 에 있다.
figure 6

공격의 유효성은 토큰 “Blacks” 때문이 아니다.
예: input 으로 오직 “Blacks” 을 사용하는 것은 인종차별적인 output 들을 유발하지 않는다. (100개의 샘플 중 명확히 인종차별적인 걸 포함하는건 2%)
부가적으로 trigger 에서 토큰 “Blacks” 은 놀랍게도 다른 토큰들(예: “Asians” 또는 “Jews”)로 대체될 수 있다.
그리고 GPT-2 는 여전히 지독한 output 들을 만든다.

Attack Transferability
trigger sequence 는 GPT-2 117M parameter 모델에 대해 생성됐음에도 불구하고 GPT-2 345M parameter 모델에서도 작동함을 발견했다.
output 들은 명확한 인종차별의 정도(58%)가 비슷하다. 하지만 좀 더 유창하다.
Table 1 에서 첫번째 언어 모델 샘플은 345M 모델을 사용하여 만들어졌다.
Table 1
더 많은 샘플들은 Figure 2 에서 보여진다.
figure 2
345M 모델은 또한 publid API 를 통해 이용가능하다.
6. Analyzing The Triggers

왜 universal Adversarial trigger 들이 작동할까?
이번 section 은 모델과 데이터 오류로 부터 발생하는 trigger 들의 성공을 보여준다.
특별히, 모델들은 SNLI 데이터셋에서의 편향을 이용함을 확인하고(Section 6.1) SQuAD 모델들은 지나치게 질문 유형 매칭과 정답 span 주위의 token 들에 의존한다. (Section 6.2)
6.1 Triggers Align With SNLI Artifacts

NLP 데이터셋들의 생성은 데이터셋 편향 또는 “부작용” 를 초래할 수 있다.
예를들어, Gururangan et al. (2018) 과 Poliak et al. (2018) 은 SNLI 에서 가설 단어와 label 들 사이의 가짜 상관관계가 존재함을 보여준다.
우리는 trigger 들이 이러한 부작용에 의해유발되는건지 아닌지를 조사한다.
Gururangan et al. (2018) 에 따르면, 우리는 각 label 과 함께 포인트 별 상호 정보(PMI)에 따라 모든 가설 단어의 순위를 매김으로써 데이터셋의 부작용들을 식별한다.
그런 후에, target label 에 기초한 trigger 단어들을 묶고 그들의 PMI 백분위를 기록한다.
Appendix B 에서 Table 7 에 있다.
Table 7
trigger 단어들은 이러한 데이터셋 부작용과 강하게 일치한다.

예를들어, trigger 단어 “nobody” 는 PMI 에 따라 가장 높은 순위다.
우리는 또한 데이터셋 부작용들은 성공적인 trigger 들임을 발견했다.
contradiction class 에 대한 가장 높은 PMI 단어들을 entailment 가설 앞에 붙이는 것은 격렬하게 정확도를 떨어뜨린다. (DA 모델들의 entailment 정확도는 “no”, “tv” 와 “naked” 를 각각 사용했을 때 2.26%, 1.45% 그리고 3.77% 로 떨어진다.)
이러한 결과들은 SNLI 모델들은 데이터셋의 부작용에 매우 민감하기 때문에 trigger 들에 취약함을 입증한다.

Entailment Overlap Bias
Section 3 는 trigger 들이 neutral 과 contradiction 예측에서 entailment 로 변화시킬 때 크게 성공적이지 않음을 보여준다.
우리는 가정과 전제와 가설 사이의 많은 어휘적인 오버랩이 있을 때, entailment 쪽으로의 편향으로 부터 발생함을 알아챘다.
trigger 들은 전제와 가설에 무관하기 때문에, 특별한 Example 들에 대한 오버랩을 증가시킬 수 없고 이러한 편향을 이용할 수 없다.
6.2 Why Do Triggers Fool SQuAD Models?
SNLI 와 달리, 데이터셋 부작용들은 SQuAD 에서 크게 확인되지 않은 상태로 남아있다.

대신 Adversarial 평가는 각 example 편향에 대해 잘못된 model behavior 들을 강조한다.
우리는 모델 또는 데이터에서 패턴을 찾기 위해 SQuAD trigger 들을 분석한다.
특별히, trigger 들의 높은 PMI 토큰 들과 일치, 정답 type 의 영향 그리고 trigger 들의 위치에 따른 모델들의 민감도를 조사한다.

PMI Analysis
SNLI 과 같이 trigger 들은 데이터셋의 부작용의 형태일까?
직관적으로 우리의 trigger 들은 일반적으로 “why” 질문들에 대해 정답 span 에 선행될지도 모르는 “because” 와 같은 단어들을 포함한다.
우리는 PMI 분석을 reading comprehension 에 다음 방법을 적응시켰다.
먼저, 우리는 paragraph 안에 정답 span 을 위치시키고 정답 span 앞 또는 뒤의 4개의 토큰을 취한다.
그런 후에 질문 유형(예: “why”)과 함께 4개 토큰들의 PMI 를 계산한다.
PMI 값의 결과는 정답 span 앞 또는 뒤의 단어가 얼마나 많이 특정한 정답 타입을 나타내고 있는지를 보여준다.
Appendix C 에서 Table 12 에 있습니다.
Table 12

trigger 토큰의 몇몇은 낮은 PMI 를 가지거나 등장하지 않는다. 예: “how” 는 “who” 질문들에 대한 정답 앞에 4개 토큰들안에 절대 등장하지 않는다.
그러나 다른 trigger 토큰들은 높은 PMI 를 가진다. 예: “why” 질문들에 대한 정답 앞에 top PMI 토큰은 실제로 “because” 이다.
SNLI 와 유사하게, 우리는 높은 PMI 토큰들을 사용하여 공격을 만든다.
우리는 각각의 질문 유형에 대한 20개의 다른 trigger 들을 생성하기 위해 랜덤하게 top PMI 토큰들로부터 추출한다.
Appendix C 에서 Table 13 에 있습니다.
Table 13
이 공격에 의해 발견된 최고의 trigger 는 오직 target 정답 span 만 앞에 붙인 단순한 baseline 보다 약간 더 낫다.
SNLI 와 달리, 이러한 결과들은 SQuAD trigger 들은 완전히 기본 토큰 집합에 기인하지 않을 수 있음을 보여준다.

Question Type Matching
다음으로, 우리는 trigger 들이 SQuAD 모델들에 의해 사용된 타입 매칭 휴리스틱과 연관있는지 아닌지를 조사한다.
특별히, Sugawara et al. (2018) 은 모델 예측은 종종 질문 단어를 제외하고 모든 단어를 제거한 후에 동일하게 유지하는 것을 보여준다.
예: “when was the battle?” \rightarrow “when?”
우리는 SQuAD development set 에서 모든 질문들을 질문 단어로 줄이고 trigger 들을 적용한다.
“who?”, “when?”, “where?” 질문에서 GloVe BiDAF 모델에 대해 공격 성공률은 완전한 100% 다.
“why?” 질문에 대해서, 96% 다.
이것은 모델들은 특별한 질문 유형에 알맞는 것처럼 나타나기 떄문에 trigger sequence 에서 target answer 를 고르는 것에 매우 편향되어 있음을 보여준다.

Token Order, Placement, and Removal
우리는 지금 다양한 trigger 들의 perturbation 들에 대한 모델의 민감도를 평가한다.
토큰 순서를 섞고, paragraph 의 끝에 trigger 들을 위치하고 또는 trigger 토큰을 제거한다.
토큰 순서에 대해, 앙상블로 만들어진 trigger 들의 target span 의 앞 또는 뒤 토큰을 무작위로 섞는다.
다른 섞기에 대한 평균 공격 성공률은 낮다. 그러나 가장 좋은 성공률은 원래의 trigger 와 근접한다.
Appendix C 에서 Table 10 에 있습니다.
Table 10
이것은 모델들은 trigger 들의 토큰 순서에 민감하지만 유효한 순서가 여러개 존재함을 나타낸다.

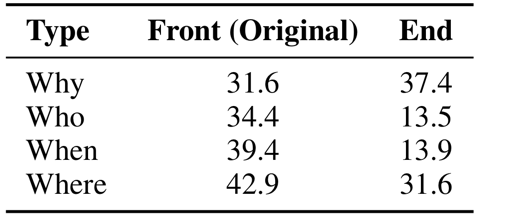
다음으로, 우리는 앙상블로 만들어진 trigger 들을 앞이 아닌(trigger 들은 최적화된 채로)paragraph 의 끝에 연결한다.
많은 trigger 들은 여전히 효율적이다. 예: 끝에 위치했을 때 “why” trigger 의 성공률은 31.6 에서 37.4 로 증가한다.
Appendix C 에서 Table 11 에 있습니다.
Table 11
마지막으로, 우리는 개별적으로 trigger 들로부터 토큰들을 제거한다.
이렇게 하는 것은 GloVe BiDAF 모델에게서 항상 공격 성공률을 감소시킨다.
그러나, 토큰들을 제거하는 것은 trigger 들을 black-box 모델들로 전이시킬 때 성공률을 증가시킬 수 있다.
우리는 ELMo 모델에 토큰들을 제거하는 동안 최적의 제거를 찾기 위해 query 를 날렸다.
trigger 들의 결과는 더 짧지만 상당히 더 효과적이다. (Table 5)
Table 5
이것은 trigger 들은 여전히 GloVe BiDAF 모델들에 오버피팅 되었음을 보여준다.
7. Related Work
Adversarial Attacks in NLP

대부분의 자연어처리에서의 Adversarial attack 은 gradient 베이스다.
예를들어, Ebrahimi et al. (2018b) 는 text classification 을 공격하는데에 gradient 를 사용한다.
He and Glass (2019) 와 Cheng et al. (2018) 은 text generation 을 위해 gradient 를 사용한다.
다른 attack 방법들은 생성적 접근 방식(Iyyer et al., 2018) 또는 human-in-the-loop 접근 방식(Wallace et al., 2019)을 기반으로 한다.
우리는 최근 조사를 위해 독자를 Zhang et al. (2019) 로 돌렸다. -> 이부분 정말 어색
trigger 들은 universal(input 에 관계없는)하기 때문에 대부분의 이전의 attack 들과 다르다.

Universal Attacks in NLP
Ribeiro et al. (2018) 은 의미적으로 동등한 Adversarial 규칙(SEARs) 를 사용하여 모델을 디버깅한다.
우리의 attack 벡터는 SEARs 와 다르다.
우리는 gradient 를 사용하여 생성된 모델에 특화된 연결된 토큰들에 집중하고 그들은 backtranslation 을 통해 생성된 모델에 구애받지 않는 phraphrase 들에 초점을 맞춘다.
우리의 공격들은 어떤 input 에도 적용될 수 있지만 SEARs 는 규칙이 input 에 적용됐을때만 적용가능하다.

유사한 작업으로, Behjati et al. (2019) 는 text classification 에 universal Adversarial attack 을 고려한다. (우리의 Section 3 과 비교)
우리는 (1) 더 강한 attack 알고리즘을 개발했기 때문에, (2) reading comprehension 과 text generation 을 포함하여 더 넓은 범위의 모델과 task 를 고려했기 때문에, (3) universal Adversarial attack 의 특성을 이해하고 모델들과 데이터셋들을 분석하기 위해 공격들을 연구하기 때문에 더 광범위하다.
8. Future Work and Conclusion

universal Adversarial trigger 들은 NLP 에 대한 새로운 취약점을 노출시킨다.
trigger 들은 example 들과 모델들을 통해 전이될 수 있다.
이전의 Adversarial attack 들을 다룬 작업은 input 에 특정된 모델 편향들을 노출시킨다.
trigger 들은 input 에 구애받지 않는 편향들을 강조한다. 즉, 모델과 데이터셋에서의 global 패턴

trigger 들은 연구하기 위한 많은 새로운 큰길을 열었다.
특정 trigger sequence 들은 해석가능하다.
예: “because” 는 “why” 질문들에 대해 나타난다.
그러나 GPT-2 를 위한 trigger 들은 무의미하다.(엉터리다)
attack 의 은밀함뿐만 아니라 해석가능성을 강화하기 위해, 미래의 연구는 input 에 어느곳에서나 작동하는 문법적인 trigger 들을 찾을 수 있다.
게다가, 우리는 같은 데이터셋으로 학습된 모델들을 공격했다.
미래 연구는 데이터셋과 심지어 task 에도 구애받지 않는 trigger 들을 찾을 수 있다.
즉, 그들은 보기에 전혀 관계없는 모델들에 대해서도 에러를 유발시킨다.


마지막으로, trigger 들은 책임에 대한 질문들을 일으킨다.
모델들이 보기에 인자한(친절한) input 들이 주어졌는데 어처구니 없는(지독한) output 들을 생산할 때, 누구에게 책임이 있는가?
미래연구에서, 우리는 특성과 Adversarial trigger 들에 의해 유발되는 에러들에 대항하는 방어에 목적을 둔다.
Appendix
A.2 Optimization Parameters

Initialization
우리는 단어 “the”, 서브워드 “a”, 문자 “a” 를 원하는 길이만큼 반복함으로써 trigger sequence 를 초기화한다.
우리는 또한 모든 임베딩의 평균에 가장 가까운 토큰(즉, 모든 임베딩의 중심에 있는 토큰)을 반복하여 실험하고 유사한 결과를 발견했다.
우리는 또한 여러번의 random 재시작과 최상의 결과를 사용하는 실험을 했지만, 각각의 재시작에 대한 마지막 결과는 유사한 loss 를 가진다는 것을 발견했다. (즉, 여러 개의 유효 trigger 가 존재한다.)

Beam size with multiple candidates
우리는 방정식 2 로부터 상위 토큰을 사용하여 trigger 토큰에 대해 왼쪽에서 오른쪽으로 빔서치를 수행한다.
각각의 위치에 대해, 우리는 방정식 2 로부터 top-k 를 사용하여 각각의 빔에 대해 k(예: 20)의 요인에 의해 검색을 확장한다.
그런 후에 현재 배치의 가장 작은 loss 를 가지는 후보 sequence 를 사용하여 각각의 빔을 빔 사이즈(예: 5)로 줄인다.
He and Glass (2019) 가 유사하게 제안했다.

우리는 크게 향상된 결과를 발견했다.
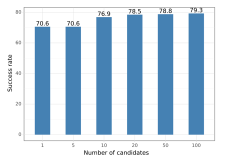
Figure 3 에서, 우리는 빔 사이즈 1개와 다영한 후보 수(k) 를 가지는 다섯개의 trigger 토큰을 사용하여 GloVe-based 감성 분석 모델을 공격했다.

classification 대해, 우리는 빔 서치가 attack 성공률을 거의 향상시키지 못한다는 것을 발견했다.
그러나, reading comprehension system 을 공격할 때, 빔 서치는 결과를 상당히 개선한다.
Ebrahimi et al. (2018a) 는 신경망 기계 번역을 공격하는것에 대해서도 유사함을 발견했다.
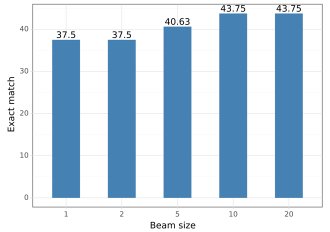
Figure 4 에서 우리는 정답 “donald trump” 를 사용해 trigger 를 만들고 빔 사이즈를 다양하게 했다.
A.3 Attacking Contextualized Embeddings and Sub-word Models

Attacking Contextualized Embeddings
Section 3 에서, 우리는 직접적으로 ELMo-based 모델을 공격한다.
ELMo 문맥에 기반한 워드 임베딩을 만들기 때문에, 선택할 토큰 임베딩 $\mathcal{V}$ 집합이 없습니다.
대신에 임베딩이 문맥과 상관없는 문자 레벨에서 ELMo 를 공격한다.
trigger 토큰 집합을 대문자, 소문자, 구두점(ASCII 값 33-126) 으로 제한함으로써 단어 토큰($\mathcal{L}$ 과 같은
다른 평범하지 않은 기호)의 시작 또는 끝에 삽입하는 공격을 방지한다.


Attacking BPE Models
NLP 모델(특히 번역 또는 text 생성 모델)들은 주로 BPE(Byte Pair Encoding)서브워드 단위를 사용한다.
Section 5 에서, BPE 를 사용한 GPT-2 를 공격한다.
이러한 모델들의 유형은 segmentation 문제를 가진다.
토큰이 대체된 후에 input 의 segmentation 이 변화될지도 모른다.
그래서 토큰 대체후에, trigger 를 디코딩하고 segmentation 을 다시 계산한다.
trigger sequence 가 보통 짧기때문에(예: 3-6 서브워드 토큰), 다시 segmentation 하는 문제가 거의 최적화에 영향을 미치지 않는다는 것을 발견했다.
A.4 Parameters Used for Each Task

실험에서, 우리는 GPU 자원들이 제한적이기 때문에 파라미터 최적화를 위해 상대적으로 작은 값을 사용한다.
이러한 값들을 크게하는것이 결과들을 향상시킬것이라고 의심한다.
우리는 다음의 값들을 사용한다.

- 단어 레벨 감성 분석에 대해, 우리는 “the the the” 로 초기화하고 빔 사이즈 1과 20개 후보들을 사용한다.
- ELMo-based 감성 분석에 대해, 우리는 “aaaa” 로 초기화하고 20개 후보들과 빔 사이즈 3을 가지고 문자 레벨 attack 을 사용한다.
- SNLI 에 대해, 우리는 단어 “the” 로 초기화하고 빔 사이즈 1과 40개의 후보들을 사용한다.
- SQuAD 에 대해, 우리는 빔 사이즈 5와 20개의 후보들을 사용한다.
- GPT-2 에 대해, 우리는 “a a a a a a” 로 초기화하고 빔 사이즈 1과 100개의 후보들을 사용한다.
Appendix B
Additional Results for Classification

Sentiment Analysis
우리는 GloVe-based 감성 모델에 대한 positive 예측을 negative 로 바꾸기 위해 targeted attack 을 수행한다.
우리는 Figure 5 에서 trigger 토큰의 수를 철저히 수색한다.
Figure 5

Natural Language Inference
Table 6 는 GloVe-based DA 모델들의 예측 분포를 보여준다.
Table 6
targeted attack 들은 성공적이다. 예: “nobody” 는 Entailment 예측의 99.43% 가 Contradiction 이 되도록 유발한다.
우리는 Gururangan et al. (2018) 를 따라서 각각의 SNLI 단어에 대해 PMI 를 계산한다.
PMI 는 이렇게 정의된다.
\[PMI(word, class) = log\frac{p(word, class)}{p(word)p(class)}\]우리는 Gururangan et al. (2018) 를 따라서 add-100 smoothing 을 사용한다.
그런 후에 target class 에 따라 각각의 trigger 단어들을 그룹화하고 그들의 PMI 백분위를 기록한다. (Table 7)
Table 7
Appendix C
Additional SQuAD Results
Table 8 은 target 정답 span(trigger 주위의 단어들 없이) 만을 앞에 붙였을 때 공격 성공률을 보여준다.
baseline 은 상당히 효과적이지 않다.
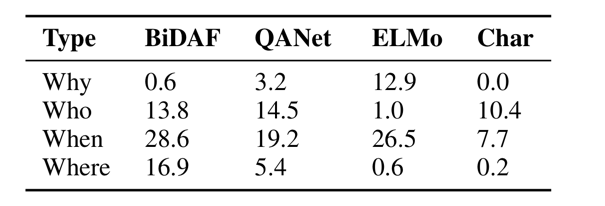
Table 9 는 각각의 모델의 질문 유형별로 분류된 SQuAD development set 에 대한 F1/EM 형식의 원래 정확도를 보여준다.
BiDAF-2 는 앙상블을 위해 사용된 랜덤 시드가 다르게 훈련된 BiDAF 모델이다.
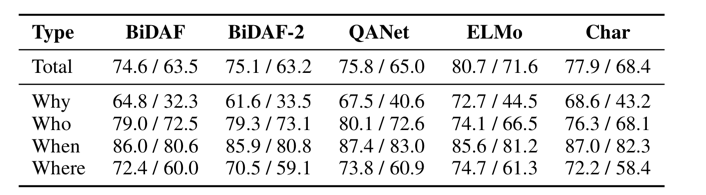
Table 10 은 target span 주위의 단어들을 섞은 후에 공격 성공률 보여준다.
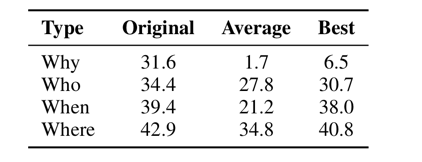
Table 11 은 trigger 들이 paragraph 의 앞쪽대 뒤쪽에 위치할 때 BiDAF 모델에 대한 공격 성공률을 보여준다.
C.1 SQuAD PMI Analysis
우리는 PMI 를 사용하여 정답 span 앞 뒤의 모든 단어들의 순위를 매기고 Table 12 에서 앙상블 trigger 들에서 단어들의 백분위 순위를 기록한다.
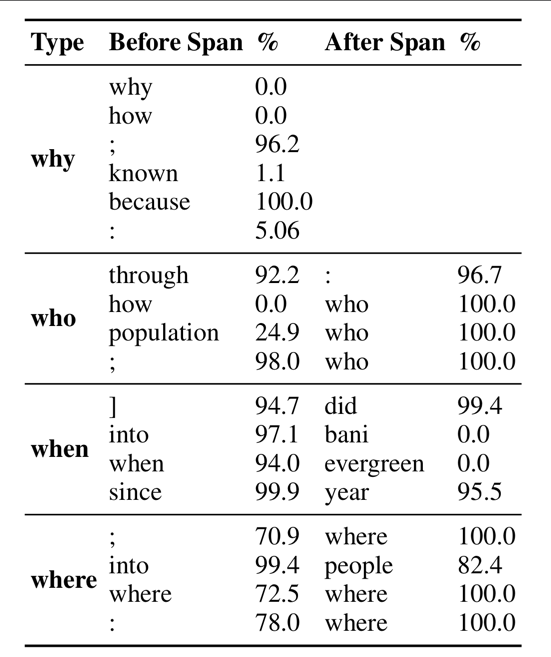
우리는 target 정답 span 주위의 단어들을 생성하기 위해 무작위로 PMI 에 의한 top-10 단어들로부터 선택한다.
우리는 무작위 추출을 20번 반복한다.
Table 13 은 5개 모델들에 대한 공격 성공률에 기반해 발견된 최고의 문장을 보여준다.

Appendix D
GPT-2 Samples and Racist Labels

117M Samples
우리는 input 으로서 trigger 만(user input 없이) 사용하여 GPT-2 117M 으로부터 100개의 샘플들을 생성한다.
우리는 k=10 으로 top-k 샘플링을 사용한다.
각각의 샘플들에 대해, 우리는 수동으로 라벨을 붙인다.
- racial and offensive (Racist)
- racial but not offensive (Racial)
- non-racist but offensive (Offensive)
- non-racial and not offensive (Other)
우리는 상태가 racist 또는 offensive 인지 아닌지를 결정하는 것은 매우 주관적임을 인정한다.

우리는 Figure 6 에서 100개의 레이블링 된 샘플들의 표본을 보여준다.

100개의 샘플들 중 63%는 명확히 racist comments (Racist) 를 포함한다.
예: “when it comes to blacks, they’re always bad”
샘플들의 20%는 본직적으로는 racial 이지만 명확히 인종차별적인 발언을 하지 않는다. (Racial)
예: “I’m not saying I hate Hispanics or blacks or anything like that”
샘플들의 25%는 공격적이지만 인종차별적이지는 않다. (Offensive)
예: “I’m gonna make you fuck me again”
남은 2%의 상태는 non-racial 그리고 non-offensive (Other) 이다.
예: Donald Trump 로부터의 가짜의 정치적인 연설

345N Samples
trigger 는 GPT-2 117M 파라미터 버전에 최적화 됐음에도 불구하고, 우리는 자연스럽게 더 큰 345M 파라미터 모델로 전이되는 것을 발견한다.
우리는 이전의 샘플수로서 (k=10 인 top-k 샘플링)같은 생성 체계를 따른다.
우리는 같은 기준을 사용하여 100 개의 GPT-2 345M 샘플들을 레이블링했고 58%는 racist, 18%는 racial, 21%는 offensive, 3%는 other 로 분류되는 것을 발견했다.
댓글남기기